The actual combat of web crawlers
- Guidance
- 1 Getting started with the Re (regular expression) library
- Example 2 "Taobao Commodity Price Comparison Targeted Crawler" (requests+re)
- Example 3 "Stock Data Oriented Crawler" (requests+bs4+re)
Guidance
1 Getting started with the Re (regular expression) library
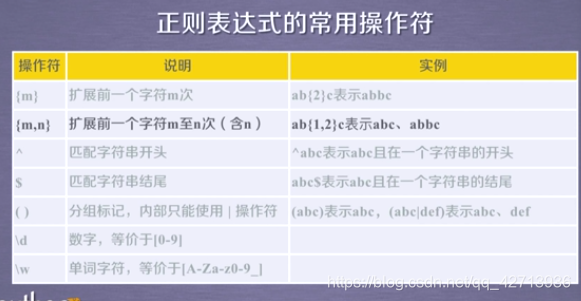
1.1 The concept of regular expressions

It is too cumbersome to list all of them, so using regular expressions

can express a group of strings.
Example 1:
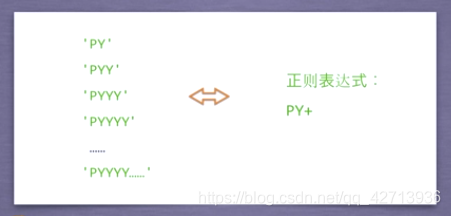
Example 2:




The features after compilation correspond to a group of strings
. The regular expression before compilation is just one that conforms to the regular expression syntax. Single string
1.2 Regular expression syntax

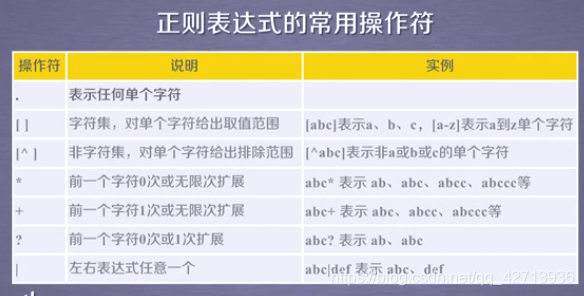
".": Any character that appears on the character table



The first one: does not consider the value range and space of each paragraph, only considers the "." between them to separate the
second: every string that appears is 0 or 1 or 2 or 3
above 2 are not precise enough

1.3 Basic use of Re library

1.3.1 Representation type of regular expression-native string type

The "in the native string is not expressed as an escape character,

so:

1.3.2 Main functions of Re library

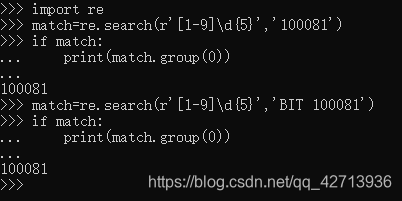
re.search(): search for the same place as the regular expression in the string
re.match(): match only at the given position
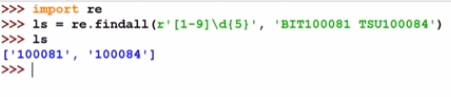
re.findall(): find all the same as the regular expression in the string String of strings
re.search()


In the regular expression,'.' matches any character except'\n'. For
example: Chinese postal code, matching "BIT 10081"

, what's the use of writing'BIT', return from re.match(), this' BIT' has no specific meaning, just to show that search does not necessarily match from the beginning
re.match()


It is found that no match is found.
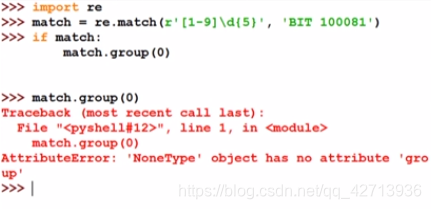
Because match matches from the beginning, it will not match'BIT 100081'.
If you don't judge whether it matches, an error will be reported.

re.findall()

re.split()

