1. The logistic regression model hypothesis is:, where X represents a feature vector, g represents a logistic function (logistic function) is a commonly used S-shaped logistic function, the formula is:,
the image of the logistic function is:
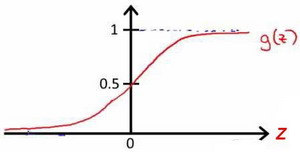
Since the value range of the g(z) function is 0-1, the understanding of this is: for a given input variable, the probability of the output variable=1 ( estimated probablity ) is calculated according to the selected parameters
. For example, if for a given x , h θ x =0.7 is calculated through the determined parameters , it means that there is a 70% probability that y is a positive category, and the corresponding probability that y is a negative category is 1-0.7= 0.3.
2. After the model function is determined, the loss function needs to be determined. The loss function is used to measure the difference between the output of the model and the real output.
Assuming that only two label 1 and 0, . If we regard any set of samples collected as an event, then the probability of this event's occurrence is assumed to be p. The value of our model y is equal to the probability that the label is 1, which is p.
Because the label is either 1 or 0, the probability of the label being 0 is:
We regard a single sample as an event, then the probability of this event occurring is:
This function is not easy to calculate, it is equivalent to:
To explain the meaning of this function, we have collected a sample , and for this sample,
the probability that its label is
. (When y=1, the result is p; when y=0, the result is 1-p).
If we collect a set of data, a total of N ,, how to find the total probability of this combined event? In fact, it is enough to multiply the probability of each sample occurrence, that is, the probability of collecting this set of samples:
Since continuous multiplication is very complicated, we take logarithms on both sides to turn continuous multiplication into continuous addition form, namely:
among them
This function is also called its loss function . The loss function can be understood as a function that measures the difference between the output result of our current model and the actual output result. The value of the loss function here is equal to the total probability of occurrence of the event, and we hope that the larger the better. But it is a bit contrary to the meaning of loss, so you can also take a negative sign in front. and so:
3. According to the above, we know the gradient loss function of logistic regression , then the gradient function can be obtained by finding the right
partial derivative
.
In the derivation,
the following can be obtained:
4. According to the above, the definition of logistic regression can be obtained:
objective function:
Cost function:
Gradient function:
Gradient descent process:

The gradient descent formula is:
Among them
is the learning rate, you can choose: 0.01, 0.03, 0.1, 0.3, 1, 3, 10
Reference from: https://zhuanlan.zhihu.com/p/44591359