
Jeder ist herzlich willkommen, uns auf GitHub zu markieren:
Verteiltes Volllink-Kausallernsystem OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Großer modellgesteuerter Wissensgraph OpenSPG: https://github.com/OpenSPG/openspg
Groß angelegtes Graphenlernsystem OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
In weniger als fünf Jahren hat die Großmodell- und Transformer-Technologie den Bereich der Verarbeitung natürlicher Sprache fast vollständig verändert und begonnen, Bereiche wie Computer Vision und Computational Biology zu revolutionieren. Dr. Sebastian Raschka konzentriert sich auf wissenschaftliche Forschungsarbeiten und hat eine einführende Leseliste für Forscher und Praktiker des maschinellen Lernens erstellt. Nachdem Sie sie der Reihe nach gelesen haben, können Sie in das aktuelle Gebiet der Großmodelltechnologie richtig einsteigen.
Natürlich erwähnte Dr. Sebastian Raschka auch, dass es noch viele weitere hilfreiche Ressourcen gibt, wie zum Beispiel:
- Jay Alammar: „Illustrated Transformer“;
- Weitere technische Blogbeiträge von Lilian Weng;
- Alle Kataloge und Genealogie der Transformers, zusammengestellt von Xavier Amatriain;
- Eine Minimalcode-Implementierung eines generativen Sprachmodells, das von Andrej Karpathy für Bildungszwecke geschrieben wurde;
- sowie eine Vorlesungsreihe und ein Buchkapitel des Autors dieses Artikels.
Verstehen Sie die Hauptarchitektur und Aufgaben
Wenn Sie neu bei Transformers/großen Modellen sind, ist es am sinnvollsten, bei Null anzufangen.
1. Neuronale maschinelle Übersetzung durch gemeinsames Lernen zum Ausrichten und Übersetzen (2014)
Autor: Bahdanau, Cho Wa Bengio
Link zum Papier: https://arxiv.org/abs/1409.0473
Wenn Sie ein paar Minuten Zeit haben, empfehle ich Ihnen, mit diesem Dokument zu beginnen. In diesem Artikel wird ein Aufmerksamkeitsmechanismus für wiederkehrende neuronale Netze (RNN) vorgestellt, um die Modellierungsfähigkeiten langer Sequenzen zu verbessern. Dadurch können RNNs längere Sätze genauer übersetzen – was die Motivation für die Entwicklung der ursprünglichen Transformer-Architektur war.
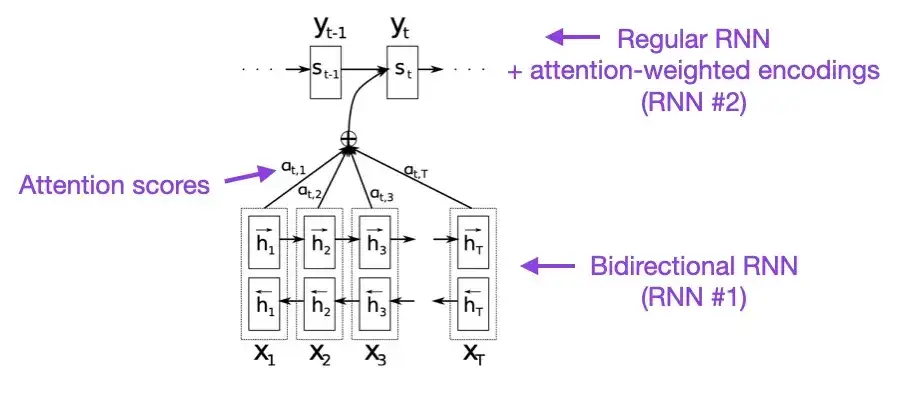
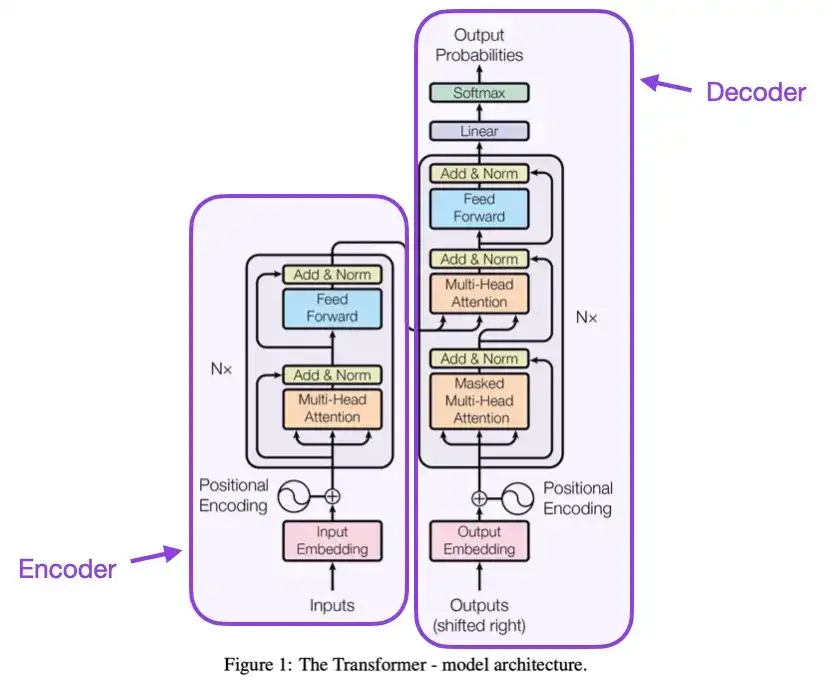
2. Aufmerksamkeit ist alles, was Sie brauchen (2017)
Credits: Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser und Polosukhin
Link zum Papier: https://arxiv.org/abs/1706.03762
In diesem Artikel wird die ursprüngliche Transformer-Architektur vorgestellt, die aus zwei Teilen besteht: einem Encoder und einem Decoder. Diese beiden Teile werden später zur Erläuterung zu unabhängigen Modulen. Darüber hinaus wurden in diesem Artikel auch Konzepte wie Skalierungs-Punktprodukt-Aufmerksamkeitsmechanismen, Mehrkopf-Aufmerksamkeitsblöcke und Positionseingabekodierung vorgestellt, die immer noch die Grundlage moderner Transformer-Modelle bilden.
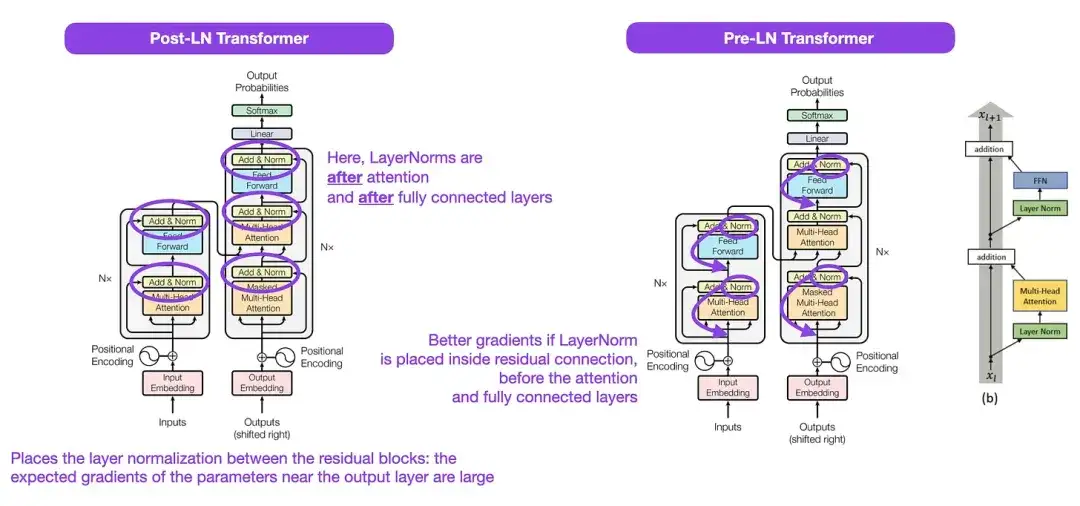
3. Zur Layer-Normalisierung in der Transformer-Architektur __ (2020)
Autoren: Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
Link zum Papier: https://arxiv.org/abs/2002.04745
Obwohl die in der Abbildung oben gezeigte ursprüngliche Transformer-Struktur eine sehr gute Zusammenfassung der ursprünglichen Encoder-Decoder-Architektur darstellt, war die Position von LayerNorm in der Abbildung umstritten. Beispielsweise platziert das Transformer-Strukturdiagramm in „Attention Is All You Need“ LayerNorm zwischen Restblöcken, was nicht mit der offiziellen (aktualisierten) Codeimplementierung übereinstimmt, die dem ursprünglichen Transformer-Papier beiliegt. Die im Bild von „Attention Is All You Need“ gezeigte Variante heißt Post-LN Transformer und die aktualisierte Codeimplementierung verwendet standardmäßig die Pre-LN-Variante.
