
1. Hintergrundeinführung
Der GoldenEye PAAS-Datendienst ist eine Reihe von Datendiensten, die die gleiche Indikatordienstvereinbarung implementieren. Jeder Dienst ist nach dem Thema der erzeugten Indikatoren unterteilt. Beispielsweise stellt der Echtzeit-Transaktionsdienst die Abfrage von Echtzeit-Transaktionsindikatoren bereit. und der Finanz-Offline-Dienst ermöglicht die Abfrage von Offline-Finanzkennzahlen. Der GoldenEye PAAS-Datendienst unterstützt die Datenabfrageanforderungen der GoldenEye APP, des GoldenEye PCs und verschiedener interner Großbildschirme. Damit das Unternehmen korrekte Datenerkenntnisse und Entscheidungen durchführen kann, muss die Genauigkeit der von PAAS-basierten Datendiensten bereitgestellten Daten sichergestellt werden .
Aufgrund der schnellen Iteration von Geschäftsanforderungen müssen Datendienste häufig den Abfragekaliber, die Abfragedimensionen und die Abfrageindikatoren anpassen. Daher sind effiziente automatisierte Regressionstestmethoden erforderlich, um die Qualität jeder Anforderungsiteration sicherzustellen. Beim automatisierten Testen von PAAS-Datendiensten gibt es einige Probleme:
Als Reaktion auf die Vielfalt der Anforderungsszenarien und die Besonderheiten des Indikatordienstprotokolls haben wir ein spezielles DIFF-Tool für GoldenEye PAAS-Datendienste implementiert. Durch die Aufzeichnung des Online-Verkehrs, die anschließende Wiedergabe in den Test- und Online-Umgebungen und den Vergleich der zurückgegebenen Ergebnisse. Die Effizienz der Anforderungswiedergabe und das Vergleichsergebnis bei Falschmeldungen wurden speziell optimiert. Diese Methode kann eine vollständige Abdeckung von Online-Abfrageszenarien gewährleisten, manuelle Eingriffe bei der manuellen Erstellung von Anforderungsszenarien reduzieren und ausreichend effiziente automatisierte Regressionstestfunktionen bereitstellen, um Selbsttests in Forschung und Entwicklung zu ermöglichen.
Nach einer Phase der Konstruktion und Iteration hat das PAAS-basierte Datendienst-DIFF-Tool von GoldenEye die drei Dienste von GoldenEye abgedeckt: Echtzeithandel, Offline-Handel und Offline-Finanzierung, mit einer durchschnittlichen monatlichen DIFF-Ausführungszahl von mehr als 40 Malen.
Im folgenden Artikel werden die Herausforderungen und praktischen Erfahrungen vorgestellt, die beim Aufbau von GoldenEye PAAS-basierten Datendienst-DIFF-Tools auftreten.
2. Probleme und Ideen
2.1 Schwierigkeiten beim Aufruf von PAAS-Protokollen
Die PAAS-Dienste von GoldenEye implementieren alle dasselbe Indikatordienstprotokoll. Der Anforderungsparameter ist ein komplexes verschachteltes Objekt, und jedes Filterbedingungsobjekt in der Kriteriensammlung verwendet Jacksons @JsonSubTypes-Annotation, um polymorphes Parsen zu implementieren. Laut dem http-Aufrufdokument des JSF-Teams erfordert der Aufruf einer Schnittstelle mit komplexen verschachtelten Objekten das Hinzufügen von „@type“: „Paketpfad + Klassenname“ zu jedem verschachtelten Objekt. Es wird empfohlen, JSON.toJSONString (Instanz, SerializerFeature.WriteClassName) zu verwenden ) generiert eine JSON-Zeichenfolge mit Typmerkmalen, wie in der folgenden Abbildung dargestellt. Vor der Generierung muss Jackson verwendet werden, um die Anforderungsparameter in Instanzobjekte zu deserialisieren. Wenn Sie darauf bestehen, die http-Methode zum Aufrufen dieser Art von JSF-Schnittstelle in einem Python-Skript zu verwenden, müssen Sie die Implementierungsklasse jeder Filterbedingung selbst identifizieren . Um den bequemen Aufruf der JSF-Schnittstelle des PAAS-Datendienstes zu realisieren, wurde das in Java geschriebene DIFF- Tool geboren.

