Wenn Sie nach dem Erlernen der Grundlagen von Python weitermachen möchten, lassen Sie uns einige Algorithmen erstellen! Schließlich sind Programmiersprachen nur Werkzeuge und strukturelle Algorithmen sind die Seele.
Wie kann ein Anfänger mit Python-Algorithmen beginnen?
Mehrere indische Brüder haben auf GitHub einen Leitfaden für Anfänger zu verschiedenen Python-Algorithmen erstellt. Vom Prinzip bis zum Code wird Ihnen alles anschaulich erklärt. Um Anfängern ein intuitiveres Verständnis zu ermöglichen, sind einige Teile auch mit Animationen ausgestattet.
https://github.com/TheAlgorithms/Python
Dieses Projekt besteht hauptsächlich aus zwei Teilen: Der erste Teil ist die Erläuterung der Grundprinzipien verschiedener Algorithmen und der andere die Code-Implementierung verschiedener Algorithmen.
Implementierung des Algorithmuscodes
Auch die bereitgestellten Informationen zur Code-Implementierung des Algorithmus sind relativ umfangreich. Neben dem Python-Code für die Grundprinzipien des Algorithmus gibt es auch Code-Implementierungen einschließlich neuronaler Netze, maschinellem Lernen und Mathematik.
Beispielsweise werden im Bereich des neuronalen Netzwerks das BP-neuronale Netzwerk, das Faltungs-Neuronale Netzwerk, das vollständig Faltungs-Neuronale Netzwerk und das Perzeptron angegeben.
Beispiel für einen Faltungs-Neuronalen Netzwerkcode
Der Code wird auf GitHub im Python-Dateiformat gespeichert und Schüler, die ihn benötigen, können ihn selbst speichern und herunterladen.
https://github.com/TheAlgorithms/Python
Algorithmusprinzip
Im Teil des Algorithmusprinzips werden hauptsächlich Sortieralgorithmen, Suchalgorithmen, Interpolationsalgorithmen, Sprungsuchalgorithmen, Schnellauswahlalgorithmen, Tabu-Suchalgorithmen, Verschlüsselungsalgorithmen usw. vorgestellt.
Natürlich werden neben Texterklärungen auch Links zu entsprechenden Ressourcen gegeben, die zum besseren Verständnis des Algorithmus beitragen, einschließlich Links zu Wikipedia und interaktiven Animationswebsites.
Beispielsweise sind in einigen Algorithmusabschnitten die angegebenen interaktiven Animationslinks perfekt, um das Verständnis der Funktionsweise des Algorithmus zu erleichtern.

Adresse der interaktiven Animation:
https://www.toptal.com/developers/sorting-algorithms/bubble-sort
Sortieralgorithmus
Blasensortierung

Die Blasensortierung, manchmal auch sinkende Sortierung genannt, ist ein relativ einfacher Sortieralgorithmus. Dieser Algorithmus wird implementiert, indem die zu sortierende Liste durchlaufen wird, die Positionen zweier benachbarter Datenelemente ausgetauscht werden, die nicht den Anordnungsregeln entsprechen, und dann die Liste wiederholt durchlaufen wird, bis keine Datenelemente mehr ausgetauscht werden müssen. Die Liste wird sortiert, wenn keine Datenelemente ausgetauscht werden müssen.
Bucket-Sortieralgorithmus
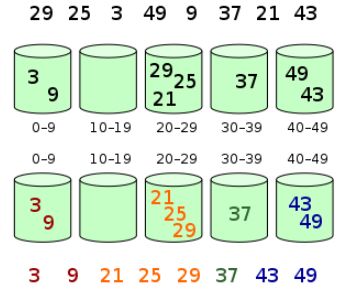
Bucket-Sortierung oder sogenannte Bin-Sortierung ist ein Sortieralgorithmus, der ein Array in eine endliche Anzahl von Buckets aufteilt. Jeder Bucket wird einzeln sortiert, und es ist möglich, einen anderen Sortieralgorithmus zu verwenden oder die Bucket-Sortierung weiterhin rekursiv zum Sortieren zu verwenden.
