
Kürzlich fand die Kangaroo Cloud Spring Conference mit dem Thema „Daten + KI, Aufbau neuer Produktivität“ einen erfolgreichen Abschluss. Die Konferenz brachte eine Reihe digitaler „ +KI “-Produkte und die neuesten Branchenniederschläge mit dem Ziel, Daten und Daten eng zu integrieren KI durchbricht die traditionellen Grenzen der Produktivität und ermöglicht es Unternehmen, eine höhere Qualität und eine effizientere digitale Entwicklung zu erreichen. Bei dem Treffen stellte Tou Tian, Produktmanager von Kangaroo Cloud Data Stack, eine neue Version von Data Stack V6.2 vor, die KI-Funktionen integriert . Dies ist nicht nur ein einfaches Produkt-Upgrade, sondern stellt auch die mutige Vorhersage von Kangaroo Cloud dar Zukunft. .
Data Stack V6.2: Maximierung des Datenwerts
Im datengesteuerten Zeitalter sind Daten zur Lebensader von Unternehmen geworden. Wie diese Daten effektiv verwaltet und genutzt werden können, ist eine Frage, mit der sich jedes Unternehmen beschäftigt. Die Veröffentlichung von Data Stack V6.2 soll genau diese Herausforderung lösen und Unternehmen dabei helfen, die Wellen im Datenmeer zu meistern.
Das Kernkonzept des neu veröffentlichten Data Stack V6.2 ist Data+AI . Die neue Version bietet nicht nur die Grundfunktionen der Big-Data-Plattform, sondern bietet Unternehmen durch tiefe Integration mit KI-Technologie auch intelligente Datenanalysen und Anwendungen . Dies bedeutet, dass Unternehmen die Datenstapelplattform nutzen können, um die Integration branchenspezifischer Content-Systeme, flexible und bequeme Dateneinblicke, extrem schnelle Analyse-Engine-Berechnungen sowie eine umfassende Verwaltung und Kontrolle der Datensicherheit zu erreichen. Darüber hinaus decken die Produktlösungen von Kangaroo Cloud auch viele Aspekte wie Lightweight, Datenverwaltung und Informationserstellung ab. All dies soll Unternehmen dabei helfen, ihre Rechenspeicherkosten zu optimieren, die Datenqualität zu verbessern, Standards und Spezifikationen zu fördern und letztendlich den Wert der Daten zu maximieren.
1. Leichte Rechenzentrumslösung, die Datenverarbeitung ist effizienter
Durch die Einführung effizienter Computer-Engines Doris und StarRocks wird eine revolutionäre Neukonstruktion der Plattformleistung erreicht. Dieser innovative Schritt verbessert nicht nur die Datenverarbeitungsgeschwindigkeit erheblich, senkt die Speicherkosten sowie die Betriebs- und Wartungskosten, sondern optimiert auch die Abfrageeffizienz und bietet Unternehmen ein beispielloses Datenbetriebserlebnis. Die Ad-hoc-Abfragefunktionen und leistungsstarken Analyseverarbeitungsfunktionen von Doris und StarRocks bilden gemeinsam eine leistungsstarke und flexible Datenverarbeitungsplattform. Benutzer können die Echtzeitanalyseanforderungen umfangreicher Daten problemlos bewältigen und sofortige Dateneinblicke und Entscheidungsunterstützung erhalten. Bei diesem Prozess sind die Genauigkeit und Zuverlässigkeit der Daten vollständig gewährleistet und bieten eine solide Datenunterstützung für die Schlüsselgeschäfte des Unternehmens wie Fehlervorhersage, Präzisionsmarketing und Prozessoptimierung.
und leistungsstarken Analyseverarbeitungsfunktionen von Doris und StarRocks bilden gemeinsam eine leistungsstarke und flexible Datenverarbeitungsplattform. Benutzer können die Echtzeitanalyseanforderungen umfangreicher Daten problemlos bewältigen und sofortige Dateneinblicke und Entscheidungsunterstützung erhalten. Bei diesem Prozess sind die Genauigkeit und Zuverlässigkeit der Daten vollständig gewährleistet und bieten eine solide Datenunterstützung für die Schlüsselgeschäfte des Unternehmens wie Fehlervorhersage, Präzisionsmarketing und Prozessoptimierung.
