Original author: Caiyuan Nan
Original address: Why will MapReduce be eliminated by Silicon Valley first-tier companies? Time.geekbang.org
table of Contents
Technical development of ultra-large-scale data processing
Why MapReduce will be replaced
Whenever I communicate with colleagues who visit Silicon Valley, they always try to explore MapReduce experience as long as they talk about data processing technology. This point surprised me, because in Silicon Valley, MapReduced has been talked very little. Today in this talk, we will talk about why MapReduce will be eliminated by Silicon Valley first-tier companies.
Let's first take a look at the important technologies of ultra-large-scale data processing along the timeline and the age of their generation:

Technical development of ultra-large-scale data processing
I think the technological development of ultra-large-scale data processing can be divided into three stages: the stone age, the bronze age, and the steam engine age.
Stone Age:
I use the "Stone Age" to compare the period before the birth of MapReduce. Although the problem of large-scale data processing has long existed, as early as 2003, Google had already faced more than 60 billion searches. However, the large-scale data processing technology is still in the hesitation stage. At that time, every company or individual might have its own set of tools to process data. But there is no way to abstract a system.
Bronze Age:
In 2003, the birth of MapReduce marked the first revolution in ultra-large-scale data processing, and the following paper "MapReduce: Simplified Data Processing on Large Clusters" was the pioneer of this bronze age. Jeff (Jeff Dean) and Sanjay (Sanjay Ghemawat) abstracted a sufficiently general programming model like Map and Reduce for us from the complicated business logic. The latter Hadoop is just a drawing of GFS, BigTable, and MapReduce, so I won't go into details here.
Steam engine era:
By around 2014, almost no one inside Google wrote a new MapReduce. Beginning in 2016, Google replaced MapReduce with data processing technology called Flume (not to be confused with Apache Flume, two technologies) in the training of new employees. This marked the end of the Bronze Age and also marked the steam engine. The beginning of the era. I skip descriptions such as "Iron Age" because only the concept of the Industrial Revolution can explain the epoch-making significance of the evolution from MapReduce to Flume. The unified programming model introduced by Google's internal Flume and its later open source version Apache Beam will be analyzed in depth for you in later chapters. Now you may have a question: why will MapReduce be replaced?
Why MapReduce will be replaced
1. High maintenance cost
Using MapReduce, you need to strictly follow the step-by-step Map and Reduce steps. When you construct a more complex processing architecture, you often need to coordinate multiple Maps and multiple Reduce tasks. However, every step of MapReduce may go wrong. For these exception handling, many people began to design their own coordination system (orchestration). For example, a state machine (state machine) to coordinate multiple MapReduce, which greatly increases the complexity of the entire system. If you search for keywords like "MapReduce orchestration", you will find that there are a lot of books on how to coordinate MapReduce. You may be surprised by the complexity of MapReduce. I often see some misleading articles that oversimplify MapReduce, such as "Import a large amount of ××data through MapReduce into a big data system to learn, and ××artificial intelligence can be produced." You can turn stones into gold. However, the complexity of the actual MapReduce system exceeds the cognitive scope of "pseudo-experts". Let me give you an example to tell you how complicated MapReduce is. Imagine this scenario. Your company wants to predict the stock price of Meituan . One of the important characteristics is the number of Meituan takeaway electric vehicles active on the street, and you are responsible for processing all the pictures of Meituan takeaway electric vehicles . In a real commercial environment, you may need at least 10 MapReduce tasks:

First, we need to collect daily pictures of take-out electric vehicles. The collection of data is often not all done by the company alone, and many companies will choose partial outsourcing or crowdsourcing. So in the Data collection section, you need at least 4 MapReduce tasks:
- Data ingestion: Used to download scattered photos (such as photos uploaded by a crowdsourcing company to a network disk) to your storage system.
- Data normalization: used to unify the format of all kinds of photos provided by different outsourcing companies.
- Data compression (compression): You need to keep the storage resource consumption to a minimum within acceptable quality.
- Data backup (backup): We all need a certain amount of data redundancy to reduce risks in large-scale data processing systems.
Just finishing the step of data collection is far from real business applications. The real world is so imperfect, we need a part of the data quality control process, such as:
- Data time validation (date validation): Check whether the uploaded picture is the date you want.
- Photo focus detection (focus detection): You need to filter out those photos that cannot be used due to inaccurate focus.
Finally, you are responsible for the main task: find the take-out electric car in these pictures. And this step is the most difficult to control time because of manual intervention. You need to do 4 steps:
- Data annotation question uploading: Upload your annotation tool and let your annotator start working.
- Annotation result downloading (answer downloading): Grab the annotated data.
- Annotation of objection integration (adjudication): Annotation of objections often occurs. For example, one annotator thinks it is a Meituan takeaway electric car, and another annotator thinks it is an electric car of JD Express.
- Structuralization of annotation results: To make annotation results available, you need to convert potentially unstructured annotation results into a structure that your storage system accepts.
I will not go into the technical details of each MapReduce task, because the focus of this chapter is only to understand the complexity of MapReduce. Through this case, the point I want to express is that because the real commercial MapReduce scenario is extremely complex, the above 10-subtask MapReduce system is commonplace in Silicon Valley first-tier companies. In the application process, every MapReduce task may go wrong, and retry and exception handling mechanisms are required. Coordinating these sub-MapReduce tasks often requires a state machine that is tightly coupled with business logic. Overly complex maintenance makes system developers miserable.
2. Time performance "cannot meet" user expectations
In addition to high maintenance costs, the time performance of MapReduce is also a thorny issue. MapReduce is such a sophisticated and complex system. If used properly, it is Qinglongyanyuedao. If used improperly, it is a pile of scrap iron. Unfortunately, not everyone is Guan Yu. In actual work, not everyone is familiar with the subtle configuration details of MapReduce. In real work, the business often requires a newbie who has just graduated to launch a data processing system within 3 months, and he has probably never used MapReduce. In this case, the system developed is difficult to give full play to the performance of MapReduce. You must want to ask, what is the complexity of the performance optimization configuration of MapReduce?
In fact, Google’s MapReduce performance optimization manual has more than 500 pages . Here I will give an example of the sharding problem of MapReduce , hoping to catch a glimpse of the leopard and arouse everyone's thinking. Google once conducted a large-scale sorting experiment on 1PB of data from 2007 to 2012 to test the performance of MapReduce. From 12 hours of sorting time in 2007 to 0.5 hour of sorting time in 2012, even Google took 5 years to continuously optimize the efficiency of a MapReduce process. In 2011, they announced their preliminary results on the Google Research blog ( http://googleresearch.blogspot.com/2011/09/sorting-petabytes-with-mapreduce-next.html ). One of the important findings is that they spent a lot of time on the performance configuration of MapReduce. Including the buffer size (buffer size), the number of shards (number of shards), prefetch strategy (prefetch), cache size (cache size) and so on. The so-called sharding refers to the distribution of large-scale data to different machines/workers. The process is shown in the following figure.

Why is choosing a good sharding function so important? Let us look at an example. Suppose you are dealing with all Facebook user data, and you have chosen to use the age of the user as the sharding function. Let's see what happens at this time. Because the age distribution of users is unbalanced, if there are the most Facebook users in the 20-30 age group, the tasks we assign to worker C in the figure below are much larger than the tasks on other machines.

At this time, stragglers will occur. Other machines have completed the Reduce phase, and it is still working. The problem of lagging behind can be found through the performance profiling of MapReduce. As shown in the figure below, the left machine is at the arrow.
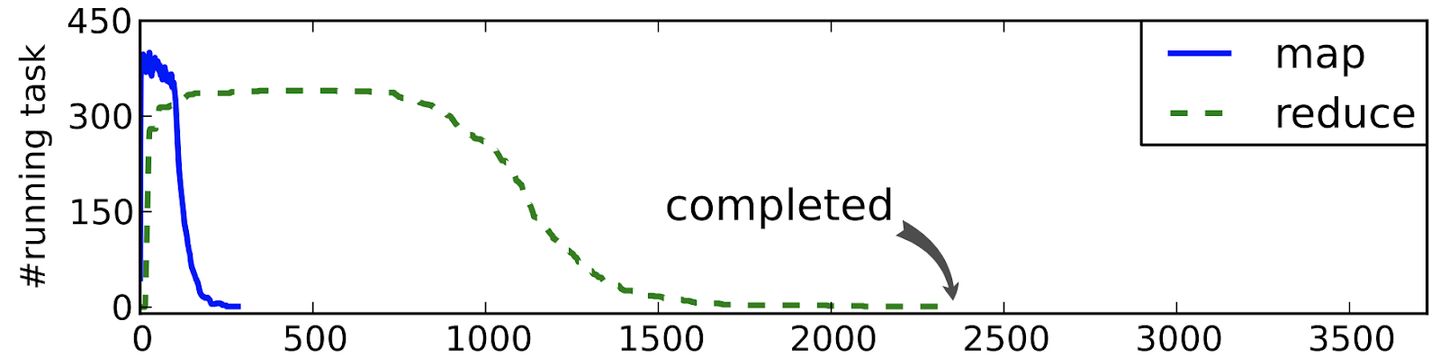
图片引用:Chen, Qi, Cheng Liu, and Zhen Xiao. "Improving MapReduce performance using smart speculative execution strategy." IEEE Transactions on Computers 63.4 (2014): 954-967.
Back to the Google large-scale sorting experiment just now. Because the sharding configuration of MapReduce is extremely complicated, after 2008, Google improved the sharding function of MapReduce and introduced dynamic sharding, which greatly simplified the manual adjustment of sharding by users. After that, various new ideas including dynamic sharding technology were gradually introduced, laying the prototype of the next generation of large-scale data processing technology.