Erstellen Sie die Tensorflow-Version des pointNet++-Modells von Grund auf, führen Sie sie aus und lösen Sie häufig auftretende Probleme
- 1. Installation und Initialisierung des Ubuntu18-Systems
- 2. Quellcode und Datensatz herunterladen
- 3. Die zum Erstellen von pointNet++ erforderliche Umgebung (Anaconda, Cuda, cuDNN, Pytorch, Python)
-
- 1. Grafikkartentreiber herunterladen und installieren
- 2. Installation und Konfiguration von Anaconda und Cuda
- 3. cudnn-Installation und -Konfiguration
- Wenn bei der Installation von cudnn der folgende Fehler auftritt: libcudnn7-doc_7.4.2.24-1+cuda10.0_amd64.deb ist keine Paketdatei im Debian-Format
- 4. Installation und Konfiguration der Python-Umgebung und der Tensorflow-abhängigen Bibliothek
- Wenn bei der Installation der python3-pip-Bibliothek der folgende Fehler gemeldet wird: Die folgenden Pakete weisen nicht erfüllte Abhängigkeiten auf
- Wenn beim Testen von Tensorflow der folgende Fehler auftritt: TypeError: Deskriptoren können nicht direkt erstellt werden.
- 5. Installation und Konfiguration von gcc5 und g++5
- 4. Führen Sie pointNet++ aus
-
- 1. Ändern Sie die Skriptdatei von tf
- 2. Kompilieren Sie diese Datei und geben Sie sie aus
- Wenn dieser Schritt nicht ausgeführt wird, kann während der Kompilierung der folgende Fehler auftreten: /usr/bin/ld: can not find -ltensorflow_framework Collect2: Fehler: ld hat 1 Exit-Status zurückgegeben
- Wenn die Befehle chmod und cd nicht ausgeführt werden, wird der folgende Fehler angezeigt: gcc: Fehler: tf_sampling_g.cu: Keine solche Datei oder kein solches Verzeichnis
- 3. Ändern Sie den pointNet++-Quellcode
- 4. Führen Sie das Trainingsmodell aus
- 5. Lösung häufiger Probleme im Betrieb
-
- 1. Fehler: {NotFoundError}libcudart.so.10.0: Gemeinsam genutzte Objektdatei kann nicht geöffnet werden: Keine solche Datei oder kein solches Verzeichnis
- 2.报错:{NotFoundError}/home/sdg/code/pointnet2-master/tf.ops/sampling/tf.sampling_so.s0:( undefiniertes Symbol: _ZM10temsorflow120pDefBuilder4AttrESs