2. Umfassendes Data-Governance-System zur Maximierung des Unternehmenswerts
Mit Data Stack V6.2 haben wir die Datenverwaltung umfassend aktualisiert und neu definiert, um den wachsenden Anforderungen von Unternehmen im Datenmanagement gerecht zu werden. Die fünf Dimensionen des Data Governance Centers : Speicherung, Datenverarbeitung, Qualität, Spezifikation und Wert bilden ein umfassendes Data Governance-System , um die Integrität, Genauigkeit und Verfügbarkeit von Unternehmensdaten sicherzustellen.
Die Governance-Workbench bietet eine intuitive Bedienoberfläche, die das Initiieren, Aufzeichnen, Zuweisen und Verarbeiten von Data-Governance-Aufgaben einfach und effizient macht. Über diese Plattform können Unternehmen den Status der Datenverwaltung aus einer persönlichen Perspektive, einer Projektperspektive oder einer Panoramaperspektive anzeigen und so sicherstellen, dass die Datenqualität jeder Verbindung effektiv überwacht und verwaltet wird. Die Code-Inspektionsfunktion standardisiert SQL-Code durch SQL-Inspektionsregeln, um mögliche Verwaltungsprobleme im Voraus zu verhindern. Die Verwaltung kleiner Dateien zielt darauf ab, das Problem kleiner Dateien in Hadoop-Clustern zu lösen, die Leistung und Skalierbarkeit des Clusters durch einmaliges oder regelmäßiges Zusammenführen zu optimieren und die Effizienz der Datenverarbeitung zu verbessern .
Die Datenverwaltung von DataStack V6.2 ist nicht nur ein Upgrade der Technologie, sondern auch eine Gestaltung der Unternehmensdatenkultur. Durch ein solches Governance-System können Unternehmen ein vollständiges Daten-Governance-Framework einrichten , die Datenstandardisierung und -standardisierung fördern und letztendlich den Wert von Datenbeständen maximieren.
3. Die Full-Link-Xinchuang-Anpassung unterstützt eine umfassende Lokalisierung
Im Zeitalter der Informationisierung und Informationsinnovation sind wir uns der Bedürfnisse von Unternehmen nach Datensicherheit und unabhängiger Kontrollierbarkeit bewusst. Daher erreicht unsere Plattform nicht nur eine umfassende Informationsinnovationsabdeckung in Bezug auf Server, Betriebssysteme, Chips, Middleware, Metadatendatenbanken, Computer-Engines usw., sondern nimmt auch tiefgreifende Anpassungen bei dem vollständigen Prozesssicherheitsschutz vor.undder privatisierten Bereitstellung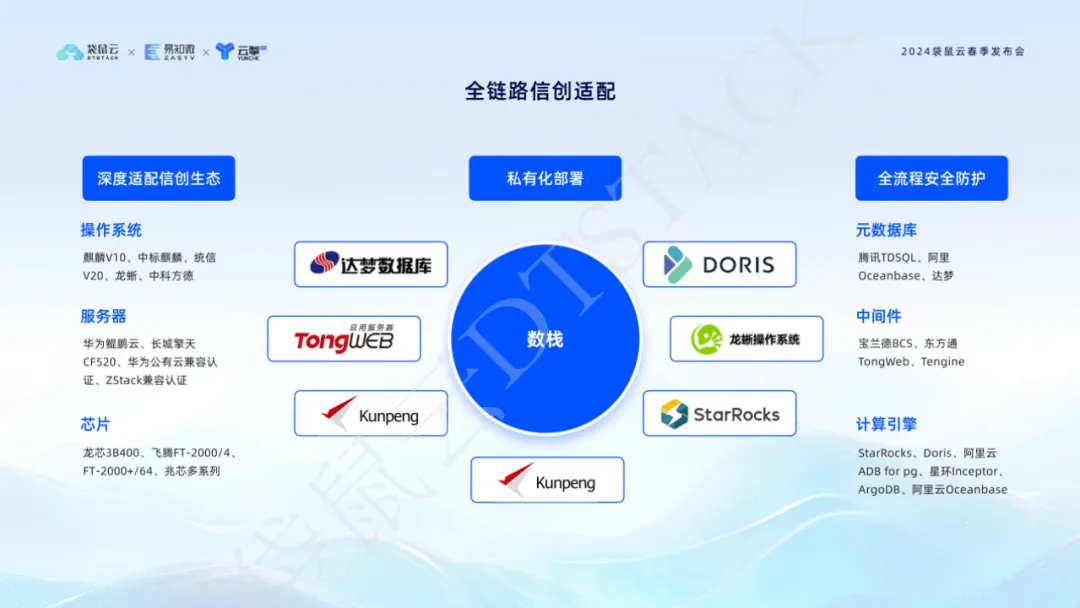