2.2 Hauptherausforderungen
Das in Java geschriebene DIFF-Tool kann das Problem des Aufrufs von PAAS-basierten Datendienstschnittstellen lösen, steht jedoch bei der tatsächlichen Verwendung vorhandener DIFF-Skripte vor den folgenden zwei Herausforderungen:
2.2.1 Probleme mit der Wiedergabeeffizienz anfordern
Einzelthread-Wiedergabe
Der Schnittstellenaufruf und der Ergebnisvergleich der aufgezeichneten Anforderungen werden von einem einzelnen Thread implementiert, der die Anforderungsliste durchläuft. Nachdem eine einzelne Anforderung die Schnittstelle der Online- und Testumgebung erfolgreich aufgerufen hat, werden die zurückgegebenen Ergebnisse verglichen. Erst nachdem der Vergleich abgeschlossen ist, gehen Sie einfach zurück zur nächsten Anfrage. Tatsächlich gibt es jedoch keine Aufrufsequenz zwischen der Wiedergabe der vorherigen Anfrage und der nächsten Anfrage. Diese Methode, einen einzelnen Thread für die Anforderungswiedergabe zu verwenden, verringert die Ausführungseffizienz erheblich und führt zu einer zu langen Diff-Ausführungszeit.
Schnittstelle für synchrone Anrufe
Darüber hinaus werden die Aufrufe der Online- und Testumgebungsschnittstellen synchronisiert. Nachdem die Schnittstelle einer Umgebung ein Ergebnis zurückgibt, wird die nächste Schnittstelle aufgerufen. Ebenso besteht keine Abhängigkeit zwischen den Schnittstellenaufrufen der beiden Umgebungen. Der Rückgabewert einer Umgebungsschnittstelle hat keinen Einfluss auf den Aufruf der nächsten Schnittstelle. Sie müssen lediglich sicherstellen, dass beide Umgebungsschnittstellenaufrufe Rückgabewerte haben Vergleichen Sie dann die Ergebnisse. Kann.
2.2.2 Das Problem falsch positiver Ergebnisse bei Vergleichsergebnissen
Indizes sind inkonsistent
Die Rückgabeparameterstruktur des PAAS-Protokolls ist wie folgt. Es ist ersichtlich, dass der Datensatz body.data die meisten Informationselemente enthält und das Hauptvergleichsziel ist. Der Datenindex meteData.metaIndex definiert die spezifischen Felder, die durch jeden Wert in dargestellt werden Die Unterelemente des Datensatzes. Nennen Sie beispielsweise die drei Werte in [1234,12345,41, „11068“], die jeweils das übergeordnete Bestellvolumen der Transaktion, den Transaktionsbetrag und die Hauptmarken-ID darstellen. Wenn die Rückgabewert-Feldnamenindizes der beiden Umgebungsschnittstellen nicht konsistent sind, die Werte, die den tatsächlich gemäß dem Index erhaltenen Feldnamen entsprechen, jedoch gleich sind, wird in diesem Fall die Datensammlungs-Untersammlung zum Vergleich direkt durchlaufen , erhalten Sie eine andere Schlussfolgerung. Tatsächlich sind die beiden Rückgabewerte jedoch konsistent, was zu falsch positiven Ergebnissen in den Vergleichsergebnissen führt, wie in der folgenden Abbildung dargestellt.
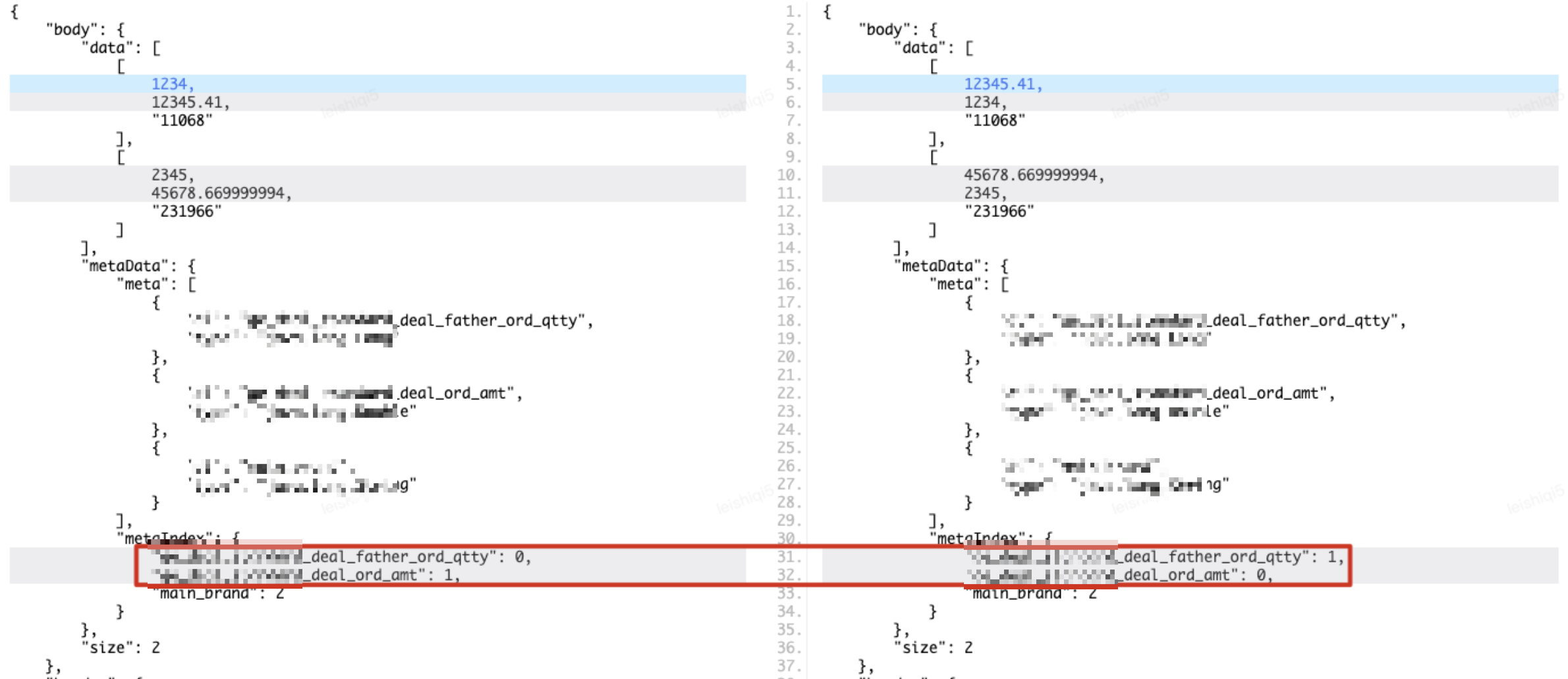
ungeordnetes Array
Zusätzlich zu inkonsistenten Feldnamenindizes, die im Vergleich zu falsch positiven Ergebnissen führen können, kann es sein, dass jede Untersammlung der Datensatzdaten nicht in der richtigen Reihenfolge ist. In den Rückgabeparameterdaten des Beispiels enthält die erste Untersammlung zwei Indikatoren der Hauptmarke „11068“ und die zweite Untersammlung enthält zwei Indikatoren der Hauptmarke „231966“. Wenn die Rückgabeparameterdaten aus einer anderen Umgebung stammen Schnittstelle, die Hauptmarke einer Untersammlung ist „231966“ und die Hauptmarke der zweiten Untersammlung ist „11068“. Direkter Durchlauf und Vergleich führen in diesem Fall zu Unterschieden in den Vergleichsergebnissen, aber tatsächlich es ist auch ein falsches Positiv.

