Inhaltsverzeichnis
1. Hauptschritte der Zielverfolgung
2. Der Prozess des traditionellen Sortieralgorithmus
3.Deepsort-Algorithmus-Prozess
4. Gesamtcode für die Zielverfolgung
4.1 Im Configs-Dateiverzeichnis:
4.2 Im Verzeichnis deep_sort/deep_sort/deep:
4.3 Im Verzeichnis deep_sort/deep_sort/sort:
DeepSORT (Deep Learning based SORT) ist ein auf Deep Learning basierender visueller Zielverfolgungsalgorithmus, der Deep Learning und den traditionellen Zielverfolgungsalgorithmus SORT (Simple Online and Realtime Tracking) kombiniert.
DeepSORT erkennt das Ziel in jedem Bildbild basierend auf Zieldetektoren (wie YOLO, Faster R-CNN usw.), verwendet die Multi-Feature-Fusion-Technologie (Muti-Feature-Fusion), um das Ziel darzustellen und zu beschreiben, und verwendet dann die SORT-Algorithmus zur Erkennung des Ziels. Spur. Auf der Grundlage des SORT-Algorithmus führt DeepSORT das Re-IDentification (Re-ID)-Modell ein, um das Problem der Bestimmung der Ziel-ID zu lösen. Das Re-ID-Modell ermittelt die eindeutige ID des Ziels, indem es die Ähnlichkeit des Ziels berechnet mehrere Rahmenbilder.
Die Vorteile des DeepSORT-Algorithmus sind: hohe Genauigkeit, starke Robustheit und gute Anpassungsfähigkeit an Zielokklusion und -deformation. Es wird häufig in Bereichen wie der Verfolgung von Fußgängern, Fahrzeugen und anderen Zielen sowie der intelligenten Videoüberwachung eingesetzt.
1. Hauptschritte der Zielverfolgung
- Holen Sie sich Original-Videobilder
- Verwenden Sie einen Objektdetektor, um Objekte in Videobildern zu erkennen
- Extrahieren Sie die Merkmale im Rahmen des erkannten Ziels, einschließlich Erscheinungsmerkmale (praktisch für den Merkmalsvergleich, um einen ID-Wechsel zu vermeiden) und Bewegungsmerkmale (Bewegungsmerkmale sind praktisch für die Vorhersage durch den Kalman-Filter).
- Berechnen Sie den Übereinstimmungsgrad des Ziels in den beiden Frames davor und danach (unter Verwendung des ungarischen Algorithmus und des Kaskadenabgleichs) und weisen Sie jedem verfolgten Ziel eine ID zu.
2. Der Prozess des traditionellen Sortieralgorithmus
Der Vorgänger von Deepsort ist der Sortieralgorithmus. Der Kern des Sortieralgorithmus ist der Kalman-Filteralgorithmus und der ungarische Algorithmus.
Funktion des Kalman-Filteralgorithmus: Die Hauptfunktion dieses Algorithmus besteht darin, die aktuelle Reihe von Bewegungsvariablen zu verwenden, um die Bewegungsvariablen des nächsten Moments vorherzusagen. Das erste Erkennungsergebnis wird jedoch zum Initialisieren der Bewegungsvariablen des Kalman-Filters verwendet.
Die Rolle des ungarischen Algorithmus: Einfach ausgedrückt löst er das Zuordnungsproblem, das darin besteht, eine Gruppe von Erkennungsrahmen und die von Kalman vorhergesagten Rahmen zuzuweisen, damit die von Kalman vorhergesagten Rahmen den Erkennungsrahmen finden können, der am besten zu sich selbst passt Der Tracking-Effekt.
Der Sortierworkflow ist in der folgenden Abbildung dargestellt:
Erkennungen sind vom Ziel erkannte Frames. Bei Tracks handelt es sich um Trackinformationen.
(1) Erstellen Sie entsprechende Tracks basierend auf den erkannten Ergebnissen des ersten Frames. Initialisieren Sie die Bewegungsvariablen des Kalman-Filters und sagen Sie ihre entsprechenden Frames über den Kalman-Filter voraus.
(2) Ordnen Sie den vom Ziel in diesem Frame erkannten Frame nacheinander dem von Tracks im vorherigen Frame vorhergesagten Frame zu und berechnen Sie dann die Kostenmatrix (Kostenmatrix, die Berechnungsmethode ist 1-IOU) anhand des IOU-Matching-Ergebnisses .
(3) Verwenden Sie alle in (2) erhaltenen Kostenmatrizen als Eingabe des ungarischen Algorithmus, um lineare Matching-Ergebnisse zu erhalten. Zu diesem Zeitpunkt erhalten wir drei Arten von Ergebnissen. Die erste ist die Nichtübereinstimmung der Tracks (nicht übereinstimmende Tracks). Wir löschen direkt die nicht übereinstimmenden Tracks; der zweite ist die Nichtübereinstimmung der Erkennungen (nicht übereinstimmende Erkennungen), wir initialisieren solche Erkennungen in neue Tracks (neue Tracks); der dritte ist, dass der Erkennungsrahmen und der vorhergesagte Rahmen erfolgreich gepaart wurden, was bedeutet, dass wir den vorherigen verfolgt haben Frame und den nächsten Frame erfolgreich abgerufen und die entsprechenden Tracks-Variablen durch Kalman-Filterung aktualisiert.
(4) Wiederholen Sie die Schritte (2)–(3), bis das Videobild endet.
3.Deepsort-Algorithmus-Prozess
Da es sich bei dem Sortieralgorithmus noch um einen relativ groben Tracking-Algorithmus handelt, kann es besonders leicht passieren, dass die ID verloren geht, wenn ein Objekt verdeckt wird. Der Deepsort-Algorithmus fügt dem Sortieralgorithmus eine Matching-Kaskade und die Bestätigung neuer Trajektorien hinzu. Tracks werden in den bestätigten Status (bestätigt) und den unbestätigten Status (unbestätigt) unterteilt. Die neu generierten Tracks befinden sich im unbestätigten Status; unbestätigte Tracks müssen eine bestimmte Anzahl von Malen mit Erkennungen übereinstimmen (Standard ist 3), bevor sie in den Bestätigungsstatus umgewandelt werden können. Bestätigte Tracks müssen eine bestimmte Anzahl von Malen (standardmäßig 30 Mal) nicht mit Erkennungen übereinstimmen, bevor sie gelöscht werden.
Der Arbeitsablauf des Deepsort-Algorithmus ist in der folgenden Abbildung dargestellt:
Der Arbeitsablauf des gesamten Algorithmus ist wie folgt:
(1) Erstellen Sie entsprechende Spuren basierend auf den Erkennungsergebnissen des ersten Frames. Initialisieren Sie die Bewegungsvariablen des Kalman-Filters und sagen Sie ihre entsprechenden Frames über den Kalman-Filter voraus. Die Tracks müssen zu diesem Zeitpunkt noch unbestätigt sein.
(2) Ordnen Sie den vom Ziel in diesem Frame erkannten Frame nacheinander dem von Tracks im vorherigen Frame vorhergesagten Frame zu und berechnen Sie dann die Kostenmatrix (Kostenmatrix, die Berechnungsmethode ist 1-IOU) anhand des IOU-Matching-Ergebnisses .
(3) Verwenden Sie alle in (2) erhaltenen Kostenmatrizen als Eingabe des ungarischen Algorithmus, um lineare Matching-Ergebnisse zu erhalten. Zu diesem Zeitpunkt erhalten wir drei Arten von Ergebnissen. Die erste ist die Nichtübereinstimmung der Tracks (nicht übereinstimmende Tracks). Wir löschen direkt die nicht übereinstimmenden Tracks (da sich dieser Track in einem unsicheren Zustand befindet. Wenn er sich in einem bestimmten Zustand befindet, muss er nach Erreichen einer bestimmten Anzahl von Malen gelöscht werden (Standard 30 Mal)); der zweite Typ sind nicht übereinstimmende Erkennungen. Wir initialisieren solche Erkennungen in neue Tracks (neue Tracks); der dritte besteht darin, dass der Erkennungsrahmen und der vorhergesagte Rahmen erfolgreich gepaart werden, was bedeutet, dass wir den vorherigen Rahmen und den nächsten Rahmen erfolgreich verfolgt haben und die entsprechenden Erkennungen durch den Kalman-Filter geleitet und aktualisiert werden die entsprechende Tracks-Variable.
