
Author | Liu Mi Alibaba Alibaba Cloud Intelligence
This article is compiled from "Serverless Technology Open Course"
Introduction : This lesson mainly introduces how to run Spark data calculation at low cost in a Serverless Kubernetes cluster. First, briefly introduce the two products of Alibaba Cloud Serverless Kubernetes and Elastic Container Instance ECI; then introduce Spark on Kubernetes; finally, give a practical demonstration.
product description
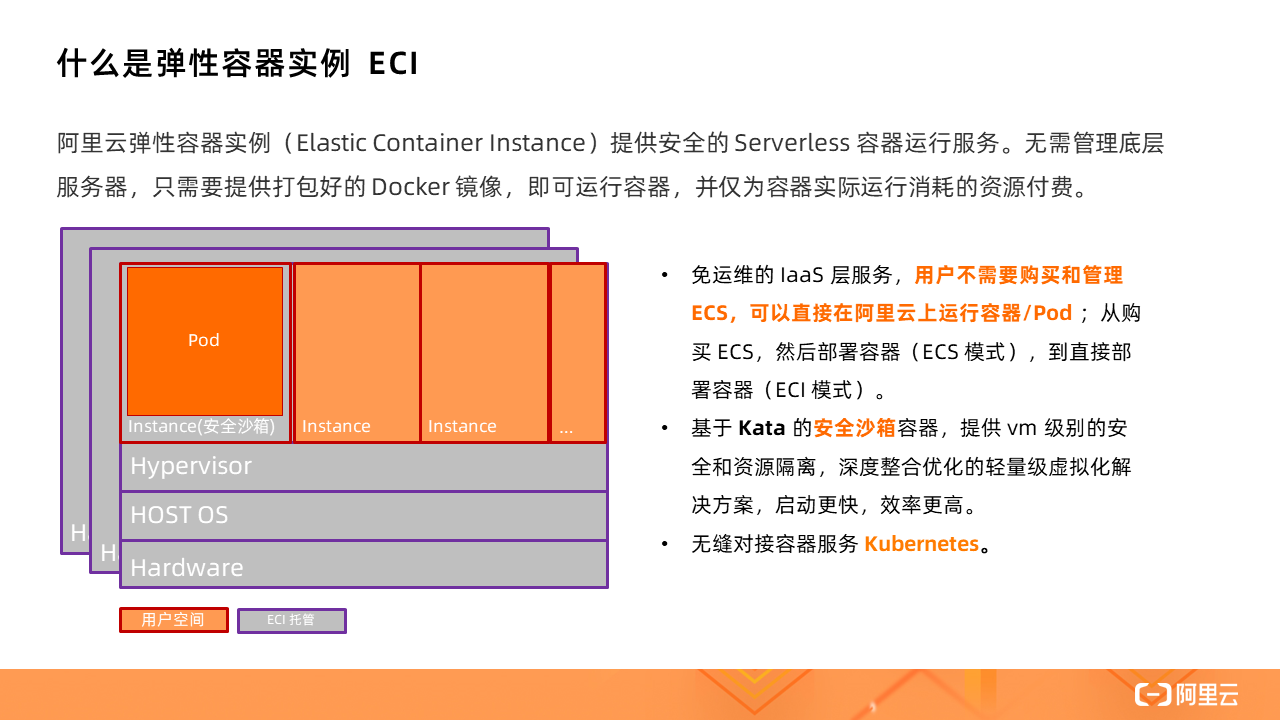
Alibaba Cloud Elastic Container Instance ECI
ECI provides secure serverless container operation services. There is no need to manage the underlying server. You only need to provide a packaged Docker image to run the container and only pay for the resources consumed by the actual operation of the container.
