Wie der Titel vermuten lässt, geht es in diesem Blog hauptsächlich um
Warum ist in void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint>> &allKeypoints){} maxY = iniY + hCell + 6 +6 statt +3?
Aus Gründen der Kontinuität wird die Funktion ComputeKeyPointsOctTree eingeführt. Weitere Informationen finden Sie im Blog: Referenzlink
(Wenn Sie mit dieser Funktion vertraut sind, können Sie direkt zum zweiten Teil springen )
Erstens: Einführung in die ComputeKeyPointsOctTree-Funktion
1. Was macht diese Funktion?
Teilen Sie jede Ebene des Bildpyramidenbilds in kleine Blöcke auf und extrahieren Sie mit dem FAST-Algorithmus Merkmalspunkte für jeden Block. Da die Anzahl der extrahierten Merkmalspunkte groß sein muss, müssen wir die Anzahl der Merkmalspunkte extrahieren, die extrahiert werden sollen für jede Ebene gemäß dem ORBExtrator-Konstruktor. Filtern und verteilen Sie die Merkmalspunkte (diskretisieren Sie die Merkmalspunkte und sorgen Sie für eine gleichmäßige Verteilung der Merkmalspunkte), erhalten Sie die von allen endgültigen Bildpyramiden extrahierten Schlüsselpunkte und berechnen Sie die Winkelinformationen dieser Merkmalspunkte .
