Inhaltsverzeichnis
1. Der Ursprung des Aufmerksamkeitsmechanismus
2. Nadaraya-Watson-Kernel-Regression
Mit der Popularität des Transformer-Modells in den Bereichen NLP, CV und sogar CG wurde der Aufmerksamkeitsmechanismus (Attention Mechanism) von immer mehr Wissenschaftlern bemerkt und in verschiedene Deep-Learning-Aufgaben eingeführt, um die Leistung zu verbessern. Das Team von Professor Hu Shimin von der Tsinghua-Universität veröffentlichte kürzlich einen Attention Review zu CVM [1], der die Fortschritte der verwandten Forschung auf diesem Gebiet detailliert vorstellte. Für Punktwolkenanwendungen ist die Einführung eines Aufmerksamkeitsmechanismus und die Entwicklung eines neuen Deep-Learning-Modells natürlich ein Forschungsschwerpunkt. Dieser Artikel nimmt den Aufmerksamkeitsmechanismus zum Gegenstand, skizziert seine Entwicklung und seine erfolgreiche Anwendung im Bereich der Punktwolkenanwendungen und gibt einige Hinweise für Studenten, die Durchbrüche in dieser Forschungsrichtung erwarten.
1. Der Ursprung des Aufmerksamkeitsmechanismus
Eine Einführung in den Aufmerksamkeitsmechanismus finden Sie in Herrn Li Mu's ausführlichem Lehrbuch [2] Hier ist eine einfache Erklärung des Aufmerksamkeitsmechanismus. Der Aufmerksamkeitsmechanismus ist ein Mechanismus, der die menschliche visuelle Wahrnehmung simuliert und Informationen selektiv auf Empfang und Verarbeitung durchsucht. Wenn beim Screening von Informationen keine autonome Aufforderung bereitgestellt wird, d. h. wenn eine Person einen Text liest, eine Szene beobachtet oder sich ein Audio anhört, ohne nachzudenken, ist der Aufmerksamkeitsmechanismus auf anormale Informationen wie eine Schwarz-Weiß-Szene voreingenommen Ein Mädchen in Rot oder ein Ausrufezeichen in einem Absatz usw. Wenn autonome Eingabeaufforderungen eingeführt werden, z. B. wenn Sie Sätze lesen möchten, die sich auf ein bestimmtes Substantiv beziehen, oder Szenen, die mit verschiedenen Objekten verbunden sind, führt der Aufmerksamkeitsmechanismus diese Eingabeaufforderung ein und erhöht die Sensibilität für diese Informationen, wenn Informationen angezeigt werden. Um den obigen Prozess mathematisch zu modellieren, führt der Aufmerksamkeitsmechanismus drei Grundelemente ein, nämlich Abfrage, Schlüssel und Wert. Diese drei Elemente bilden zusammen die grundlegende Verarbeitungseinheit des Aufmerksamkeitsmoduls. Der Schlüssel (Key) und der Wert (Value) entsprechen der Ein- und Ausgabe von Informationen, die Abfrage (Query) dem autonomen Prompt. Die grundlegende Verarbeitungseinheit des Aufmerksamkeitsmoduls ist in der folgenden Abbildung dargestellt.
