As the business expands and the amount of data accumulates, the data capacity and computing power of the database system will gradually become overwhelmed. Therefore, an excellent database system must have good scalability. The data nodes in the DolphinDB cluster integrate computing and storage. Therefore, to improve computing power and data capacity, you only need to target the data nodes. DolphinDB supports both horizontal expansion, which means adding nodes, and vertical expansion, which means increasing node storage.
Before expanding the cluster, you need to have a basic concept of the DolphinDB cluster. The DolphinDB cluster is composed of 3 roles: Controller, Agent and Data Node. The tasks assigned to each role are as follows:
- The control node is responsible for managing metadata and providing Web cluster management tools.
- The agent node is responsible for the start and stop of the node, and there must be an agent node on each server.
- The data node is responsible for calculation and storage.
Configuration files related to the cluster are generally located in the config directory:
controller.cfg: Located on the server where the control node is located, it is responsible for defining the relevant configuration of the control node, such as IP, port number, and upper limit of the number of connections of the control node.
cluster.cfg: Located on the server where the control node is located, it is responsible for defining the personalized configuration of each node in the cluster, such as storage path, number of connections, memory limit, etc.
cluster.nodes: Located on the server where the control node is located, the member configuration file of the cluster, including the node's IP, port, node alias and role.
agent.cfg: Contains the IP and port of the agent node and the IP and port of the control node. Each physical server must have a proxy node.
If the cluster is scaled horizontally, the member configuration file (cluster.nodes) of the cluster needs to be modified. If the data node is located on a new physical server, a new agent node (agent.cfg) needs to be deployed to be responsible for the node on the new physical machine. Start and stop, and then restart the control node to load the new data node. When a new data node is started, the computing power of the node will be immediately included in the cluster's computing resource planning, but the data that has been stored in the cluster will not be adjusted to the new data node, and the system will allocate the subsequent newly entered data according to the strategy. Various data nodes.
If it is a vertically expanded cluster, you only need to modify the configuration file (cluster.cfg) of the data node to add a path to the volume parameter of the specified node.
The steps to expand the cluster are described in detail below.
1. Cluster configuration instructions
For cluster deployment, please refer to the tutorial Multi-physical server cluster deployment .
The example cluster has 3 data nodes, each data node is located on a physical server, and the control node is located on another physical server:
Control node: 172.18.0.10
Data node 1: 172.18.0.11
Data node 2: 172.18.0.12
Data node 3: 172.18.0.13
The information of each configuration file is as follows:
controller.cfg
localSite=172.18.0.10:8990:ctl8990
cluster.nodes
localSite,mode 172.18.0.11:8701:agent1,agent 172.18.0.12:8701:agent2,agent 172.18.0.13:8701:agent3,agent 172.18.0.11:8801:node1,datanode 172.18.0.12:8802:node2,datanode 172.18.0.13:8803:node3,datanode
Agent.cfg on the physical server where data node 1 is located
localSite=172.18.0.11:8701:agent1 controllerSite=172.18.0.10:ctl8900
In order to reflect the expanded effect, we first set
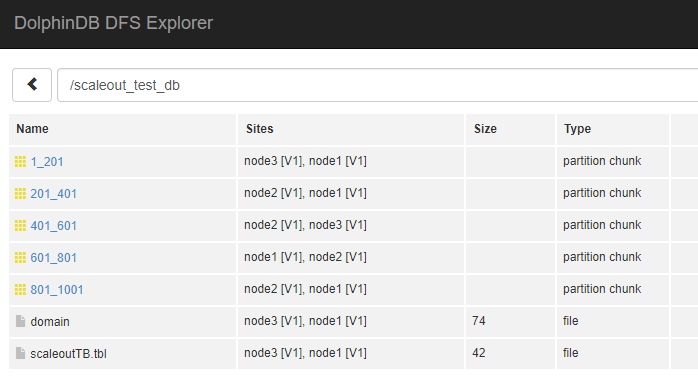
Create a distributed database in the group and write data:
data = table(1..1000 as id,rand(`A`B`C,1000) as name)
//A reserve of 1000 is reserved for partitioning, and it is used for subsequent write tests.
db = database("dfs: //scaleout_test_db",RANGE,cutPoints(1..2000,10))
tb = db.createPartitionedTable(data,"scaleoutTB",`id)
tb.append!(data)
After execution, observe the distribution of data through DFS Explorer on the Web:
After expanding the cluster, we can observe whether the new node or storage is enabled by appending new data.