4. Erneuern und durchbrechen Sie die Funktionen des Paimon-Datensees, um ein integriertes Batch-Stream-Datenverarbeitungsmodell zu realisieren
Im traditionellen Datenverarbeitungsmodell stehen Unternehmen oft vor dem Dilemma, zwei Sätze Codelogik zu entwickeln und zu pflegen: einen für die Stapelverarbeitung und einen für die Echtzeit-Stream-Verarbeitung. Dies bedeutet nicht nur eine Verdoppelung des Entwicklungs- und Wartungsaufwands, sondern erfordert auch die Verarbeitung der Datenzusammenführungslogik zwischen beiden, um sicherzustellen, dass die beiden Systeme gleichzeitig online gehen. Ein solches Modell erhöht nicht nur den Ressourcenverbrauch, sondern kann auch zu Datenmehrdeutigkeiten führen, was die Gewährleistung der Datengenauigkeit erschwert und das Vertrauen des Geschäftspersonals in die Datenergebnisse verringert.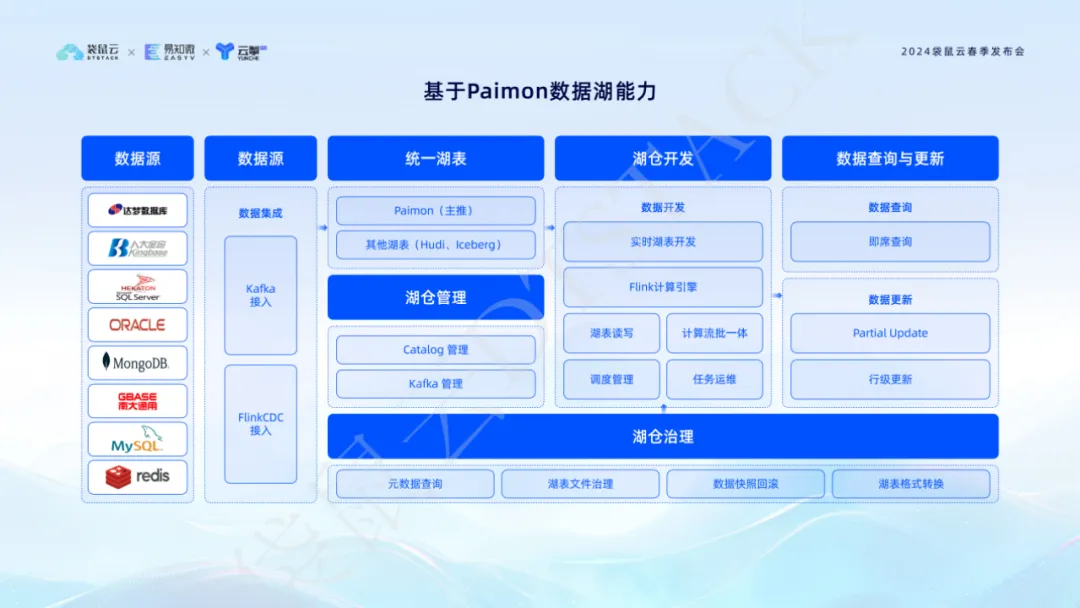
Der innovative Durchbruch des Datenstapels realisiert das Batch-Stream-integrierte Datenverarbeitungsmodell durch die Funktionen von Paimon Data Lake und löst so die oben genannten Probleme effektiv. Die Plattform bietet Echtzeit-Lake-Table-Entwicklung und Ad-hoc-Abfragefunktionen , sodass Datenentwickler Echtzeit- und Batch-Daten gleichzeitig auf einer einzigen Plattform verarbeiten können, ohne dass zusätzliche Ressourceninvestitionen und komplexe Datensynchronisierungsprozesse erforderlich sind. Eine solche integrierte Lösung reduziert nicht nur die Nutzung von Rechen- und Speicherressourcen, sondern stellt auch die Konsistenz und Genauigkeit der Daten sicher und verbessert so die Erkennung der Ergebnisse der Datenanalyse durch das Geschäftspersonal. Diese Innovation wird die digitale Transformation und die intelligente Modernisierung von Unternehmen nachhaltig unterstützen.
5. Die vier Hauptfunktionen von EasyMR sind umfassend optimiert, um ein neues Big-Data-Verarbeitungs- und Rechenerlebnis zu ermöglichen.