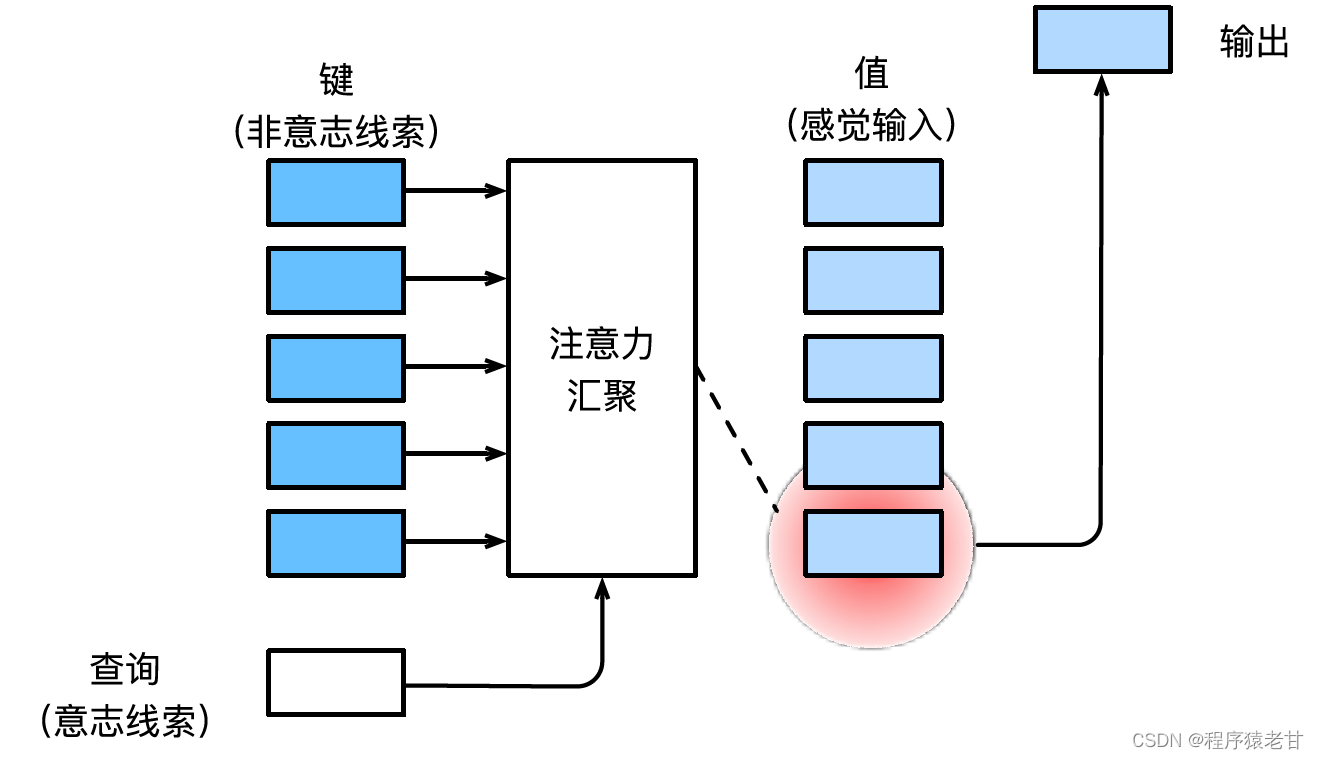
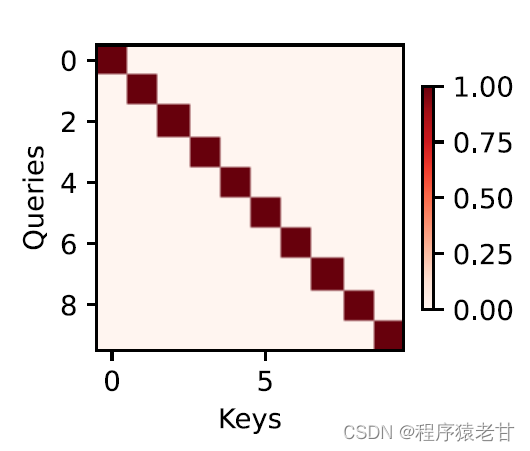
Der Aufmerksamkeitsmechanismus kombiniert die Abfrage und den Schlüssel durch Aufmerksamkeitsbündelung, um die Auswahltendenz des Werts zu realisieren. Der Schlüssel und der Wert werden gepaart, genau wie die Eingabe und Ausgabe in der Trainingsaufgabe, die eine bekannte Datenverteilung oder Kategorieentsprechung ist. Der Aufmerksamkeitsmechanismus gibt die Abfrage in den Aufmerksamkeitspool ein, erstellt den Gewichtungscode von der Abfrage zu jedem Schlüssel, erhält die Beziehung zwischen der Abfrage und dem Schlüssel und leitet dann die Ausgabe des entsprechenden Werts. Kurz gesagt, wenn die Abfrage näher an einem Schlüssel liegt, ist die Ausgabe der Abfrage näher an dem Wert, der dem Schlüssel entspricht. Dieser Prozess lenkt die Aufmerksamkeit auf die Schlüssel-Wert-Korrespondenz näher an der Abfrage, um die aufmerksamkeitskonforme Ausgabe zu leiten. Wenn eine zweidimensionale Beziehungsmatrix entsprechend der Abfrage und dem Schlüssel erstellt wird, ist sie 1, wenn die Werte gleich sind, und wenn sie unterschiedlich sind, 0, und das Visualisierungsergebnis kann ausgedrückt werden als :
2. Nadaraya-Watson-Kernel-Regression
Hier ist ein klassisches Aufmerksamkeitsmechanismusmodell, die Nadaraya-Watson-Kernel-Regression [3] [4], um die grundlegende Betriebslogik des Aufmerksamkeitsmechanismus zu verstehen. Angenommen, wir haben einen Schlüsselwert-Korrespondenzdatensatz {(x1,y1),(x2,y2),...