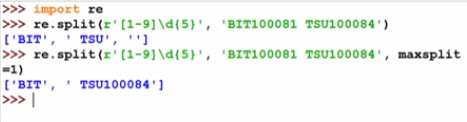
The second one above adds maxsplit=1 to indicate that it only matches once
re.finditer ()


Ability to iteratively return each result and process each result separately


re.compiler()

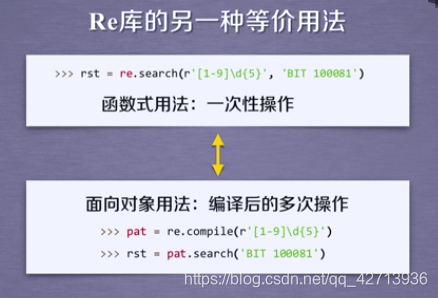

1.4 match object of Re library
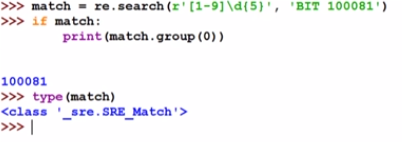
1.4.1 Properties of the Match object

1.4.2 Methods of Match Object


The output is marked with compile, which means that only after compile will be

the start and end position of the regular expression search

match returns the result of the first match. If you want to return every time, you must use finditer() to

match

the binary relationship between the start and end positions of the string.
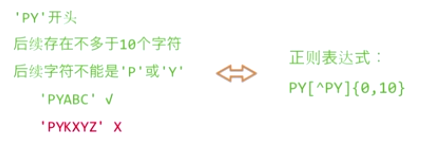
1.5 Greedy matching and minimum matching of the Re library

PY.*N: start with PY, end with N, and a string of any characters in the middle



1.6 Summary

Example 2 "Taobao Commodity Price Comparison Targeted Crawler" (requests+re)
1 "Taobao commodity price comparison directional crawler" example introduction



This example does not harass Taobao’s servers

2 "Taobao commodity price comparison directional crawler" example compilation
Overall structure
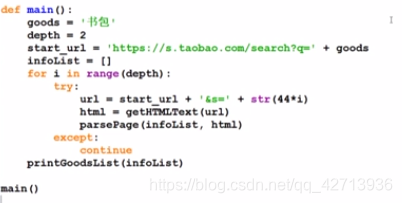
depth=2: crawl 2 pages
try:
…
except:
continue
crawling a page after an error, continue to crawl the next page
getHTMLText()

parsePage ()
Because the price of Taobao uses a scripting language, it can be done only by search, so there is no need to use bs, here is just a regular rule,
but now the search on Taobao will pop up the login interface, this crawler may not be suitable for Now the
Taobao source code in the video.
Its price is:
- "View_price": 139.9
Its name is in: - “raw_Title”:xxxxx


The first slash is an escaped
regular expression: "view_price":"[\d.]* "

eval(): remove the double quotes and
take the following ":"
printGoodsList()
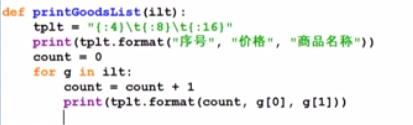

Indicates that the length of the first element of the output is 4, the length of the second element is 8, and the length of the third element is 16

3 summary

Source code
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
It doesn't seem to be good anymore, I haven't climbed anything
Example 3 "Stock Data Oriented Crawler" (requests+bs4+re)
1 Introduction to the "Stock Data Targeted Crawler" example



Looking at the source code, you can see that Baidu stock is more suitable.
However, Baidu stock cannot find many stock information on one page.
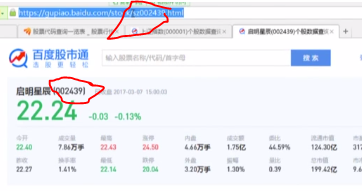
Therefore, open the Oriental Fortune website.