Als wichtiges Produktmodul im Datenstapel repräsentiert EasyMR unser tiefgreifendes Verständnis und unsere kontinuierliche Innovation des Big-Data-Ökosystems. Es basiert auf Open-Source-Hadoop und iteriert synchron mit der Open-Source-Community. Es wird unabhängig von unserem Computing-Engine-Team entwickelt und verfügt über optimierte und erweiterte Funktionen von Kernkomponenten wie Spark, Flink und Paimon. Diese Optimierungen verbessern nicht nur die Leistung und Stabilität der Datenverarbeitung, sondern geben auch der Community etwas zurück und fördern den gemeinsamen Aufbau des Hadoop-Ökosystems.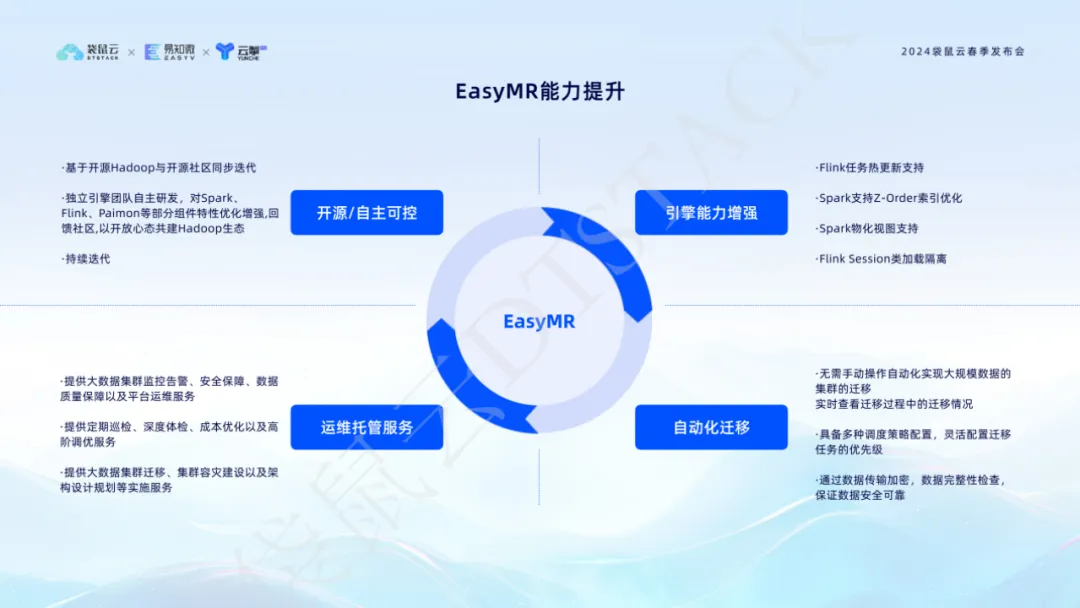
Die verbesserten Funktionen von EasyMR spiegeln sich in vielen Aspekten wider: Es unterstützt Hot-Updates von Flink-Aufgaben und gewährleistet so die Geschäftskontinuität und Flexibilität. Die Z-Order-Indexoptimierung und die Unterstützung materialisierter Ansichten verbessern die Datenverarbeitungseffizienz und die Antwortgeschwindigkeit Zuverlässigkeit der Betriebsumgebung. Darüber hinaus macht die automatisierte Migrationsfunktion von EasyMR die Migration großer Datencluster einfach und unkompliziert und überwacht den Status während des Migrationsprozesses in Echtzeit, um Datensicherheit und Zuverlässigkeit zu gewährleisten. Durch diese Innovationen und Optimierungen stellt EasyMR den Benutzern eine effiziente, intelligente und einfach zu wartende Big-Data-Plattform zur Verfügung und hilft Unternehmen dabei, einen qualitativen Sprung in der Datenverwaltung und -analyse zu erzielen.