Wir definieren einen zweischichtigen Vektorcontainer zum Speichern aller Merkmalspunkte. Beachten Sie, dass es sich um einen zweidimensionalen Vektor handelt. Die erste Dimension speichert die Anzahl der Schichten der Pyramide und die zweite Dimension speichert alle aus dem Pyramidenbild extrahierten Merkmale diese Schicht. Punkt.
vector < vector<KeyPoint> > allKeypoints;
Dann rufen wir die Funktion auf, um die Merkmalspunkte jeder Bildebene mithilfe von Quadtree zu berechnen und sie zuzuweisen. Denken Sie daran, dass wir jeder Pyramidenebene die in der Konfigurationsdatei angegebene Anzahl von Feature-Punkten zuweisen möchten. Wie Sie nFeatures-Feature-Punkten nLevels zuweisen, haben wir bereits im letzten Artikel beschrieben. Allerdings wird nur die Anzahl und die spezifische Verteilung angegeben ist nicht verfügbar. Klar, um es klar auszudrücken: Im vorherigen Schritt (Link unten) haben wir gerade eine Pyramide erstellt, um anzugeben, wie viel jeder Schicht der Pyramide zugewiesen wird, aber es ist immer noch eine leere Pyramide. Wir werden diese leere füllen Pyramide mit dieser Funktion!ORB-SLAM2 ---- ORBextractor::ComputePyramid function_Courage2022's Blog-CSDN Blog
2. Definition von Schleifenvariablen und dreischichtiger Schleife