Alibaba Cloud Container Service Product Family
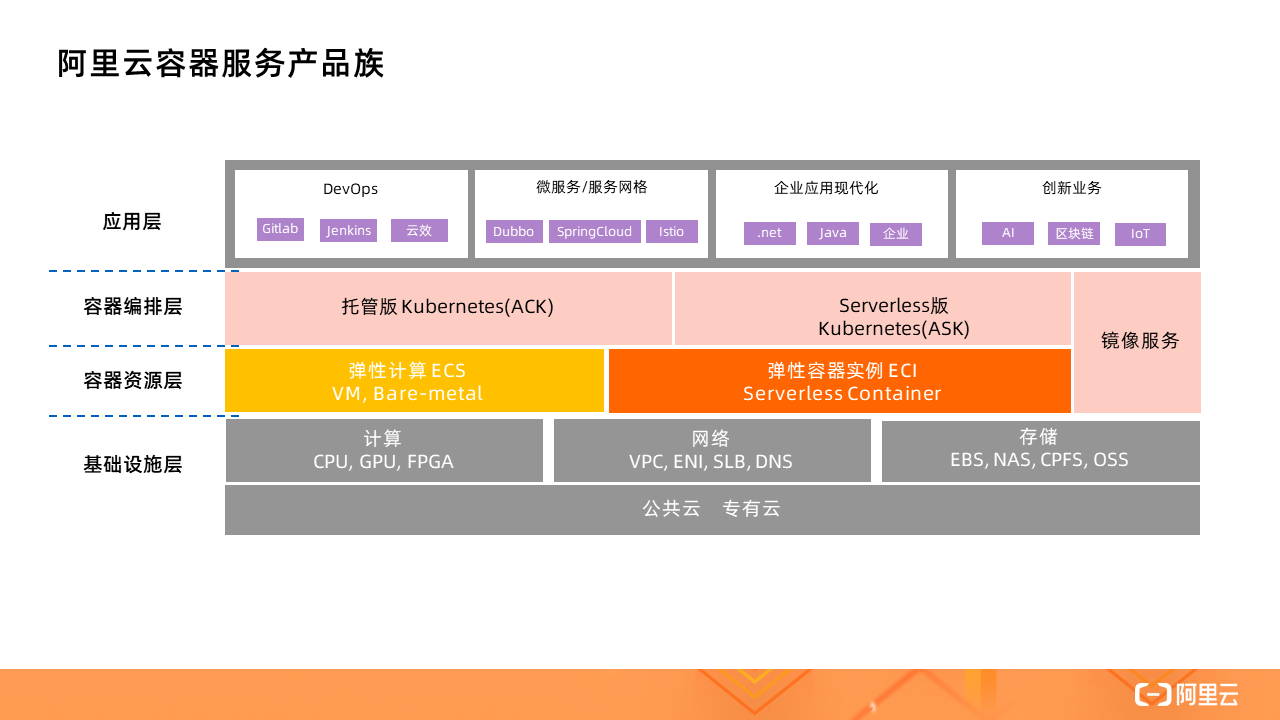
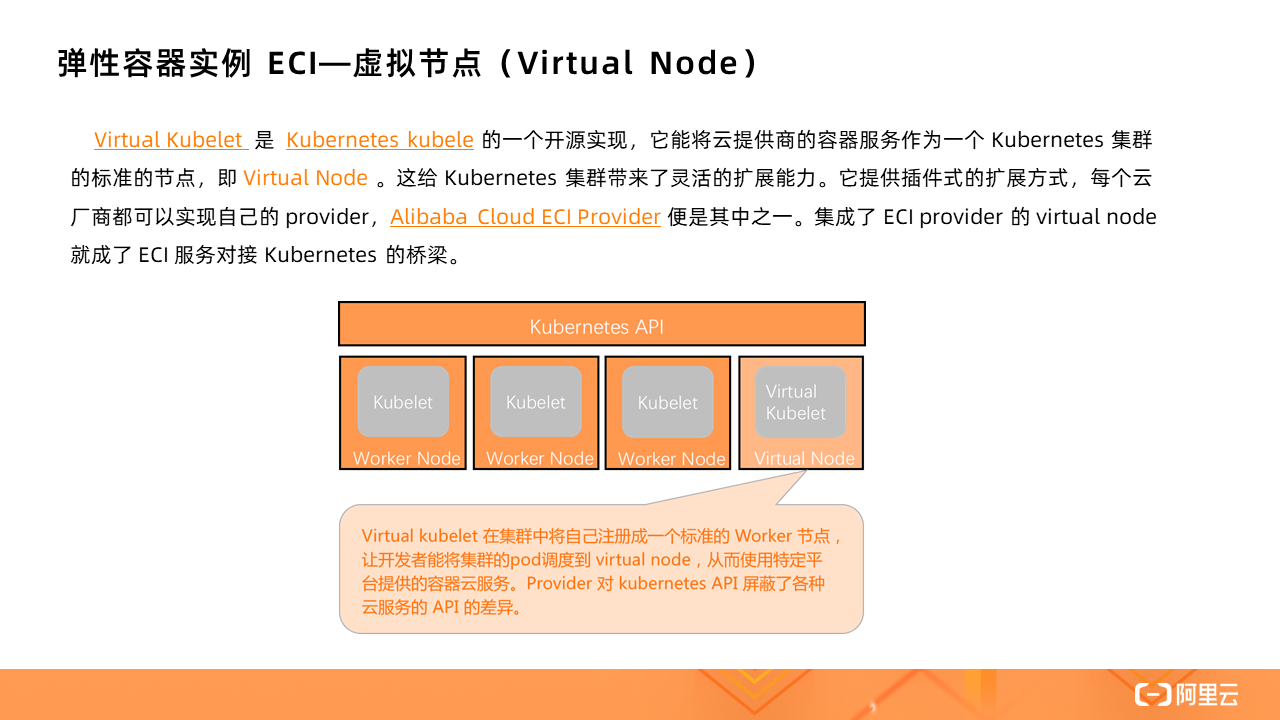
Whether it is the hosted version of Kubernetes (ACK) or the serverless version of Kubernetes (ASK), ECI can be used as the container resource layer. The implementation behind it is to use virtual node technology to connect to ECI through a virtual node called Virtual Node.
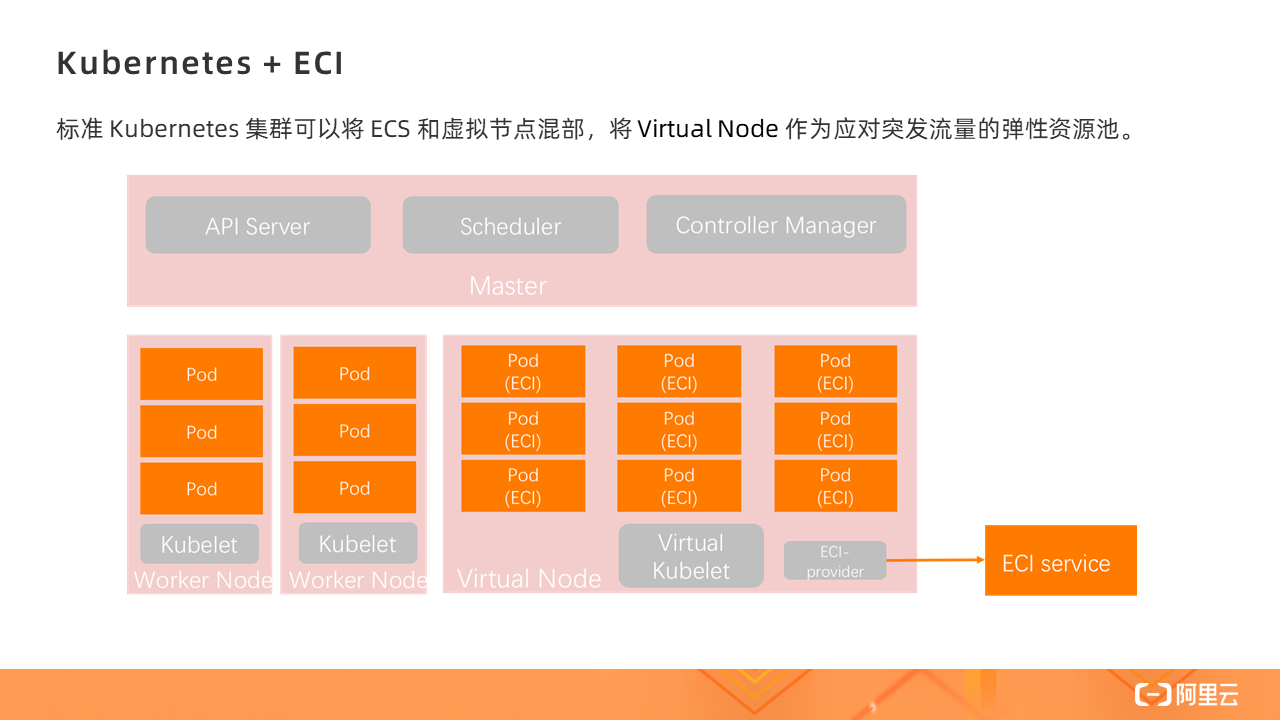
Kubernetes + ECI
With Virtual Kubelet, a standard Kubernetes cluster can mix ECS and virtual nodes, and use Virtual Node as an elastic resource pool for sudden traffic.
ASK(Serverless Kubernetes)+ ECI
There is no ECS worker node in the serverless cluster, and there is no need to reserve or plan resources. There is only one Virtual Node. All Pods are created on the Virtual Node, that is, based on ECI instances.