- 3.Fehler:FileNotFoundError: [Errno 2] Keine solche Datei oder kein solches Verzeichnis:'/home/sdg/code/pointnet2-master/data/modelnet40_normal_resampled/shape_names.txt'
- 4. Hinweis: Das {AttributeError}Modul „provider“ hat kein Attribut „rotate_point_cloud“.
- 5. Fehler: 64,00 MB (67108864 Bytes) vom Gerät konnten nicht zugewiesen werden: CUDA_ERROR_OUT_OF_MEMORY: nicht genügend Speicher
本次采用的是Tensorflow版的pointNet++模型
服务器环境是Ubuntu18/python3.7/cuda10.0/cudnn7.4/tensorflow-gpu1.4/g++5
Referenz: Tutorial zur nullbasierten Reproduktion des PointNet++-Modells und Tutorial zum Ausführen von Pointnet++-Pointnet2-Code auf Nanny-Ebene
1. Installation und Initialisierung des Ubuntu18-Systems
Referenz: Installation und Initialisierung des Ubuntu18-Systems (SSH-Dienst, Netzwerkkonfiguration)
Wenn das Ubuntu16-System installiert ist, können Sie den folgenden Befehl ausführen, um ein Upgrade auf Ubuntu18 durchzuführen:
sudo apt update
sudo apt upgrade
sudo apt dist-upgrade
sudo apt autoremove
sudo do-release-upgrade
2. Quellcode und Datensatz herunterladen
1. pointNet++-Quellcode
Download-Adresse: https://github.com/charlesq34/pointnet2
Kopieren Sie die heruntergeladene Datei pointnet2-master.zip auf den Server und führen Sie sie dann ausunzip pointnet2-master.zip
2. ModelNet40-Datensatz (XYZ und Normal vom Netz, 10.000 Punkte)
Download-Adresse: modelnet40_normal_resampled.zip
Kopieren Sie die heruntergeladene Datensatzdatei in das Datenverzeichnis im Programm pointnet2-master und führen Sie den unzip modelnet40_normal_resampled.zipBefehl zum Dekomprimieren des Datensatzes aus
3. ModelNet40-Datensatz im h5-Format (XYZ und Normal vom Netz, 2048 Punkte)
Laden Sie die Adresse modelnet40_ply_hdf5_2048.zip
herunter . Kopieren Sie die heruntergeladene Datensatzdatei in das Datenverzeichnis im Programm pointnet2-master und führen Sie unzip modelnet40_ply_hdf5_2048.zipden Befehl zum Dekomprimieren des Datensatzes aus
3. Die zum Erstellen von pointNet++ erforderliche Umgebung (Anaconda, Cuda, cuDNN, Pytorch, Python)
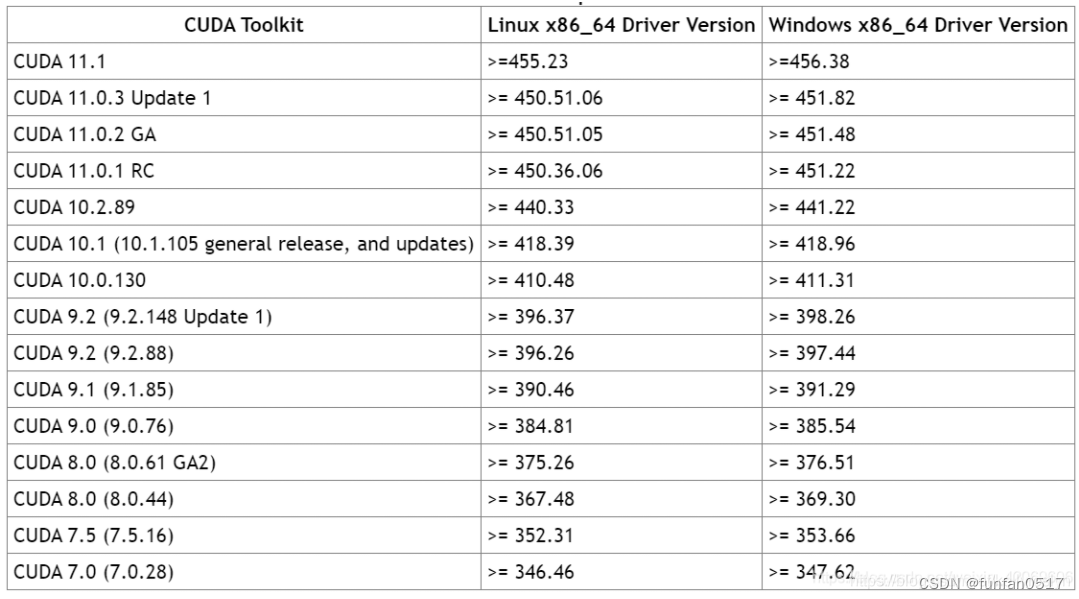
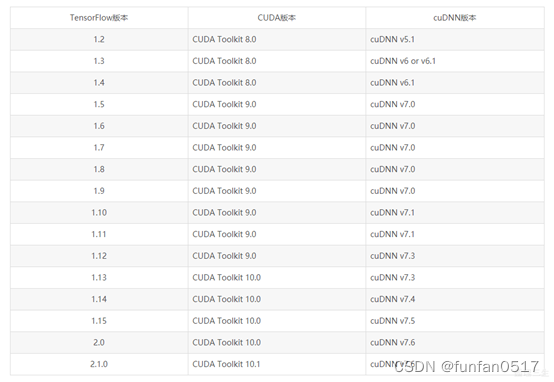