(xi,yi)}, der von einer Funktion f gesteuert wird, besteht die Lernaufgabe darin, f zu etablieren und das Neue zu leiten Auswertung der x-Taste. In dieser Aufgabe entspricht (xi, yi) dem Schlüssel und dem Wert, die Eingabe x stellt die Abfrage dar, und das Ziel besteht darin, den entsprechenden Wert zu erhalten. Gemäß dem Aufmerksamkeitsmechanismus ist es notwendig, die Vorhersage seines Wertes zu erstellen, indem die Ähnlichkeitsbeziehung zwischen x und jedem Schlüsselwert in dem Schlüsselwert-Korrespondenzdatensatz untersucht wird. Wenn die Eingabe x näher an einem bestimmten xi-Schlüssel liegt, liegt der Ausgabewert näher an yi. Der einfachste Schätzer für Schlüsselwerte ist hier die Mittelwertbildung:
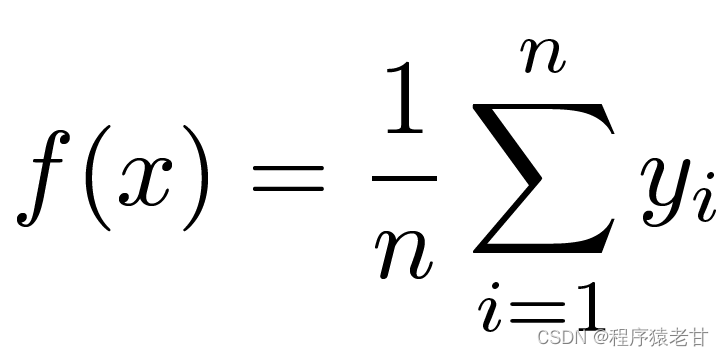
Offensichtlich ist dies keine gute Idee. Denn das Average Pooling ignoriert die Abweichung der Stichprobe in der Key-Value-Verteilung. Wird die Key-Value-Differenz in den Bewertungsprozess eingeführt, wird das Ergebnis natürlich besser. Die Nadaraya-Watson-Kernel-Regression verwendet eine solche Idee und schlägt eine gewichtete Bewertungsmethode vor:
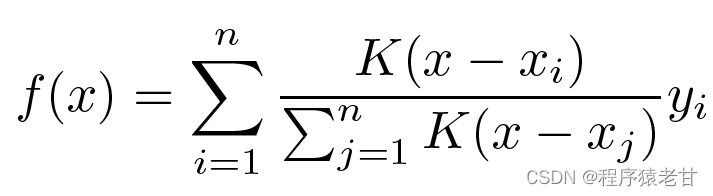
K wird als Kern betrachtet, also als Gewicht verstanden, um die Abweichung von der Differenz zu messen. Wenn die obige Formel entsprechend dem Gewicht der Differenz zwischen der Eingabe und dem Schlüssel umgeschrieben wird, kann eine eigene Formel erhalten werden:
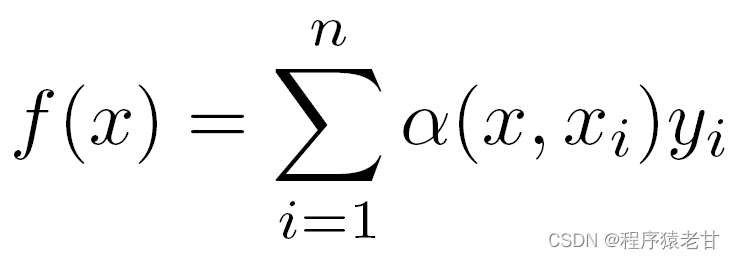
Wenn die obigen Gewichte durch ein Gaußsches Gewicht ersetzt werden, das von einem Gaußschen Kern angetrieben wird, dann kann die Funktion f ausgedrückt werden als:
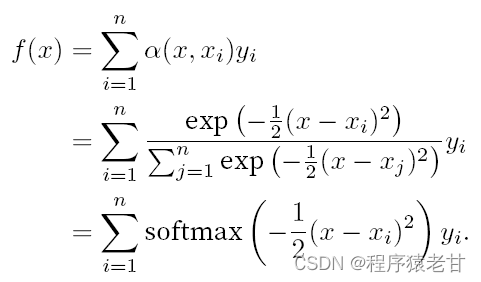
Hier ist ein Schema dargestellt, um die Anpassung verschiedener f an beispielhafte Schlüssel-Wert-Paare zu vergleichen, die aus dem durchschnittlichen Pooling (linkes Feld) und dem Gaußschen Kernel-gesteuerten Aufmerksamkeitspooling (rechtes Feld) abgeleitet wurden. Es ist ersichtlich, dass die Anpassungsleistung des letzteren viel besser ist.
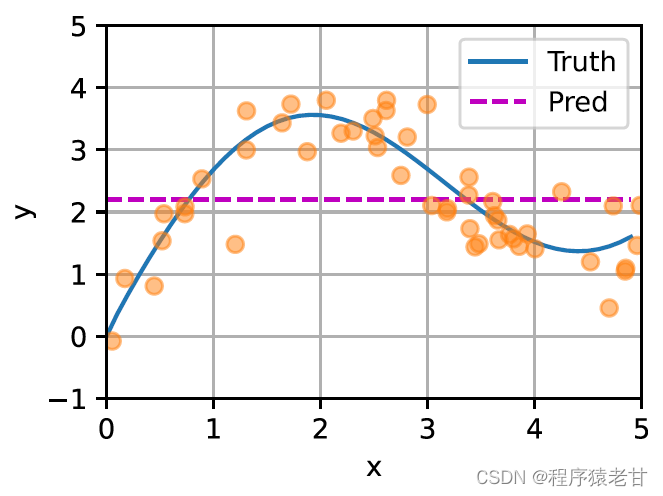
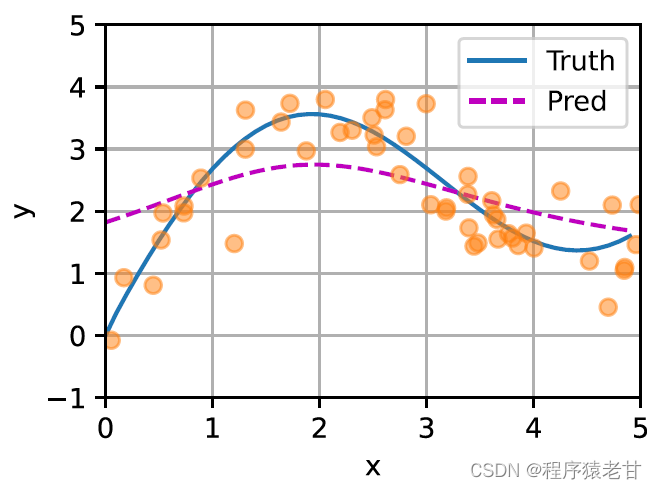
Das obige Modell ist ein nicht-parametrisches Modell, für den Fall mit lernbaren Parametern wird empfohlen, das Aufmerksamkeitsmechanismus-Kapitel von [2] zu lesen. Der hier verwendete Gaußsche Kern und sein entsprechendes Gaußsches Gewicht werden verwendet, um die Beziehung zwischen der Abfrage und dem Schlüssel zu beschreiben. Im Aufmerksamkeitsmechanismus ist die quantitative Darstellung dieser Beziehung der Aufmerksamkeitswert. Der oben erwähnte Prozess zum Erstellen von Vorhersagen für Abfragewerte kann ausgedrückt werden als Erstellen einer Bewertung basierend auf Schlüssel-Wert-Paaren für die Abfrage und durch Zuweisen von Gewichtungen zu den Bewertungen zum Erhalten von Abfragewerten, ausgedrückt als:
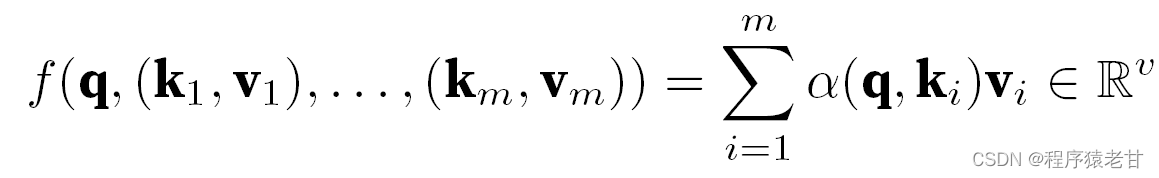
Dabei steht α für die Gewichtung, q für die Abfrage und kv für das Schlüssel-Wert-Paar. In dem Lehrbuch [2] wird auch der Umgang mit dem additiven Aufmerksamkeitsverarbeitungsverfahren der Abfrage- und Schlüssellängenfehlanpassungszeit und dem Skalierungspunktprodukt Aufmerksamkeit, das zum Definieren des Aufmerksamkeitsscores verwendet wird, eingeführt und wird hier nicht detailliert beschrieben.
3. Mehrkopfaufmerksamkeit und Selbstaufmerksamkeit
1) Mehrkopf-Aufmerksamkeit
Die Multi-Head-Aufmerksamkeit wird verwendet, um Abfragen und Unterraumdarstellungen mit unterschiedlichen Schlüsselwerten zu kombinieren und die Organisation unterschiedlicher Verhaltensweisen basierend auf dem Aufmerksamkeitsmechanismus zu realisieren, um strukturiertes Wissen und Datenabhängigkeiten zu lernen. Verschiedene lineare Projektionen werden unabhängig voneinander erlernt, um Abfragen, Schlüssel und Werte zu transformieren. Dann werden die transformierte Abfrage und der Schlüsselwert parallel an den Aufmerksamkeitspool gesendet, und dann werden die Ausgaben mehrerer Aufmerksamkeitspools zusammengefügt und durch eine andere lineare Projektion transformiert, die gelernt werden kann, und die endgültige Ausgabe wird generiert. Dieses Design wird Multi-Head-Aufmerksamkeit genannt [5]. Die folgende Abbildung zeigt ein lernbares Mehrkopf-Aufmerksamkeitsmodell:
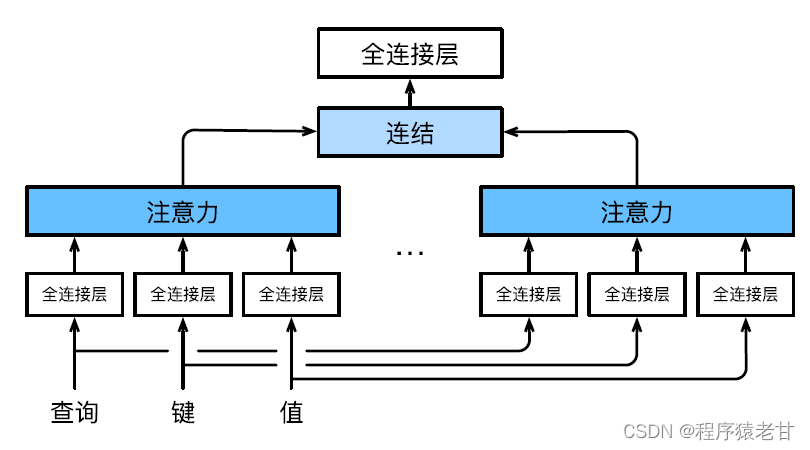
Die mathematische Definition jedes Aufmerksamkeitskopfes ist hier gegeben.Wenn eine Abfrage q, ein Schlüssel k und ein Wert v gegeben sind, ist die Berechnungsmethode jedes Aufmerksamkeitskopfes h:
![]()
Hier kann f additive Aufmerksamkeit und skalierte Punktprodukt-Aufmerksamkeit sein. Die Ausgabe der Mehrkopf-Aufmerksamkeit wird einer weiteren linearen Transformation unterzogen, um die Ausgaben mehrerer Aufmerksamkeitsmechanismen zu verketten, um komplexere Funktionen nachzuahmen.
2) Selbstaufmerksamkeit und Positionscodierung
Basierend auf dem Aufmerksamkeitsmechanismus wird die lexikalische Sequenz im NLP-Problem in den Aufmerksamkeitspool eingegeben, und eine Gruppe von lexikalischen Elementen wird gleichzeitig als Abfragen und Schlüsselwerte verwendet. Jede Abfrage berücksichtigt alle Schlüssel-Wert-Paare und erzeugt eine Aufmerksamkeitsausgabe. Da die Abfrage- und Schlüsselwerte alle aus demselben Satz von Eingaben stammen, wird dies als Selbstaufmerksamkeitsmechanismus bezeichnet. Hier wird ein Codierungsverfahren basierend auf dem Selbstaufmerksamkeitsmechanismus angegeben.