Daten- und KI-Funktionen machen die Datenentwicklung intelligenter
Die KI-Technologie ist zur zentralen treibenden Kraft für Unternehmensinnovationen und Effizienzsteigerungen geworden. Durch die Integration generativer KI-Technologie hat DataStack V6.2 sechs Hauptfunktionen realisiert: intelligente Entwicklung, intelligente Abstimmung, intelligente Diagnose, intelligenter Abruf, intelligente Analyse und intelligente Verifizierung, was die Effizienz und Qualität der Datenverarbeitung erheblich verbessert.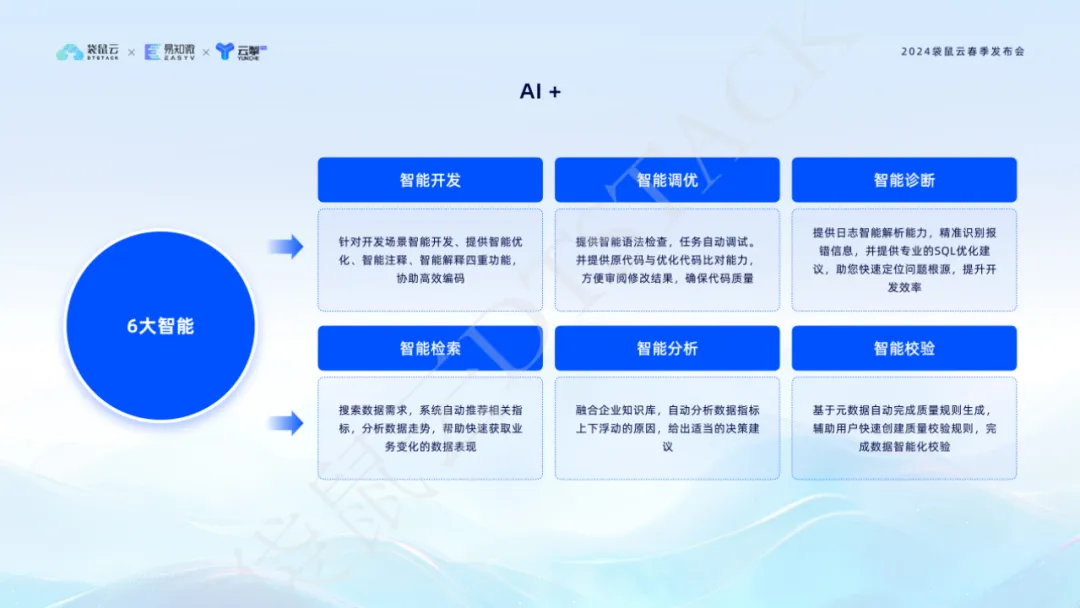
Intelligentes Tuning kann den SQL-Code automatisch optimieren und die Ausführungsleistung verbessern. Die intelligente Diagnose nutzt KI, um Protokolle schnell zu lokalisieren und professionelle Optimierungsvorschläge zu liefern . Diese Funktionen verbessern nicht nur die Entwicklungseffizienz, sondern stellen auch die Codequalität sicher und erreichen Geschäftsziele auf datengesteuerte Weise genauer. Die Einführung von AI+ markiert den Beginn einer neuen Ära eines intelligenteren und effizienteren Datenmanagements.
Die intelligente Optimierungsfunktion AI + kann intelligente Optimierungsvorschläge liefern, wenn Entwickler Code im Editor schreiben, sodass Studenten die Datenentwicklung überprüfen und vergleichen können. Dadurch werden die Codierungseffizienz und die Codequalität verbessert, sodass sich Datenentwicklungsstudenten mehr auf die Implementierung der Geschäftslogik konzentrieren können.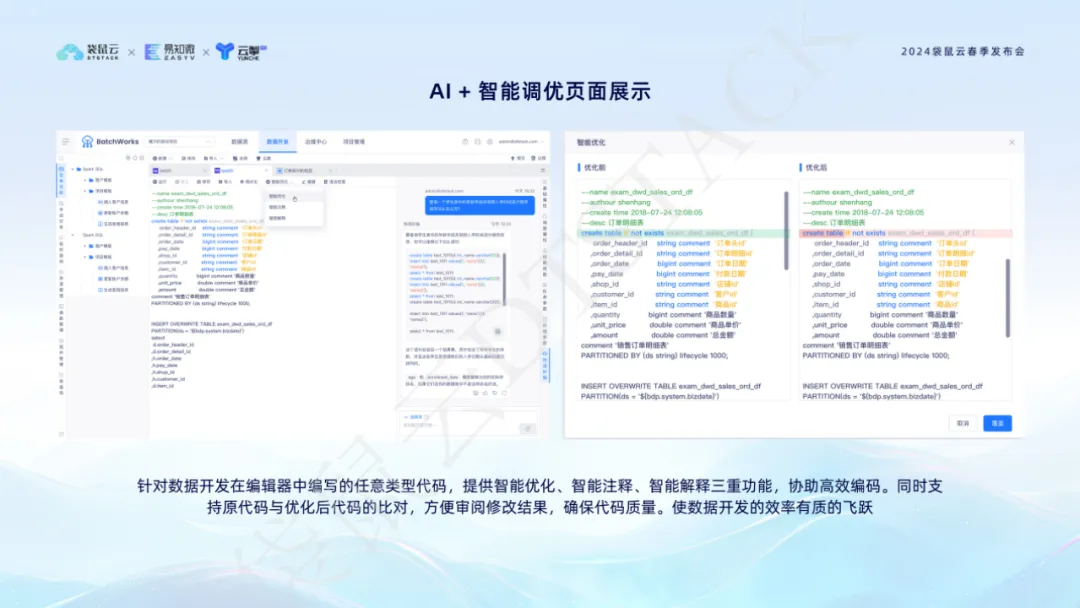
Die intelligente Diagnosefunktion AI + nutzt KI-Technologie, um Spark SQL-, Flink SQL- und andere Aufgabenprotokolle intelligent zu analysieren, Fehlermeldungen zu identifizieren und professionelle SQL-Optimierungsvorschläge bereitzustellen, um die Ursache des Problems schnell zu lokalisieren und die Effizienz der Codeentwicklung zu verbessern. 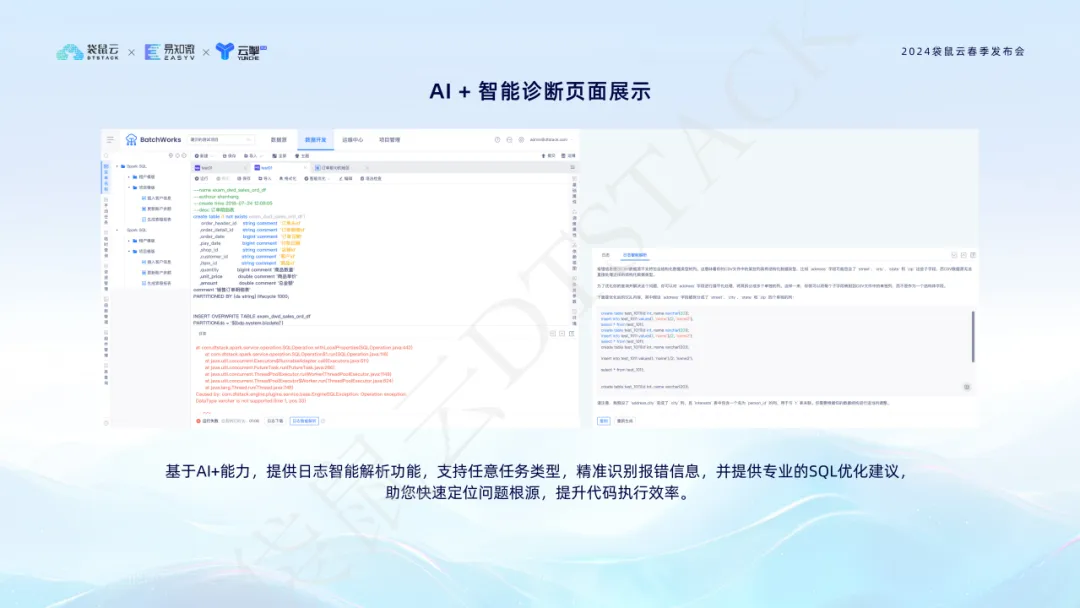 Durch die Integration mit AI+ vereinfacht der Datenstapel nicht nur den Datenentwicklungsprozess, sondern verbessert auch die Genauigkeit und Zuverlässigkeit der Datenverarbeitung und bietet solide technische Unterstützung für die datengesteuerte Entscheidungsfindung von Unternehmen.
Durch die Integration mit AI+ vereinfacht der Datenstapel nicht nur den Datenentwicklungsprozess, sondern verbessert auch die Genauigkeit und Zuverlässigkeit der Datenverarbeitung und bietet solide technische Unterstützung für die datengesteuerte Entscheidungsfindung von Unternehmen.