Cocktailsorte

Cocktail Sort, auch bekannt als Directed Bubble Sort, Cocktail Stir Sort, Stir Sort (was auch als Variation von Selection Sort angesehen werden kann), Ripple Sort, Hin- und Her-Sortierung oder Happy Hour Sort, ist eine Variation von Bubble Sort. Der Unterschied zwischen diesem Algorithmus und der Blasensortierung besteht darin, dass die Sortierung in der Reihenfolge in beide Richtungen erfolgt.
Anmerkung des Übersetzers:
Die Cocktailsorte ist eine leichte Variante der Bubble-Sorte. Der Unterschied besteht darin, dass es von niedrig nach hoch und dann von hoch nach niedrig geht, während die Blasensortierung nur jedes Element in der Sequenz von niedrig nach hoch vergleicht. Er kann eine etwas bessere Leistung als die Blasensortierung erzielen, da die Blasensortierung nur aus einer Richtung vergleicht (von niedrig nach hoch) und nur ein Element pro Schleife verschiebt.
Am Beispiel der Sequenz (2,3,4,5,1) muss die Cocktail-Sortierung die Sequenz nur einmal durchlaufen, um die Sortierung abzuschließen, bei Verwendung der Blasensortierung sind jedoch vier Mal erforderlich. Im Zustand der Zufallszahlenfolge ist die Effizienz der Cocktail- und Blasensortierung jedoch sehr gering.
Sortieren durch Einfügen

Insertion Sort ist ein einfacher und intuitiver Sortieralgorithmus. Es funktioniert, indem es eine geordnete Sequenz erstellt und bei unsortierten Daten die sortierte Sequenz von hinten nach vorne durchsucht, die entsprechende Position findet und sie einfügt. Bei der Implementierung der Einfügungssortierung wird normalerweise der zusätzliche Platz der In-Place-Sortierung zum Sortieren verwendet. Daher ist es beim Scannen von hinten nach vorne erforderlich, die sortierten Elemente wiederholt nach und nach nach hinten zu verschieben, um Einfügungsraum für die bereitzustellen neueste Elemente.
Zusammenführen, sortieren
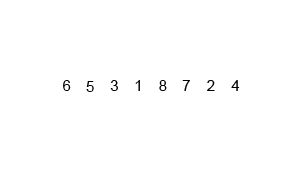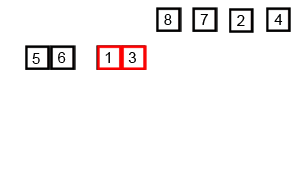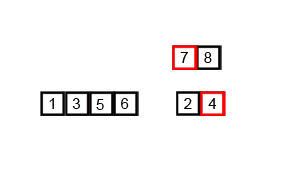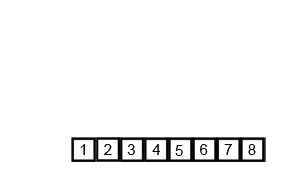
Zusammenführungssortierung (Zusammenführungssortierung oder Zusammenführungssortierung) ist ein effektiver Sortieralgorithmus, der auf der Zusammenführungsoperation erstellt wird, mit einer Effizienz von O(n log n) (Big O-Notation). Es wurde erstmals 1945 von John von Neumann vorgeschlagen. Dieser Algorithmus ist eine sehr typische Anwendung von Divide and Conquer, und jede Ebene der Divide and Conquer-Rekursion kann gleichzeitig ausgeführt werden.
Haufen
Heap ist ein Sortieralgorithmus, der auf Vergleichen basiert. Man kann es sich als eine verbesserte Auswahlsortierung vorstellen. Es unterteilt seine Eingabe in sortierte und unsortierte Bereiche und verkleinert den unsortierten Bereich iterativ, indem es das größte Element extrahiert und in den sortierten Bereich verschiebt.
Anmerkung des Übersetzers:
Heap begann mit der Heap-Sortierung, die 1964 von J._W._J._Williams veröffentlicht wurde, als er den binären Heap-Baum als Datenstruktur dieses Algorithmus vorschlug.
In der Warteschlange extrahiert der Planer wiederholt den ersten Job in der Warteschlange und führt ihn aus, da in Wirklichkeit einige Aufgaben mit kurzer Zeit lange auf den Abschluss warten, oder einige Jobs, die nicht kurz, aber wichtig sind, auch abgeschlossen werden sollten Priorität. Der Heap ist eine Datenstruktur, die zur Lösung solcher Probleme entwickelt wurde.
Basissortierung
Die Radix-Sortierung (Radix-Sortierung) ist ein nicht vergleichender Ganzzahl-Sortieralgorithmus. Sein Prinzip besteht darin, die Ganzzahl entsprechend den Ziffern in verschiedene Zahlen zu zerlegen und dann jede Ziffer einzeln zu vergleichen. Da Ganzzahlen in bestimmten Formaten auch Zeichenfolgen (z. B. Namen oder Datumsangaben) und Gleitkommazahlen darstellen können, ist die Basissortierung nicht auf Ganzzahlen beschränkt. Die Erfindung der Radix-Sortierung lässt sich auf den Beitrag von Herman Hollery zur Lochkarten-Tabelliermaschine (Tabulation Machine) im Jahr 1887 zurückführen.
Auswahl sortieren

Selection Sort ist ein einfacher und intuitiver Sortieralgorithmus. Es funktioniert wie folgt. Suchen Sie zuerst das kleinste (größte) Element in der unsortierten Sequenz, speichern Sie es am Anfang der sortierten Sequenz, suchen Sie dann weiter nach dem kleinsten (größten) Element aus den verbleibenden unsortierten Elementen und fügen Sie es dann am Ende der sortierten Sequenz ein . Und so weiter, bis alle Elemente sortiert sind.
Shellsort

ShellSort ist eine Verallgemeinerung der Einfügungssortierung, die es ermöglicht, weit voneinander entfernte Elemente auszutauschen. Die Idee besteht darin, die Liste der Elemente so anzuordnen, dass sie von einer beliebigen Stelle aus beginnt und berücksichtigt, dass jedes n-te Element eine sortierte Liste ergibt. Eine solche Liste heißt h-geordnet. Entsprechend kann man sich eine gezackte Liste von h vorstellen, wobei jedes Element einzeln sortiert ist.
Topologie
Eine topologische Sortierung oder topologische Sortierung eines gerichteten Graphen ist eine lineare Reihenfolge seiner Scheitelpunkte, sodass für jede gerichtete Kante uv vom Scheitelpunkt u bis zum Scheitelpunkt v u in der Sortierung vor v steht. Beispielsweise können die Eckpunkte eines Diagramms auszuführende Aufgaben darstellen, und die Kanten können Einschränkungen darstellen, dass eine Aufgabe vor einer anderen ausgeführt werden muss; in dieser Anwendung ist die topologische Sortierung einfach eine gültige Abfolge von Aufgaben. Topologische Sortierung ist genau dann möglich, wenn der Graph keine gerichteten Zyklen hat, d. h. wenn es sich um einen gerichteten azyklischen Graphen (DAG) handelt. Jede DAG verfügt über mindestens eine topologische Sortierung, und es sind Algorithmen zum Erstellen der topologischen Sortierung jeder DAG in linearer Zeit bekannt.
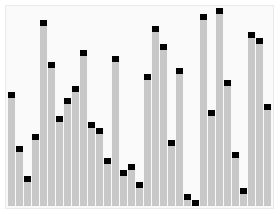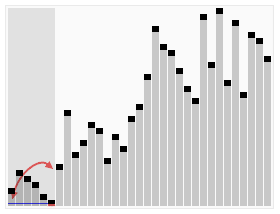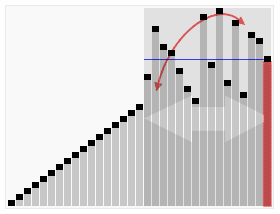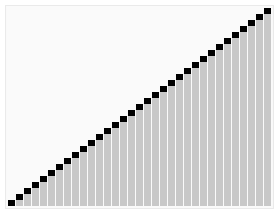
Zeitkomplexes Liniendiagramm
Vergleich der Komplexität von Sortieralgorithmen (Blasensortierung, Einfügungssortierung, Auswahlsortierung)
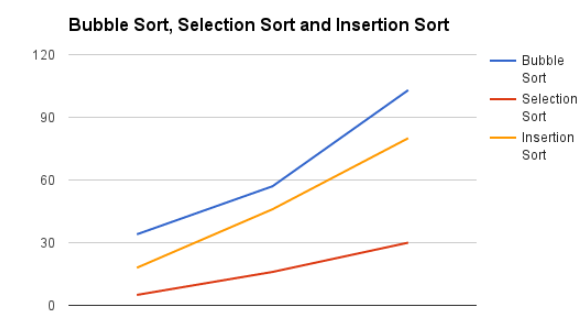
Vergleichssortieralgorithmus:
Quicksort ist ein sehr schneller Algorithmus, aber ziemlich schwierig zu implementieren. Bubble Sort ist ein langsamer Algorithmus, aber einfach zu implementieren. Zum Sortieren kleiner Datensätze ist die Blasensortierung möglicherweise die bessere Wahl.
Suchalgorithmus
lineare Suche

Die lineare Suche oder sequentielle Suche ist die Methode, mit der der Zielwert in der Liste gefunden wird. Es prüft nacheinander jedes Element der Liste auf den Zielwert, bis eine Übereinstimmung gefunden wird oder bis alle Elemente durchsucht sind.
Unter der Annahme, dass ein Array N Elemente enthält, ist der gesuchte spezifische Wert im besten Fall das erste Element im Array, sodass nur ein Vergleich erforderlich ist. Und der schlimmste Fall ist, dass der spezifische Wert, den Sie suchen, nicht in diesem Array oder im letzten Element des Arrays ist, was N Vergleiche erfordert.
Binäre Binärsuche

Die binäre Suche, auch Halbintervallsuche oder logarithmische Suche genannt, wird verwendet, um die Position eines Zielwerts in einem sortierten Array zu finden. Es vergleicht den Zielwert mit dem mittleren Element des Arrays. Wenn sie nicht gleich sind, wird die Hälfte des Ziels eliminiert und die Suche wird mit der verbleibenden Hälfte fortgesetzt, bis sie erfolgreich ist.
Interpolationssuche
Die Interpolationssuche ist ein Algorithmus zum Suchen nach Schlüsseln in einem Array, das bereits nach dem Wert des Schlüssels sortiert ist.
Erstmals 1957 von WW Peterson beschrieben. Interpolationssuchen ähneln der Suche nach Namen in Telefonverzeichnissen (dem Schlüssel zum Bestellen von Bucheinträgen): Bei jedem Schritt berechnet der Algorithmus die Position im verbleibenden Suchraum, basierend auf den Schlüsselwerten an den Grenzen des Suchraum und Der Wert des Schlüssels kann normalerweise durch lineare Interpolation ermittelt werden, um das Element zu finden.
Im Gegensatz dazu wählt die binäre Suche immer die Mitte des verbleibenden Suchraums aus und verwirft die Hälfte oder die andere Hälfte, abhängig vom Vergleich zwischen dem an der geschätzten Position gefundenen Schlüssel und dem gesuchten Schlüssel. Der verbleibende Suchraum wird auf den Teil vor oder nach der geschätzten Position eingegrenzt. Die lineare Suche verwendet nur Gleichheit, da sie Elemente von Anfang an einzeln vergleicht und dabei jegliche Reihenfolge ignoriert.
Durchschnittliche Interpolationssuchen führen log(log(n))-Vergleiche durch (wenn Elemente gleichmäßig verteilt sind), wobei n die Anzahl der zu durchsuchenden Elemente ist. Im schlimmsten Fall (z. B. wenn der numerische Wert des Schlüssels exponentiell ansteigt) kann es zu O(n) Vergleichen kommen.
Bei einer interpolierten sequentiellen Suche wird die Interpolation verwendet, um Elemente in der Nähe des gesuchten Elements zu finden, und anschließend wird eine lineare Suche verwendet, um das genaue Element zu finden.
Sprungsuche
Sprungsuche bezeichnet einen Suchalgorithmus für geordnete Listen. Zunächst wird die Lkm aller Elemente überprüft, wobei K ∈ N und m die Blockgröße ist, bis ein Element gefunden wird, das größer als der Suchschlüssel ist. Um die genaue Position des Suchschlüssels in der Liste zu finden, wird eine lineare Suche in der Unterliste L[(k-1)m, km] durchgeführt.
Der optimale Wert von m ist √n, wobei n die Länge der Liste L ist. Da beide Schritte des Algorithmus höchstens √n Terme sind, läuft der Algorithmus in O(√n) Zeit. Das ist besser als die lineare Suche, aber schlechter als die binäre Suche. Der Vorteil gegenüber Letzterem besteht darin, dass eine Sprungsuche nur einmal zurückgesprungen werden muss, während eine Binärsuche n-mal zu einem Datensatz zurückspringen kann.
Der Algorithmus kann geändert werden, indem mehrere Ebenen von Sprungsuchen in Unterlisten durchgeführt werden, bevor schließlich eine lineare Suche durchgeführt wird. Für die k-Level-Sprungsuche beträgt die optimale Blockgröße ml (ab 1 gezählt) auf Level l n(k1)/k. Der modifizierte Algorithmus führt k Rückwärtssprünge aus und läuft in O(kn1/(k+1)) Zeit.
Schnellauswahl-Algorithmus
Quicksort (Quicksort) ist ein Auswahlalgorithmus, der das k-kleinste Element aus einer ungeordneten Liste findet. Es ist im Prinzip mit Quicksort verwandt. Wie die schnelle Sortierung wurde er von Tony Hall vorgeschlagen und wird daher auch als Hall-Auswahlalgorithmus bezeichnet. In ähnlicher Weise handelt es sich in praktischen Anwendungen um einen effizienten Algorithmus mit einer guten durchschnittlichen Zeitkomplexität, aber die schlechteste Zeitkomplexität ist nicht ideal. Die Schnellauswahl und ihre Varianten sind die in der Praxis am häufigsten verwendeten effizienten Auswahlalgorithmen.
Die Grundidee der Schnellauswahl ist dieselbe wie die der Schnellsortierung. Ein Element wird als Benchmark zum Partitionieren von Elementen ausgewählt, und Elemente, die kleiner und größer als der Benchmark sind, werden in zwei Bereiche links und rechts vom Benchmark unterteilt . Der Unterschied besteht darin, dass bei der Schnellauswahl nicht beide Seiten rekursiv besucht werden, sondern nur die Elemente auf einer Seite rekursiv eingegeben werden, um die Suche fortzusetzen. Dies reduziert die durchschnittliche Zeitkomplexität von O(n log n) auf O(n), obwohl der schlimmste Fall immer noch O(n2) ist.
Tabusuche
Tabu Search (Tabu Search, TS, auch bekannt als Tabu Search) ist ein moderner heuristischer Algorithmus, der um 1986 von Fred Glover, einem Professor an der University of Colorado, vorgeschlagen wurde. Es handelt sich um eine Suchmethode, die verwendet wird, um lokal optimale Lösungen zu umgehen . Zunächst wird eine Ausgangslösung erstellt; auf dieser Grundlage „bewegt“ sich der Algorithmus zu einer benachbarten Lösung. Verbessern Sie die Qualität der Lösung über viele aufeinanderfolgende Schritte hinweg.
Passwort
Caesar-Chiffre
Die Caesar-Chiffre, auch Caesar-Chiffre, Shift-Chiffre, Caesar-Code oder Caesar-Shift genannt, ist eine der einfachsten und bekanntesten Verschlüsselungstechniken.
Es handelt sich um eine Substitutions-Chiffre, bei der jeder Buchstabe im Klartext durch einen Buchstaben an einer bestimmten Anzahl von Positionen im Alphabet ersetzt wird. Wenn Sie beispielsweise um 3 nach links verschieben, wird D durch A ersetzt, E wird zu B und so weiter.
Die Methode ist nach Julius Cäsar benannt, der sie ursprünglich in seiner privaten Korrespondenz verwendete. Der von der Caesar-Chiffre durchgeführte Verschlüsselungsschritt wird häufig als Teil eines komplexeren Schemas wie der Vigenère-Chiffre verwendet und findet im ROT13-System immer noch moderne Anwendung. Wie alle Einzelbuchstaben-Ersetzungs-Chiffren sind Caesar-Chiffren leicht zu knacken und für die Kommunikation in der modernen Praxis grundsätzlich unsicher.
Vigenère-Chiffre
Eine Vigenère-Chiffre ist eine Methode zur Verschlüsselung alphabetischer Texte mithilfe einer Reihe verschachtelter Caesar-Chiffren, die auf Schlüsselbuchstaben basieren. Es handelt sich um eine aus mehreren Buchstaben bestehende Alternativform.
Vigenère-Chiffre Diese Methode wurde erstmals von Giovan Battista Bellaso in seinem 1553 erschienenen Buch „La cifra del“ vorgeschlagen. Allerdings wurde das Schema später im 19. Jahrhundert bei Blaise de Vigenère missbraucht und ist heute weithin als „Vigenère-Chiffre“ bekannt.
Obwohl die Chiffre leicht zu verstehen und umzusetzen ist, hat sie drei Jahrhunderte lang allen Versuchen, sie zu knacken, widerstanden, daher der Name le chiffre indé chiffrable (französisch für „unverständliche Chiffre“). Friedrich Kasiski war der erste, der 1863 eine allgemeine Methode zum Knacken der Vigenère-Chiffre veröffentlichte.
Chiffre transponieren
Eine Transpositionsverschlüsselung ist ein Verschlüsselungsverfahren, bei dem die Positionen von Klartexteinheiten (normalerweise Zeichen oder Zeichengruppen) nach einem herkömmlichen System verschoben werden, sodass der Chiffretext eine Anordnung von Klartext darstellt. Das heißt, die Reihenfolge der Einheiten ändert sich (der Klartext wird neu geordnet).
Mathematisch gesehen wird eine Zwei-Zeichen-Funktion zum Verschlüsseln der Position des Zeichens und eine Umkehrfunktion zur Entschlüsselung verwendet.
RSA (Rivest–Shamir–Adleman)
Der RSA-Verschlüsselungsalgorithmus ist ein asymmetrischer Verschlüsselungsalgorithmus. RSA wird häufig in der Public-Key-Verschlüsselung und im elektronischen Handel eingesetzt. RSA wurde 1977 von Ronald Rivest, Adi Shamir und Leonard Adleman vorgeschlagen. Alle drei arbeiteten zu dieser Zeit am MIT. RSA setzt sich aus den Anfangsbuchstaben ihrer drei Nachnamen zusammen.
1973 schlug der am GCHQ arbeitende Mathematiker Clifford Cocks in einem internen Dokument einen gleichwertigen Algorithmus vor, der jedoch bis 1997 geheim gehalten wurde.
ROT13
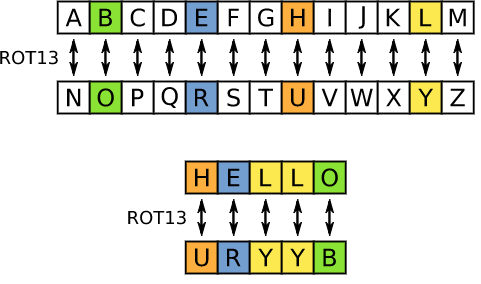
ROT13 („13 Positionen drehen“, manchmal mit dem Bindestrich ROT-13) ist eine einfache Buchstabenersetzungs-Chiffre, die einen Buchstaben durch den 13. Buchstaben nach dem Alphabet ersetzt. ROT13 ist ein Sonderfall der im antiken Rom entwickelten Caesar-Chiffre.
Da es im lateinischen Grundalphabet 26 Buchstaben (2×13) gibt, ist ROT13 das Gegenteil von sich selbst, d. Dieser Algorithmus bietet wenig kryptografische Sicherheit und wird oft als klassisches Beispiel für schwache Verschlüsselung angeführt.