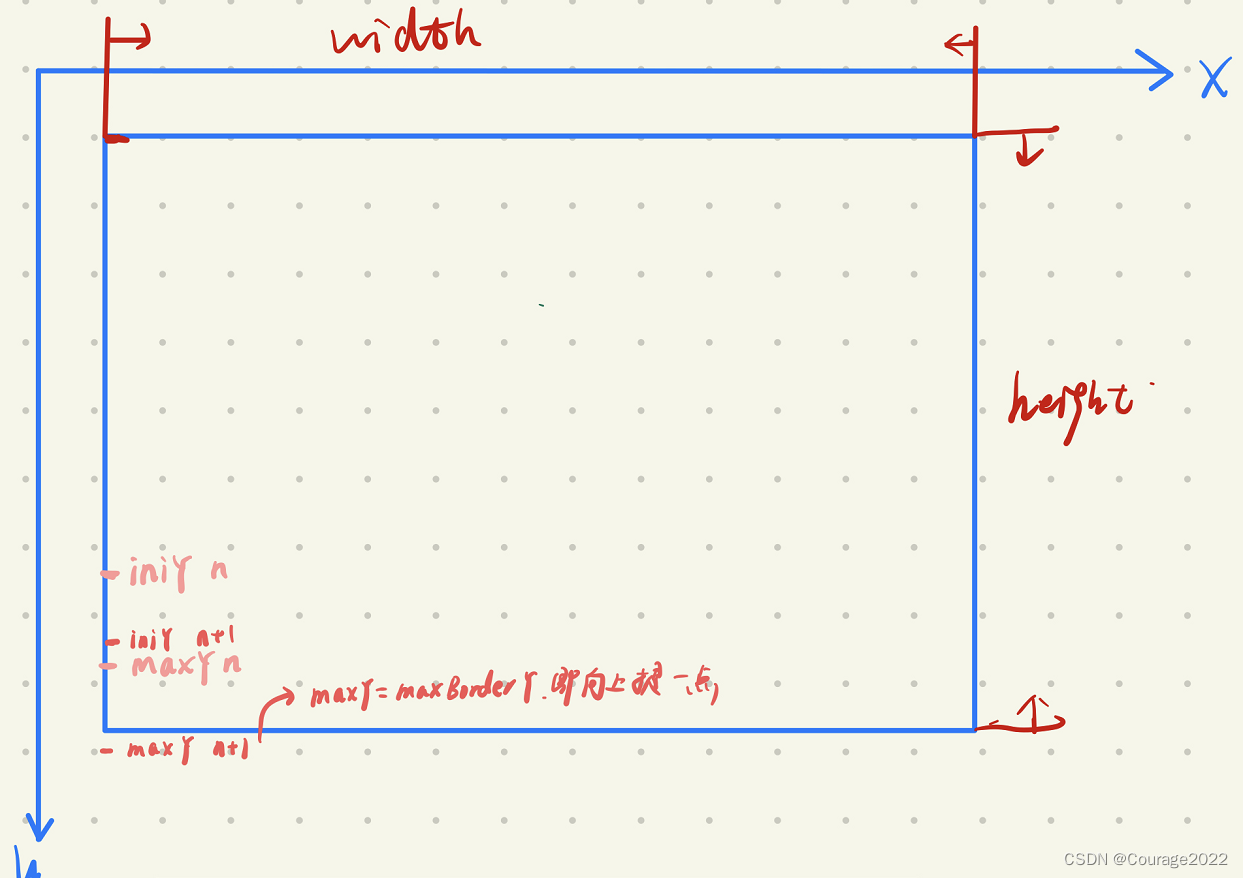
2.1 minBorderX, minBorderY, maxBorderX, maxBorderY des Levelzyklus
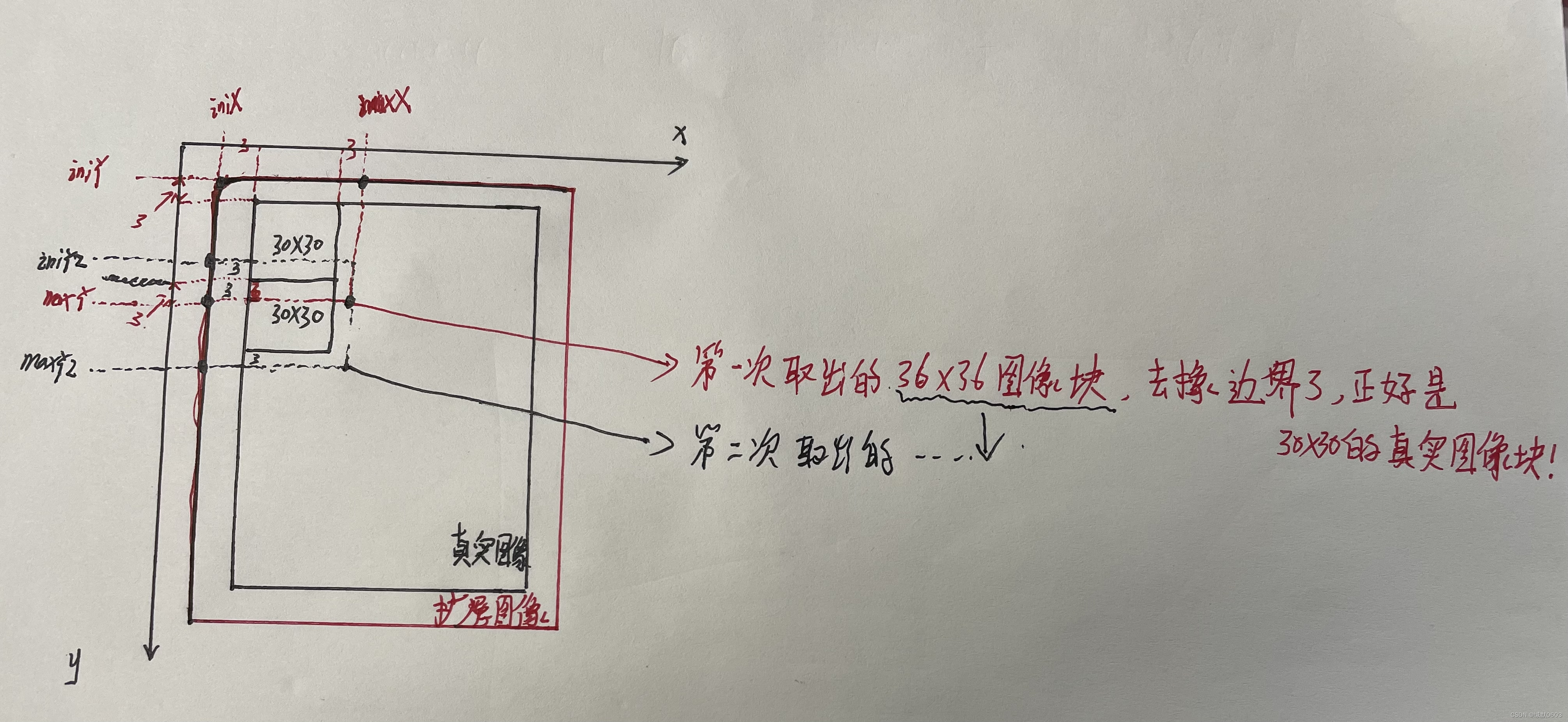
Wir definieren die Schleifenvariablen minBorderX, minBorderY, maxBorderX, maxBorderY der ersten Ebene (für jede Ebene der Bildpyramide), wie in der folgenden Abbildung dargestellt:
Daher besteht die Koordinatengrenze des Bildes darin, dass das Originalbild um 3 Pixelwerte erweitert wird. Warum den Pixelwert erweitern? Ich habe bereits im vorherigen Artikel gesagt, daher werde ich es nicht wiederholen!
[Hinweis]: Die kleinen schwarzen Quadrate hier zeigen das Bild an, und die roten Quadrate zeigen an, dass 3 Pixelwerte auf der Grundlage des Bildes nach außen erweitert wurden, sodass die Pixel an der Bildgrenze auch die Möglichkeit haben, Schlüssel zu extrahieren Punkte.
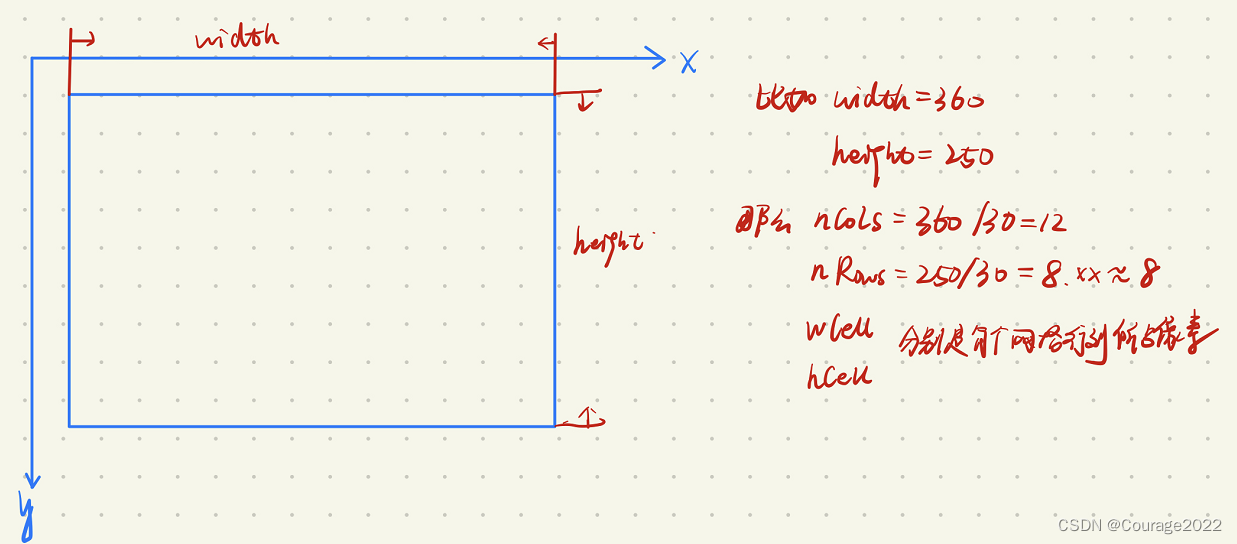
2.2 vToDistributeKeys, Breite, Höhe, nCols, nRows, wCell, hCell der Level-Schleife
[Hinweis]: Die Breite und Höhe sind hier die roten Quadrate im obigen Bild; nCols und nRows geben die Anzahl der Bildblockzellen in Zeilen bzw. Spalten an; wCell und hCell sind die Anzahl der Pixelzeilen und -spalten, die von Bildblockzellen belegt werden .