Produkte + Dienstleistungen, ein neues Upgrade der Kommerzialisierungsstrategie für Datenstapelprodukte
Bei dieser Produkteinführung haben wir die Kommerzialisierungsstrategie unserer Produkte neu definiert und zielen darauf ab, flexible und vielfältige Servicelösungen für Unternehmen mit unterschiedlichen Anforderungen bereitzustellen.  Die Produktserie umfasst die Standard Edition, die Professional Edition und die Ultimate Edition und bietet Optionen für die Anwendungs-Cloud-Bereitstellung, um den Datenverarbeitungsanforderungen von Unternehmen unterschiedlicher Größe gerecht zu werden. Darüber hinaus bieten wir auch Mehrwertdienste wie Xinchuang-Anpassung und Echtzeit-Seelager sowie erweiterte und Top-Versionen systematischer Betriebs- und Wartungsdienste an, um sicherzustellen, dass Kunden von der Basis bis zur Fortgeschrittenen umfassenden Unterstützung genießen können.
Die Produktserie umfasst die Standard Edition, die Professional Edition und die Ultimate Edition und bietet Optionen für die Anwendungs-Cloud-Bereitstellung, um den Datenverarbeitungsanforderungen von Unternehmen unterschiedlicher Größe gerecht zu werden. Darüber hinaus bieten wir auch Mehrwertdienste wie Xinchuang-Anpassung und Echtzeit-Seelager sowie erweiterte und Top-Versionen systematischer Betriebs- und Wartungsdienste an, um sicherzustellen, dass Kunden von der Basis bis zur Fortgeschrittenen umfassenden Unterstützung genießen können.
Die Produktkommerzialisierungsstrategie von Datastack konzentriert sich nicht nur auf den Verkauf von Produkten, sondern auch auf die kontinuierliche Optimierung und Aktualisierung von Dienstleistungen. Durch die Bereitstellung zweier Wege für Produkt-Upgrades und Versions-Upgrades hilft es Unternehmen dabei, die kontinuierliche Anpassungsfähigkeit und den zukunftsorientierten Charakter der Datenplattform sicherzustellen. Eine solche Strategie verbessert nicht nur das Kundenerlebnis, sondern legt auch eine solide Grundlage für die langfristige Entwicklung von Datenstack-Produkten.
Drei wichtige Produktpraxisfälle zur Unterstützung der digitalen Transformation von Unternehmen
1. Eine Bank: Implementierung einer KI-basierten Leistungsbeurteilung
Basierend auf den gesammelten Leistungsbeurteilungsindikatoren, kombiniert mit der unternehmenseigenen Wissensbasis, nutzt die Bank intelligente KI-Analyse- und Datenverarbeitungsfunktionen, um die Managementeffizienz und das Governance-Niveau der Leistungsbeurteilung deutlich zu verbessern.
Unsere Lösung half der Bank, den Wandel von Indikatorberichten zu Indikator-Dashboards und dann zu Indikator-Konversations-BI zu realisieren, was die Kosten für die Mitarbeiter für die Beschaffung und Nutzung von Daten erheblich reduzierte, die Bewertungsstandards wissenschaftlicher und strenger machte und die Bewertungsinhalte vollständiger machte , um sicherzustellen, dass in der Bank ein enger Zusammenhang zwischen der Gesamtleistung und der Leistung der einzelnen Mitarbeiter besteht. Durch intelligente KI-Attribution und intelligente Vorschläge können Banken die Leistungsergebnisse der Mitarbeiter in Echtzeit verfolgen, Probleme rechtzeitig erkennen und Anpassungen vornehmen und so die Konsistenz der Mitarbeiter- und Organisationsziele sowie die kontinuierliche Verbesserung der Leistung fördern. Diese Transformation optimiert nicht nur das Personalmanagement der Bank, sondern führt auch zu einer höheren betrieblichen Effizienz und höheren Geschäftsergebnissen für die gesamte Organisation.
2. Eine chinesische Spirituosenmarke: leichtes Rechenzentrum
Durch Data Stack hat die Marke eine einheitliche Marketingplattform etabliert, die Unternehmen dabei unterstützt, mehrdimensionale Analysefunktionen wie Datenaustausch , Smart Tags und Indikatorenmanagement zu realisieren und eine starke Datenunterstützung für das Präzisionsmarketing, die Prozessoptimierung usw. von Unternehmen bietet.  Die Plattform übernimmt eine leichtgewichtige Daten-Middle-End-Lösung und kombiniert sie mit den Hochleistungs-Computing-Fähigkeiten von StarRocks, um Spirituosenunternehmen eine effiziente Datenverwaltung und sofortige Analyse zu ermöglichen. Die Abfragefunktionen mit geringer Latenz und das schnelle Laden von Daten von StarRocks ermöglichen es Unternehmen, schnell auf Marktveränderungen zu reagieren und Fehlervorhersagen und präzises Marketing zu erzielen. Im Vergleich zum herkömmlichen Hadoop-Ökosystem bietet eine solche leichte Daten-Mid-End-Lösung eine hervorragende Abfrageleistung, Echtzeit-Datenverarbeitung, hohe Parallelität und einfache Wartung in Szenarien mit geringem Datenvolumen, was sie zu einer idealen Lösung macht Durch die Datenanalyse fördert es die digitale Transformation von Spirituosenunternehmen.
Die Plattform übernimmt eine leichtgewichtige Daten-Middle-End-Lösung und kombiniert sie mit den Hochleistungs-Computing-Fähigkeiten von StarRocks, um Spirituosenunternehmen eine effiziente Datenverwaltung und sofortige Analyse zu ermöglichen. Die Abfragefunktionen mit geringer Latenz und das schnelle Laden von Daten von StarRocks ermöglichen es Unternehmen, schnell auf Marktveränderungen zu reagieren und Fehlervorhersagen und präzises Marketing zu erzielen. Im Vergleich zum herkömmlichen Hadoop-Ökosystem bietet eine solche leichte Daten-Mid-End-Lösung eine hervorragende Abfrageleistung, Echtzeit-Datenverarbeitung, hohe Parallelität und einfache Wartung in Szenarien mit geringem Datenvolumen, was sie zu einer idealen Lösung macht Durch die Datenanalyse fördert es die digitale Transformation von Spirituosenunternehmen.
3. Staatseigenes Konzernunternehmen der Stadt Peking: Vollständiger Link Xinchuang
Um die Probleme der digitalen Transformation von Unternehmen und der Informationsinnovationsanforderungen zu lösen, richtete dieser Kunde eine „ Full-Link-Informationsinnovations-Big-Data-Plattform “ ein.  Die Plattform ist stark an das Xinchuang-Ökosystem angepasst und ermöglicht einen vollständigen Prozesssicherheitsschutz und eine privatisierte Bereitstellung von Servern, Betriebssystemen, Chips, Anwendungsmetadatendatenbanken, Middleware und Computer-Engines. Durch eine solche umfassende Anpassung der Informationsinnovation löste die Gruppe nicht nur das Problem der Dateninseln, sondern erfüllte auch die strengen Anforderungen des Landes an Informationsinnovation und gewährleistete die Sicherheit und Kontrollierbarkeit der Daten. Diese Initiative hat die Data-Governance-Fähigkeiten der Gruppe deutlich verbessert, eine solide Datengrundlage für die langfristige Entwicklung des Unternehmens gelegt und auch anderen staatseigenen Unternehmen wertvolle praktische Erfahrungen im Bereich Informationsinnovation vermittelt.
Die Plattform ist stark an das Xinchuang-Ökosystem angepasst und ermöglicht einen vollständigen Prozesssicherheitsschutz und eine privatisierte Bereitstellung von Servern, Betriebssystemen, Chips, Anwendungsmetadatendatenbanken, Middleware und Computer-Engines. Durch eine solche umfassende Anpassung der Informationsinnovation löste die Gruppe nicht nur das Problem der Dateninseln, sondern erfüllte auch die strengen Anforderungen des Landes an Informationsinnovation und gewährleistete die Sicherheit und Kontrollierbarkeit der Daten. Diese Initiative hat die Data-Governance-Fähigkeiten der Gruppe deutlich verbessert, eine solide Datengrundlage für die langfristige Entwicklung des Unternehmens gelegt und auch anderen staatseigenen Unternehmen wertvolle praktische Erfahrungen im Bereich Informationsinnovation vermittelt.
Das Obige ist die Einführung in die Veröffentlichung von DataStack V6.2. Es ist nicht nur ein Produkt, sondern auch eine Zusammenfassung unseres tiefen Verständnisses und unserer Praxis von Big Data Governance und intelligenter Analyse. Wir glauben, dass Data Stack V6.2 mehr Unternehmen dabei helfen kann, den Wert ihrer Daten zu maximieren und ihre digitale Transformation voranzutreiben.
Downloadadresse „Industry Indicator System White Paper“: https://www.dtstack.com/resources/1057?src=szsm
Download-Adresse „Dutstack Product White Paper“: https://www.dtstack.com/resources/1004?src=szsm
Downloadadresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm
Wenn Sie mehr über Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder sich beraten lassen möchten, besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt