Notice: If this site is helpful to your learning algorithm, please bookmark the website and recommend it to your friends . Because labuladong 's algorithmic routines are too popular , many people directly use my GitHub articles to open paid columns, and the price is not cheap. I’ll write this for you for free. Promote the original author is the only thing you can do . No one wants bad money to drive out good money, right?
Our official account has a lot of hard-core algorithm articles. Let’s talk a little bit lightly today, let’s talk specifically about "Algorithm 4" which I am very "advocating". I have recommended this book many times in previous articles, but there is no specific introduction. I will officially introduce it today. .
My recommendation will not directly throw a lot of books, but will relate to real life and talk about some interesting and useful knowledge in the book. Whether you will read this book or not, this article will bring you some gains.
First of all, this book is suitable for beginners . Many readers always ask, I only know C language, can I watch "Algorithm 4"? What language is best to use to learn algorithms? Such questions.
Readers who often read our official account should realize that algorithms are actually a mode of thinking, which has nothing to do with what language you use. Our articles will not be fixed in a certain language, but in any language that is easy to understand. Take a step back and say, is it right for you? Find a PDF on the Internet and read it in person.
"Algorithm 4" looks quite thick, but the first dozen pages are for teaching you Java; there are exercises at the end of each chapter, occupying a lot of pages; each chapter also has some mathematical proofs, which can be ignored. Calculated in this way, what is left is the basic knowledge and troubleshooting, which contains a lot of gold. If you put these basic knowledge into practice, you can really reach a good level.
PS: I have written more than 100 original articles carefully , and I have hand-in-hand brushed 200 buckle questions, all of which are published in labuladong's algorithm cheat sheet , which is continuously updated . It is recommended to collect, brush the questions in the order of my articles , master various algorithm routines, and cast them into the sea of questions.
I think the reason why this book has such a high score is because of the detailed explanation and a large number of pictures. The other reason is that the book connects some algorithms with real-life usage scenarios. You not only know a certain How to implement the algorithm and know what scenarios it can be used in. Now I will introduce the simple application of two graph algorithms.
1. Application of bipartite graph
The first example I want to give is a bipartite graph . In simple terms, a bipartite graph is a graph with special properties: it can color all vertices with two colors, so that the two vertices of any edge have different colors.
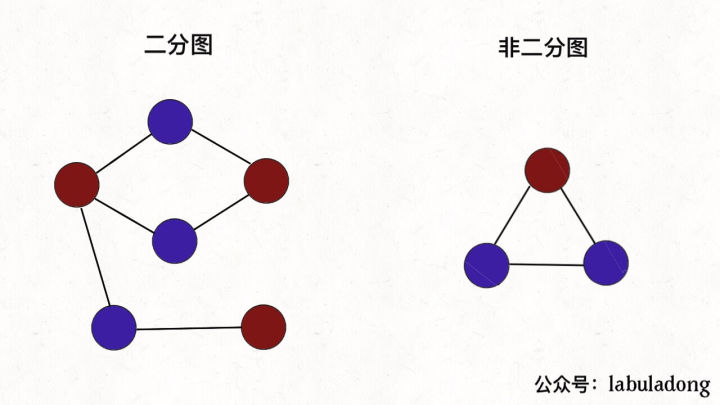
Understand what a bipartite graph is, and what practical problems can it solve? In terms of algorithms, a common operation is how to determine whether a picture is a bipartite graph . For example, the following LeetCode topic:
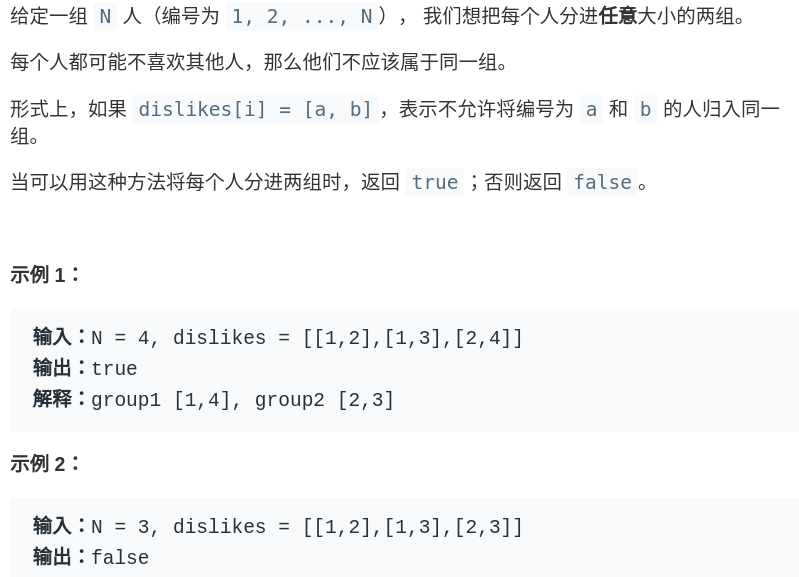
If you think about it, if we treat everyone as a vertex, and the edge represents annoying; two people who hate each other connect an edge to form a graph. Then according to the definition of the bipartite graph just now, if the picture is a bipartite graph, it means that these people can be divided into two groups, otherwise it won't work.
This is an application of the judgment bipartite graph algorithm. In fact, the bipartite graph also has some good characteristics in terms of data structure .
For example, we need a data structure to store the relationship between movies and actors: a certain movie must be played by multiple actors, and a certain actor may play multiple movies. What data structure do you use to store this relationship?
Since it is to store the mapping relationship, the easiest way is not to use a hash table. We can use a HashMap<String, List<String>> mapping to store the movie to the actor list. If you give a movie the name, you can quickly get the actors who played the movie.
But if we give an actor the name, we want to quickly get all the movies performed by the actor, what should we do? This requires "reverse indexing" to perform some operations on the previous hash table and create another hash table with actors as keys and movie lists as values.
For the above example, a bipartite graph can be used to replace the hash table. Movies and actors are of the nature of a bipartite graph: if you regard movies and actors as vertices in the graph, and the starring relationship as edges, then the actor connected to the vertices of the movie must be the actor, and the next to the actor must be the movie. There is no actor and The actors are connected, and the movie and the movie are connected.
PS: I have written more than 100 original articles carefully , and I have hand-in-hand brushed 200 buckle questions, all of which are published in labuladong's algorithm cheat sheet , which is continuously updated . It is recommended to collect, brush the questions in the order of my articles , master various algorithm routines, and cast them into the sea of questions.
Looking back at the definition of a bipartite graph, if you color the vertices of actors and movies, it must be a bipartite graph:
If this picture is constructed, there is no need for reverse indexing. For the actor vertex, the directly connected vertex is the movie he starred in, and for the movie vertex, the directly connected vertex is the actor.
Of course, for this issue, the book also mentions some other interesting gameplay, such as the calculation of "interval degree" in social networks (six degree space theory should have heard of it), etc., in fact, it is a BFS breadth first search to find the shortest The path issue, the specific code implementation will not be expanded here.
2. Arbitrage algorithm
If we say that the exchange rate from currency A to currency B is 10, it means that 1 unit of currency A can be exchanged for 10 units of currency B. If we regard each currency as the vertex of a graph, and the exchange rate between currencies as a weighted directed edge, then the entire exchange rate market is a "fully weighted directed graph."
Once the real-life scenarios are abstracted into pictures, it is possible to use algorithms to solve some problems. For example, the following situation may exist in the picture:
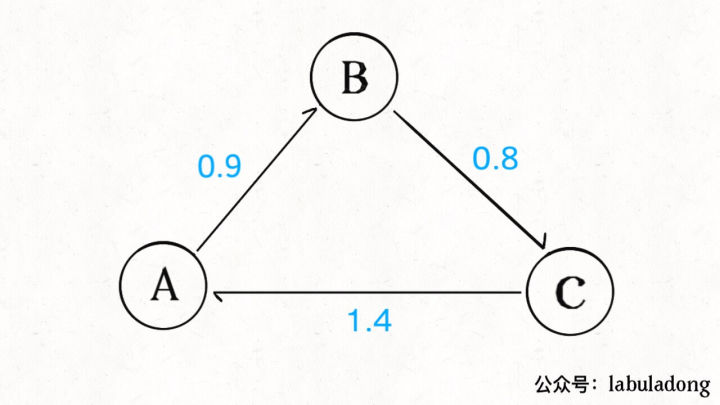
The weighted directed edge in the figure represents the exchange rate. We can find that if 100 units of currency A is replaced by B, then replaced by C, and finally back to A, we can get 100×0.9×0.8×1.4 = 100.8 units of A! If the transaction amount is larger, the money earned is considerable. This kind of empty glove white wolf operation is arbitrage.
In reality, there are various restrictions on trading, and the market is changing rapidly, but the profit of arbitrage is still very high. The key is how to quickly find such arbitrage opportunities?
With the help of the abstraction of the graph, we find that the arbitrage opportunity is actually a ring, and the product of the weights on this ring is greater than 1. As long as you trade along this ring, you can empty the white wolf.
There is a classic algorithm in graph theory called Bellman-Ford algorithm, which can be used to find negative weight loops . For the arbitrage problem we are talking about, you can first replace the weight w of all edges with -ln(w), so that "looking for a ring with a weight product greater than 1" is transformed into "looking for a ring with a weight sum less than 0", you can use The Bellman-Ford algorithm looks for negative weight loops in O(EV) time, that is, looking for arbitrage opportunities.
"Algorithm 4" is introduced here. Regarding the specific content of the above two examples, you can read the book yourself, and the public account backstage reply keyword "Algorithm 4" will have a PDF .
PS: I have written more than 100 original articles carefully , and I have hand-in-hand brushed 200 buckle questions, all of which are published in labuladong's algorithm cheat sheet , which is continuously updated . It is recommended to collect, brush the questions in the order of my articles , master various algorithm routines, and cast them into the sea of questions.
Three, finally say a few words
First of all, the previous article said that the mathematical proofs and post-chapter exercises can be ignored, and some people may want to raise the bar: Are the exercises and mathematical proofs not important?
Then I want to say that it is not important, at least not important to most people. I think, learning must be done with purpose. Isn't most people learning algorithms just to consolidate computer knowledge and deal with interview questions? If it is for this purpose , then learn some basic data structures and classic algorithms, understand their time complexity, and then go to the questions, why bother with the exercises and proofs?
This is why I never recommend the book "Introduction to Algorithms". If someone recommends this book to you, there may only be two reasons, either he is a real boss, or he is pretending to be a boss. "Introduction to Algorithms" is full of a lot of mathematical proofs, and many data structures are rarely used, at best as a dictionary. You said that what's the use of what you learned, spare yourself.
In addition, there is not much reading. You spend most of the time on "Algorithm 4" (the last small part is a bit difficult), and at the same time, brush up some questions and take a look at our official account article. The algorithm is really enough. Don't be too serious about the details.