Passen Sie in Kombination mit Ihrer eigenen Grafikkartenhardware die Grafikkartentreiber-, Cuda-, Cudnn- und Tensorflow-Versionen gemäß der folgenden Abbildung an. Die diesmal
ausgewählte Umgebung ist /cuda10.0/cudnn7.4/tensorflow-gpu1.4
1. Grafikkartentreiber herunterladen und installieren
Sie können sich auf Folgendes beziehen: Mehrere Möglichkeiten, den Grafikkartentreiber auf einer physischen Ubuntu-Maschine zu installieren
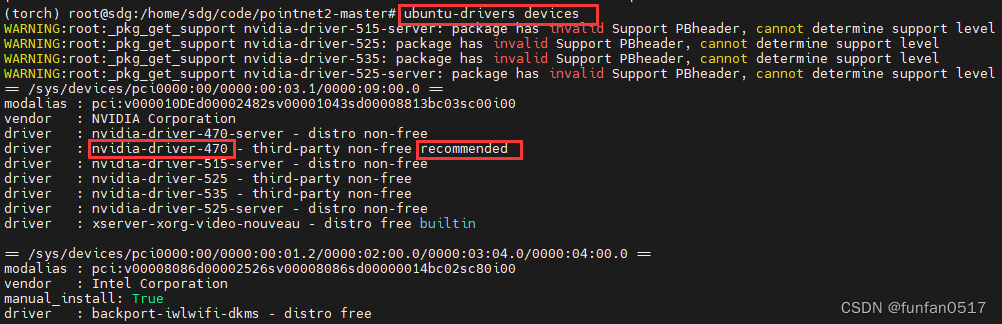
(1) Sehen Sie sich den für diese Grafikkarte geeigneten Treiber an:ubuntu-drivers devices
(2) Fügen Sie die Treiberquelle hinzu: sudo add-apt-repository ppa:graphics-drivers/ppa
(3) Aktualisieren Sie die Softwarequelle: sudo apt-get update
(4) Installieren Sie den vom System empfohlenen Grafikkartentreiber: sudo apt-get install nvidia-driver-470
(5) Installieren Sie das Tool nvidia-cuda-toolkit: sudo apt-get install nvidia-cuda-toolkit
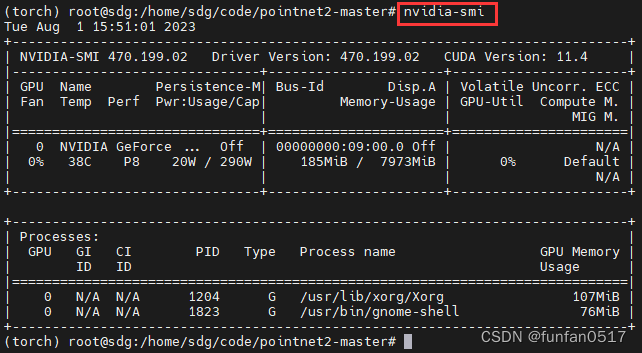
(6) Testen Sie, ob der Grafikkartentreiber wurde erfolgreich installiert:nvidia-smi
2. Installation und Konfiguration von Anaconda und Cuda
Die Installationskonfiguration von Anaconda und Cuda kann sich beziehen auf: Ubuntu erstellt eine Pytorch-Umgebung (Anaconda, Cuda, cuDNN, Pytorch, Python, Pycharm, Jupyter) . Achten Sie auf die Version von Cuda, ich verwende cuda10.0
3. cudnn-Installation und -Konfiguration
Weitere Informationen finden Sie im Tutorial zum nullbasierten Reproduktionsmodell pointNet++
Wenn bei der Installation von cudnn der folgende Fehler auftritt: libcudnn7-doc_7.4.2.24-1+cuda10.0_amd64.deb ist keine Paketdatei im Debian-Format
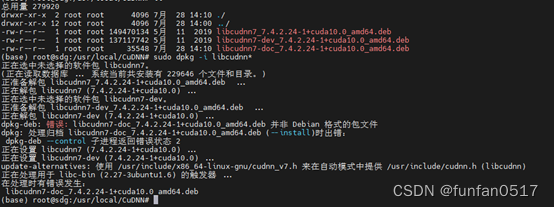
Der Grund dafür ist, dass die Installationsquelle des dritten Pakets beschädigt ist. Es wird empfohlen, cudnn7.4 gemäß den folgenden Schritten zu installieren:
(1) Wechseln Sie zuerst in das Verzeichnis /usr/local und erstellen Sie dann ein Verzeichnis CuDNN
cd /usr/local
mkdir CuDNN
cd CuDNN
(2) Gehen Sie zu https://developer.nvidia.com/rdp/cudnn-archive , um die erforderlichen Dateien herunterzuladen.