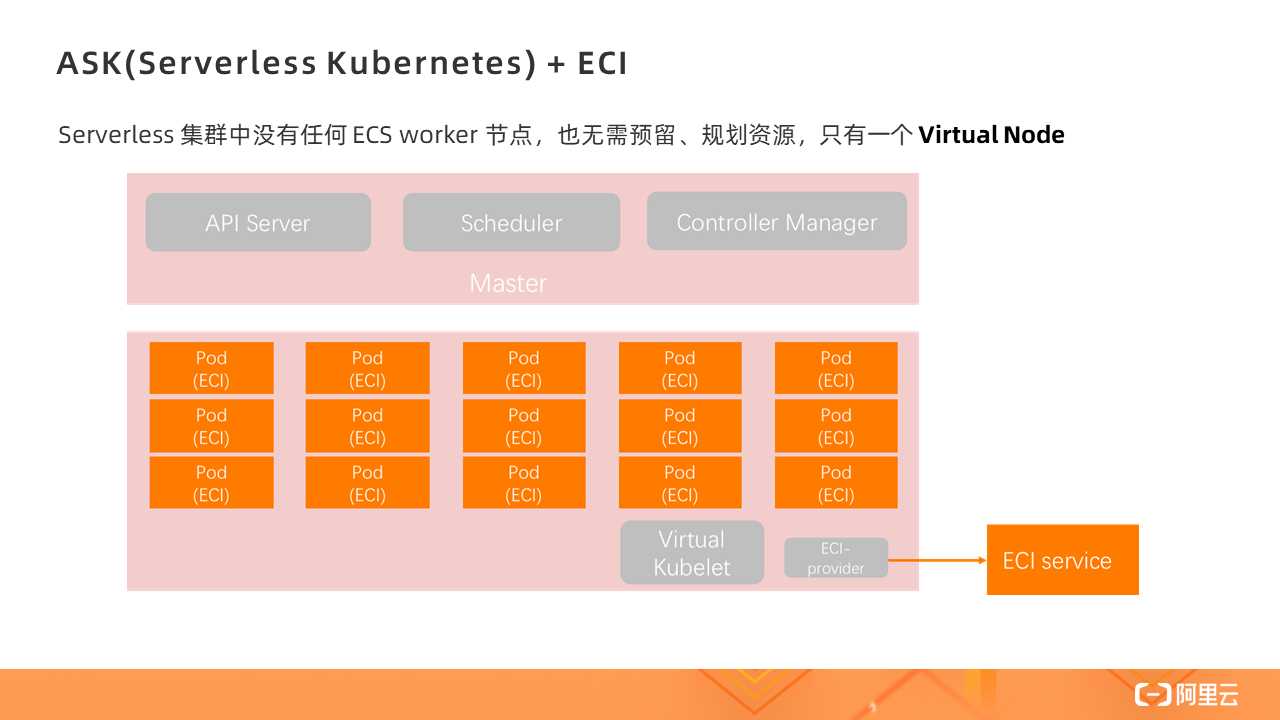
Serverless Kubernetes is a serverless service based on containers and Kubernetes. It provides a simple, easy-to-use, extremely flexible, optimal cost, and pay-as-you-go Kubernetes container service. There is no need for node management, operation and maintenance, and no capacity planning. Users pay more attention to application rather than infrastructure management.
Spark is in the Governors
Spark has experimentally supported new deployment methods other than Standalone, on YARN, and on Mesos since 2.3.0: Running Spark on Kubernetes . Now the support is very mature.
The advantages of Kubernetes
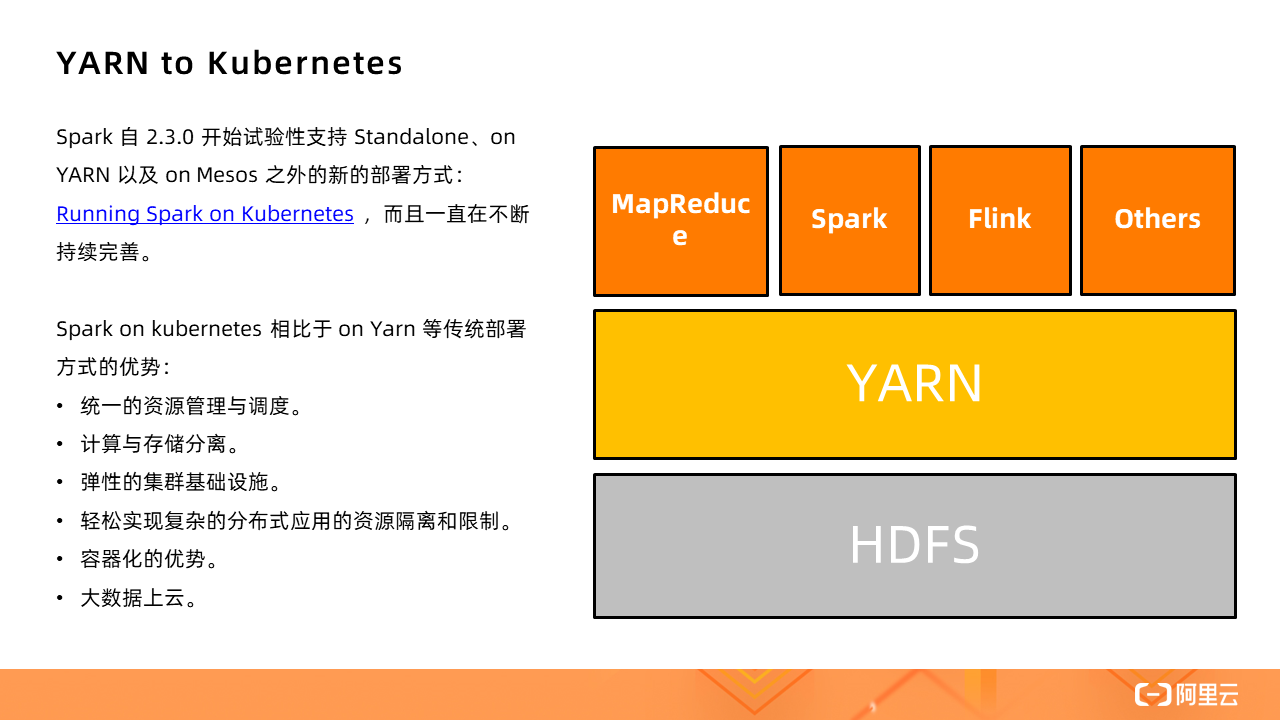
The advantages of Spark on kubernetes over traditional deployment methods such as on Yarn:
1. Unified resource management. No matter what type of job it is, it can be run in a unified Kubernetes cluster, and it is no longer necessary to maintain a separate YARN cluster for big data jobs.
2. The traditional hybrid deployment of computing and storage often brings additional computing expansion for storage expansion, which is actually a waste; for the same reason, just to improve computing power will also cause a period of storage waste. Kubernetes directly jumped out of storage limitations, separating the calculation and storage of offline computing, which can better deal with unilateral deficiencies.
3. Flexible cluster infrastructure.
4. Easily realize resource isolation and restriction of complex distributed applications, free from YRAN's complex queue management and queue allocation.
5. Advantages of containerization. Each application can package its own dependencies through Docker images and run in an independent environment, even including the Spark version. All applications are completely isolated.
6. Big data goes to the cloud. There are currently two common ways for big data applications to go to the cloud: 1) Use ECS to build your own YARN (not limited to YARN) cluster; 2) Purchase EMR services. All cloud vendors currently have this type of PaaS, and now there is one more choice—— Kubernetes.
Spark scheduling
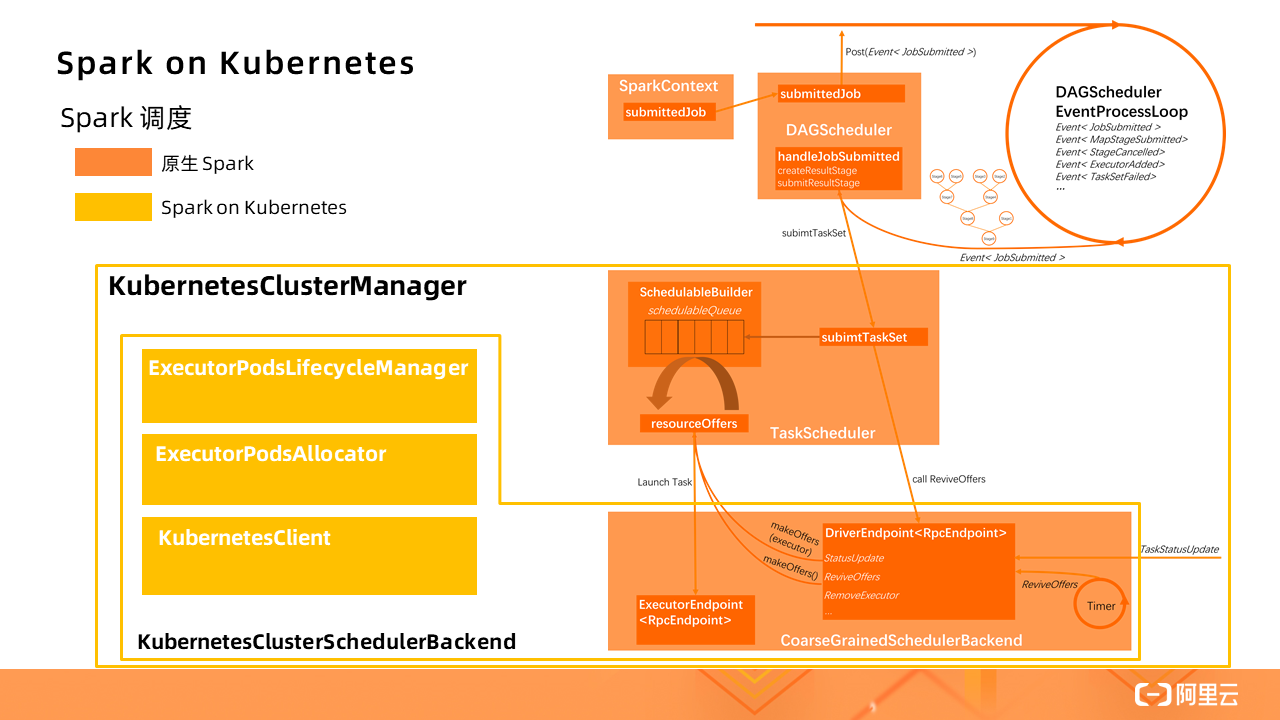
The orange part in the figure is the native Spark application scheduling process, and Spark on Kubernetes has made a certain extension (yellow part) to implement a KubernetesClusterManager . Which KubernetesClusterSchedulerBackend extends the native CoarseGrainedSchedulerBackend, added ExecutorPodsLifecycleManager, ExecutorPodsAllocator and KubernetesClient and other components to achieve the conversion process into the standard Spark Driver Kubernetes of Pod management.
Spark submit
Before the appearance of Spark Operator, the only way to submit Spark jobs in the Kubernetes cluster was through Spark submit. After creating a Kubernetes cluster, you can submit jobs locally.
The basic process of job start:
1. Spark first creates a Spark Driver (pod) in the K8s cluster.
2. After the Driver gets up, it calls the K8s API to create Executors (pods), and Executors is the carrier for executing the job.
3. After the job calculation is over, the Executor Pods will be automatically recycled, and the Driver Pod is in the Completed state (final state). Can be used for users to view logs, etc.
4. The Driver Pod can only be manually cleaned up by the user or recycled by the K8s GC.
Directly through this method of Spark submit, the parameters are very difficult to maintain and not intuitive enough, especially when custom parameters are increased; in addition, there is no concept of Spark Application, which are scattered Kubernetes Pod and Service, these basic units , When the number of applications increases, maintenance costs increase, and there is a lack of a unified management mechanism.
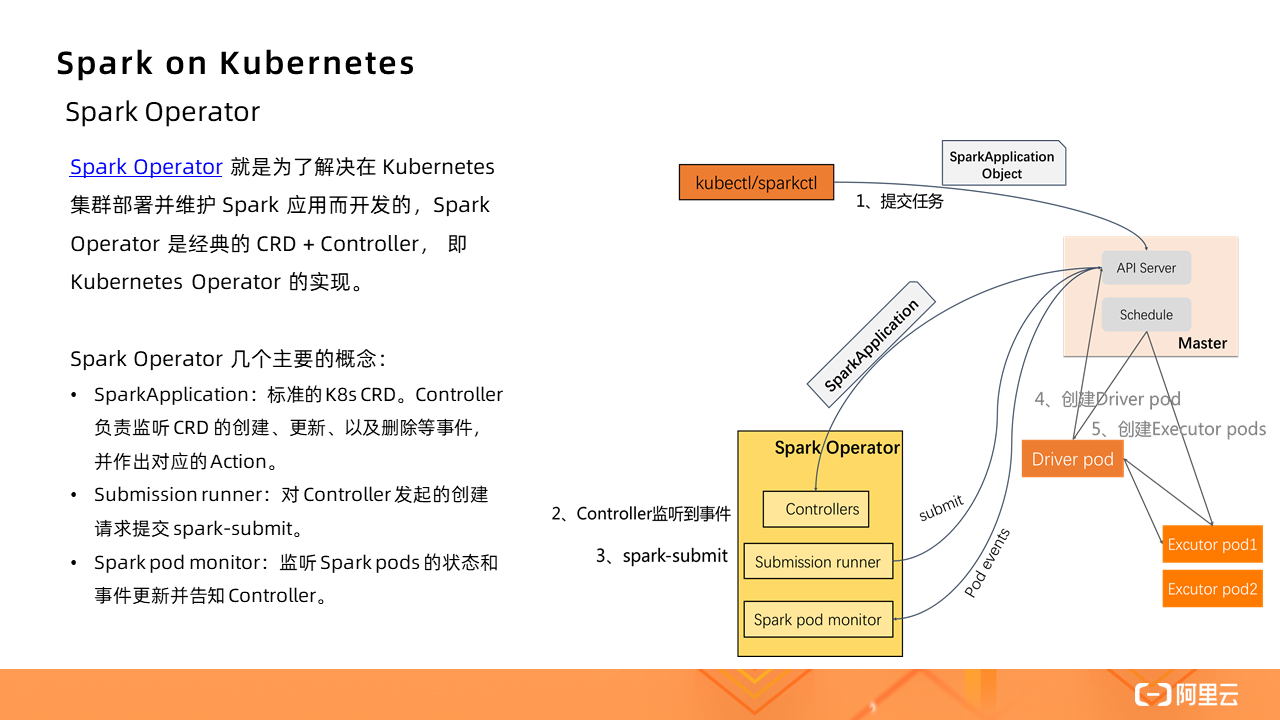
Spark Operator
Spark Operator was developed to solve the problem of deploying and maintaining Spark applications in a Kubernetes cluster. Spark Operator is the classic CRD + Controller, which is the implementation of Kubernetes Operator.
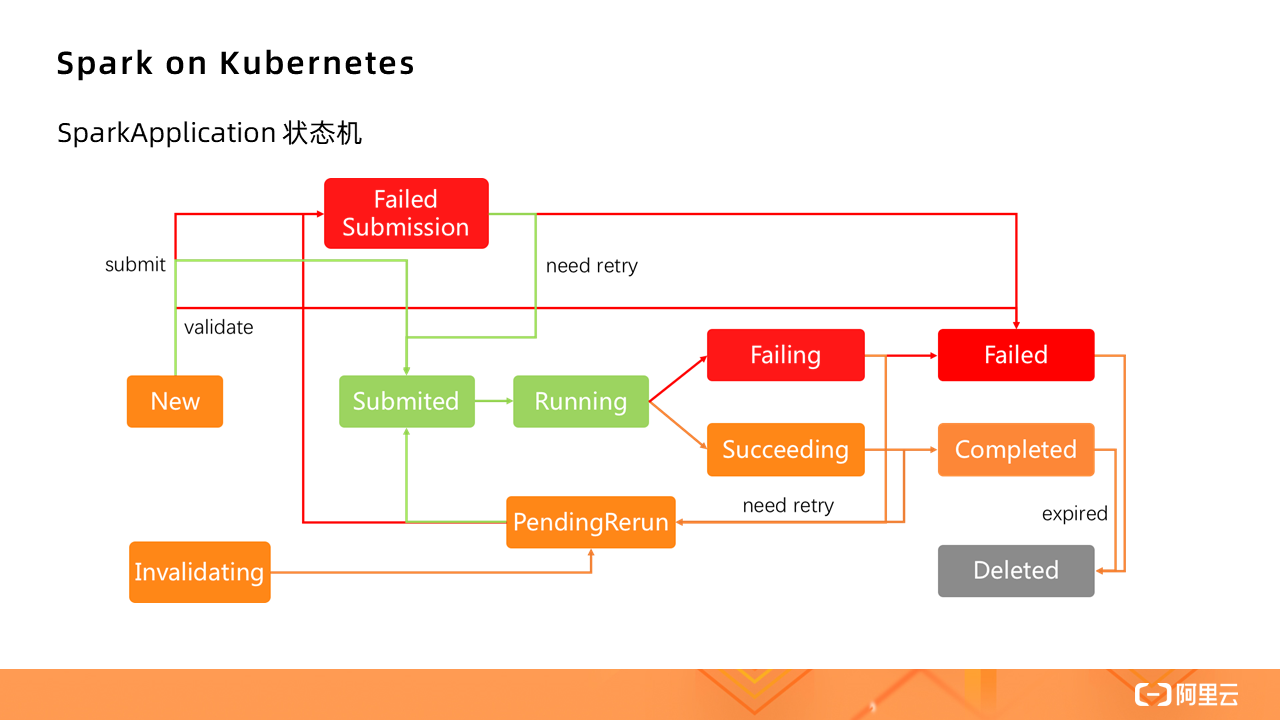
The following figure shows the SparkApplication state machine:
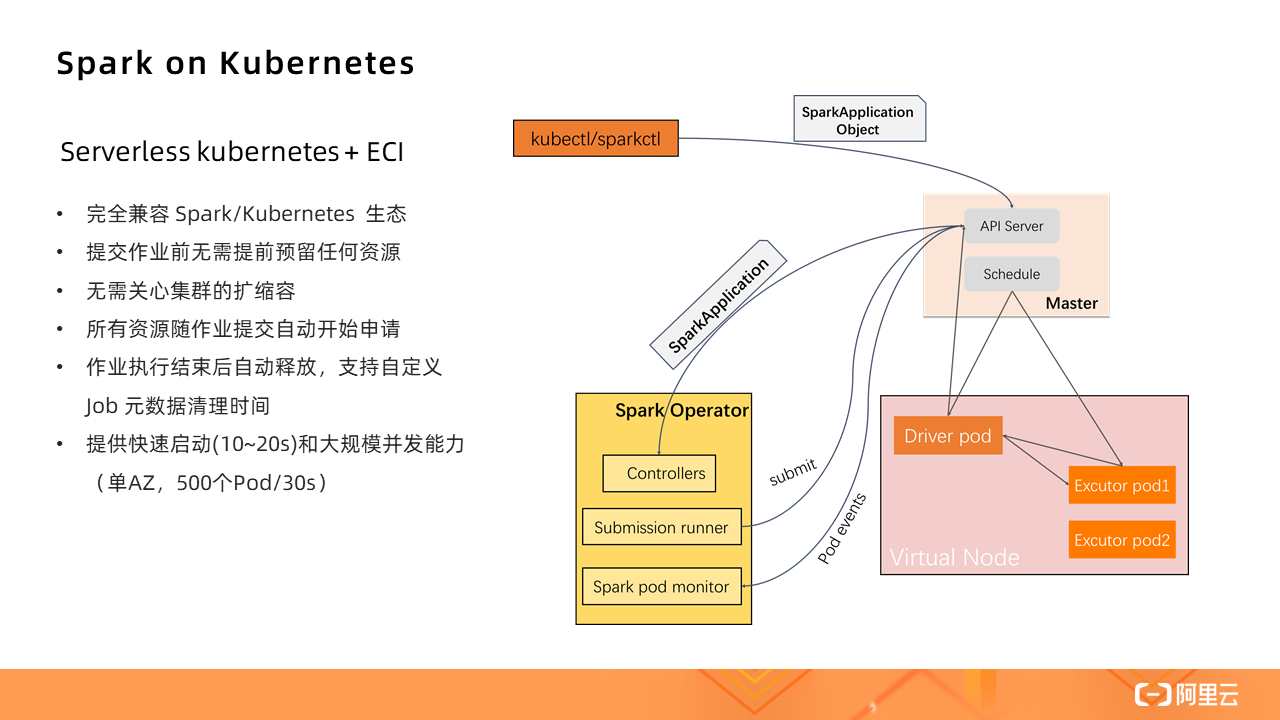
Serverless Kubernetes + ECI
So, if you run Spark in a Serverless Kubernetes cluster, it is actually a further streamlining of native Spark.
Storage options
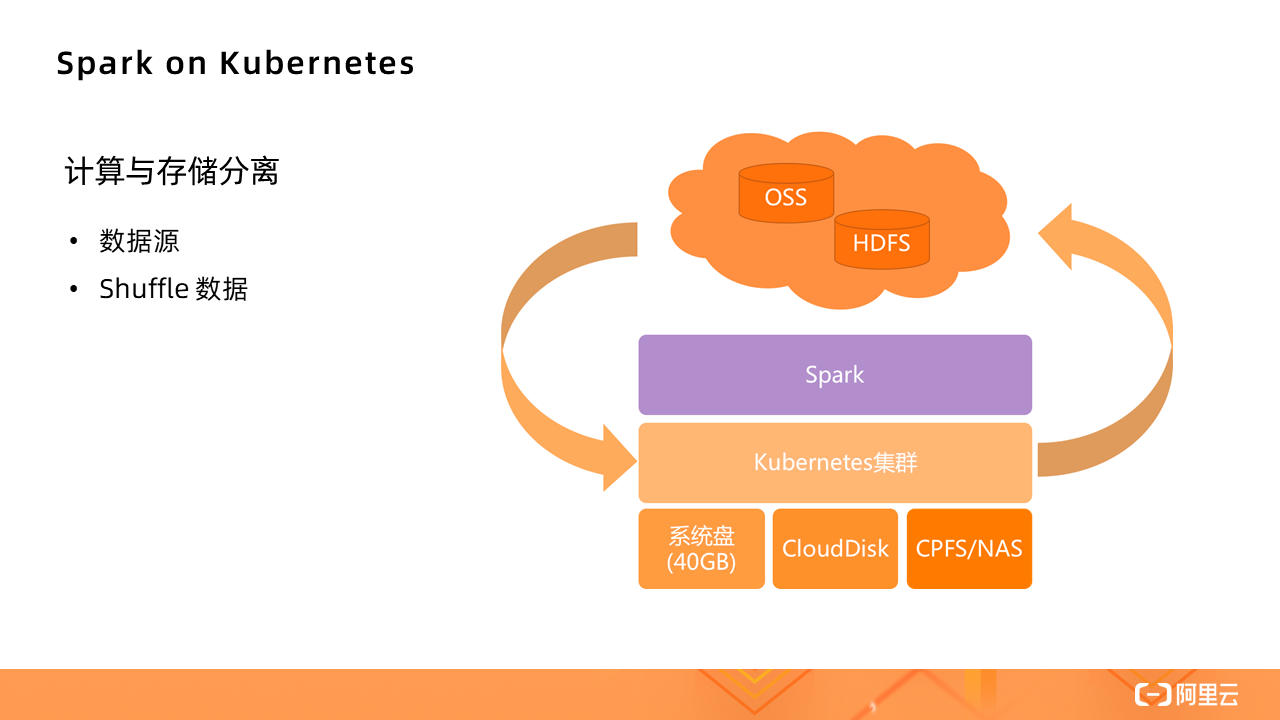
For batch-processed data sources, since the cluster is not based on HDFS, the data sources will be different, and computing and storage need to be separated. The Kubernetes cluster is only responsible for providing computing resources.
- The storage of data sources can use Alibaba Cloud Object Storage OSS, Alibaba Cloud Distributed Storage HDFS, etc.
- The calculated temporary data and Shuffle data can use the free 40GB system disk storage space provided by ECI, and can also customize the mounting of Alibaba Cloud data disks and CPFS/NAS file systems, etc., all have very good performance.
Practical demonstration
This actual operation shows two applications, TPC-DS and WordCount, respectively, click to watch the specific operation demonstration process
The Serverless official account releases the latest information on Serverless technology, gathers the most complete content of Serverless technology, pays attention to the trend of Serverless, and pays more attention to the confusion and problems you encounter in your practice.