Refer to the storage method of the page to perform related calibration for each information source and information value. Key-value pairs can be used. The dictionary type is the data type that maintains the key-value pairs to save the information of each stock, and then use the dictionary to compare all stocks. Integration of information
2 Example preparation of "stock data directional crawler"
For debugging convenience, use the traceback library
Overall framework
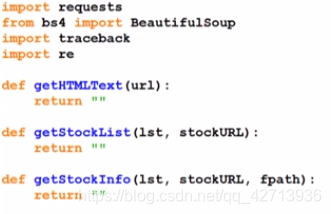
getStockList(): get the list of stocks
getStockInfo(): get the information of a single stock
getHTMLText()

getStockList()
Eastern Fortune.com source code:

all stored in, as long as it is parsed, there will be stock codes (the last few digits of href)
using regular expressions, but not all hrefs in them will meet the conditions, so try can be used …Except

regular expression is the stock code of Shenzhen or Shanghai, starting with s, followed by h or z, and then 6 digits
getStockInfo()
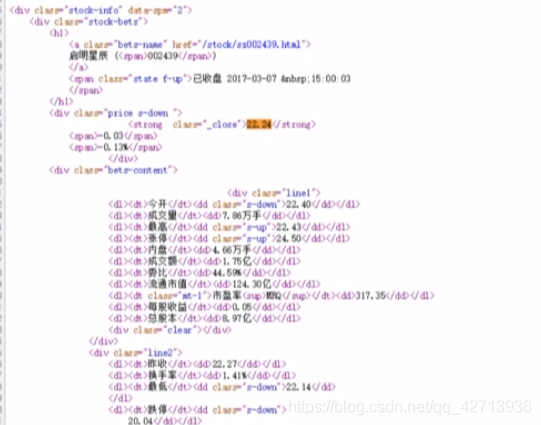
The source code of Baidu stock
First, send a request to each stock.
Use try...except to ensure that the returned page is normal.
All stock information is encapsulated in
stock name with the stock name in class='bets-name'

, because some names are also associated with other identifiers, using spaces which was taken after the separation points out part 0
then, the information in all of the stock
-
key
- value
Complete code
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
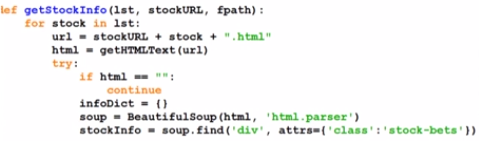
def getStockInfo(lst, stockURL, fpath):
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {
}
soup = BeautifulSoup(html, 'html.parser')
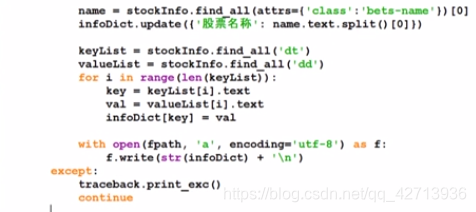
stockInfo = soup.find('div',attrs={
'class':'stock-bets'})
name = stockInfo.find_all(attrs={
'class':'bets-name'})[0]
infoDict.update({
'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
except:
traceback.print_exc()
continue
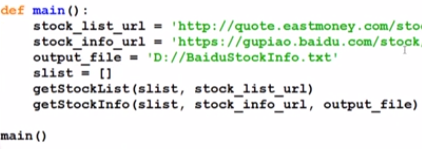
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
This is not good either. The website has been revised and cannot be crawled out. The importance of keeping up with the times
3 Example optimization of "stock data directional crawler"
Improve user experience, but as long as requests and bs4 are used, the speed will not increase
3.1 Speed improvement: optimization of code recognition

Manually obtain the coding method.
Modified to:

The code of Oriental Fortune.com is'GB2312'.

Baidu stock adopts'utf-8', and it is not modified.
3.2 Experience improvement: add dynamic progress prompt

There are a lot of crawling pages, the progress is displayed dynamically, and the progress bar that does not wrap dynamically is added.
- Add 1 count variable

- No line breaks, using the escape character'\r', can bring the last cursor of the string we printed to the head of the current line, and the previous

'\r' will be overwritten in the next printing. Idle is forbidden Dropped, so use the command line