(4) Wiederholen Sie die Schritte (2)–(3), bis bestätigte Titel angezeigt werden oder das Videobild endet.
(5) Verwenden Sie die Kalman-Filterung, um die Frames vorherzusagen, die den Tracks im bestätigten Zustand und den Tracks im unbestätigten Zustand entsprechen. Kaskadieren Sie den Abgleich der Frames bestätigter Tracks und Erkennungen (bisher wurden bei jedem Abgleich von Tracks die Erscheinungsmerkmale und Bewegungsinformationen der Erkennungen gespeichert. Die ersten 100 Frames wurden standardmäßig gespeichert und die Erscheinungsmerkmale und Bewegungsinformationen wurden zur Kaskadierung verwendet mit Erkennungen. Der Abgleich erfolgt, da bestätigte Tracks und Erkennungen mit größerer Wahrscheinlichkeit übereinstimmen.
(6) Nach der Durchführung des Kaskadenabgleichs gibt es drei mögliche Ergebnisse. Der erste ist der Tracks-Abgleich. Solche Tracks aktualisieren ihre entsprechenden Tracks-Variablen durch Kalman-Filterung. Der zweite und dritte Typ ist die Nichtübereinstimmung zwischen Erkennungen und Tracks. Zu diesem Zeitpunkt werden die zuvor unbestätigten Tracks und nicht übereinstimmenden Tracks einzeln nach IOU mit nicht übereinstimmenden Erkennungen abgeglichen, und dann wird die Kostenmatrix basierend auf den IOU-Übereinstimmungsergebnissen berechnet . , seine Berechnungsmethode ist 1-IOU).
(7) Verwenden Sie alle in (6) erhaltenen Kostenmatrizen als Eingabe des ungarischen Algorithmus, um lineare Matching-Ergebnisse zu erhalten. Zu diesem Zeitpunkt erhalten wir drei Arten von Ergebnissen. Die erste ist die Nichtübereinstimmung der Tracks (nicht übereinstimmende Tracks). Wir löschen direkt die nicht übereinstimmenden Tracks (da sich dieser Track in einem unsicheren Zustand befindet. Wenn er sich in einem bestimmten Zustand befindet, muss er nach Erreichen einer bestimmten Anzahl von Malen gelöscht werden (Standard 30 Mal)); der zweite Typ sind nicht übereinstimmende Erkennungen. Wir initialisieren solche Erkennungen in neue Tracks (neue Tracks); der dritte besteht darin, dass der Erkennungsrahmen und der vorhergesagte Rahmen erfolgreich gepaart werden, was bedeutet, dass wir den vorherigen Rahmen und den nächsten Rahmen erfolgreich verfolgt haben und die entsprechenden Erkennungen durch den Kalman-Filter geleitet und aktualisiert werden die entsprechende Tracks-Variable.
(8) Wiederholen Sie die Schritte (5)–(7) bis zum Ende des Videobilds.
4. Gesamtcode für die Zielverfolgung
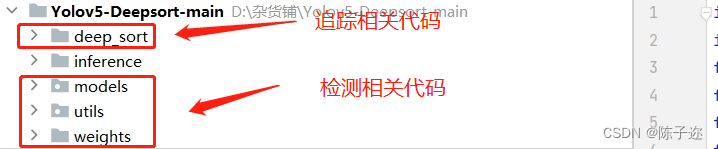
Im Folgenden werden die Funktionen des wichtigen Codes zur Zielverfolgung erläutert.
Zunächst ist der Code in drei Teile unterteilt:
- Zugehörige Codes und Gewichte zur Zielverfolgung
- Codes und Gewichte im Zusammenhang mit der Zielerkennung. Hier wird der Zielerkennungsalgorithmus yolov5.5 verwendet
- Anruferkennungs- und Tracking-Code-bezogene Py-Dateien
Zum Inhalt der Zielerkennung können Sie andere Artikel lesen
Hier erklären wir hauptsächlich den Codeteil im Zusammenhang mit der Zielverfolgung. Die Haupt-PY-Datei ist in der folgenden Abbildung dargestellt: Die Hauptfunktionen jeder PY-Datei werden einzeln erläutert.

Die Hauptfunktion
4.1 Im Configs-Dateiverzeichnis:
deep_sort.yaml: Diese Yaml-Datei speichert hauptsächlich einige Parameter.
(1) Der Verzeichnispfad, der die Merkmalsextraktionsgewichte enthält;
(2) Maximaler Kosinusabstand, der für den Kaskadenabgleich verwendet wird. Wenn er größer als der Schwellenwert ist, wird er ignoriert.
(3) Konfidenzschwelle für Erkennungsergebnisse
(4) Nicht-maximaler Unterdrückungsschwellenwert, auf 1 gesetzt, um anzuzeigen, dass keine Unterdrückung erfolgt
(5) Maximaler IOU-Schwellenwert
(6) Maximale Lebensdauer, dh wenn das Objekt nach dem MAX_AGE-Frame nicht verfolgt wird, wird die Flugbahn in den gelöschten Status geändert.
(7) Die höchste Trefferzahl. Wenn die Trefferzahl erreicht wird, wird der Zustand von „unsicher“ in „bestimmt“ umgewandelt.
(8) Die maximale Anzahl von Frames zum Speichern von Funktionen. Wenn die Anzahl der Frames überschritten wird, wird eine fortlaufende Speicherung durchgeführt.
4.2 Im Verzeichnis deep_sort/deep_sort/deep:
ckpt.t7: Dies ist eine Gewichtsdatei des Merkmalsextraktionsnetzwerks. Diese Gewichtsdatei wird nach dem Training des Merkmalsextraktionsnetzwerks generiert. Dies ist praktisch, um Merkmale im Zielrahmen während der Zielverfolgung zu extrahieren und einen ID-Wechsel während der Zielverfolgung zu vermeiden.
evaluieren.py: Berechnen Sie die Genauigkeit des Merkmalsextraktionsmodells.
feature_extractor.py: Extrahieren Sie die Features im entsprechenden Begrenzungsrahmen und erhalten Sie ein Feature mit fester Dimension als Repräsentant des Begrenzungsrahmens zur Verwendung bei der Berechnung der Ähnlichkeit.
model.py: Feature-Extraktionsnetzwerkmodell, das zum Extrahieren der Gewichte des Trainings-Feature-Extraktionsnetzwerks verwendet wird.
train.py: Python-Datei zum Trainieren des Feature-Extraktionsnetzwerks
test.py: Testen Sie die Leistung des trainierten Feature-Extraktionsnetzwerks
4.3 Im Verzeichnis deep_sort/deep_sort/sort:
Erkennung.py: Speichert einen Erkennungsrahmen, der die Zielerkennung besteht, sowie die Vertrauenswürdigkeit des Rahmens und der erfassten Merkmale; außerdem werden Konvertierungsmethoden für verschiedene Formate des Rahmens bereitgestellt.
iou_matching.py: Berechnen Sie die IOU zwischen zwei Frames.
kalman_filter.py: Der relevante Code des Kalman-Filters, der hauptsächlich den Kalman-Filter verwendet, um die Flugbahninformationen des Erkennungsrahmens vorherzusagen.
linear_assignment.py: Verwenden Sie den ungarischen Algorithmus, um den vorhergesagten Trajektorienrahmen und den Erkennungsrahmen abzugleichen, um den besten Übereinstimmungseffekt zu erzielen.
nn_matching.py: Berechnen Sie den nächsten Kragenabstand, indem Sie den euklidischen Abstand, den Kosinusabstand und andere Abstände berechnen.
preprocessing.py: Nicht-maximaler Unterdrückungscode, der den nicht-maximalen Unterdrückungsalgorithmus verwendet, um den optimalen Erkennungsrahmen auszugeben.
track.py: Speichert hauptsächlich Trajektorieninformationen, einschließlich der Positions- und Geschwindigkeitsinformationen des Trajektorienrahmens, der ID und des Status des Trajektorienrahmens, von denen es drei Zustände gibt, einer ist der ermittelte Zustand, der unsichere Zustand und der gelöschte Zustand .
tracker.py: Speichert alle Flugbahninformationen, ist für die Initialisierung des ersten Frames, die Vorhersage und Aktualisierung des Kalman-Filters sowie für den Kaskadenabgleich und den IOU-Abgleich verantwortlich.
deep_sort/deep_sort/deep_sort.py: Die Gesamtkapselung von Deepsort, wodurch ein Gesamteffekt der Deepsort-Verfolgung erzielt wird.
deep_sort/utils: Zu den wichtigsten gehören hier Python-Codes für verschiedene Tools, z. B. Bilderrahmen-Tools, Tools zum Speichern von Protokollen usw.
Link: https://pan.baidu.com/s/1uORzJIav2z2SXMqaBfJ5pQ
Extraktionscode: ztaw
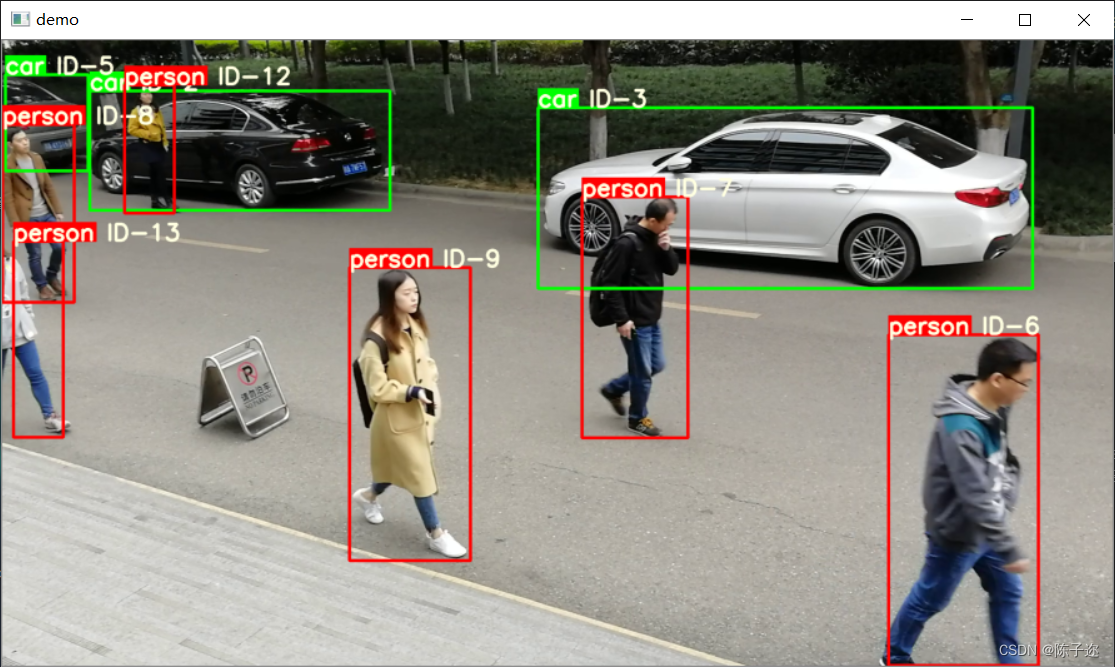
Führen Sie die Demo aus:
Ergebnis
Im nächsten Kapitel wird erklärt, wie Sie Ihr eigenes Feature-Extraktionsnetzwerk trainieren