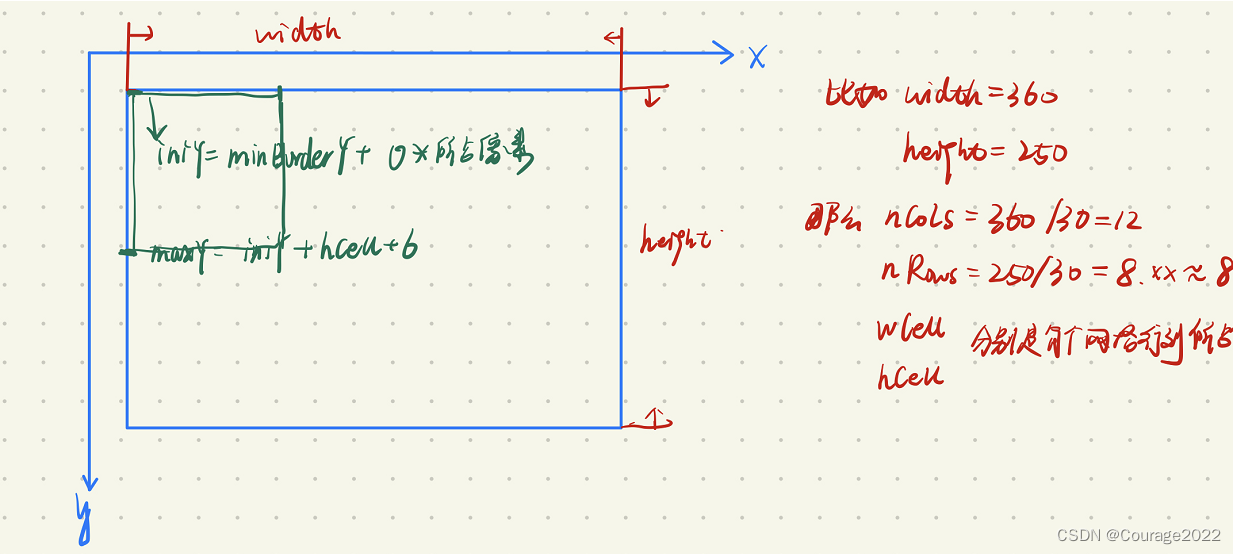
2.3 iniX, maxX, iniY, maxY beim Durchlaufen der zweiten Schicht und der dritten Schicht
Angenommen, wir führen zum ersten Mal eine Schleife durch und die Variablen sind wie in der folgenden Abbildung dargestellt:
Warum dann 6 hinzufügen? Aufgrund der Kantenanpassungs-Feature-Punkte fügen wir jedoch außerhalb des Bildes eine 3-Pixel-Hülle hinzu, um sicherzustellen, dass der Kantenteil Feature-Punkte extrahieren kann! ( Hier ist die Erklärung im Referenzblog. Ich glaube nicht, dass sie sehr klar ist. Die Erklärung hier ist der Zweck des Schreibens dieses Blogs. Lassen Sie uns weiter unten darüber sprechen. )
3. Was bewirken die drei Schleifen?
Die erste Ebene der for-Schleife: Berechnen Sie die Schleifenvariable jeder Ebene für die Verwendung in den nächsten beiden Ebenen
Die zweite Ebene der for-Schleife: Durchlaufen Sie jede Zeile, berechnen Sie die anfänglichen und maximalen Zeilenkoordinaten. Das maxY der vorherigen Ebene und das iniY der nächsten Ebene sind in der Abbildung dargestellt, da es 6 gibt.
Wenn außerdem das initialisierte iniY größer als die Grenze -3 ist, bedeutet dies, dass die Grenze des Bildes überschritten wurde. Warum ist es -3, denn wenn wir FAST verwenden, um Schlüsselpunkte zu extrahieren, um die Situation zu vermeiden, dass Die Grenze kann nicht extrahiert werden, wir müssen nach außen einen Radius von 3 hinzufügen. Shell, weshalb 6 hinzugefügt wird. Wenn iniY größer als Grenze-3 ist, bedeutet dies, dass die Shell die Grenze erreicht hat.
Wenn außerdem die maximale Y-Koordinate des Gitters die Grenzkoordinaten überschreitet, soll die maximale Y-Koordinate zu den Grenzkoordinaten werden.
Das Gleiche gilt für die Spaltendurchquerung.
In der innersten Schleife verwenden wir einen Container vector<cv::KeyPoint> vKeysCell, um die aus dem aktuellen Raster extrahierten Feature-Punkte zu speichern. Rufen Sie die integrierte Funktion von opencv auf, um Feature-Punkte zu extrahieren.

Zwei: maxY = iniY + hCell + 6 Warum ist es +6 statt +3?
Schauen Sie sich zuerst den Code an:
// 计算进行特征点提取的图像区域尺寸
const float width = (maxBorderX - minBorderX);
const float height = (maxBorderY - minBorderY);Die obigen beiden Codezeilen stellen das oben erwähnte rote Quadrat dar, dh das Bild, dessen Grenze des realen Bildes auf eine Grenze von 3 Pixeln erweitert wird (später wird es zu: erweitertem Bild). Dann teilen Sie das erweiterte Bild auf:
// 计算网格在当前层的图像有的行数和列数
const int nCols = width / W;
const int nRows = height / W;
// 计算每个图像网格所占的像素行数和列数
const int wCell = ceil(width / nCols);
const int hCell = ceil(height / nRows);Die nächsten beiden for-Schleifen durchlaufen die Anzahl der Bildblöcke:
// 开始遍历图像网格,还是以行开始遍历的
for (int i = 0; i < nRows; i++)
{
const float iniY = minBorderY + i * hCell;
float maxY = iniY + hCell + 6;
// 开始列的遍历
for (int j = 0; j < nCols; j++)
{
...
}
}erklären:
Nach diesem Codefluss kann es leicht missverstanden werden, dass das erweiterte Bild in kleine Bildblöcke von 30 x 30 unterteilt wird und Schlüsselpunkte jeweils aus den kleinen Bildblöcken extrahiert werden. Wenn ich so denke, habe ich die Bedeutung von + nie verstanden 6...
Denn wenn FAST Schlüsselpunkte extrahiert, muss außen eine Schale mit einem Radius von 3 hinzugefügt werden, um zu vermeiden, dass die Grenze nicht extrahiert werden kann, sodass die Größe des an die Funktion FAST () gesendeten Bildblocks 36 x 36 beträgt. Dies ist der Zweck von +6, um sicherzustellen, dass in der FAST()-Funktion der Bildblock jedes 30x30-Realbildes an der Extraktion von Schlüsselpunkten beteiligt ist.
Wenn Sie den Code wie folgt schreiben: Teilen Sie das reale Bild in 30 x 30 Bildblöcke auf, erweitern Sie die Grenze von 3 Pixeln für jeden Bildblock und senden Sie es dann an die Funktion FAST (), um wichtige Punkte zu extrahieren. Sie werden es nicht falsch verstehen, aber es wird mehr Rechenressourcen verbrauchen. Dafür ist die +6 da
Bildbeispiel: