Wussten Sie, dass die Art und Weise, wie Sie Ihren Text auszeichnen, Ihr Sprachmodell beeinflussen oder zerstören kann? Wollten Sie schon immer Dokumente mit einer seltenen Sprache oder Fachdomäne auszeichnen? Das Aufteilen von Text in Markup ist keine lästige Pflicht; es ist das Tor zur Umwandlung von Sprache in umsetzbare Informationen. In dieser Geschichte erfahren Sie alles, was Sie über Tokenisierung wissen müssen, nicht nur für BERT, sondern für jeden LL.M.-Studiengang.
In meinem letzten Artikel haben wir BERT besprochen, seine theoretischen Grundlagen und Trainingsmechanismen untersucht und diskutiert, wie man es verfeinern und ein Frage-Antwort-System erstellen kann. Während wir nun die Komplexität dieses bahnbrechenden Modells weiter erforschen, ist es an der Zeit, uns auf einen der unbesungenen Helden zu konzentrieren: die Tokenisierung.
Ich verstehe: Die Tokenisierung scheint das letzte langweilige Hindernis zwischen Ihnen und dem aufregenden Prozess des Modelltrainings zu sein. Glauben Sie mir, das dachte ich früher. Aber ich möchte Ihnen sagen, dass die Tokenisierung nicht nur ein „notwendiges Übel“ ist, sondern eine eigenständige Kunstform.