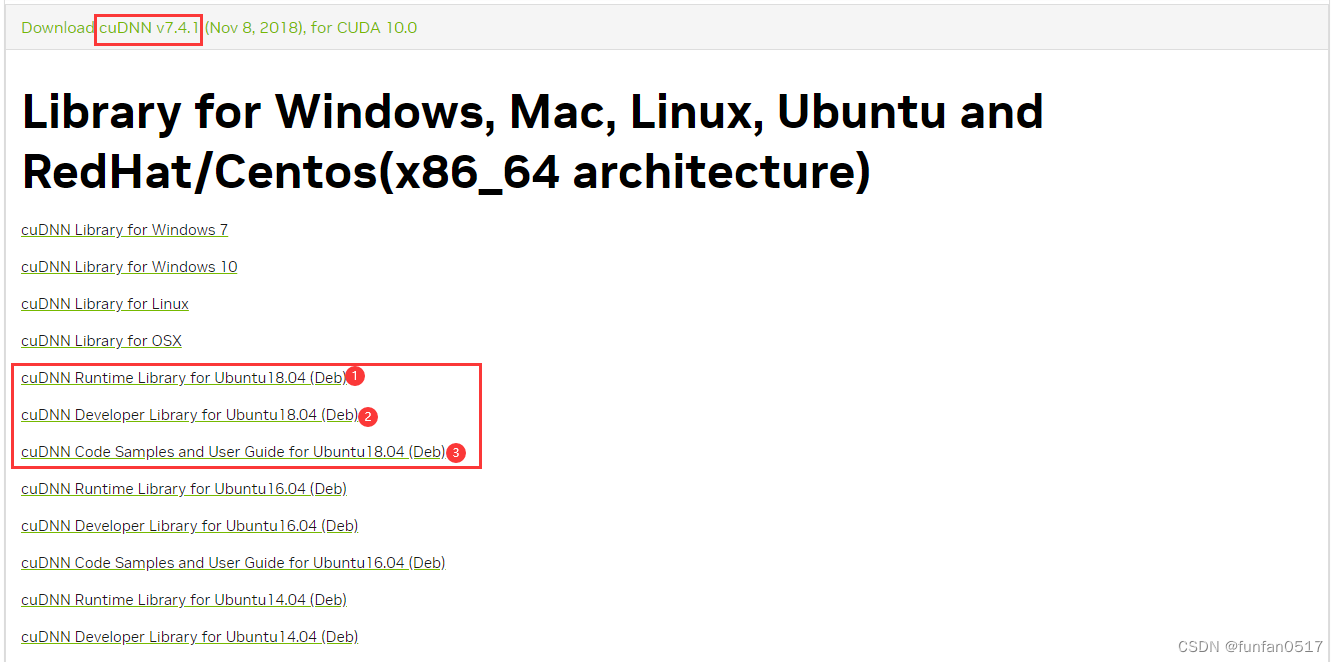
(3) Kopieren Sie die heruntergeladenen Dateien in das Verzeichnis /usr/local/CuDNN/ und

führen Sie den folgenden Befehl aus, um CUDNN7 zu installieren .4.2, hier installieren Die Reihenfolge muss wie folgt sein:
sudo dpkg -i libcudnn7_7.4.2.24-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-dev_7.4.2.24-1+cuda10.0_amd64.deb
sudo dpkg -i libcudnn7-doc_7.4.2.24-1+cuda10.0_amd64.deb
(4) Kopieren Sie die Datei in den Ordner /usr/local/cuda/include und ändern Sie die Berechtigungen:
sudo cp /usr/include/cudnn.h /usr/local/cuda/include
sudo chmod a+x /usr/local/cuda/include/cudnn.h
(5) Testbefehl, um zu prüfen, ob die Installation erfolgreich ist:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2

4. Installation und Konfiguration der Python-Umgebung und der Tensorflow-abhängigen Bibliothek
(1) Aktivieren Sie die standardmäßige virtuelle Umgebung (Basisumgebung): source activate
(2) Erstellen Sie eine virtuelle Umgebung namens Torch basierend auf Python3.7: conda create -n torch python=3.7
(3) Wechseln Sie zur erstellten virtuellen Torch-Umgebung: conda activate torch
(4) Installieren Sie die Python3-Pip-Bibliothek:sudo apt-get install python3-pip
Wenn bei der Installation der python3-pip-Bibliothek der folgende Fehler gemeldet wird: Die folgenden Pakete weisen nicht erfüllte Abhängigkeiten auf
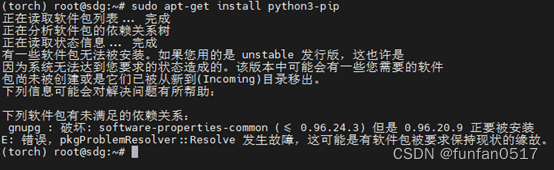
Sie können die Installation von aptitude anstelle von apt-get verwenden. Aptitude ist intelligenter im Umgang mit Abhängigkeitsproblemen:
apt-get install aptitude
sudo aptitude install python3-pip
(5) Andere abhängige Bibliotheken installieren: pip install numpy scipy matplotlib pylint
(6) Tensorflow installieren: pip install tensorflow-gpu==1.14.0
Führen Sie nach der Installation python -c 'import tensorflow as tf; print(tf.__version__)'einen Test durch, um zu sehen, ob die GPU verwendet werden kann. Die Informationen zur Tensorflow-Version werden angezeigt.