Im Artikel „Layer Normalization in the Transformer Architecture“ wird darauf hingewiesen, dass Pre-LN besser funktioniert und das Gradientenproblem lösen kann. Wie unten gezeigt, übernehmen viele Architekturen diesen Ansatz in der Praxis, er kann jedoch zum Zusammenbruch der Darstellung führen. Während die Diskussion darüber, ob Post-LN oder Pre-LN verwendet werden soll, weitergeht, schlägt daher ein neues Papier „ResiDual: Transformer with Dual Residual Connections“ ( https://arxiv.org/abs/2304.14802 ) vor, beide Vorteile zu nutzen; Die Wirksamkeit in der Praxis bleibt abzuwarten.
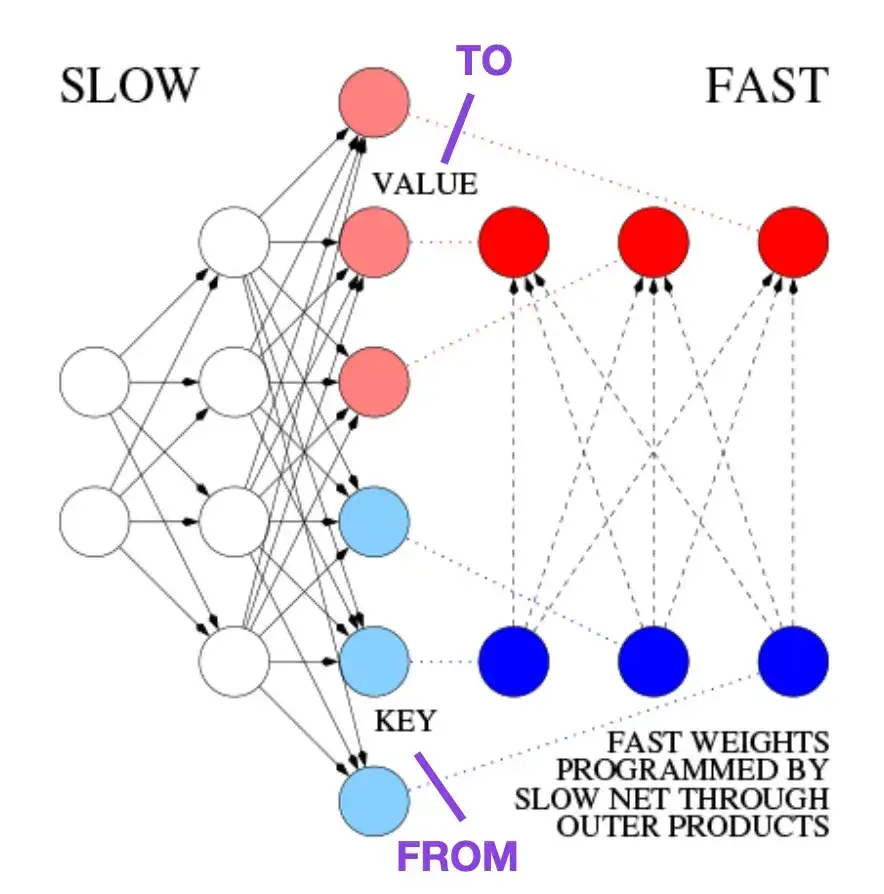
4. Lernen, schnelle Erinnerungen zu kontrollieren: Eine Alternative zu dynamischen wiederkehrenden neuronalen Netzen __ (1991)
Autor: Schmidhuber
Papierlink:
Dieses Papier wird Lesern empfohlen, die sich für historische Anekdoten und frühe Technologien ähnlich der modernen Transformer-Architektur interessieren. Beispielsweise schlug Jürgen Schmidhuber 1991, etwa 25 Jahre vor dem ursprünglichen Transformer-Artikel Attention Is All You Need , einen Fast Weight Programmer (FWP) als Alternative zu rekurrenten neuronalen Netzen vor. Bei der FWP-Methode handelt es sich um ein vorwärtsgerichtetes neuronales Netzwerk, das langsam über einen Gradientenabstieg lernt, um die schnellen Gewichtsänderungen eines anderen neuronalen Netzwerks zu programmieren. Die Analogie zu einem modernen Transformer wird im folgenden Blogbeitrag erläutert:
In der heutigen Transformer-Terminologie werden FROM und TO als Schlüssel bzw. Werte bezeichnet. Die von schnellen Netzwerken verwendete EINGABE wird als Abfrage bezeichnet. Im Wesentlichen wird die Abfrage über eine schnelle Gewichtsmatrix verarbeitet, die die Summe der äußeren Produkte von Schlüsseln und Werten darstellt (Normalisierung und Projektion werden ignoriert). Da alle Operationen beider Netzwerke differenzierbar sind, erhalten wir durch die Addition äußerer Produkte oder Tensorprodukte zweiter Ordnung eine durchgängig differenzierbare aktive Kontrolle schneller Gewichtsänderungen. Daher kann das langsame Netzwerk durch Gradientenabstieg erlernt werden, wodurch das schnelle Netzwerk während der Sequenzverarbeitung schnell modifiziert wird. Dies ist mathematisch äquivalent (mit Ausnahme der Normalisierung) zu dem, was als linearer Selbstaufmerksamkeitstransformator (oder linearer Transformator) bekannt wurde.
Wie im Auszug aus dem Blogbeitrag oben erwähnt, ist dieser Ansatz mittlerweile als „Linear Transformer“ oder „Transformer mit linearisierter Selbstaufmerksamkeit“ bekannt. Anschließend wurde die Äquivalenz zwischen linearisierter Selbstaufmerksamkeit und den Fast-Weight-Programmierern der 1990er Jahre in der Arbeit „Linear Transformers Are Secretly Fast-Weight Programmers“ aus dem Jahr 2021 deutlich demonstriert.
5. Feinabstimmung des universellen Sprachmodells für die Textklassifizierung (2018)
Autor; Howard, Ruder
Papieradresse: https://arxiv.org/abs/1801.06146
Aus historischer Sicht ist dies ein sehr interessanter Artikel. Es wurde ein Jahr nach der Veröffentlichung von „Attention Is All You Need“ geschrieben, beinhaltete jedoch keinen Transformer, sondern konzentrierte sich auf wiederkehrende neuronale Netze. Es verdient jedoch dennoch Aufmerksamkeit, da es effektiv vorab trainierte Sprachmodelle vorschlägt und das Lernen für nachgelagerte Aufgaben überträgt. Obwohl Transferlernen im Bereich Computer Vision gut etabliert ist, hat es sich in der Verarbeitung natürlicher Sprache (NLP) noch nicht durchgesetzt. ULMFit ist eines der ersten Papiere, das vorab trainierte Sprachmodelle demonstriert und sie an bestimmte Aufgaben anpasst, was zu hochmodernen Ergebnissen bei vielen NLP-Aufgaben führt.