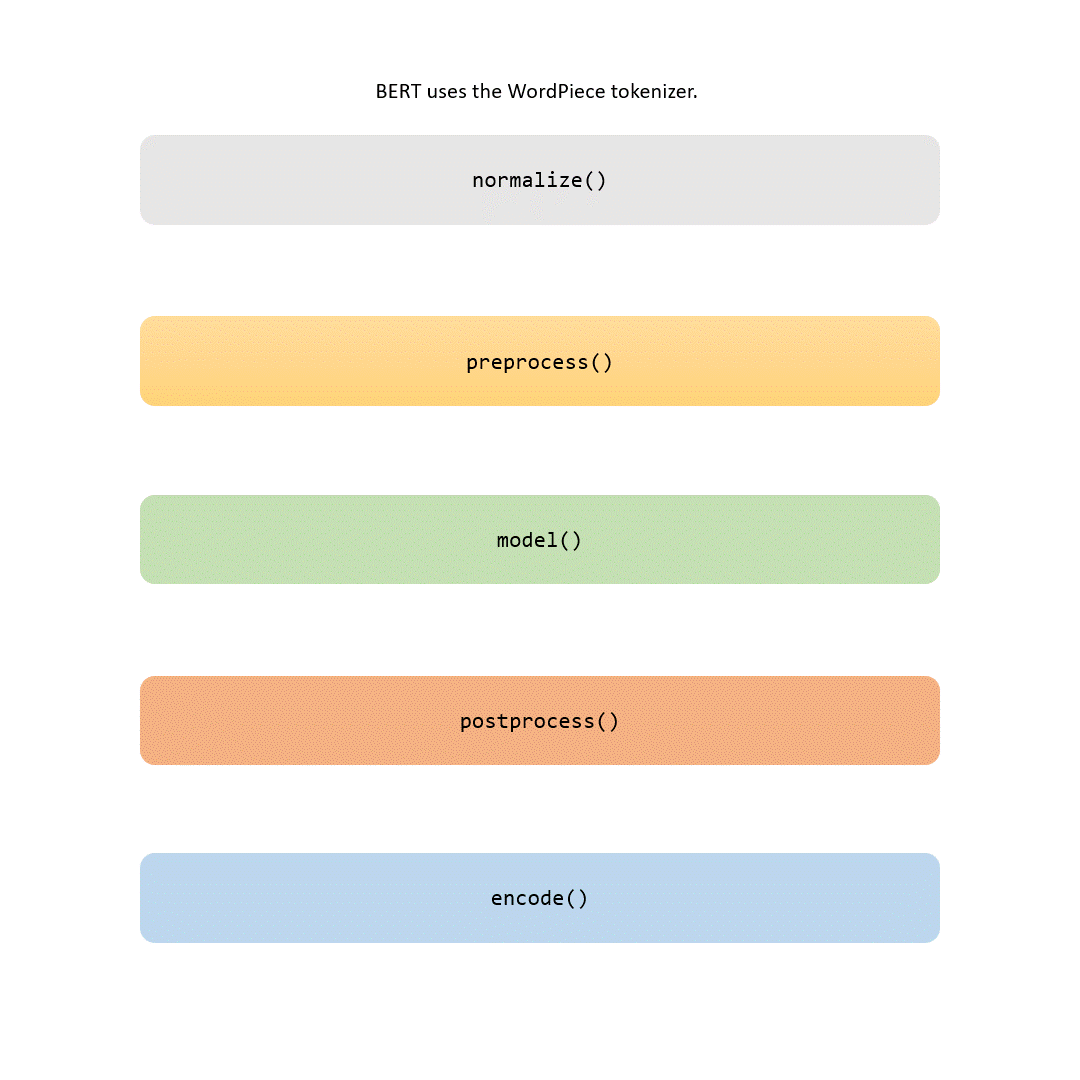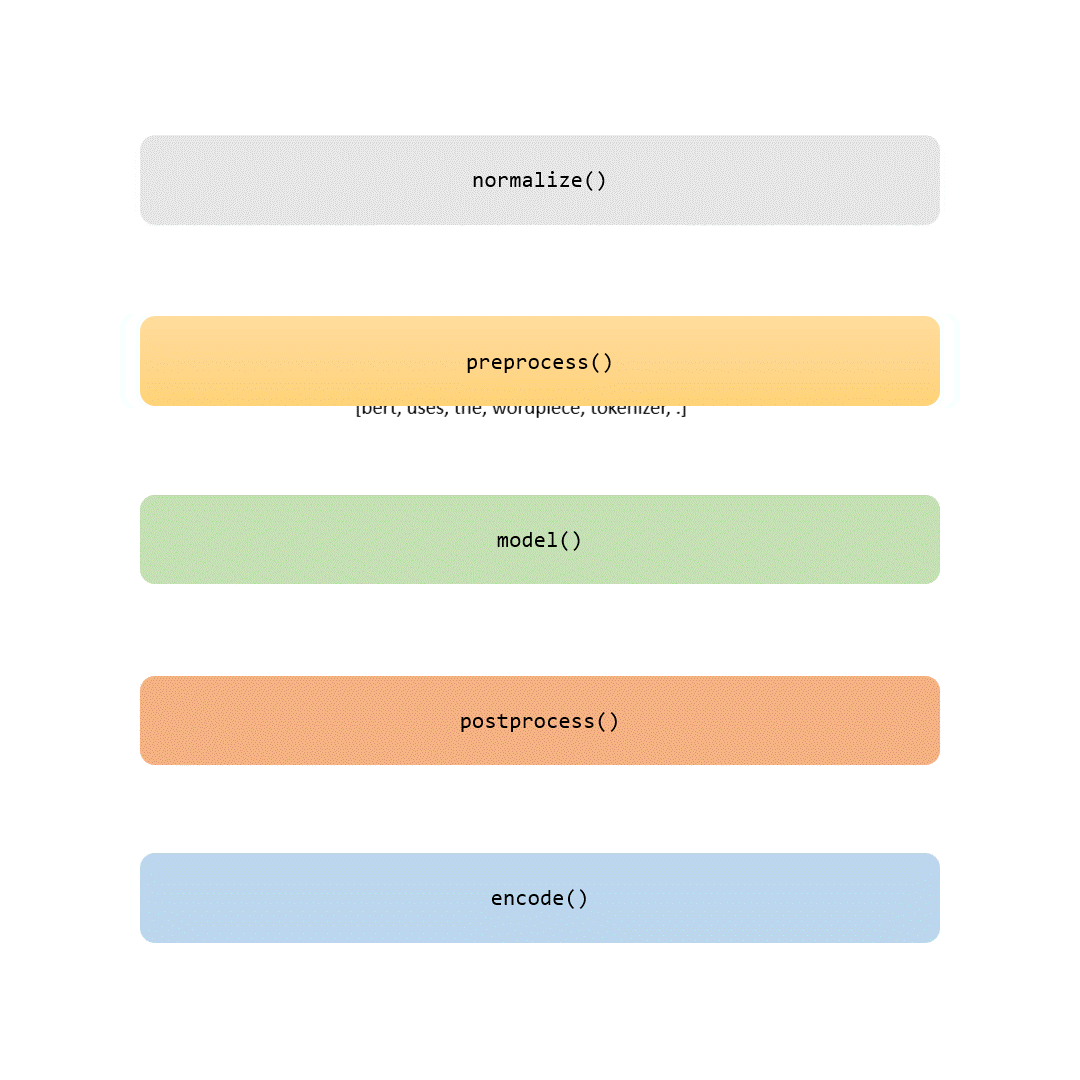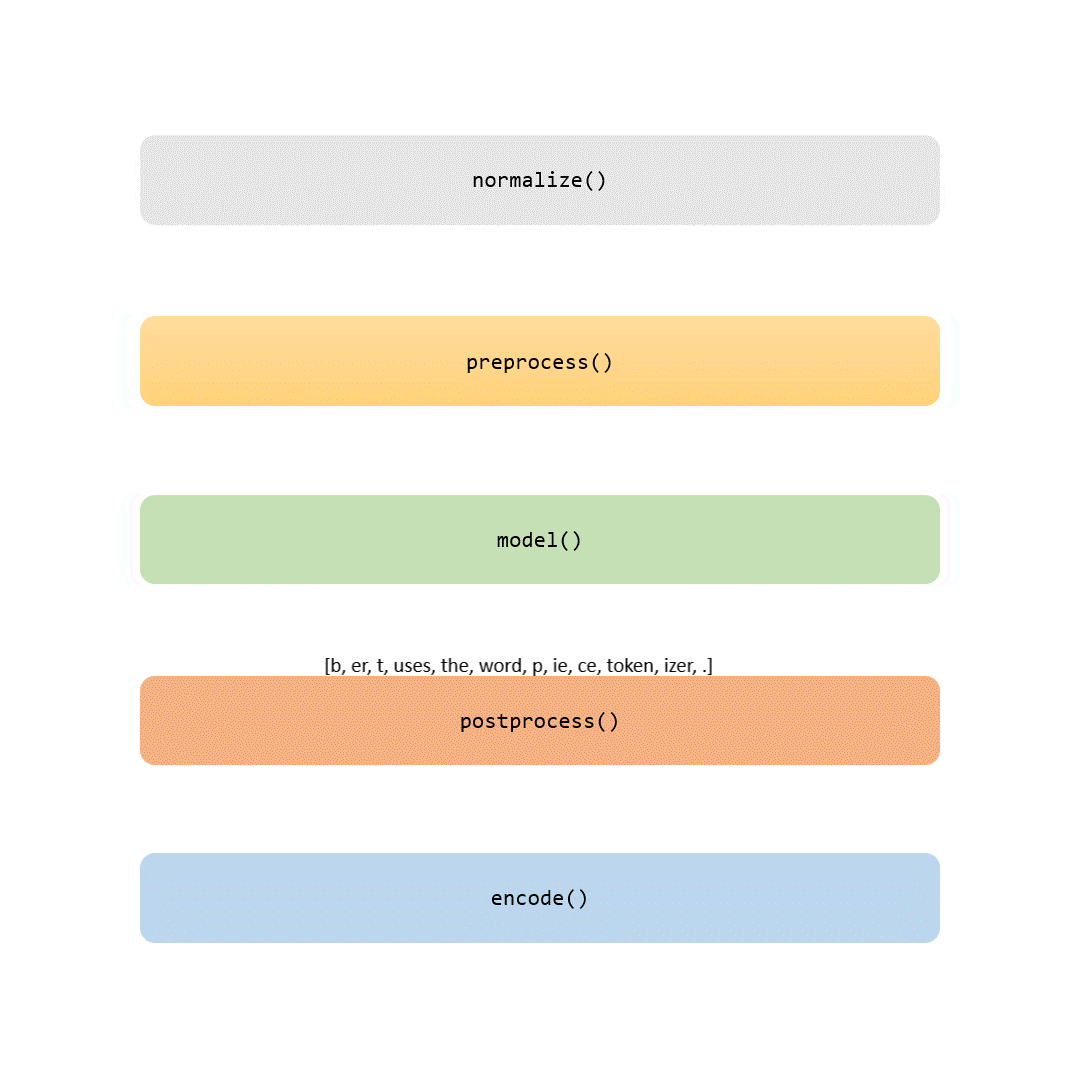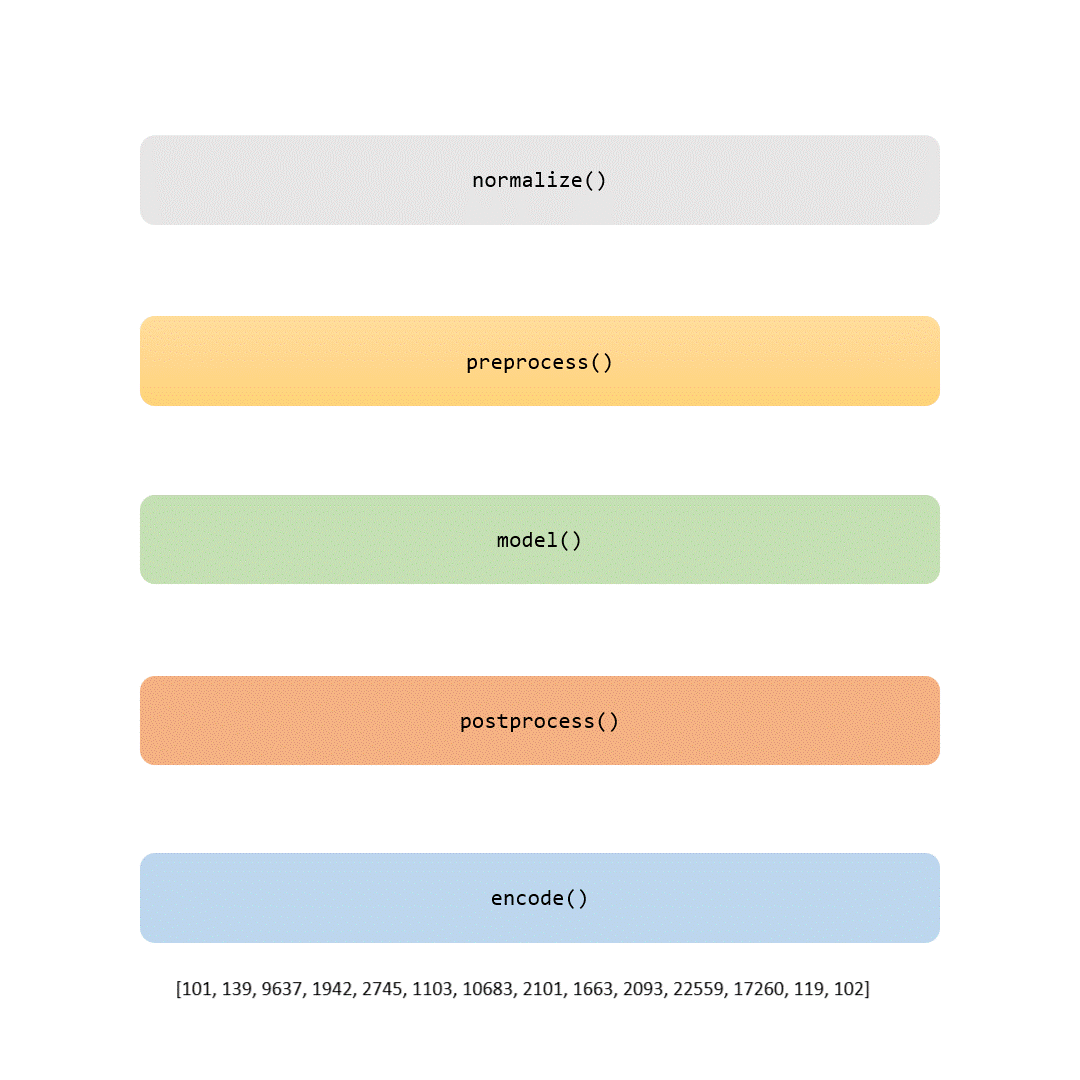
In dieser Geschichte werden wir jeden Teil der Tokenisierungspipeline untersuchen. Einige Schritte sind trivial (wie Normalisierung und Vorverarbeitung), während andere (wie der Modellierungsteil) jeden Tokenizer einzigartig machen.
Wenn Sie diesen Artikel zu Ende gelesen haben, kennen Sie nicht nur die Details des BERT-Tokenizers, sondern können ihn auch anhand Ihrer eigenen Daten trainieren. Wenn Sie abenteuerlustig sind, können Sie diesen entscheidenden Schritt sogar mithilfe von Tools anpassen, wenn Sie Ihr eigenes BERT-Modell von Grund auf trainieren.
Das Aufteilen von Text in Markup ist keine lästige Pflicht; es ist das Tor zur Umwandlung von Sprache in umsetzbare Informationen.
Warum ist die Tokenisierung so wichtig? Im Wesentlichen handelt es sich bei der Tokenisierung um einen Übersetzer; sie nimmt die menschliche Sprache und übersetzt sie in eine Sprache, die Maschinen verstehen können: Zahlen. Aber es gibt einen Haken: Während dieses Übersetzungsprozesses muss der Tokenizer das kritische Gleichgewicht zwischen Bedeutungsfindung und Berechnung aufrechterhalten