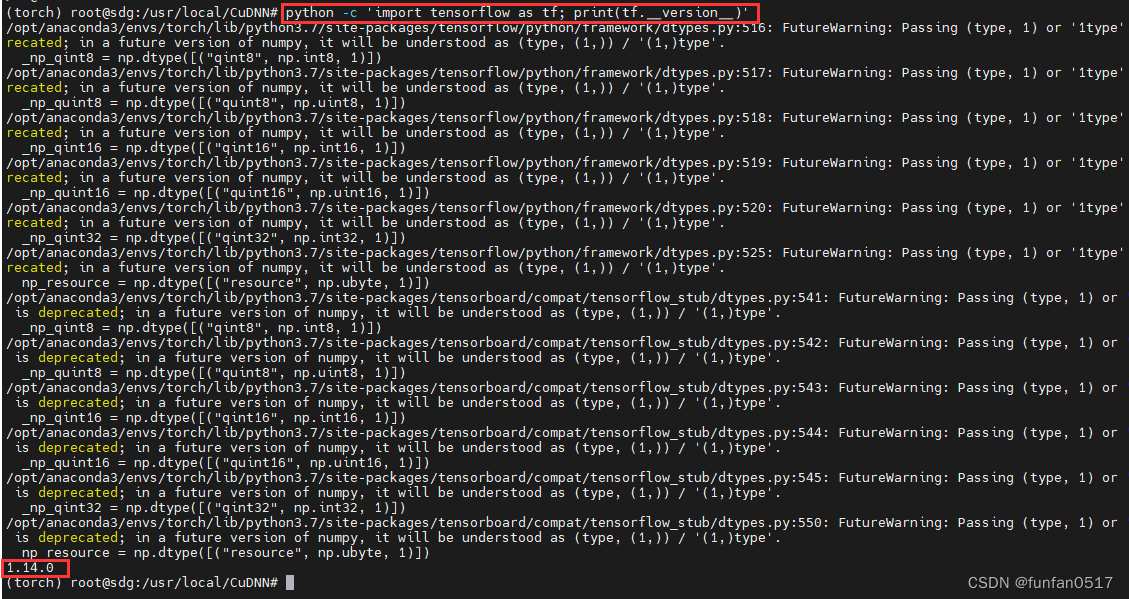
Hinweis: Es ist normal, dass in diesem Schritt Warnungen angezeigt werden. Obsessiv -Zwangsstörung kann den Aufforderungen folgen, die Antwortdatei in Klammern zu setzen. „1“ wird in „(1,)“ geändert, was durch das Problem der Python-Klasse verursacht wird, sodass Sie sich nicht damit befassen müssen
Wenn beim Testen von Tensorflow der folgende Fehler auftritt: TypeError: Deskriptoren können nicht direkt erstellt werden.