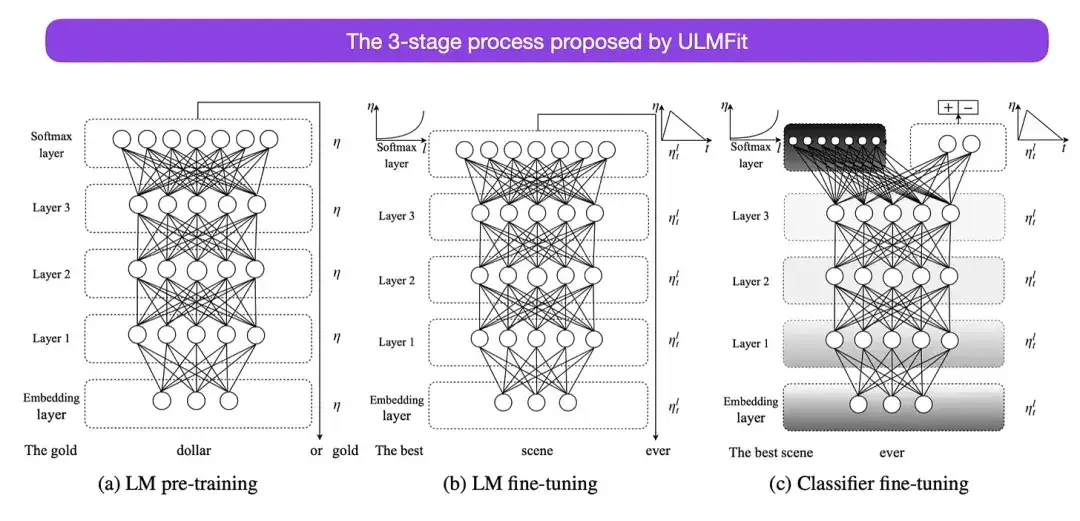
Der von ULMFit vorgeschlagene dreistufige Prozess zur Feinabstimmung von Sprachmodellen ist wie folgt:
- Trainieren Sie ein Sprachmodell auf einem großen Textkorpus.
- Optimieren Sie dieses vorab trainierte Sprachmodell anhand aufgabenspezifischer Daten, um es an den Stil und das Vokabular des spezifischen Textes anzupassen.
- Vermeiden Sie katastrophales Vergessen, indem Sie die Schichten schrittweise freigeben und gleichzeitig den Klassifikator auf aufgabenspezifische Daten abstimmen.
Diese Methode – zunächst das Trainieren eines Sprachmodells auf einem großen Korpus und dann die Feinabstimmung auf nachgelagerte Aufgaben – ist die Kernmethode transformatorbasierter Modelle und Basismodelle (wie BERT, GPT-2/3/4, RoBERTa, usw.). Der entscheidende Teil von ULMFit, das schrittweise Auftauen, wird jedoch normalerweise nicht routinemäßig beim tatsächlichen Betrieb der Konverterarchitektur durchgeführt, und normalerweise werden alle Schichten gleichzeitig feinabgestimmt.
6. BERT: Vorschulung tiefer bidirektionaler Transformatoren zum Sprachverständnis ****(2018)
Mitwirkende: Devlin, Chang, Lee, Toutanova
Link zum Papier: https://arxiv.org/abs/1810.04805
Gemäß der ursprünglichen Transformer-Architektur begann die Forschung an großen Sprachmodellen in zwei Richtungen zu divergieren: Encoder-basierte Transformer für prädiktive Modellierungsaufgaben (z. B. Textklassifizierung) und generative Modellierungsaufgaben (z. B. Übersetzung, Zusammenfassung und Decoder). Style Transformer für andere Texterstellungsformen).
Das oben erwähnte BERT-Papier führte die ursprünglichen Konzepte der maskierten Sprachmodellierung und der Vorhersage des nächsten Satzes ein und bleibt die einflussreichste Architektur im Encoder-Stil. Wenn Sie sich für diesen Forschungszweig interessieren, empfehle ich Ihnen, sich weiter über RoBERTa zu informieren, das das Ziel vor dem Training vereinfacht, indem die Aufgabe zur Vorhersage des nächsten Satzes entfernt wird.
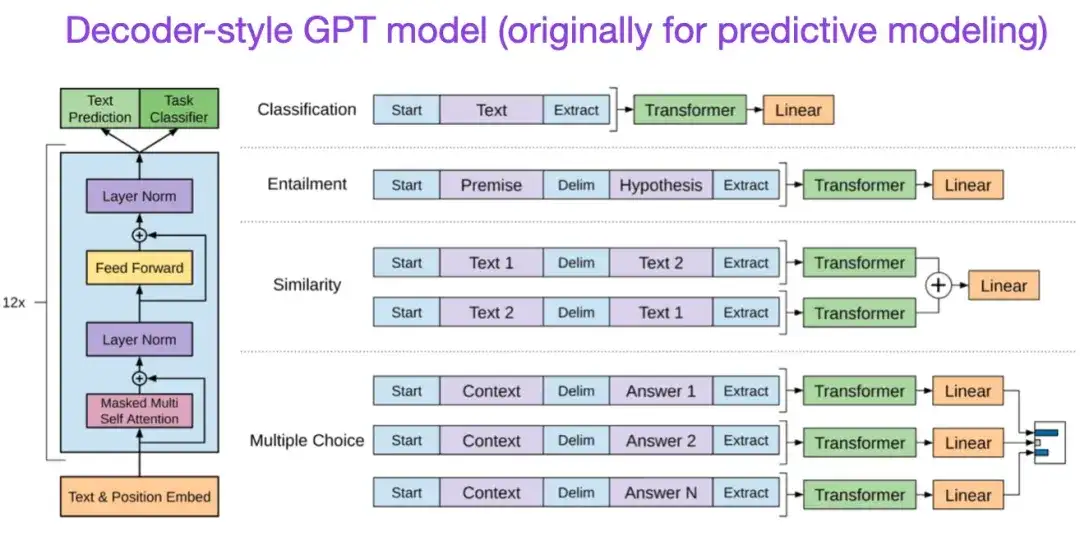
** 7. Verbesserung des Sprachverständnisses durch generatives Pre-Training (2018)** Autor: Radford und Narasimhan Adresse des Beitrags:
Das ursprüngliche GPT-Papier stellte die beliebte Architektur im Decoder-Stil und das Vortraining mittels Vorhersage des nächsten Wortes vor. Während BERT aufgrund seines maskierten Sprachmodells vor dem Training als bidirektionaler Transformator angesehen werden kann, ist GPT ein einseitiges, autoregressives Modell. Obwohl GPT-Einbettungen auch zur Klassifizierung verwendet werden können, bilden GPT-Methoden den Kern der heute einflussreichsten großen Sprachmodelle (LLMs) wie ChatGPT.
Wenn Sie an dieser Forschungsrichtung interessiert sind, empfehle ich Ihnen, weiterhin mehr über GPT-2- und GPT-3-bezogene Artikel zu erfahren. Diese beiden Papiere zeigen, dass LLMs Zero-Shot- und Few-Shot-Lernen erreichen können, und heben die neuen Fähigkeiten von LLMs hervor. GPT-3 ist immer noch die am häufigsten verwendete Basis und das Basismodell für das Training aktueller LLM. Die InstructGPT-Technologie, aus der ChatGPT hervorgegangen ist, wird später in einem separaten Eintrag vorgestellt.
GPT2-bezogene Artikel: https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
GPT3-bezogene Artikel: https://arxiv.org/abs/2005.14165
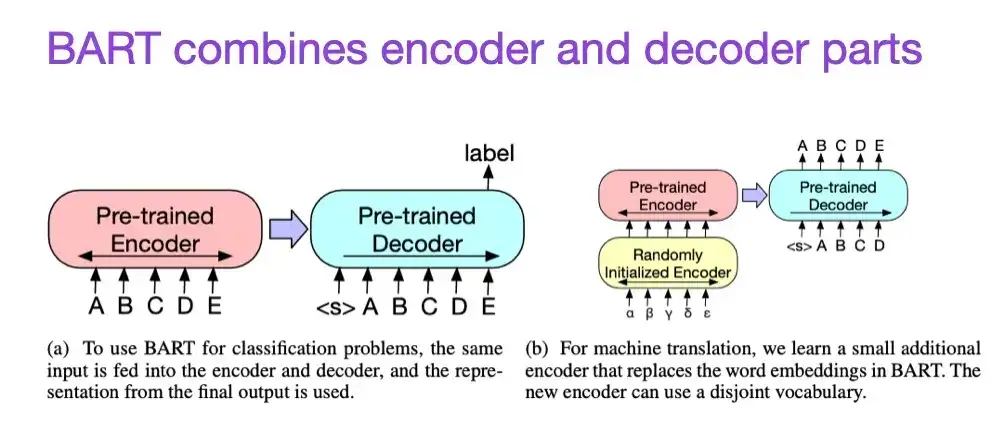
8. BART: Denoising Sequence-to-Sequence Pre-Training für die Erzeugung, Übersetzung und das Verständnis natürlicher Sprache (2019)
Mitwirkende: Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
Papierlink: https://arxiv.org/abs/1910.13461 .