2.3. Lösungsideen
2.3.1 Parallelität bei Durchlaufanforderungen und Asynchronität bei der Verkehrswiedergabe, um das Problem der Effizienz der Anforderungswiedergabe zu lösen
Aus der Analyse in der Hauptherausforderung geht hervor, dass der Zeitverbrauch einer DIFF-Ausführung = die Anzahl der Anforderungen, die wiedergegeben werden müssen * (der Zeitverbrauch der Schnittstellenaufrufe in den beiden Umgebungen + der Zeitverbrauch des Vergleichs). . Aus der zeitaufwändigen Aufteilungsformel ist ersichtlich, dass die Optimierung der Effizienz der DIFF-Ausführung in zwei Richtungen erreicht werden kann: Anforderung paralleler Wiedergabe und asynchroner Schnittstellenaufruf.
2.3.2 Die Vereinheitlichung des Feldindex und die sekundäre Sortierung werden implementiert, um das Problem falsch positiver Ergebnisse in Vergleichsergebnissen zu lösen
Für die Struktur der Rückgabeparameter des PAAS-Protokolls ist es notwendig, die Vereinheitlichung der Rückgabewertfeldindizes der beiden Umgebungen und die Reihenfolge der Untersammlungen innerhalb des Datensatzes sicherzustellen, um null Fehlalarme in den Vergleichsergebnissen zu erzielen , sodass beim Vergleich der Rückgabewertergebnisse keine Kontrastanomalien auftreten.
Die einheitliche Implementierung des Feldindex ist relativ einfach. Ordnen Sie die Position jedes Werts in der Datenuntersammlung im Rückgabewert einer anderen Umgebungsschnittstelle basierend auf dem Feldindex metaIndex des Rückgabewerts einer Umgebungsschnittstelle neu an, um dies sicherzustellen Jeder Wert in der Datenuntersammlung wird durchlaufen. Die entsprechenden Feldnamen sind konsistent.
Die sekundäre Sortierung dient dazu, das Ordnungsproblem zwischen Datenteilmengen zu lösen. Der Grund, warum die Betonung auf „sekundär“ liegt, liegt darin, dass die Teilmenge mehrere Werte enthalten kann. Wenn nur ein Wert sortiert wird, kann die Teilmenge nicht vollständig garantiert werden Daher ist es notwendig, einen sekundären Sortierer zu implementieren, um mehrere Werte in der Teilmenge als Grundlage für die Sortierung auszuwählen , um die Reihenfolge zwischen Teilmengen stabil zu machen und die Zuverlässigkeit der Vergleichsergebnisse sicherzustellen.
3. Gesamtstruktur

4. Kernpunkte des Designs
4.1 Fordern Sie eine Optimierung der Wiedergabeeffizienz an
4.1.1 Deduplizierung vor der Wiedergabe anfordern
Vor der Entwicklung des Datendienst-DIFF-Tools bestand ein Ziel darin, „ jede Wiedergabeanforderung aussagekräftig zu machen “. Bei schreibgeschützten Datenabfragediensten wird es jeden Tag eine große Anzahl wiederholter Anfragen geben. Wenn die Anfragen nicht dedupliziert werden, wird ein großer Teil der Wiedergabeanfragen wiederholt. Solche Anfragen werden für die Wiedergabe und DIFF verwendet, was nicht der Fall ist Nur eine Verschwendung von Ressourcen, die die Zusammenfassung der endgültigen Vergleichsergebnisse beeinträchtigt, hat noch keine Bedeutung. Daher ist eine Deduplizierungsverarbeitung vor der Anforderung der Wiedergabe erforderlich.
Die vom DIFF-Tool übernommene Methode zur Deduplizierung von Anforderungsparametern ist zunächst die HashSet-Methode. Bevor die Schnittstelle zum Abspielen des Datenverkehrs aufgerufen wird, wird die Deduplizierung der Anforderung in einem HashSet gespeichert. Nach Abschluss der Deduplizierung wird das HashSet für die Datenverkehrswiedergabe durchlaufen DIFF-Ausführung. Obwohl diese Methode Duplikate effektiv entfernen kann, ist die HashSet-Deduplizierungseffizienz bei tatsächlicher Verwendung gering, wenn die Anzahl der Anforderungen, die Diff erfordern, zu groß ist oder die Anforderungsparameter zu groß sind (z. B. beim Abfragen der Finanzindikatoren von 2000 angegebenen SKUs). relativ niedrig, und die Traversal-Deduplizierung von 50.000 großen Anforderungen dauert mehr als 10 Minuten und beansprucht viel Speicher. Wenn der Speicher des Pipeline-Containers, der DIFF ausführt, klein ist, schlägt die DIFF-Ausführung direkt fehl.
Um die Deduplizierungseffizienz von Anforderungen zu verbessern, wird die Bloom-Filtermethode verwendet , um eine Deduplizierung zu erreichen. Der belegte Speicher ist kleiner als bei der HashSet-Methode, und die Effizienz bei der Bestimmung, ob Duplikate vorhanden sind, ist ebenfalls relativ hoch. Sie eignet sich für Deduplizierungsvorgänge großer Datenmengen .
for (int i = 0; i < maxLogSize; i++) {
String reqParam = fileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//请求重复,跳过此请求
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//请求不重复,执行接口调用和DIFF
}4.1.2 Parallelität beim Durchlaufen von Anforderungen
Verwenden Sie beim Durchlaufen von Anforderungen die Methode „execute()“, um die Anforderungswiedergabe und DIFF-Ausführungsaufgaben an den Thread-Pool zu senden. Jede Anforderung generiert eine unabhängige Aufgabe und Aufgaben werden parallel ausgeführt, wodurch die Ausführungseffizienz des gesamten DIFF-Prozesses verbessert wird. Da DIFF nach Abschluss jeder Wiedergabe- und Ergebnisvergleichsanforderung eine Zusammenfassung und Anzeige der Vergleichsunterschiede durchführen muss, muss der Hauptthread blockiert werden und warten, bis alle Unterthreads der Wiedergabevergleichsaufgabe beendet sind, bevor der Hauptthread gestartet wird, um eine Zusammenfassung durchzuführen Analyse der Differenzergebnisse.
Um die Aufrufzeitanforderungen zwischen Haupt- und Unterthread zu erfüllen, wird der CountDownLatch-Zähler verwendet. Die maximale Anzahl von Anforderungen n wird während der Initialisierung festgelegt. Immer wenn ein Unterthread endet, wird der Zähler um eins dekrementiert. Wenn der Zähler wird 0, der Hauptthread, der gewartet hat, wacht auf und fasst die Differenzergebnisse zusammen. .
Dies beinhaltet wiederum das Problem der Thread-Pool-Ablehnungsrichtlinie. Wenn Sie die Standardrichtlinie „AbortPolicy“ des Thread-Pools verwenden, aber keine Ausnahmen abfangen und den Zähler während der Ausnahmebehandlung um eins verringern, wird der CountDownLatch-Zähler dies tun, wenn der Thread-Pool keine neuen Aufgaben annehmen kann niemals 0 sein, der Hauptthread ist immer blockiert und der DIFF-Prozess wird niemals enden. Um eine reibungslose Ausführung von DIFF und die Ausgabe von Vergleichsergebnissen unter ungewöhnlichen Umständen zu ermöglichen und sicherzustellen, dass jede Anforderung wiedergegeben und verglichen werden kann, wird hier CallerRunsPolicy verwendet, um abgelehnte Aufgaben zur Ausführung an den Aufrufer zurückzugeben.
//初始化计数器
CountDownLatch countDownLatch = new CountDownLatch(maxLogSize);
log.info("开始读取日志");
for (int i = 0; i < maxLogSize; i++) {
String reqParam = asciiFileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//有重复请求,跳出本次循环,计数器减一
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//向线程池提交回放和对比任务
threadPoolTaskExecutor.execute(() -> {
try {
//执行接口调用和返回结果对比
}
} catch (Exception e) {
} finally {
//子线程一次执行完成,计数器减一
countDownLatch.countDown();
}
});
}
//阻塞主线程
countDownLatch.await();
//等待计数器为0后,开始汇总对比结果4.1.3 Asynchron bei Wiedergabeanforderung
JSF bietet eine asynchrone Aufrufmethode für die Schnittstelle, die ein CompletableFuture<T>-Objekt zurückgibt. Sie können die Methode thenCombine einfach verwenden, um die Testumgebungsschnittstelle und den Rückgabewert des Testumgebungsschnittstellenaufrufs zu kombinieren, einen Vergleich der Rückgabewerte durchzuführen und die zurückzugeben Vergleichsergebnis.
