Ich habe mich in letzter Zeit mit Erkennungsarbeiten beschäftigt und vor einigen Jahren den Code und die Dokumente von Faster-RCNN analysiert. Schauen wir uns nun das neueste und schnellste Modell yolov5 an. Diese Serie beginnt mit der Entwicklungsgeschichte von Yolo, geht über das Konzept der Verlustfunktion, mAP und schließlich, wie Sie Ihren benutzerdefinierten Datensatz auf Codeebene trainieren. Ok, fangen wir an~
1. Entwicklungsgeschichte von YOLO (You Only Look Once)
Dieser Teil des Inhalts ist hauptsächlich dem Artikel entlehnt, den das Technologie-Biest @Zhihu auf Zhihu gepostet hat. Ich werde ihn hier vereinfachen. Bitte lesen Sie diesen Artikel für spezifische Details
[1-3].
1.1 YOLO v0
Die Idee von YOLO v0 entstand aus der Erweiterung der grundlegenden CNN-Idee von Klassifizierungsaufgaben auf Erkennung. Schauen wir uns also zunächst den Unterschied zwischen Erkennungsaufgaben und Klassifizierungsaufgaben an:
- Erkennung : Die Ausgabe des Netzwerks sollte die Koordinaten des Begrenzungsrahmens (rechteckiger Rahmen) sein (dargestellt durch mindestens 4 Zahlen, es gibt 2 gemeinsame: (x1, y1, x2, y2), (x1, y1, w, H)). Der Grund für die Verwendung eines rechteckigen Rahmens liegt darin, dass der rechteckige Rahmen im Vergleich zu Kreisen und anderen Formen von Polygonen aufgrund seiner geometrischen Eigenschaften besser geeignet ist, das Zielobjekt mit minimalen zusätzlichen Redundanzkosten einzurahmen.

- Klassifizierung : Nehmen Sie als Beispiel die grundlegendste Einzelklassifizierungsaufgabe. Einzelklassifizierung bedeutet, dass das Objekt nur zu einer Kategorie gehört. Das Merkmal dieser Aufgabe ist, dass die Eingabe ein Bild und die Ausgabe seine Kategorie ist. Für das Eingabebild verwenden wir im Allgemeinen einen Tensor, um es darzustellen, und seine Form ist [N, C, H, W]. Für das Ausgabeergebnis verwenden wir im Allgemeinen einen One-Hot-Vektor, um Folgendes darzustellen: [0, 0, 0, 1] [0, 0, 0, 1][ 0 ,0 ,0 ,1 ] , dessen Dimension 1 ist, gibt an, zu welcher Kategorie das Bild gehört.
Okay, nachdem wir den grundlegenden Unterschied zwischen Klassifizierung und Erkennung kennen, können wir die Erkennungsaufgabe als ergodische Klassifizierungsaufgabe betrachten (d. h. Erkennung mehrerer Ziele; wenn festgestellt wird, dass eine einzelne Zielerkennung in einem Bild höchstens 1 Ziel hat, dann ist dies der Fall ähnelt der Klassifizierung. Das Netzwerkdesign und die Ausgabe der Aufgabe sind ähnlich, außer dass die Aktivierungsfunktion der endgültigen vollständig verbundenen Schicht unterschiedlich ist.
Wie kann man es also durchqueren? Die RCNN-Klassenmethode besteht darin, alle Positionen des Bildes durch ein Schiebefenster zu durchlaufen und jedes Feld zu klassifizieren.
Allerdings treten bei dieser Methode Probleme auf: Die Unvollständigkeit der Durchquerung hat großen Einfluss auf die Genauigkeit. Je genauer die Durchquerung ist, desto höher ist die Genauigkeit des Detektors, aber gleichzeitig sind auch die Kosten höher, da Bboxen unterschiedlicher Maßstäbe berücksichtigt werden müssen, um das gesamte Bild zu durchqueren, was recht kostspielig ist. . .
Beispiel: Die Eingabebildgröße beträgt beispielsweise (320, 320) (320, 320)( 3 2 0 ,3 2 0 ) , was bedeutet, dass es320 × 320 = 102, 400 320 \times 320 = 102, 400 gibt3 2 0×3 2 0=1 0 2 ,400 Stellen . _ Das minimale Fenster ist( 1 , 1 ) (1, 1)( 1 ,1 ) , das Maximum( 320 × 320 ) (320 \times 320)( 3 2 0×3 2 0 ) , also ist die Anzahl der Durchläufe unendlich. Schauen wir uns den Pseudocode an:
Das heißt im Wesentlichen, wir trainieren einen binären Klassifikator. Die Eingabe dieses binären Klassifikators ist der Inhalt einer Box und die Ausgabe ist (Vordergrund/Hintergrund).
Und das wirft zwei Probleme auf:
- ① Frames haben unterschiedliche Größen. Werden Frames unterschiedlicher Größe in denselben Zwei-Klassifikator eingegeben?
Wir müssen mit dieser Situation umgehen. Der übliche Weg besteht darin, die Größe der Eingabe in die beiden Klassifikatoren auf die gleiche feste Größe zu ändern. Dies führt offensichtlich zu großen Problemen. Beispielsweise sind die Höhe und Breite des festen Eingabetensors eines Zwei-Klassifikators gleich 64 . × 64 64 \times 646 4×6 4 Nach dem Verschieben des Rahmens beträgt die Größe einiger Rahmen200 × 200 200 \times 2002 0 0×2 0 0 , einige sind10 × 10 10 \times 101 0×1 0 , wir alle müssen die Größe dieser Bboxen auf64 × 64 64 \times 646 4×Die bbox von 6 4 kann in den binären Klassifikator eingegeben werden.
- ②Es gibt viele Hintergrundbilder und wenige Vordergrundbilder: Die Stichproben mit zwei Klassifizierungen sind unausgewogen.
Diese Klassifizierungsmethode mit Schiebefenster ist sehr langsam und das Problem des Klassenungleichgewichts ist schwerwiegend.
Bisher wurde ein Detektor mithilfe eines Klassifizierungsalgorithmus entworfen. Es gibt verschiedene Probleme. Jetzt ist es an der Zeit zu optimieren (dann werden wir offiziell in die YOLO-Methodenreihe eintreten):
Der Autor von YOLO dachte damals so: Für den Klassifikator gibt die letzte vollständig verbundene Schicht einen One-Hot-Vektor aus und ersetzt ihn dann durch (x, y, w, h, c). Wäre es nicht besser, das Problem in ein Regressionsproblem umzuwandeln und die Position des Begrenzungsrahmens direkt zurückzugeben?
Okay, jetzt lautet das Modell:

Wie organisiert man das Training? Beschriften Sie die Punktdaten selbst und setzen Sie die Beschriftung auf ( 1 , x ∗ , y ∗ , w ∗ , h ∗ ) (1, x^*, y^*, w^*, h^*)( 1 ,X∗ ,j∗ ,w∗ ,H∗ ). Hier**∗ stellt die Grundwahrheit dar (d. h. die tatsächliche Bezeichnung). Mit Daten und Labels kann Training durchgeführt werden.
Wir werden feststellen, dass diese Methode derzeit viel einfacher ist als die Klassifizierungsmethode mit Schiebefenstern. Diese Version der Idee heißt YOLO v0, da es sich um die einfachste Version von You Only Look Once handelt.
1.2 YOLO v1
YOLO v1 löst mehrere Probleme basierend auf YOLO v0:
- ① YOLO v0 kann nur die Erkennung einzelner Ziele durchführen und muss dringend erweitert werden.
Die Lösungsidee von YOLO v1 besteht darin, a (c, x, y, w, h) zu verwenden, um für die Eingabe des Ziels eines bestimmten Teilbereichs des Bildes verantwortlich zu sein.
Das heißt, im Vergleich zu einem Bild von YOLO v0, das nur eins (x, y, h, w, c) erhält, erhält YOLO v1 n (x, y, h, w, c). Wie erhält man also n ( x, y 
), h, w, c) Wie wäre es, wenn wir die Gesichter von Rick und Morty bekommen würden, die wir wollen? Hier verwendet der Autor von YOLO v1 NMS (nicht maximale Unterdrückung), um Bbox zu filtern. Der spezifische Algorithmus lautet [1]:
NMS löst automatisch das Problem, dass man nicht weiß, wie viele Ziele sich im Diagramm befinden.
- ② YOLO v0 kann nur die Erkennung einzelner Kategorien durchführen und muss dringend erweitert werden.
Eine allgemeine Erkennungsaufgabe erfordert die Erkennung vieler Inhalte. Beispielsweise müssen sowohl die Gesichter von Rick und Morty als auch das Teleskop erkannt werden. Was sollen wir also tun?
Am Beispiel von 2 Kategorien: Gesicht und Teleskop lassen wir das Netzwerk den Inhalt von N * (c, x, y, w, h) bis N * (c, x, y, w, h, one-hot) vorhersagen. . 2 Kategorien, One-Hot ist [0,1],[1,0], wie in der folgenden Abbildung dargestellt:
- ③ Erkennung kleiner Ziele
Kleine Ziele werden immer schlecht erkannt, daher entwickelt YOLO v1 Neuronen speziell für kleine Ziele.
Im eigentlichen Code verwendet YOLO v1 zwei Fünffache (c, x, y, w, h) für jeden Bereich, eines ist für die Rückgabe des großen Ziels und das andere für die Rückgabe des kleinen Ziels verantwortlich. Fügen Sie außerdem One-Hot hinzu Vektor, eins-Hot ist [0,1],[1,0], um anzugeben, zu welcher Kategorie es gehört (Gesicht oder Teleskop).

Der Kern von YOLO v1 besteht darin, diese drei Probleme im Vergleich zu v0 zu lösen. Das Architekturdiagramm sieht wie folgt aus (Raster stellt die Aufteilung von Bildern in Bereiche dar. Das obige Beispiel ist 4x4, in YOLO v1 jedoch tatsächlich 7x7. Die Kategorie ist 20 Kategorien):

1.3 YOLO v2
Obwohl YOLO v1 viel schneller ist als RCNN-Erkennungsalgorithmen, weist es dennoch Probleme auf, wie zum Beispiel: Die vorhergesagten Frames sind ungenau und viele Ziele können nicht gefunden werden:
- ① Die von YOLO v1 vorhergesagte Box ist ungenau
Der Hauptgrund für dieses Problem besteht darin, dass YOLO v1 die Bbox (x, y, w, h) direkt vorhersagt und dieser Wertebereich sehr groß ist, sodass es zu Ungenauigkeitsproblemen kommt. Denken Sie darüber nach, wenn wir CV-Aufgaben erledigen: Wir normalisieren die Bildverarbeitung und skalieren gängige 8-Bit-Bilder (0-255) auf [0, 1] oder [-1, 1].
Die Strategie der direkten Vorhersage der Position von YOLO v1 führt dazu, dass das neuronale Netzwerk zu Beginn des Trainings instabil wird. Durch die Verwendung von Offsets wird der Trainingsprozess jedoch stabiler und der Leistungsindex steigt um etwa 5 %.
Lernen Sie daher aus dieser Idee und den RCNN-Ideen. YOLO v2 schlägt eine Methode vor, die Bbox-Koordinaten nicht direkt vorhersagt, sondern stattdessen gitterbasierte Offsets und ankerbasierte Offsets vorhersagt .
Der Autor nennt dies Standortvorhersage .
-
Der auf dem Raster basierende Versatz bedeutet, dass die Position des Ankers fest ist (der Anker ist ein fester Anker, der durch Clustering des gesamten Datensatzes bei der Erstellung des Datensatzes erhalten wird), und der Versatz = Zielposition-Ankerposition.
-
Der ankerbasierte Versatz bedeutet, dass die Position des Gitters fest ist (das Gitter ist das grüne Gitter von Rick und Morty oben) und der Versatz = Zielposition-Gitterposition.
Illustrationen zur Standortvorhersage aus Zhihu-Artikeln über Technologie-Monster [2],

Nehmen Sie an, wie in der Abbildung oben gezeigt, dass die Abbildung in 9 Gitter unterteilt ist, GT (Ground Truth) im roten Feld und Anker im violetten Feld () angezeigt wird 该Anchor是根据数据集的GT计算产生的,与目标GT的IoU最大的那个Anchor. Die Zahlen im Bild sind die tatsächlichen Informationen des Bildes.
Der vorhergesagte Wert von YOLO v2 ergibt sich aus (x, y, h, w), x, y, h, w ∈ [0, 447] x, y, h, w \in [0,447]x ,y ,h ,w∈[ 0 ,4 4 7 ];变为tx , ty , tw , th t_x, t_y, t_w, t_hTx,Ty,Tw,ThWie unten gezeigt, ist der Bereich dieser Werte sehr klein, was für die Erkennung der Netzwerkkonvergenz sehr nützlich ist.

Es ist ersichtlich, dass die Koordinaten der Mittelposition des roten B-Felds von Ground Truth im Vergleich zur oberen linken Ecke (1, 1) des Gitters, in dem es sich befindet, (1,543, 1,463) sind. Berechnungsformel:
tx = log ( ( bboxx − cx ) / ( 1 − ( bboxx − cx ) ) ) t_x = log((bbox_x - c_x) / (1 - (bbox_x - c_x)))Tx=l o g ( ( b b o xx−Cx) / ( 1−( b b o xx−Cx) ) )
ty = log ( ( bboxy − cy ) / ( 1 − ( bboxy − cy ) ) ) t_y = log((bbox_y - c_y) / (1 - (bbox_y - c_y)))Ty=l o g ( ( b b o xy−Cy) / ( 1−( b b o xy−Cy) ) ) tw
= log ( gtw / pw ) t_w = log(gt_w / p_w)Tw=l o g ( g tw/ Sw)
th = log ( gth / ph ) t_h = log(gt_h / p_h)Th=l o g ( g th/ Sh)
Die untere rechte Ecke ist eine spezifische Darstellung der Verbesserungen von YOLO v2. Die Bedeutung der Parameter ist wie folgt [2]:

-
② YOLO v1 wird viele Ziele verfehlen, das heißt, das Phänomen der fehlenden Erkennung ist offensichtlich.
Dies liegt daran, dass bei der Erkennung mehrerer Ziele und mehrerer Kategorien die Größe und das Seitenverhältnis der Zielobjekte unterschiedlich sind. Fußgänger sind beispielsweise schmale und lange Bboxen, während Autos quadratische Bboxen sind.
Auf dieser Grundlage hat der Autor von YOLO v2 im Voraus mehrere Begrenzungsrahmen mit relativ hoher Wahrscheinlichkeit des Auftretens im Datensatz vorbereitet und diese dann als Grundlage für die Vorhersage verwendet. Dies ist die ursprüngliche Absicht von Anchor.
Insbesondere unterteilt YOLO v2 das Bild in 13 × 13 13 \times 131 3×1 3 Bereiche, jeder Bereich hat 5 Anker und jeder Anker entspricht 1 Kategorie. Am Beispiel von 2 Kategorien beträgt die letzte vom Netzwerk vorhergesagte Dimension des Tensors 35, wie mit der folgenden Formel berechnet. 35 = 5 ×
( 5 (c, tx, ty, tw, th) + 2 Klassen) 35 = 5 \times (5 (c, t_x, t_y, t_w, t_h) + 2 Klassen)3 5=5×( 5 ( c ,Tx,Ty,Tw,Th)+2 Klassen ) _ _ _ _ _ _- Wie erhält man die 5 Anker in jedem Bereich?
Wie in der folgenden Abbildung dargestellt, gruppieren Sie für jeden Datensatz, z. B. COCO (lila Anker), zunächst die Begrenzungsrahmen der GT (Ground Truth) des Trainingssatzes. In wie viele Kategorien werden sie gruppiert? Nach der Durchführung von Experimenten stellte der Autor fest, dass der Rückruf im Vergleich zur Komplexität von 5 Kategorien besser ist. Jetzt ist er in 5 Kategorien gruppiert. Bei komplexen Aufgaben gilt natürlich: Je mehr Kategorien, desto höher ist der mAP und die Vorhersage ist am höchsten umfassend, aber die Komplexität nimmt stark zu. Gleichzeitig wird die Genauigkeit des Modells nicht wesentlich verbessert, sodass eine relativ kompromisslose Methode zur Auswahl von 5 Clustern angewendet wird, dh es werden 5 A-priori-Boxen verwendet.

- Hinweis: Der Anker von YOLO v2 wird aus den Statistiken des Datensatzes ermittelt (während Breite, Höhe und Größe des Ankers in Faster-RCNN manuell ausgewählt werden).
- Wie erhält man die 5 Anker in jedem Bereich?
1.4 YOLO v3
Zu diesem Zeitpunkt steht die Grundidee von YOLO fest, aber seit YOLO v2 ist der Effekt auf die Erkennung kleiner Ziele immer noch nicht gut genug (Resnet ist noch nicht herausgekommen ... und das Netzwerk zum Extrahieren von Features ist es nicht). gut genug~).
Bei YOLO v3 besteht die wichtigste Verbesserung hier in der Hinzufügung einer Multi-Scale-Vorhersage und der Änderung des Backbones von YOLO v2 von einem 19-schichtigen Darknet zu einem 53-schichtigen Darknet [4].
- ①Der YOLO v3 -Erkennungskopf für die Multiskalenvorhersage ist gegabelt und in drei Teile unterteilt. Jede Dimension verfügt über drei Anker:
[2]
YOLO v3 verwendet insgesamt 9 Ankerboxen. Drei für jede Skala (3 große, 3 mittlere, 3 kleine). Wenn Sie YOLO auf Ihrem eigenen Datensatz trainieren, sollten Sie K-Means-Clustering verwenden, um 9 Anker zu generieren.
[4]
- 13 ∗ 13 ∗ 3 ∗ ( 4 + 1 + 2 ) 13*13*3*(4+1 + 2)1 3∗1 3∗3∗( 4+1+2 )
- 26 ∗ 26 ∗ 3 ∗ ( 4 + 1 + 2 ) 26*26*3*(4+1 + 2)2 6∗2 6∗3∗( 4+1+2 )
- 52 ∗ 52 ∗ 3 ∗ ( 4 + 1 + 2 ) 52*52*3*(4+1 + 2)5 2∗5 2∗3∗( 4+1+2 )

Im Vergleich zu YOLO v2 beträgt die Anzahl der vorhergesagten Bboxes von YOLO v3:
(13 × 13 + 26 × 26 + 52 × 52) × 3 = 10467 (V 3) ≫ 845 (V 2) (13 × 13 × 5 ) (13 \times 13 + 26 \times 26 + 52 \times 52) \times 3 = 10467(V3) \gg 845(V2) (13 \times 13 \times 5)( 1 3×1 3+2 6×2 6+5 2×5 2 )×3=1 0 4 6 7 ( V 3 )≫8 4 5 ( V 2 ) ( 1 3×1 3×5 )
Da so viele vorhersehbare Begrenzungsrahmen vorhanden sind, wurden die Fähigkeiten des Modells offensichtlich verbessert.
Das offizielle YOLO v3-Modell ist unten dargestellt:
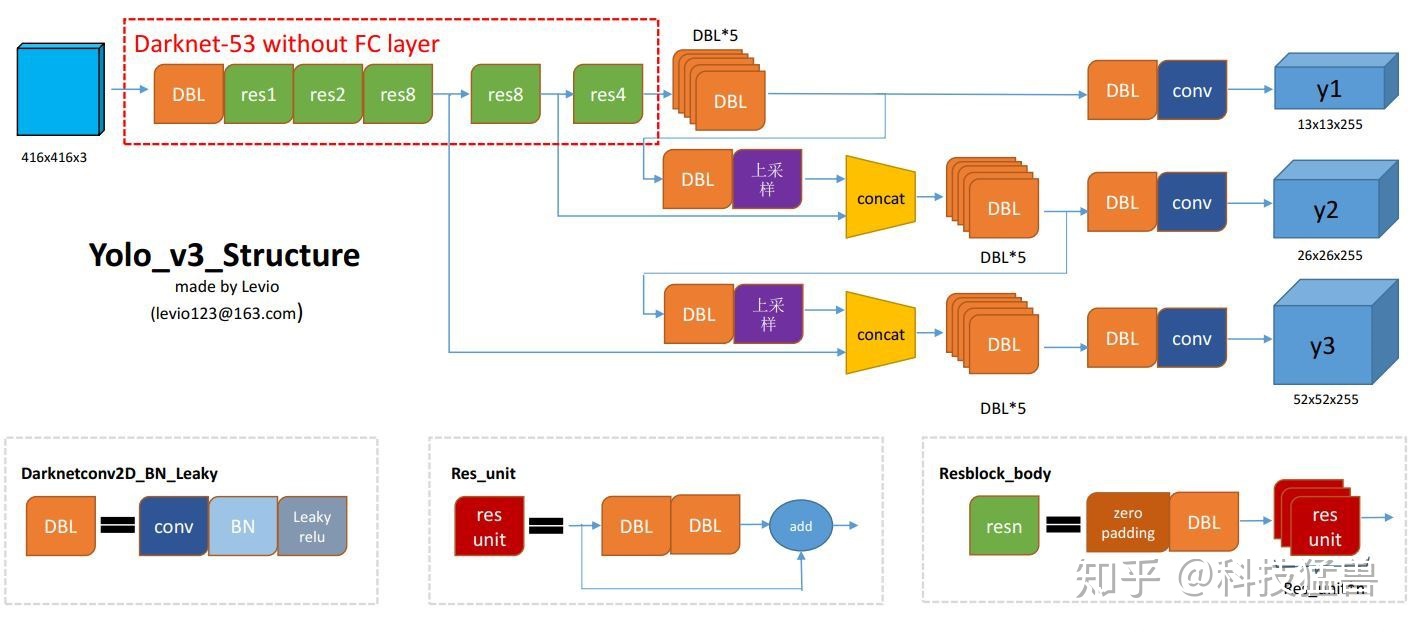
1.5 YOLO v4
Yolo v4 fügt einige Funktionen basierend auf v3 hinzu, hauptsächlich drei Funktionen:
-
① Verwendung mehrerer Anker für eine einzelne Grundwahrheit. In der
vorherigen Version von YOLO v3 war ein Anker für einen GT verantwortlich. In YOLO v4 wurden mehrere Anker für einen GT verwendet. Die Methode lautet: für GT j GT_jGT _jSolange beispielsweise I o U (anchori, GT j) > Schwellenwert IoU(anchor_i, GT_j) > Schwellenwert istI o U ( a n c h o rich,GT _j)>t h e s h o l d,Anker Anchor_i bekommenAnker _ _ _ _ _ichÜbernimm GT j GT_jGT _j.
Dies entspricht der Tatsache, dass sich die Anzahl Ihrer Ankerboxen nicht geändert hat, aber der Anteil der ausgewählten positiven Proben zugenommen hat, was das Problem des Ungleichgewichts zwischen positiven und negativen Proben (im Allgemeinen gibt es zu viele Hintergründe) lindert. -
② Eliminate_grid-Empfindlichkeit
Erinnern Sie sich noch an dieses Bild von YOLO v2? YOLO v2 und YOLO v3 sagen alle tx, ty, tw, th t_x, t_y, t_w, t_h vorausTx,Ty,Tw,ThDiese 4 Offsets.

Hier gibt es tatsächlich ein verstecktes Problem:

-
③ CIoU-Verlust
wird vorerst nicht eingeführt. Einzelheiten finden Sie im Zhihu-Artikel des Technologie-Biest-Chefs[2].
1.6 YOLO v5
YOLO v5 ändert grundsätzlich die Struktur von YOLO v3. Die folgende Einführung ist in mehrere Module unterteilt:
1.6.1 Netzwerkmodul
Mit (N, 3, 640, 640) (N, 3, 640, 640)( N ,3 ,6 4 0 ,6 4 0 ) als Beispiel. Am Beispiel der leichtesten Yolov5s ist die Struktur wie folgt

Im Folgenden werde ich die wichtigen Module Focus, BottleneckCSP, SPP und PANET ausführlich beschreiben . Da dieses Projekt die YOLO v5s-Netzwerkstruktur zum Trainieren des Modells verwendet , basieren die folgenden Netzwerkdiagramme und Beispiele alle auf YOLO v5s und dem Eingabebild ist 3x640x640 .
Das YOLO-Netzwerk besteht aus drei Hauptkomponenten:
1) Backbone : Ein Faltungs-Neuronales Netzwerk, das Bildmerkmale auf verschiedenen Bildern mit feiner Granularität aggregiert und bildet.
2) Hals : Eine Reihe von Netzwerkschichten, die Bildmerkmale mischen und kombinieren und die Bildmerkmale an die Vorhersageschicht weitergeben. (Normalerweise FPN oder PANET)
3) Kopf : Bildmerkmale vorhersagen, Begrenzungsrahmen generieren und Kategorien vorhersagen.
Zu den wichtigen Modulen, die in YOLO V5 1.0 verwendet werden, gehören Focus, BottleneckCSP, SPP und PANET. Das Upsampling des Modells verwendet die Upsampling-Interpolation des nächsten Doppelten nn.Upsample(mode="nearest").
Es ist erwähnenswert, dass das Pretrained_model, das ursprünglich für den COCO-Datensatz in YOLO V5 1.0 trainiert wurde, FPN als Hals verwendete. Nach dem 22. Juni hat Ultralytics den Hals des Modells auf PANET aktualisiert. Viele Einführungen in die YOLO V5-Netzwerkstruktur im Internet basieren auf FPN-NECK. Das Modelltraining in diesem Artikel basiert auf PANET-NECK. Im Folgenden wird nur PANET-NECK vorgestellt.
Bei YOLO V5, egal ob V5s, V5m, V5l oder V5x, sind Rückgrat, Hals und Kopf gleich. Der einzige Unterschied liegt in den Tiefen- und Breiteneinstellungen des Modells. Sie müssen nur diese beiden Parameter ändern, um die Netzwerkstruktur des Modells anzupassen. Die Parameter von V5l sind die Standardparameter.
• Tiefenmultiplikator wird verwendet, um die Tiefe des Modells zu steuern. Beispielsweise beträgt die Tiefe von V5s 0,33 und die Tiefe von V5l 1, was bedeutet, dass die Anzahl der Engpässe in V5l dreimal so hoch ist wie die von V5s.
• width_multiple wird verwendet, um die Anzahl der Faltungskerne zu steuern. Die Breite von V5s beträgt 0,5, während die Breite von V5l 1 beträgt, was bedeutet, dass die Anzahl der Faltungskerne von V5s die Hälfte der Standardeinstellung beträgt. Natürlich können Sie das auch Stellen Sie es auf das 1,25-fache ein, also V5x. Beispielsweise ist die erste Schicht des Backbones in der Yaml-Datei von YOLO V5 unten [[-1, 1, Focus, [64, 3]], und die Breite von V5s beträgt 0,5, also ist diese Schicht tatsächlich [[- 1, 1, Focus, [32, 3]].
Da mein Ziel ein sehr leichtes Erkennungsmodell ist, betrachte ich
die Modelldefinitionsdatei von yolov5s derzeit nur wie folgt: yolov5s.yaml(für den COCO-Datensatz). Es ist ersichtlich, dass sie gut mit der obigen Abbildung übereinstimmt.
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Focus
Das Bild unten zeigt die Focus-Interlaced-Sampling-Spleißstruktur von YOLO V5s.

YOLO V5 hat eine Standardeingabe von 3x640x640. Die Funktion der Fokusebene besteht darin, sie in vier Kopien zu kopieren und dann die vier Bilder durch den Slicing-Vorgang in vier 3x320x320-Slices zu schneiden. Als nächstes verwenden Sie concat, um die vier Slices aus der Tiefe zu verbinden Die Ausgabe beträgt 12 x 320 x 320 und durchläuft dann eine Faltungsschicht mit einer Faltungskernzahl von 32, um eine Ausgabe von 32 x 320 x 320 zu erzeugen. Schließlich wird das Ergebnis über Batch_norm und Leaky_Relu in die nächste Faltungsschicht eingegeben.
Der Effekt der Fokusebene ist wie folgt: 4 × 4 4 \times 44×Nehmen Sie als Beispiel das Bild 4. Das linke Bild ist das ursprüngliche Eingabebild und das rechte Bild ist die Feature-Map nach der Fokusverarbeitung.

Ab sofort (28.09.2020) sieht die Implementierung so aus [5], was mit dem Passthrough von YOLO v2 identisch ist.

Der Kern ist dieser Code self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)). x[..., ::2, ::2]Es ist der gelbe Teil, x[..., 1::2, ::2]es ist der rote Teil, x[..., ::2, 1::2]es ist der grüne Teil und so weiter.
-
BottleneckCSP
Die folgende Abbildung zeigt die erste BottleneckCSP-Struktur von YOLO V5s: Es ist ersichtlich, dass BottleneckCSP in zwei Teile unterteilt ist: Bottleneck und CSP .

DarunterBottleneckist es die klassische Reststruktur: Zuerst eine 1x1-Faltungsschicht (conv+batch_norm+leaky relu), dann eine 3x3-Faltungsschicht und schließlich wird die Reststruktur zur anfänglichen Eingabe hinzugefügt[6].

Es ist erwähnenswert, dass YOLO V5 die Tiefe des Modells durch ein Tiefenmultiplikator steuert . Beispielsweise beträgt die Tiefe von V5s 0,33 und die Tiefe von V5l 1. Das heißt, die Anzahl der Engpässe im BottlenneckCSP von V5l beträgt Dreimal so viel wie bei V5s. Der erste BottlenneckCSP im Modell. Die Standardanzahl der Engpässe beträgt x3, und für V5s gibt es im Bild oben nur einen Engpass.Der Code des Autors lautet wie folgt. Es ist erwähnenswert, dass e width_multiple ist , was das Verhältnis der Anzahl der derzeit betriebenen Faltungskerne zur Standardanzahl darstellt
[7]:

Wie aus dem obigen BottleneckCSP-Code ersichtlich ist, unterteilt er den Zweig in zwei Blöcke , unterteilt in Zweige y1 und y2,
von denen Zweig 1 (y1) die Operation „Flaschenhals * N“ ausführt und Zweig 2 (y2) die Kanalreduzierung durchführt.
Schließlich werden die beiden Zweige zusammengeführt und dann eine Reihe von Operationen von bn durchgeführt , act und Conv (das Bild unten stammt von William in Zhizhi) Hufas Artikel[6]).

-
SPP
SPP ist eine räumliche Pooling-Schicht . Die Eingabe beträgt 512 x 20 x 20. Nach einer 1 x 1-Faltungsschicht beträgt die Ausgabe 256 x 20 x 20 und wird dann durch drei parallele Maxpools mit unterschiedlichen Kernelgrößen (5, 9, 13) heruntergesampelt. Beachten Sie, dass dies für unterschiedliche Zweige gilt Die Auffüllgrößen betragen jeweils [5,9,13]//2. Da stride = 1 ist, beträgt das Ergebnis nach jedem Pooling außerdem 256 x 20 x 20, sodass die Ergebnisse gespleißt und zu ihren ursprünglichen Merkmalen hinzugefügt werden können. Ausgabe 1024 x 20 x 20 und verwenden Sie schließlich einen Faltungskern von 512, um ihn auf 512 x 20 x 20 wiederherzustellen (das Bild unten stammt aus einem Zhihu-Artikel von Technology Beast[3]).

-
PANet
Die PAN-Struktur stammt aus dem Artikel Path Aggregation Network[8]. Ihre ursprüngliche Absicht besteht darin, in Instanzsegmentierungsaufgaben (Instance Segmentation) verwendet zu werden. Die Modellstruktur ist wie folgt: Der

Feature-Extraktor dieses Netzwerks übernimmt ein neues, verbessertes Bottom-Up (Bottom Up). ) Pfad. Die FPN-Struktur verbessert die Ausbreitung von Low-Level-Features (Teil a). Jede Stufe des dritten Pfads verwendet als Eingabe die Feature-Maps der vorherigen Stufe und verarbeitet sie mit 3x3-Faltungsschichten. Die Ausgaben werden über seitliche Verbindungen zu den Feature-Maps derselben Stufe des Top-Down-Pfades hinzugefügt, und diese Feature-Maps liefern Informationen für die nächste Stufe (Teil b).Gleichzeitig wird adaptives Feature-Pooling verwendet , um die beschädigten Informationspfade zwischen jeder Kandidatenregion und allen Feature-Ebenen wiederherzustellen, jede Kandidatenregion auf jeder Feature-Ebene zu aggregieren und eine willkürliche Zuweisung zu vermeiden (Teil c).
YOLO V5 übernimmt eine modifizierte PANET-Struktur von YOLO V4: PANET verwendet normalerweise adaptives Feature-Pooling, um benachbarte Ebenen für die Maskenvorhersage zusammenzufügen. Allerdings ist diese Methode bei der Verwendung von PANET in YOLO v4 etwas umständlich. Anstatt also benachbarte Ebenen mithilfe des adaptiven Feature-Poolings hinzuzufügen, führen die Autoren von YOLO v4 eine Concat-Operation für sie durch, was die Genauigkeit der Vorhersage verbessert.

YOLO V5 verwendet auch den Kaskadenbetrieb. Einzelheiten entnehmen Sie bitte dem großen Modellbild und der entsprechenden Concat-Operation im Netron-Netzwerkdiagramm.

1.6.2 Verbesserungen der Datenverarbeitung
Der folgende Inhalt ist ein Nachdruck aus
[3]dem Zhihu-Artikel von Technological Beast
- Mosaikdatenverbesserung
[3]

CutMix verwendet nur zwei Bilder zum Zusammenfügen, während die Mosaik-Datenverbesserung vier Bilder zum Zusammenfügen durch zufällige Skalierung, zufälliges Zuschneiden und zufällige Anordnung verwendet.
Seine Hauptvorteile sind:
① Bereichern Sie den Datensatz : Verwenden Sie zufällig 4 Bilder, skalieren Sie sie zufällig und verteilen Sie sie dann zufällig zum Spleißen, wodurch der Erkennungsdatensatz erheblich bereichert wird. Insbesondere werden durch die zufällige Skalierung viele kleine Ziele hinzugefügt, wodurch das Netzwerk robuster wird.
② Reduzieren Sie die GPU-Nutzung : Einige Leute mögen sagen, dass auch zufällige Skalierung und normale Datenverbesserung möglich sind, aber der Autor ist der Ansicht, dass viele Leute möglicherweise nur eine GPU haben, sodass während des erweiterten Mosaik-Trainings die Daten von 4 Bildern direkt berechnet werden können. Herstellung von Mini- Die Stapelgröße muss nicht groß sein, und eine GPU kann bessere Ergebnisse erzielen.
- Adaptive Ankerrahmenberechnung
[3]
Im Yolo-Algorithmus gibt es für verschiedene Datensätze Ankerboxen mit anfänglicher Länge und Breite.
Während des Netzwerktrainings gibt das Netzwerk den vorhergesagten Frame basierend auf dem anfänglichen Ankerframe aus, vergleicht ihn dann mit der Grundwahrheit des realen Frames, berechnet die Differenz zwischen den beiden und aktualisiert ihn dann in umgekehrter Reihenfolge, um die Netzwerkparameter zu iterieren.
Daher ist die anfängliche Ankerbox auch ein wichtiger Teil, wie beispielsweise die Ankerbox, die ursprünglich von Yolov5 für den Coco-Datensatz festgelegt wurde:

In Yolov3 und Yolov4 wird beim Training verschiedener Datensätze der Wert der anfänglichen Ankerbox durch eine separate Berechnung berechnet Programm. .
Yolov5 bettet diese Funktion jedoch in den Code ein und berechnet bei jedem Training adaptiv die besten Ankerboxwerte in verschiedenen Trainingssätzen.
Wenn Sie der Meinung sind, dass der berechnete Ankerbox-Effekt nicht sehr gut ist, können Sie natürlich auch die automatische Ankerbox-Berechnungsfunktion im Code deaktivieren [9].
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
- Adaptive Bildskalierung
[3]
In gängigen Zielerkennungsalgorithmen haben unterschiedliche Bilder unterschiedliche Längen und Breiten. Daher besteht eine gängige Methode darin, die Originalbilder einheitlich auf eine Standardgröße zu skalieren und sie dann an das Erkennungsnetzwerk zu senden.
Im Yolo-Algorithmus wird beispielsweise häufig 416 × \times verwendet× 416,608× \times× 608 und andere Größen skalieren beispielsweise das 800 * 600-Bild unten:, wie in der Abbildung gezeigt:

Dies wurde jedoch im Yolov5-Code verbessert und ist auch ein guter Trick, der die Inferenzgeschwindigkeit von Yolov5 beschleunigt.
Der Autor ist der Ansicht, dass bei der tatsächlichen Verwendung des Projekts viele Bilder unterschiedliche Seitenverhältnisse haben, sodass nach dem Skalieren und Füllen die Größe der schwarzen Ränder an beiden Enden unterschiedlich ist. Wenn mehr Füllung vorhanden ist, kommt es zu Informationsredundanz beeinflussen die Inferenzgeschwindigkeit.
datasets.pyDaher wurden Änderungen an der Funktion im Yolov5-Code vorgenommen letterbox, um die minimalen schwarzen Kanten adaptiv zum Originalbild hinzuzufügen, wie in der Abbildung gezeigt: Die schwarzen Kanten

an beiden Enden der Bildhöhe werden reduziert, und der Berechnungsaufwand wird ebenfalls reduziert während der Inferenz reduziert werden. Das heißt, die Zielerkennungsgeschwindigkeit wird verbessert.
Durch diese einfache Verbesserung wurde die Inferenzgeschwindigkeit um 37 % verbessert, was offensichtlich einen offensichtlichen Effekt hat.
Die Füllung in Yolov5 ist grau, also (114, 114, 114), was den gleichen Effekt hat, und während des Trainings wird nicht die Methode zum Reduzieren schwarzer Kanten verwendet, sondern die herkömmliche Füllmethode, also die Skalierung auf 416*416 Größe. Nur beim Testen und Verwenden von Modellinferenz wird die Methode zur Reduzierung schwarzer Kanten verwendet, um die Geschwindigkeit der Zielerkennung und -inferenz zu verbessern.
- Positive Proben nehmen zu
[3]
Dies ist dasselbe wie die Verwendung mehrerer Anker für eine einzelne Grundwahrheit in YOLO v4 .

2. Zusammenfassung
Das Bild unten ist eine Zusammenfassung des Autors über die Merkmale jeder Generation der YOLO-Serie. Darunter wird der Verlustteil in Serie 3 besprochen.

Referenzartikel
[1] Sie müssen noch nie eine so leicht verständliche Modellinterpretation der YOLO-Serie (von v1 bis v5) gesehen haben (Teil 1) [
2] Sie müssen noch nie eine so leicht verständliche YOLO-Serie (von v1 bis v5) gesehen haben v5) Modellinterpretation (Teil 2)
[3] Sie müssen noch nie eine so leicht verständliche Modellinterpretation der YOLO-Serie (von v1 bis v5) gesehen haben (Teil 2)
[4] Was ist neu in YOLO v3?
[5] Fokus Schicht von YOLO v5
[6] Verwenden Sie YOLO V5, um das automatische Fahrzielerkennungsnetzwerk zu trainieren.
[7] Engpassschicht von YOLO v5
[8] Pfadaggregationsnetzwerk für Instanzsegmentierung: CVPR2018
[9] YOLO v5-Code train.py