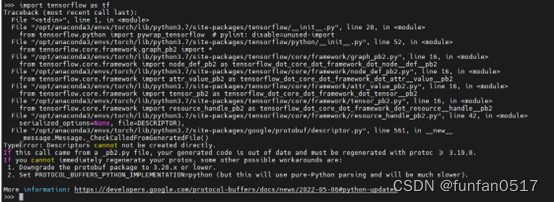
Geben Sie zunächst die Eingabetaste ein pip uninstall protobuf, um die vorhandene Version zu deinstallieren,
und geben Sie dann die Eingabetaste ein, um pip install protobuf==3.19.0die entsprechende Version neu zu installieren
5. Installation und Konfiguration von gcc5 und g++5
(1) Installieren Sie gcc5 und g++5: sudo apt install gcc-5 g++-5
(2) Überprüfen Sie die Versionsinformationen von gcc und g++:
gcc -v
g++ -v
Überprüfen Sie die Version und stellen Sie fest, dass gcc und g++ immer noch auf gcc7 und g++7 verweisen, sodass Sie den Softlink manuell ändern müssen
(3) Geben Sie das Verzeichnis /usr/bin ein und sichern Sie den alten Softlink:
cd /usr/bin
sudo mv gcc gcc_backup
sudo mv g++ g++_backup
(4) Erstellen Sie einen neuen Softlink
sudo ln -s gcc-5 gcc
sudo ln -s g++-5 g++
(5) Überprüfen Sie die Versionsinformationen von gcc und g++ erneut und Sie werden feststellen, dass es bereits 5 ist
gcc -v
g++ -v
4. Führen Sie pointNet++ aus
1. Ändern Sie die Skriptdatei von tf
(1) Geben Sie das Verzeichnis /pointnet2-master/tf_ops/ ein und ändern Sie die folgenden Dateien
vi tf_ops/sampling/tf_sampling_compile.sh
vi tf_ops/grouping/tf_grouping_compile.sh
vi tf_ops/3d_interpolation/tf_interpolate_compile.sh
(2) Am Beispiel von tf_sampling_compile.sh ist der ursprüngliche Inhalt
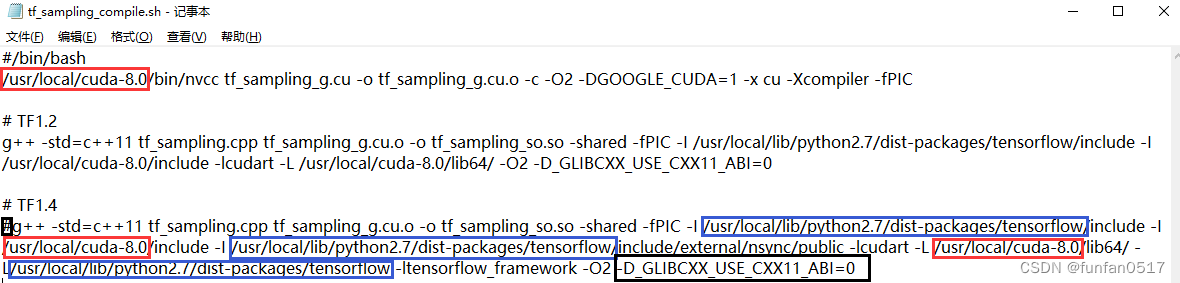
(3) Der geänderte Inhalt ist wie folgt:
1. Dieses Mal verwende ich tensorflow1.14, kommentiere den Inhalt von TF1.2 aus und gebe den Kommentar von TF1.4 frei.
2. Die gcc5-Version wird dieses Mal verwendet, wenn der gcc Die Version ist größer als 4. Dann wird die Option -D_GLIBCXX_USE_CXX11_ABI = 0 im Kompilierungsskript nicht benötigt. Löschen Sie sie.
3. Überprüfen Sie den Pfad von cuda und tensorflow, die Sie selbst installiert haben
- cuda-Pfad: Ersetzen Sie /usr/local/cuda-${ VERSION } entsprechend der von Ihnen installierten Version, meine ist /usr/local/cuda-10.0
- Der Pfad von Tensorflow: Führen Sie
python -c 'import tensorflow as tf; print(tf.sysconfig.get_lib())'den Befehl aus, die Ausgabe ist der Pfad von Tensorflow, meiner ist /opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow
Ersetzen Sie den Cuda-Pfad und den Tensorflow-Pfad im Skript wie folgt
| Originalinhalt | Inhalt ersetzt |
|---|---|
| /usr/local/cuda-8.0 | /usr/local/cuda-10.0 |
| /usr/local/lib/python2.7/dist-packages/tensorflow | /opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow |
(4) Der geänderte Inhalt ist:

2. Kompilieren Sie diese Datei und geben Sie sie aus
(1) Führen Sie den folgenden Befehl aus, um die Datei libtensorflow_framework.so abzurufen (ändern Sie sie entsprechend Ihrem eigenen Tensorflow-Verzeichnis).
cd /opt/anaconda3/envs/torch/lib/python3.7/site-packages/tensorflow/
cp libtensorflow_framework.so.1 libtensorflow_framework.so
Wenn dieser Schritt nicht ausgeführt wird, kann während der Kompilierung der folgende Fehler auftreten: /usr/bin/ld: can not find -ltensorflow_framework Collect2: Fehler: ld hat 1 Exit-Status zurückgegeben

(2) Führen Sie den folgenden Befehl aus, um die SO-Datei zu kompilieren und auszugeben (ändern Sie sie entsprechend dem Verzeichnis Ihres eigenen pointnet2-masters).
cd /home/sdg/code/pointnet2-master/tf_ops/grouping/
chmod 777 tf_grouping_compile.sh
sh tf_grouping_compile.sh
cd /home/sdg/code/pointnet2-master/tf_ops/sampling/
chmod 777 tf_sampling_compile.sh
sh tf_sampling_compile.sh
cd /home/sdg/code/pointnet2-master/tf_ops/3d_interpolation/
chmod 777 tf_interpolate_compile.sh
sh tf_interpolate_compile.sh
Wenn die Befehle chmod und cd nicht ausgeführt werden, wird der folgende Fehler angezeigt: gcc: Fehler: tf_sampling_g.cu: Keine solche Datei oder kein solches Verzeichnis

(3) Nach Abschluss der Kompilierung werden die entsprechenden .cu.o- und .so-Dateien abgerufen

3. Ändern Sie den pointNet++-Quellcode
Aufgrund des grammatikalischen Unterschieds zwischen Python2 und Python3 müssen Sie xrange im Code durch „range“ ersetzen und nach dem Drucken Klammern hinzufügen
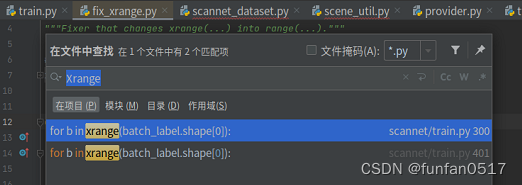
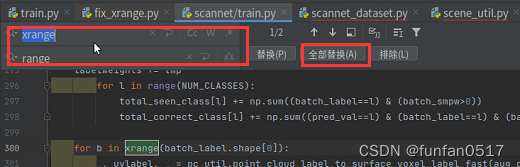
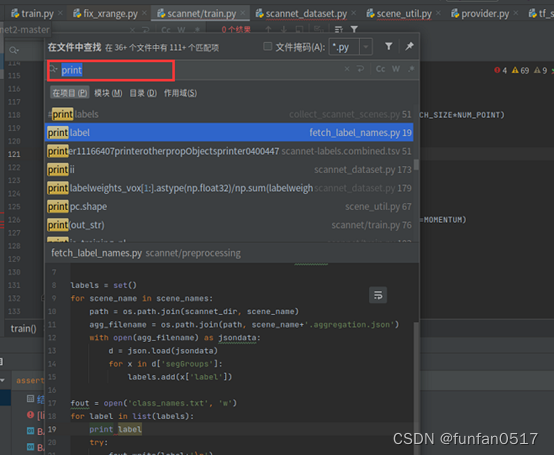
4. Führen Sie das Trainingsmodell aus
(1) Wechseln Sie in die entsprechende virtuelle Umgebung: conda activate torch
(2) Führen Sie das Trainingsmodell aus:python train.py
5. Lösung häufiger Probleme im Betrieb
1. Fehler: {NotFoundError}libcudart.so.10.0: Gemeinsam genutzte Objektdatei kann nicht geöffnet werden: Keine solche Datei oder kein solches Verzeichnis
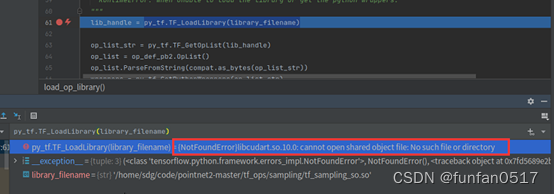
Fehlerursache: Es liegt ein Problem mit den Umgebungsvariablen von Anaconda und Cuda vor.
Lösung: Überprüfen Sie die Verzeichnisse von Anaconda und Cuda und fügen Sie relevante Umgebungsvariablen hinzu

2.报错:{NotFoundError}/home/sdg/code/pointnet2-master/tf.ops/sampling/tf.sampling_so.s0:( undefiniertes Symbol: _ZM10temsorflow120pDefBuilder4AttrESs
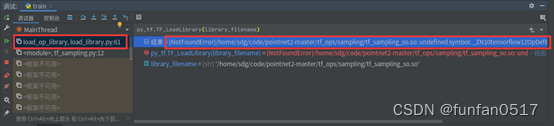
Fehlerursache: Wenn die gcc-Version größer als 4 ist, ist die Option -D_GLIBCXX_USE_CXX11_ABI = 0 im Kompilierungsskript nicht erforderlich.
Lösung: Löschen Sie -D_GLIBCXX_USE_CXX11_ABI = 0 in den oben genannten 3 Kompilierungsskripten
3.Fehler:FileNotFoundError: [Errno 2] Keine solche Datei oder kein solches Verzeichnis:'/home/sdg/code/pointnet2-master/data/modelnet40_normal_resampled/shape_names.txt'

Fehlerursache: Keine relevanten Dateien gefunden.
Lösung: Benennen Sie die Datei „modelnet40_shape_names.txt“ unter „data/modelnet40_normal_resampled/“ in „shape_names.txt“ um
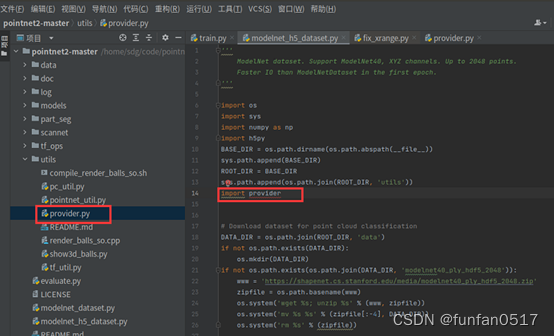
4. Hinweis: Das {AttributeError}Modul „provider“ hat kein Attribut „rotate_point_cloud“.

Fehlerursache: Die Benennung der Python-Datei ist identisch mit dem Fehler, der durch die verwendete Drittanbieter-Bibliothek verursacht wird. Der Quellcode enthält eine Datei „provider.py“, sodass die Anbieterbibliothek nicht installiert werden muss.
Lösung: Deinstallieren Sie die installierte Anbieterbibliothek (PIP-Deinstallationsanbieter), und die rote Flagge des Importanbieters hat keinen Einfluss auf den Vorgang
5. Fehler: 64,00 MB (67108864 Bytes) vom Gerät konnten nicht zugewiesen werden: CUDA_ERROR_OUT_OF_MEMORY: nicht genügend Speicher
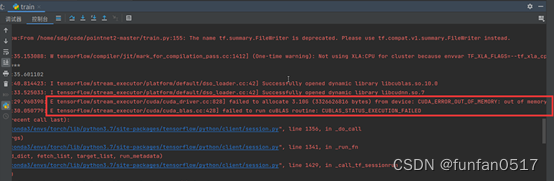
Fehlerursache: Nicht genügend Grafikkartenspeicher
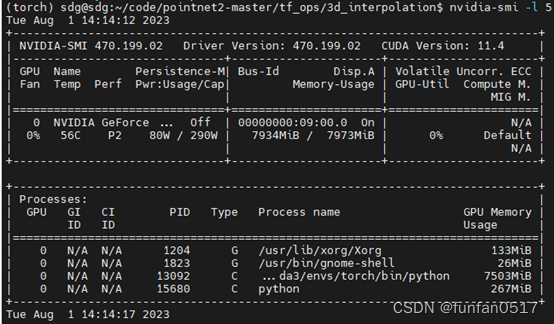
Lösung: Ersetzen Sie die Grafikkarte (empfohlen 24G Videospeicher)