//测试环境接口异步请求
CompletableFuture<UResData> futureTest = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceTest.fetchBizData(param)
);
//线上环境接口异步请求
CompletableFuture<UResData> future = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceOnline.fetchBizData(param)
);
//使用thenCombine对futureTest和future执行结果合并处理
CompletableFuture<ResCompareData> resultFuture = futureTest.thenCombine(future, (res1, res2) -> {
//执行对比,返回对比结果
return resCompareData;
});
//获取对比结果的值
return resultFuture.join();4.2 Optimierung der Fehlalarmrate
4.2.1 Vereinheitlichung des Feldindex
Der Kern der Feldindexvereinheitlichung besteht darin, die Zuordnungsbeziehung zwischen demselben Feldnamenindex zwischen zwei Rückgabewerten zu finden. Beispielsweise entspricht der Indexindex1 des Feldnamens a im Rückgabewert A dem Indexindex2 des Feldnamens a im Rückgabewert B . Nachdem alle Zuordnungsbeziehungen gefunden wurden, wird die Reihenfolge der Felder im Rückgabewert-Array B neu angeordnet.
List<List<Object>> tmp = new ArrayList<>();
int elementNum = metaIndex1.size();
HashMap<Integer, Integer> indexToIndex = new HashMap<>(elementNum);
//获取索引映射关系
for (int i = 0; i < elementNum; i++) {
String indicator = getIndicatorFromIndex(i, metaIndex2);
Integer index = metaIndex1.get(indicator);
indexToIndex.put(i, index);
}
//根据映射关系重新排放字段,生成新的数据集合
for (List<Object> dataElement : data2) {
List<Object> tmpList = new ArrayList<>();
Object[] objects = new Object[elementNum];
for (int i = 0; i < dataElement.size(); i++) {
objects[indexToIndex.get(i)] = dataElement.get(i);
}
Collections.addAll(tmpList, objects);
tmp.add(tmpList);
}4.2.2 Sekundärsortierung von Datensätzen
Die Datensatzdaten enthalten mehrere Teilmengen, und jede Teilmenge ist eine Kombination aus Attributwerten und Indikatoren. Um eine Reihenfolge zwischen Untersammlungen zu erreichen, müssen die Indizes aller Attributfelder ermittelt und ein sekundärer Sortierer implementiert werden, der die Werte aller Attributfelder als Sortierkriterium verwendet.
Im Allgemeinen ist der Datentyp von Attributfeldern der Typ String, es gibt jedoch auch Sonderfälle. Wenn beispielsweise sku_id als Attributwert verwendet wird, ist der von sku_id zurückgegebene Datentyp der Typ Long. Um die Universalität und Zuverlässigkeit des sekundären Sortierers zu realisieren, werden zunächst alle Felder vom Typ String zum Sortieren und dann Felder vom Typ Long zum Sortieren verwendet. Wenn kein Feld vom Typ String vorhanden ist, werden alle Felder vom Typ Long sortiert.
List<Integer> strIndexList = new ArrayList<>();
List<Integer> longIndexList = new ArrayList<>();
// 保存所有String和Long类型字段的索引
for (int i = 0; i < size; i++) {
if (data.get(0).get(i) instanceof String) {
strIndexList.add(i);
}
if (data.get(0).get(i) instanceof Long || data.get(0).get(i) instanceof Integer) {
longIndexList.add(i);
}
}
//首选依据String类型字段排序
if (!strIndexList.isEmpty()) {
//初始化排序器
Comparator<List<Object>> comparing = Comparator.comparing(o -> ((String) o.get(strIndexList.get(0))));
for (int i = 1; i < strIndexList.size(); i++) {
int finalI = i;
//遍历剩余String字段,实现任意长度次级排序器
comparing = comparing.thenComparing(n -> ((String) n.get(strIndexList.get(finalI))));
}
for (int i = 0; i < longIndexList.size(); i++) {
int finalI = i;
comparing = comparing.thenComparingLong(n -> Long.parseLong(n.get(longIndexList.get(finalI)).toString()));
}
sortedList = data.stream().sorted(comparing).collect(Collectors.toList());
}4.3 DIFF-Effekt des PAAS-Datendienstes
Nach der Optimierung der Anforderungswiedergabeeffizienz und der Fehlalarmrate können der Zeitaufwand und die Vergleichsergebnisse einer DIFF-Ausführung des Datendienstes den Anforderungen vorhandener F&E-Selbsttests und Regressionen vor dem Online-Gehen gerecht werden. Die folgende Abbildung zeigt einen DIFF-Bericht des GoldenEye-Handels-Echtzeitdienstes. Bei der Konfiguration von vier Arbeitsthreads dauerte die Anforderungswiedergabe nach der Deduplizierung von 40.000 Anforderungen 570 Sekunden. Die Vergleichsergebnisse können auch die Datenunterschiede deutlich zeigen. Um die Untersuchung von Datenunterschieden zu erleichtern, werden bei der Anzeige der Differenzvergleichsergebnisse die Feldnamen vor den Werten gespleißt, um eine manuelle Suche nach den Feldnamen zu vermeiden, die den Differenzwerten basierend auf dem Index entsprechen.

5. Umsetzung
5.1 Datendienst-Testzugriffspipeline
Die Pipeline stellt Download-Code-Atome, Kompilierungs-Atome und benutzerdefinierte Shell-Skript-Atome bereit. Diese drei Atome können die Ausführung von DIFF-Aufgaben auslösen. Mit Hilfe dieser Fähigkeit der Pipeline wurde die Fähigkeit von DIFF-Tools in die Testzugriffspipeline von GoldenEye eingeführt. GoldenEye handelt mit Echtzeit- und Offline-Datendiensten. Die Testzugriffspipeline umfasst die Kompilierung und JDOS-Bereitstellung von Testzweigcodes, die Verkehrswiedergabe und den Vergleich der Ausführungsergebnisse sowie Statistiken zur Schnittstellentestabdeckung während des DIFF-Prozesses. Durch die Online-Verkehrswiedergabe für DIFF-Tests erreichte die Leitungsabdeckung des Transaktions-Offline-Dienstes und des Echtzeit-Dienstcodes 51 % bzw. 65 % .

Transaktions-Offline-Service-Testzugriffspipeline
Transaktions-Echtzeit-Servicetest-Zugriffspipeline
5.2 Service-F&E-Selbsttest zur Verbesserung der Effizienz
Zusätzlich zu dem DIFF-Tool, das in der Testzulassungspipeline eine Rolle spielt, haben wir auch eine Pipeline eingerichtet, die DIFF manuell auslösen kann, um F&E-Selbsttests zu ermöglichen und die Effizienz zu verbessern. Derzeit ist die DIFF-Pipeline in mehreren Datendiensten von GoldenEye PAAS implementiert, darunter Transaktions-Offline-Dienste, Echtzeit-Transaktionsdienste und Finanz-Offline-Dienste. Die folgende Abbildung zeigt die monatlichen Ausführungszeiten der DIFF-Pipeline dieser drei Datendienste. Die kumulierten Ausführungszeiten im September betragen : 66-mal DIFF .

*Datenquelle: Trendstatistik zur Pipeline-Ausführung
Derzeit verfügt das DIFF-Tool bereits über die Möglichkeit, den Schwellenwert für die Differenzrate anzupassen, Schlüsselwörter zu filtern und auszuschließen sowie Filterbedingungen und Anforderungsindikatoren für PAAS-Anfragen von Indikatordiensten anzupassen. Diese Anpassungsfähigkeit für PAAS-basierte Anfragen für Indikatordienste spielt eine gewisse Rolle bei der täglichen Bedarfsiteration und der technischen Transformation.