Wie bereits erwähnt, eignen sich Large Language Models (LLMs) im Encoder-Stil vom BERT-Typ im Allgemeinen besser für prädiktive Modellierungsaufgaben, während LLMs im Decoder-Stil vom GPT-Typ besser für die Textgenerierung geeignet sind. Um das Beste aus beiden Welten zu kombinieren, kombiniert das oben erwähnte BART-Papier die Encoder- und Decoder-Teile (ähnlich der ursprünglichen Transformer-Struktur, die im zweiten Papier vorgestellt wurde).
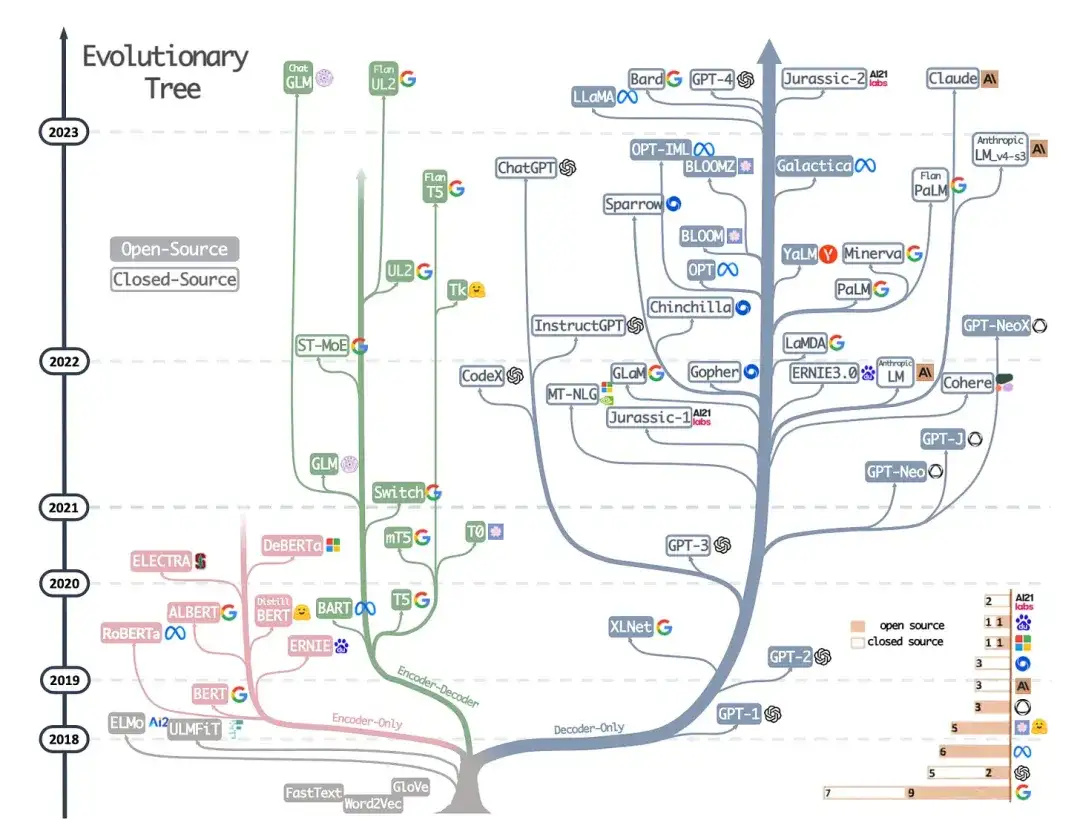
9. Die Leistungsfähigkeit von LLMs in der Praxis nutzen: Eine Umfrage zu ChatGPT und darüber hinaus (2023)
Autor: Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
Link zum Papier: https://arxiv.org/abs/2304.13712
Dies ist kein Forschungsbericht, aber es ist wahrscheinlich der bisher beste Architektur-Überblicksartikel und er zeigt anschaulich, wie sich verschiedene Architekturen entwickelt haben. Neben der Erörterung maskierter Sprachmodelle (Encoder) im BERT-Stil und autoregressiven Sprachmodellen (Decoder) im GPT-Stil bietet es jedoch auch hilfreiche Diskussionen und Anleitungen zum Vortraining und zur Feinabstimmung von Daten.
Gesetze skalieren und die Effizienz verbessern
Wenn Sie mehr über verschiedene Techniken zur Verbesserung der Transformatoreffizienz erfahren möchten, empfehle ich die Lektüre des Papiers „Efficient Transformers: A Survey“ aus dem Jahr 2020 und des Papiers „A Survey on Efficient Training of Transformers“ aus dem Jahr 2023. Darüber hinaus finden Sie hier einige Artikel, die ich besonders interessant und lesenswert fand.
- „Effiziente Transformatoren: Eine Umfrage“:
https://arxiv.org/abs/2009.06732
- „Eine Umfrage zum effizienten Training von Transformatoren“:
https://arxiv.org/abs/2302.01107
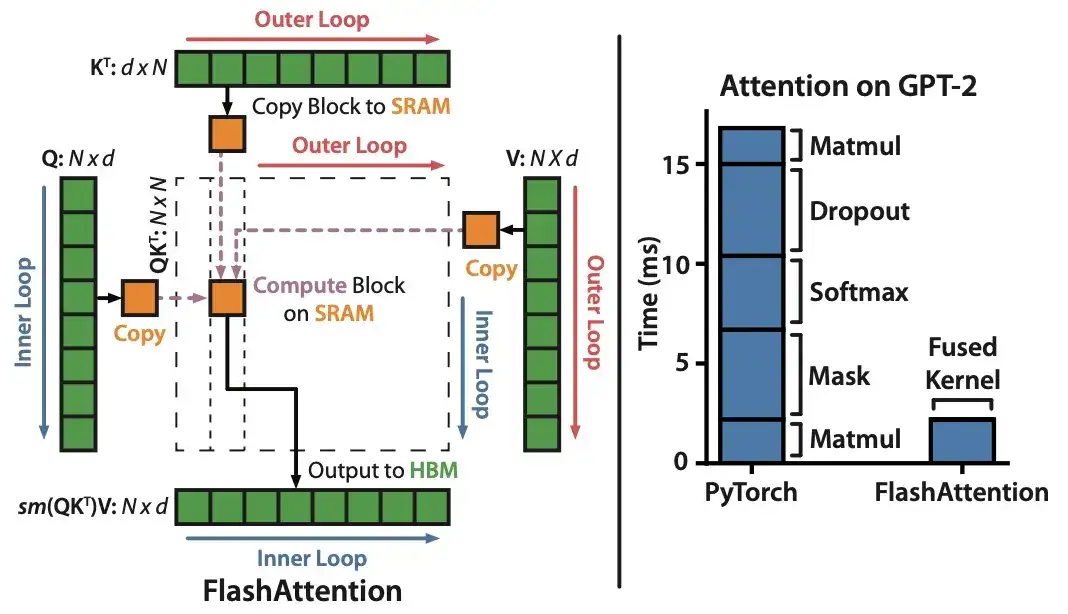
10. FlashAttention: Schnelle und speichereffiziente exakte Aufmerksamkeit mit IO-Awareness (2022)
Autor: Dao, Fu, Ermon, Rudra, Ré
Papierlink: https://arxiv.org/abs/2205.14135 .
Obwohl sich die meisten Transformer-Artikel nicht die Mühe machen, den ursprünglichen skalierten Punktproduktmechanismus zu ersetzen, um Selbstaufmerksamkeit zu erreichen, ist FlashAttention der einzige Mechanismus, der mir zuletzt zitiert wurde.
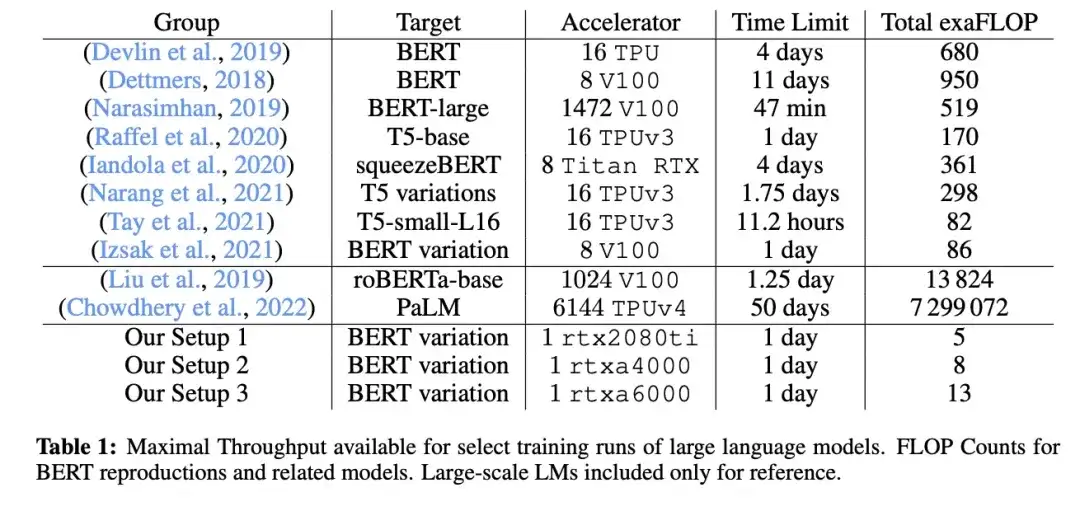
11. Cramming: Ein Sprachmodell auf einer einzelnen GPU an einem Tag trainieren (2022)
_Autor:_Geiping und Goldstein,
Link zum Papier: https://arxiv.org/abs/2212.14034
In diesem Artikel verwendeten Forscher eine einzelne GPU, um ein großes Sprachmodell im maskierten Sprachmodell/Encoder-Stil (hier BERT) 24 Stunden lang zu trainieren. Zum Vergleich: Das ursprüngliche BERT-Papier aus dem Jahr 2018 wurde vier Tage lang an 16 TPUs trainiert. Ein interessantes Ergebnis ist, dass kleinere Modelle zwar einen höheren Durchsatz haben, aber auch weniger effizient lernen. Daher erfordern größere Modelle keine längeren Trainingszeiten, um einen bestimmten Schwellenwert für die Vorhersageleistung zu erreichen.
12. LoRA: Low-Rank-Anpassung großer Sprachmodelle (2021)
Autor: von Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen
Papierlink: https://arxiv.org/abs/2106.09685 .
Moderne groß angelegte Sprachmodelle weisen durch Vortraining an großen Datensätzen neue Fähigkeiten auf und eignen sich gut für eine Vielzahl von Aufgaben, darunter Sprachübersetzung, Zusammenfassungserstellung, Programmierung und Beantwortung von Fragen. Es ist jedoch sinnvoll, einen Transformator fein abzustimmen, um seine Fähigkeiten für domänenspezifische Daten und spezielle Aufgaben zu verbessern. Die Low-Rank-Adaption (LoRA) ist eine der einflussreichsten Methoden zur parametereffizienten Feinabstimmung großer Sprachmodelle.
Obwohl es andere Methoden zur effizienten Feinabstimmung von Parametern gibt, verdient LoRA besondere Aufmerksamkeit, da es sowohl elegant als auch sehr allgemein ist und auf andere Modelltypen angewendet werden kann. Die Gewichte eines vorab trainierten Modells haben den vollen Rang für die Aufgabe, für die sie vorab trainiert wurden, wohingegen die Autoren von LoRA anmerken, dass große Sprachmodelle eine geringere „intrinsische Dimensionalität“ aufweisen, wenn sie an neue Aufgaben angepasst werden. Daher besteht die Kernidee von LoRA darin, die Gewichtsänderung ΔW in Darstellungen mit niedrigerem Rang zu zerlegen, um eine höhere Parametereffizienz zu erreichen.

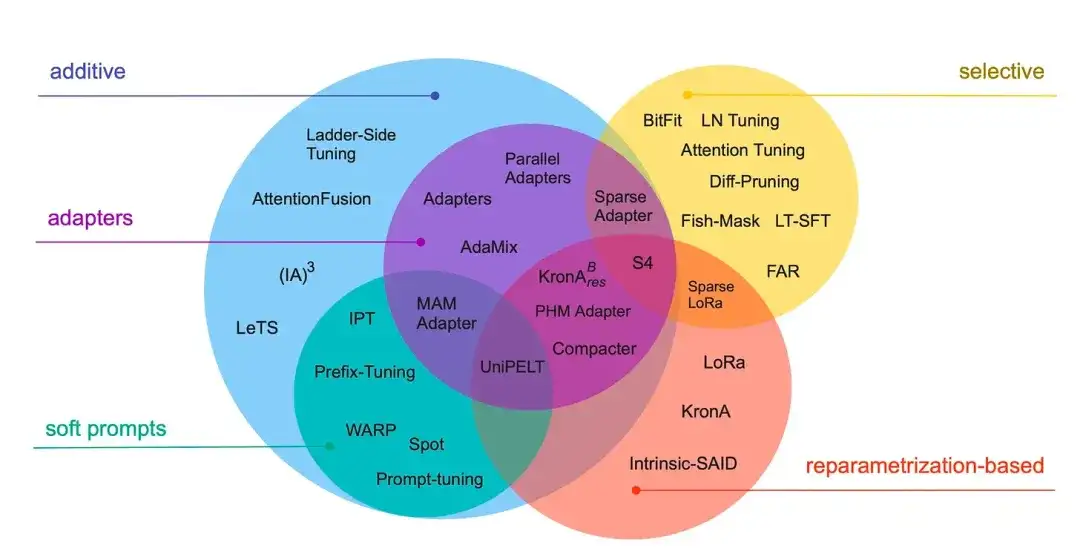
13_. Von unten nach oben skalieren: Ein Leitfaden zur parametereffizienten Feinabstimmung (2022)_
Autor: Lialin, Deshpande, Rumshisky
Papierlink: https://arxiv.org/abs/2303.15647 .
In dieser Rezension werden mehr als 40 Artikel zu effizienten Parameter-Feinabstimmungsmethoden überprüft (die gängige Techniken wie Präfixanpassung, Adapter und Low-Rank-Anpassung abdecken) mit dem Ziel, den Feinabstimmungsprozess (extrem) recheneffizient zu gestalten.
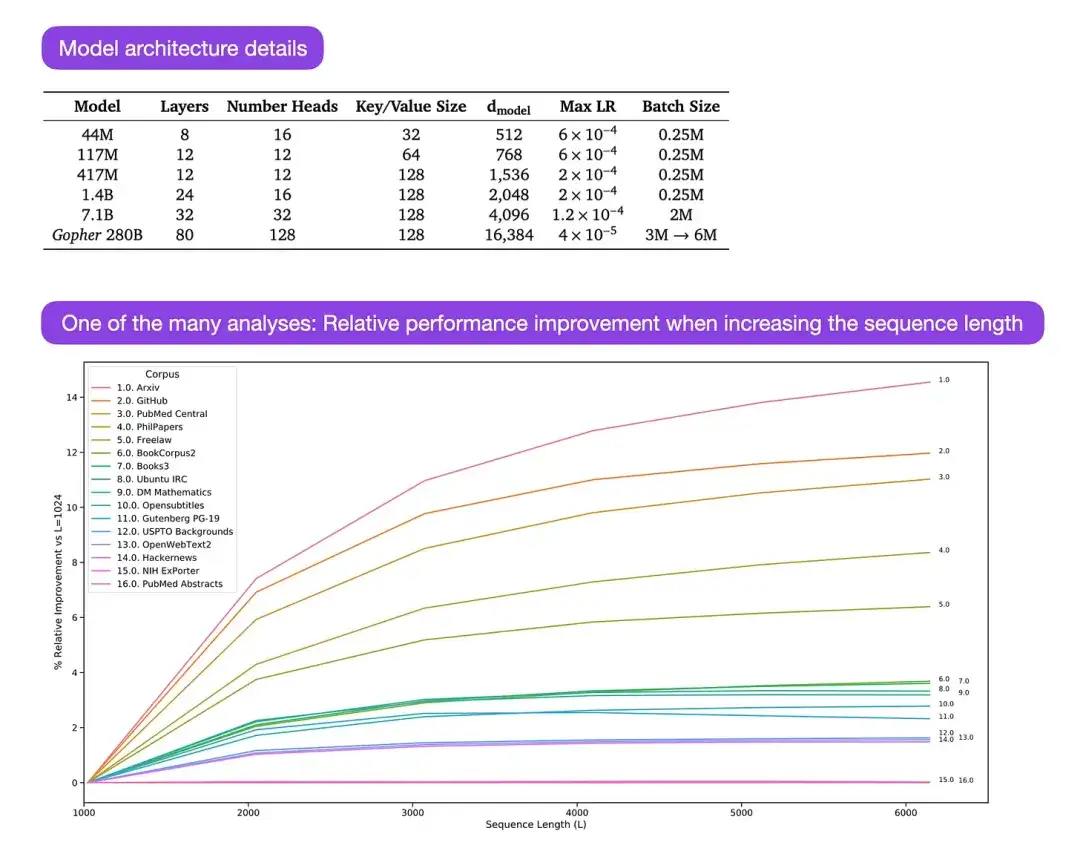
** 14. Skalierende Sprachmodelle: Methoden, Analysen und Erkenntnisse aus Training Gopher (2022)** Autor: Rae und 78 Kollegen
Link zum Papier: https://arxiv.org/abs/2112.11446
Gopher ist ein besonders gutes Papier, das viele Analysen enthält, um den Trainingsprozess großer Sprachmodelle (LLM) zu verstehen. Der Forscher trainierte hier ein Modell mit 280B Parametern und 80 Schichten. Das Modell wurde auf Basis von 300B Token trainiert. Es enthält einige interessante architektonische Verbesserungen, wie z. B. die Verwendung von RMSNorm (Root Mean Square Normalization) anstelle von LayerNorm (Layer Normalization). Sowohl LayerNorm als auch RMSNorm werden gegenüber BatchNorm bevorzugt, da sie nicht von der Stapelgröße abhängen und keine Synchronisierung erfordern, was besonders bei der Verwendung kleinerer Stapel in verteilten Umgebungen von Vorteil ist. Es wird jedoch allgemein angenommen, dass RMSNorm den Trainingsprozess tiefer Architekturen wirksamer stabilisiert.
Abgesehen von diesen interessanten Details liegt der Schwerpunkt des Artikels auf der Analyse der Aufgabenleistung auf verschiedenen Skalen. Auswertungen zu 152 verschiedenen Aufgaben zeigen, dass eine Erhöhung der Modellgröße den deutlichsten Verbesserungseffekt auf Aufgaben wie Verständnis, Faktenprüfung und Identifizierung schädlicher Sprache hat. Allerdings profitieren Aufgaben im Zusammenhang mit logischem und mathematischem Denken weniger von Architekturerweiterungen.
15. Training rechenoptimaler großer Sprachmodelle (2022)
Mitwirkende: Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals und Sifre
Papierlink: https://arxiv.org/abs/2203.15556 .
In diesem Artikel wird ein 70B-Parametermodell namens Chinchilla vorgestellt, das das beliebte 175B-Parameter-GPT-3-Modell bei generativen Modellierungsaufgaben übertrifft. Der Kernpunkt besteht jedoch darin, darauf hinzuweisen, dass die aktuellen großen Sprachmodelle „erheblich untertrainiert“ sind. Der Artikel definiert ein lineares Skalierungsgesetz für das Training großer Sprachmodelle. Obwohl Chinchilla beispielsweise nur halb so groß ist wie GPT-3, übertrifft es GPT-3, da es auf 1,4 Billionen Token (statt nur 300 Milliarden) trainiert wurde. Mit anderen Worten: Die Anzahl der Trainingstoken ist ebenso wichtig wie die Modellgröße.
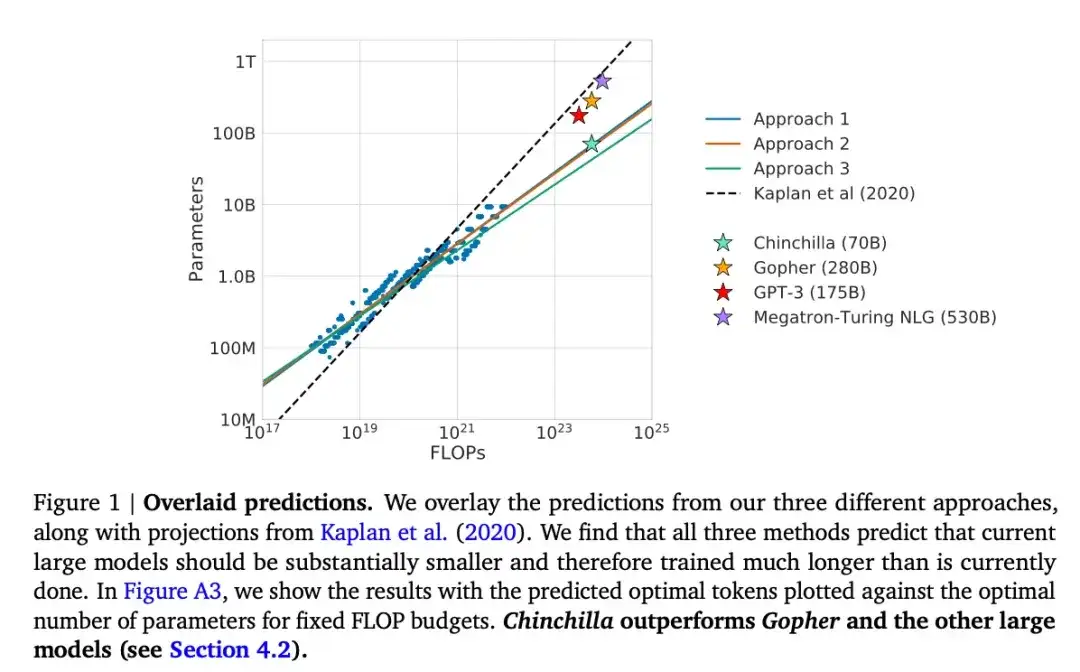
16.Pythia : Eine Suite zur Analyse großer Sprachmodelle über Training und Skalierung hinweg (2023)
Mitwirkende: Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika und van der Wal
Link zum Papier: https://arxiv.org/abs/2304.01373
Pythia ist eine Reihe großer Open-Source-Sprachmodelle (von 700 Millionen bis 12 Milliarden Parametern), die darauf ausgelegt sind, die Entwicklung großer Sprachmodelle während des Trainingsprozesses zu untersuchen. Seine Architektur ähnelt GPT-3, enthält jedoch einige Verbesserungen, wie z. B. Flash Attention (ähnlich wie LLaMA) und Rotary Positional Embeddings (ähnlich wie PaLM). Pythia wird auf dem Pile-Datensatz (825 GB) trainiert, und für das Training werden 300 B-Tokens verwendet (entspricht etwa 1 Epoche bei regulärem PILE oder 1,5 Epochen bei dedupliziertem PILE).
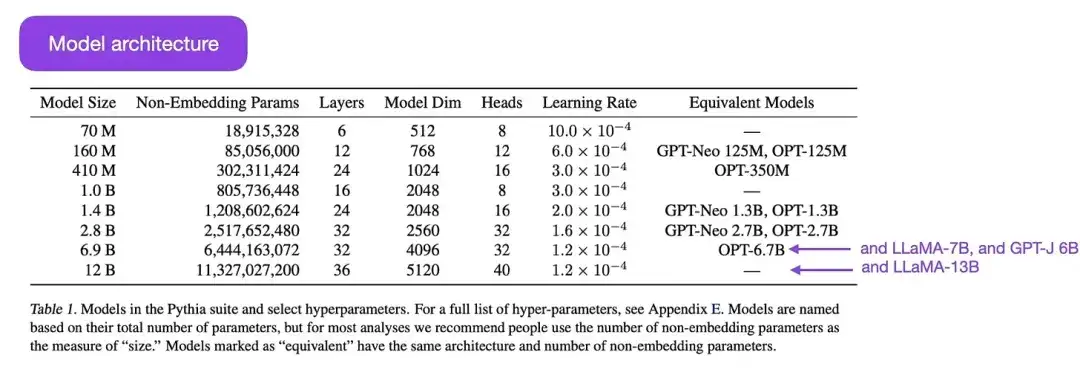
Die wichtigsten Ergebnisse der Pythia-Studie sind wie folgt:
- Das Training auf wiederholten Daten (was aufgrund der Art und Weise, wie große Sprachmodelle trainiert werden, ein Training für mehr als eine Epoche bedeutet) trägt weder zur Leistung bei noch beeinträchtigt sie sie;
- Die Trainingsreihenfolge hat keinen Einfluss auf den Memory-Effekt. Das ist bedauerlich, denn wenn das Gegenteil der Fall wäre, könnten wir das unerwünschte Problem des wörtlichen Gedächtnisses durch eine Neuordnung der Trainingsdaten lindern;
- Die Worthäufigkeit während des Vortrainings wirkt sich auf die Aufgabenleistung aus. Bei Wörtern, die beispielsweise häufiger vorkommen, ist die Genauigkeit bei einer geringeren Anzahl von Stichproben tendenziell höher;
- Durch die Verdoppelung der Batchgröße wird die Trainingszeit halbiert, ohne dass die Konvergenz beeinträchtigt wird.
Ausrichtung: Führen Sie große Sprachmodelle zu gewünschten Zielen und Interessen
In den letzten Jahren haben wir eine Reihe umfangreicher Sprachmodelle gesehen, die relativ leistungsfähig und in der Lage sind, realistische Texte zu generieren (wie GPT-3 und Chinchilla usw.). Es scheint, dass wir eine Obergrenze dessen erreicht haben, was mit häufig verwendeten Paradigmen vor dem Training erreicht werden kann.
Um das Sprachmodell nützlicher zu machen und die Entstehung von Fehlinformationen und schädlicher Sprache zu reduzieren, entwickelten die Forscher zusätzliche Trainingsparadigmen, um das vorab trainierte Basismodell zu verfeinern.
17. Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen ****(2022)
Mitwirkende: Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, 和Lowe,
Papierlink: https://arxiv.org/abs/2203.02155 .
Im sogenannten InstructGPT-Papier nutzten die Forscher einen Reinforcement-Learning-Mechanismus in Kombination mit menschlichem Feedback (RLHF). Sie verwendeten zunächst das vorab trainierte GPT-3-Basismodell und verfeinerten es durch überwachtes Lernen anhand von Menschen generierter Hinweis-Antwort-Paare (Schritt 1). Als nächstes trainierten sie ein Belohnungsmodell, indem sie Menschen die Modellergebnisse bewerten ließen (Schritt 2). Schließlich nutzten sie das Belohnungsmodell, um das vorab trainierte und fein abgestimmte GPT-3-Modell durch die Reinforcement-Learning-Methode der proximalen Richtlinienoptimierung zu aktualisieren (Schritt 3).
Dieses Papier gilt übrigens auch als das Papier, das die Idee hinter ChatGPT erklärt – aktuellen Gerüchten zufolge handelt es sich bei ChatGPT um eine skalierte Version von InstructGPT, die mit einem größeren Datensatz verfeinert wurde.
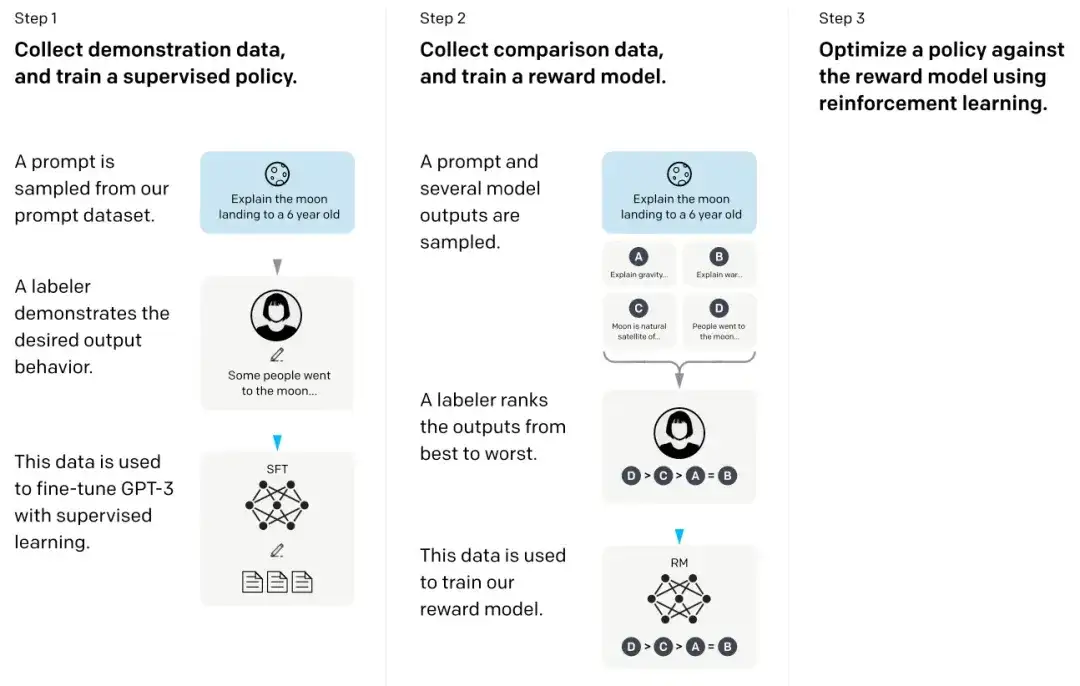
18. Konstitutionelle KI: Harmlosigkeit durch KI-Feedback (2022 )
Vorgestellt: Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann , Amodei, Joseph, McCandlish, Brown, Kaplan
Papierlink: https://arxiv.org/abs/2212.08073 .
In diesem Artikel entwickeln Forscher die Idee der „Ausrichtung“ weiter und schlagen einen Trainingsmechanismus zur Schaffung „harmloser“ KI-Systeme vor. Anstelle einer direkten menschlichen Aufsicht schlagen die Forscher einen Selbsttrainingsmechanismus vor, der auf einer Liste von Regeln basiert, die von Menschen vorgegeben werden. Ähnlich wie das oben erwähnte InstructGPT-Papier verwendet die vorgeschlagene Methode Methoden des verstärkenden Lernens.
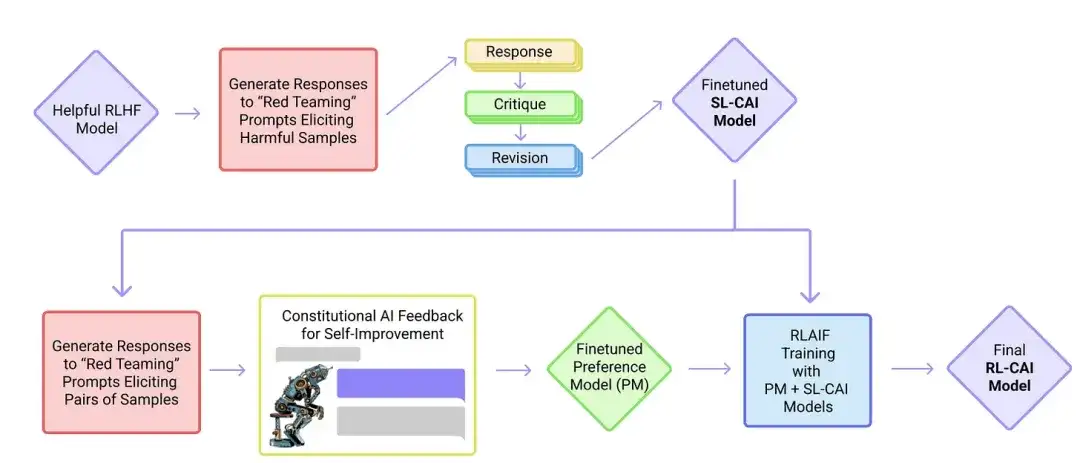
19. Selbstunterricht: Sprachmodell mit selbstgeneriertem Unterricht in Einklang bringen (2022)
Autoren des Papiers: Wang, Kordi, Mishra, Liu, Smith, Khashabi und Hajishirzi
Link zum Papier: https://arxiv.org/abs/2212.10560
Durch die Feinabstimmung der Anweisungen wechseln wir von vorab trainierten Basismodellen wie GPT-3 zu leistungsfähigeren LLMs wie ChatGPT. Von Menschen erstellte Open-Source-Anweisungsdatensätze wie databricks-dolly-15k können dazu beitragen, diesen Prozess zu ermöglichen. Aber wie erreicht man Skalierung? Ein Ansatz besteht darin, LLM das Bootstrap-Lernen auf der Grundlage seiner selbst generierten Inhalte durchführen zu lassen.
Self-Instruct ist eine (nahezu annotationsfreie) Methode zum Ausrichten vorab trainierter LLMs an Anweisungen. Wie funktioniert dieser Prozess? Kurz gesagt besteht es aus vier Schritten:
- Initialisieren Sie einen Aufgabenpool mit einem Satz von Menschen geschriebener Anweisungen (in diesem Fall 175) und Beispielanweisungen daraus;
- Verwenden Sie ein vorab trainiertes LLM (z. B. GPT-3), um die Aufgabenkategorie zu bestimmen.
- Lassen Sie für neue Anweisungen das vorab trainierte LLM Antworten generieren;
- Diese Antworten werden gesammelt, gefiltert und gefiltert, bevor sie dem Aufgabenpool hinzugefügt werden.
Auf diese Weise kann die Selbstinstruktionsmethode die Fähigkeit des vorab trainierten Sprachmodells, Anweisungen zu befolgen und zu generieren, effektiv verbessern und gleichzeitig manuelle Anmerkungen reduzieren, wodurch die Fähigkeiten des Modells erweitert und optimiert werden.
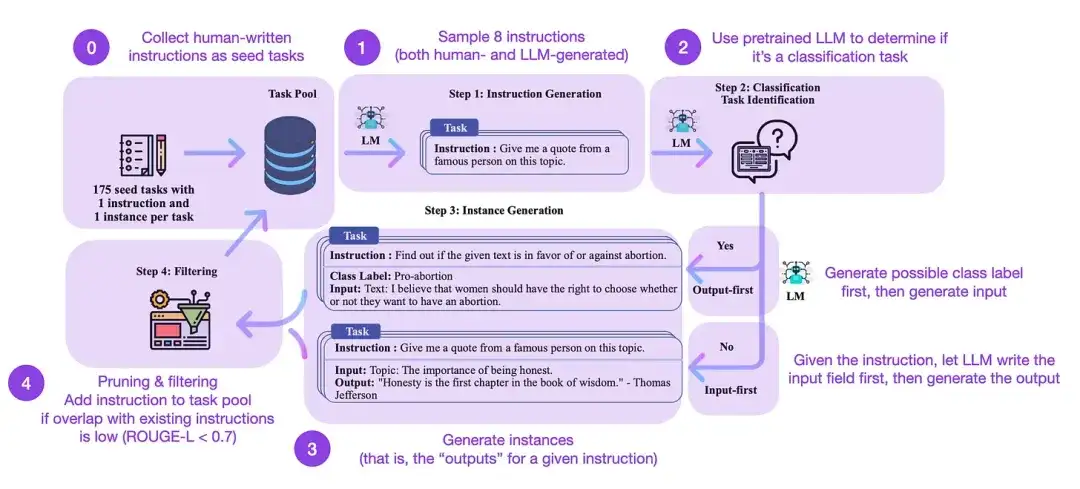
In der Praxis schneidet diese Methode basierend auf dem ROUGE-Score relativ gut ab. Beispielsweise übertraf die selbstgesteuerte Feinabstimmung großer Sprachmodelle (LLMs) das GPT-3-Basismodell und konnte mit LLMs konkurrieren, die auf großen Sätzen von Menschen geschriebener Anweisungen vorab trainiert waren. Darüber hinaus kann die Selbstführung auch LLMs zugute kommen, die durch menschliche Anweisungen verfeinert wurden.
Der Goldstandard für die Bewertung von LLM besteht natürlich darin, menschliche Gutachter zur Teilnahme einzuladen. Basierend auf menschlicher Bewertung gehen selbstgesteuerte Methoden über das grundlegende LLM hinaus und umfassen LLM, das auf überwachten Weise auf Datensätzen mit menschlichem Unterricht trainiert wird (z. B. SuperNI, T0-Trainer). Aber interessanterweise übertraf die Selbstführung nicht diejenigen, die durch Methoden des verstärkenden Lernens unter Einbeziehung menschlichen Feedbacks (RLHF) trainiert wurden.
Was ist vielversprechender: von Menschen erstellte Befehlsdatensätze oder selbstgesteuerte Datensätze? Ich bin in beiden Fällen optimistisch. Warum nicht mit einem von Menschen erstellten Befehlsdatensatz beginnen, wie etwa den 15.000 Anweisungen in databricks-dolly-15k, und ihn dann auf selbstgesteuerte Weise erweitern?
Reinforcement Learning und Human Feedback (RLHF) Weitere Erläuterungen zu Reinforcement Learning und Human Feedback (RLHF) sowie verwandte Dokumente zur proximalen Richtlinienoptimierung zur Implementierung von RLHF finden Sie in meinem ausführlicheren Artikel unten:
Wenn ich über große Sprachmodelle (LLMs) diskutiere, sei es in Forschungsaktualisierungen oder Tutorials, beziehe ich mich oft auf einen Prozess namens Reinforcement Learning with Human Feedback (RLHF). RLHF ist zu einem wichtigen Bestandteil der modernen LLM-Trainingspipeline geworden, da es menschliche Präferenzen in das Optimierungsframework einbeziehen und so den Nutzen und die Sicherheit des Modells verbessern kann.
Lesen Sie den vollständigen Artikel:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
Fazit und weiterführende Literatur
Ich habe versucht, die obige Liste prägnant und prägnant zu halten und mich auf die zehn besten Artikel (plus drei Artikel zu RLHF) zu konzentrieren, die das Design, die Einschränkungen und die Entwicklung zeitgenössischer groß angelegter Sprachmodelle verstehen. Für weitere Untersuchungen wird empfohlen, auf die zitierten Dokumente in den oben genannten Arbeiten zu verweisen. Hier sind einige zusätzliche Ressourcen:
Open-Source-Alternativen zu GPT:
- BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (2022), https://arxiv.org/abs/2211.05100
- OPT: Open Pre-trained Transformer Language Models (2022), https://arxiv.org/abs/2205.01068
- UL2: Vereinheitlichung der Paradigmen des Sprachenlernens (2022), https://arxiv.org/abs/2205.05131
ChatGPT-Alternativen:
- LaMDA: Sprachmodelle für Dialoganwendungen (2022), https://arxiv.org/abs/2201.08239
- (Bloomz) Crosslingual Generalization through Multitask Finetuning (2022), https://arxiv.org/abs/2211.01786
- (Sparrow) Verbesserung der Ausrichtung von Dialogagenten durch gezielte menschliche Urteile (2022), https://arxiv.org/abs/2209.14375
- BlenderBot 3: Ein eingesetzter Konversationsagent, der kontinuierlich lernt, verantwortungsbewusst zu handeln, https://arxiv.org/abs/2208.03188
Große Modelle im Biocomputing:
- ProtTrans: Auf dem Weg zum Knacken des Codes der Sprache des Lebens durch selbstüberwachtes Deep Learning und Hochleistungsrechnen (2021), https://arxiv.org/abs/2007.06225
- Hochpräzise Proteinstrukturvorhersage mit AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
- Große Sprachmodelle generieren funktionelle Proteinsequenzen in verschiedenen Familien (2023), https://www.nature.com/articles/s41587-022-01618-2
Artikelempfehlungen
7 schnelle Tipps, um Ihr Gespräch mit KI effektiver zu gestalten
Ist es in einer Zeit, in der jeder Entwickler ist, noch sinnvoll, Programmieren zu lernen?
Wenn ein Verstoß vorliegt, kontaktieren Sie uns bitte, um ihn zu löschen. Referenzlinks:
https://magazine.sebastianraschka.com/p/understanding-large-lingual-models
Folgen Sie uns
OpenSPG:
Offizielle Website: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
Offizielle Website: https://openasce.openfinai.org/
GitHub: [https://github .com /Open-All-Scale-Causal-Engine/OpenASCE ]