2. Horizontal expansion
Due to the increase in business data volume, the storage and computing capacity of the cluster cannot meet the requirements, a new server is now added and added to the original cluster as a new node. The newly added server IP address is 172.18.0.14, the port number is 8804, and the alias is node4. The new server needs to deploy an agent node, using port 8701, and the alias is agent4.
Proceed as follows:
(1) Deploy new agent nodes
Copy the DolphinDB installation package to the new server and unzip it. Add a config folder under the server folder and create agent.cfg, adding the following content:
#Specify the ip and port of the Agent itself localSite=172.18.0.14:8701:agent4 #Tell the Agent the location of the controller of this cluster controllerSite=172.18.0.10:8990:ctl8990 mode=agent
(2) Modify the cluster member configuration
Go to the physical server where the control node is located, modify config/cluster.nodes, and add cluster member information. The contents of the modified file are:
localSite,mode 172.18.0.11:8701:agent1,agent 172.18.0.12:8701:agent2,agent 172.18.0.13:8701:agent3,agent 172.18.0.14:8701:agent4,agent 172.18.0.11:8801:node1,datanode 172.18.0.12:8802:node2,datanode 172.18.0.13:8803:node3,datanode 172.18.0.14:8804:node4,datanode
(3) Restart the cluster
In the Linux environment, use the command pkill dolphindb to shut down the cluster. After waiting for the port resources to be released, restart the controller and each agent. The command is as follows:
Start the controller:
nohup ./dolphindb -console 0 -mode controller -script dolphindb.dos -config config/controller.cfg -logFile log/controller.log -nodesFile config/cluster.nodes &
Start the agent:
./dolphindb -mode agent -home data -script dolphindb.dos -config config/agent.cfg -logFile log/agent.log
Enter the IP and port number of the control node in the browser address bar, such as 172.18.0.10:8990, to access the Web, we can see that the newly added agent node agent4 has been started, and the data node node4 is shut down.
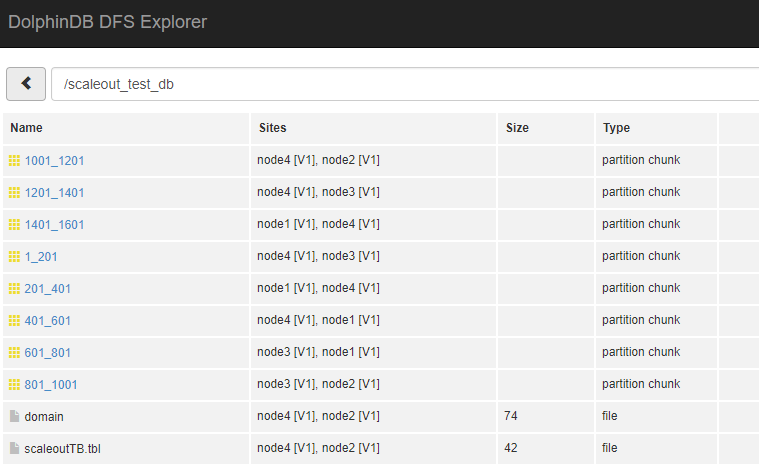
Start each node, and the cluster can be used normally.
Next, we write some data to the database dfs://scaleout_test_db on the cluster to verify whether the new data node has been enabled.
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1001..1500 as id,rand(`A`B`C,500) as name))
Observe the DFS Explorer, you can see that there is data distributed to the new node node4.
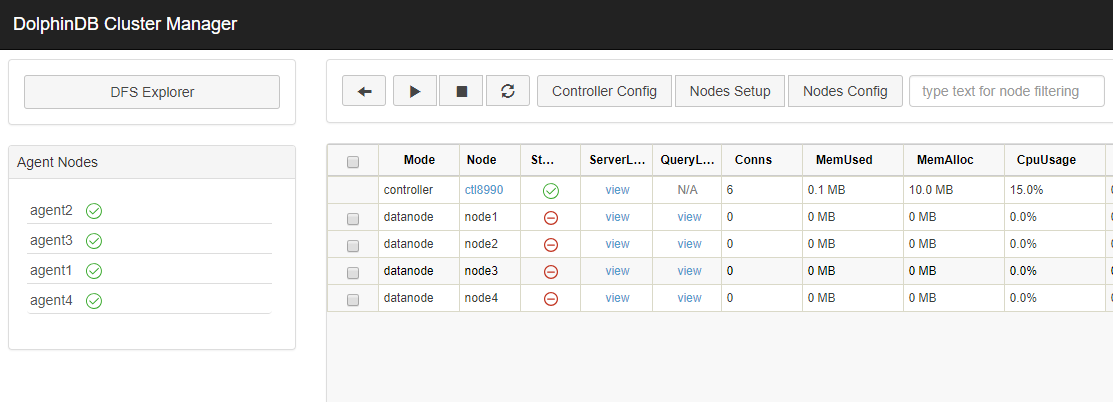
Sometimes we will find that some data will be migrated to other nodes. This is related to the recovery mechanism of DolphinDB. DolphinDB cluster supports automatic data recovery. When the system detects that some nodes in the cluster have not had a heartbeat for a long time, it is determined to be down, and data will be automatically restored from other copies and the number of copies of the entire cluster will be kept stable. This is the reason why data will migrate when a node has not been started for a long time. The recovery mechanism of DolphinDB is related to the following configuration parameters of the control node:
#The number of copies of each data in the cluster, the default is 2 dfsReplicationFactor= 2 #Replica security policy, more than 0 copies are allowed to exist on one node 1 Multiple copies must be stored in different nodes, the default is 0 dfsReplicaReliabilityLevel=1 #How long does the node's heartbeat stop and start Recovery ,Not enabled by default, unit ms dfsRecoveryWaitTime=30000
dfsRecoveryWaitTime controls the startup of recovery. If this parameter is not set, the recovery function will be turned off. The default is off. The setting of the waiting time is mainly to avoid unnecessary recovery caused by some planned shutdowns and maintenance, and needs to be set by the user according to the actual situation of operation and maintenance.
In terms of stability, the more replicas, the less likely it is to lose data accidentally, but too many replicas will also lead to poor performance when the system saves data, so the value of dfsReplicationFactor is not recommended to be lower than 2, but the specific settings require users Consider comprehensively based on the number of nodes in the overall cluster, data stability requirements, and system write performance requirements.
dfsReplicaReliabilityLevel is recommended to be set to 1 in a production environment, that is, multiple replicas are located on different servers.
3. Vertical expansion
Assuming that the disk space of the server where node3 is located is insufficient, a disk is now added with the path /dev/disk2, which needs to be included in the storage of node3. The storage path of the data node is specified by the volume parameter in the configuration file. If the initial cluster does not specify the volume parameter, the default storage path is [HomeDir]/DataNodeAlias]/storage, that is, the default storage path of node3 is data/node3/storage .
Add the following content to the cluster.cfg file of the control node:
node3.volumes=data/node3/storage,/dev/disk2/node3
Note that if you need to add a storage path after the default path, you need to explicitly set the default path, otherwise the metadata under the default path will be lost.
After modifying the configuration, you only need to restart the data node, not the control node.
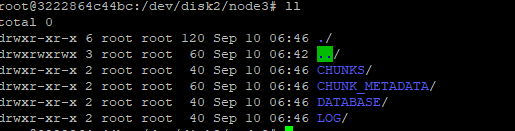
Next, write new data to the cluster to see if the data is written to the new disk.
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1501..2000 as id,rand(`A`B`C,500) as name))
Go to the disk to observe whether the data is written:
There is no clear upper limit on the data size that DolphinDB can support, and it depends entirely on the amount of resources invested.