Beispielsweise wurde die Echtzeit-Abfrage-Engine für den Handel mit GoldenEye von Elasticsearch auf Doris umgestellt. Diese Transformation erforderte eine Menge DIFF-Regressionstests. Während dieses Prozesses stellte R&D fest, dass es einige Unterschiede in den Berechnungsmethoden von Elasticsearch und Doris für Deduplizierungsindikatoren (z. B. Unterelementmengen) gibt. Infolgedessen ist die Differenzrate der mit den beiden Engines abgefragten Deduplizierungsindikatoren höher als die anderer Nicht-Deduplizierungsindikatoren. Indikatoren (z. B. Menge) beeinträchtigen die Anzeige der endgültigen Vergleichsergebnisse und sind nicht förderlich für die Entdeckung wirklich unterschiedlicher Anforderungen. Um dieses Problem zu lösen, bieten wir die Möglichkeit , den Indikatordienst PAAS-basierte Anforderungsindikatoren anzupassen . Sie können die Wiedergabeanforderung so einstellen, dass nur Nicht-Deduplizierungsindikatoren abgefragt werden, wodurch die Beeinträchtigung durch Deduplizierungsindikatoren vermieden und der Fortschritt des Regressionstests gefördert wird .
6. Zusammenfassung
In diesem Artikel werden die beiden Hauptprobleme der DIFF-Effizienz und der Zuverlässigkeit der Vergleichsergebnisse vorgestellt, mit denen das Datenqualitätsteam von GoldenEye während der Erstellung des DIFF-Tools für den Datendienst konfrontiert war. Außerdem werden die Lösungen und praktischen Erfahrungen bei der Implementierung der beiden oben genannten Problemtypen und der entsprechenden Probleme erläutert Herausforderungen.
6.1 Vorteile kundenspezifischer DIFF-Tools
Im Vergleich zu JD.coms interner professioneller Aufnahme- und Wiedergabeplattform R2 ist unser DIFF-Tool in Bezug auf Verkehrsaufzeichnung, Linkverfolgung, Vielseitigkeit und andere Funktionen bei weitem unzureichend oder fehlt. Aus Sicht der DIFF-Anpassung des PAAS-Datendienstes wird die von unserem DIFF-Tool im Anforderungsanpassungs- und Vergleichsprozess vorgenommene Optimierung jedoch derzeit von dieser universellen Plattform nicht unterstützt.
6.2 Zukunftsaussichten
Derzeit wird das DIFF-Tool für automatisierte Regressionstests verwendet. Die Codezeilenabdeckungsrate des Schnittstellentests des Offline-Handelsdienstes und des Echtzeitdienstes von GoldenEye beträgt etwa 50 % , was zeigt, dass tägliche Online-Abfrageszenarien nicht alle Codezweige abdecken können. Um die Codezeilenabdeckung des DIFF-Tests zu verbessern, werden wir erwägen, den Abdeckungsbericht später zu analysieren, um die Szenarien herauszufinden, die nicht von der Online-Abfrage abgedeckt werden , und einen festen Satz von Anforderungsanwendungsfällen zu bilden. Während des DIFF-Tests werden wir spielen Unterstützt sowohl den Online-Verkehr als auch die Anwendungsfälle mit festen Anforderungen. Wird festgelegt, um die Zeilenabdeckung von DIFF-Tests zu verbessern.
Lei Jun: Die offizielle Version von Xiaomis neuem Betriebssystem ThePaper OS wurde verpackt. Das Popup-Fenster auf der Lotterieseite der Gome App beleidigt seinen Gründer. Ubuntu 23.10 ist offiziell veröffentlicht. Sie können den Freitag genauso gut für ein Upgrade nutzen! Ubuntu 23.10-Release-Folge: Das ISO-Image wurde dringend „zurückgerufen“, da es Hassreden enthielt. Ein 23-jähriger Doktorand behob den 22 Jahre alten „Ghost Bug“ in Firefox. RustDesk Remote Desktop 1.2.3 wurde veröffentlicht, verbessertes Wayland zur Unterstützung von TiDB 7.4 Release: Offiziell kompatibel mit MySQL 8.0. Nach dem Abziehen des Logitech USB-Empfängers stürzte der Linux-Kernel ab. Der Master verwendete Scratch, um den RISC-V-Simulator zu rubbeln, und führte den Linux-Kernel erfolgreich aus. JetBrains startete Writerside, ein Tool zur Erstellung technischer Dokumente.Autor: JD Retail Lei Shiqi
Quelle: JD Cloud Developer Community Bitte geben Sie beim Nachdruck die Quelle an