Bei einer Token-Eingangssequenz x1,x2,...,xn ist die entsprechende Ausgabe eine identische Sequenz y1,y2,...,yn. y wird ausgedrückt als:
![]()
Ich habe diese Formel zunächst nicht ganz verstanden. In Kombination mit der spezifischen Aufgabe der Textübersetzung ist es jedoch leicht zu verstehen. Die Bedeutung hier ist, dass ein Element an einer bestimmten Position eines Tokens der Ein- und Ausgabe entspricht. Das heißt, der Schlüsselwert ist das Element selbst. Wir müssen die Funktion lernen, die die Vorhersage des Werts erstellt, indem wir die Gewichte jedes Wortes und aller Wörter im Token lernen.
Beim Umgang mit Token wird auf sequentielle Operationen verzichtet, da eine parallele Berechnung der Selbstaufmerksamkeit erforderlich ist. Um Sequenzinformationen zu verwenden, können Positionscodierungen zu der Eingabedarstellung hinzugefügt werden, um absolute oder relative Positionsinformationen einzufügen. Durch Hinzufügen einer Positionseinbettungsmatrix derselben Form zur Eingabematrix, um eine absolute Positionscodierung zu erreichen , werden die Elemente, die den Zeilen und Spalten entsprechen, ausgedrückt als:
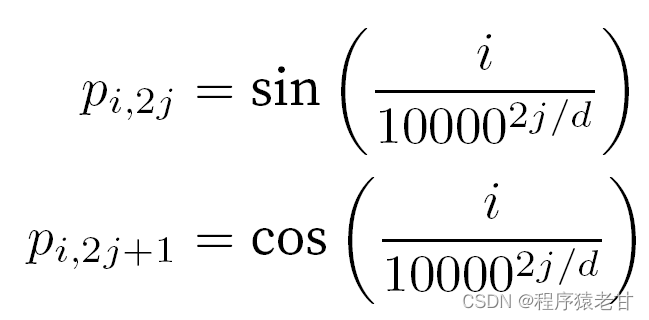
Diese auf Trigonometrie basierende Darstellung der Positionseinbettung von Matrixelementen ist nicht intuitiv. Wir wissen nur, dass es eine Beziehung zwischen der codierten Dimension und der Frequenz der Kurven gibt, die von den trigonometrischen Funktionen angetrieben werden. Das heißt, die Informationen unterschiedlicher Dimensionen innerhalb jeder lexikalischen Einheit haben unterschiedliche Häufigkeiten entsprechender trigonometrischer Funktionskurven, wie in der Abbildung gezeigt:
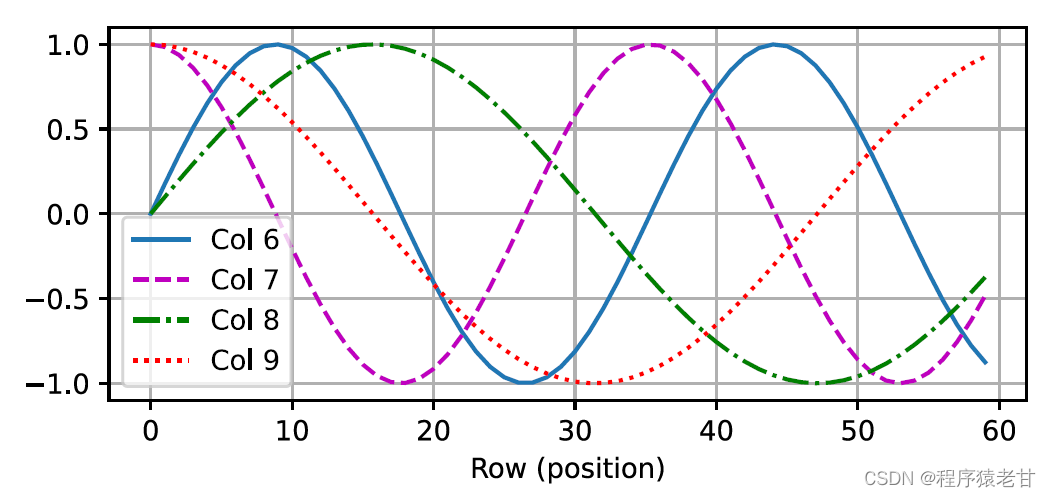
Es scheint, dass mit zunehmender Dimensionalität jedes Lemmas die seinem Intervall entsprechende Frequenz abnimmt. Um die Beziehung zwischen dieser Frequenzänderung und der absoluten Position zu verdeutlichen, wird hier ein Beispiel zur Erläuterung verwendet. Dies gibt die binäre Darstellung von 0-7 aus (die Frequenz-Heatmap befindet sich rechts):

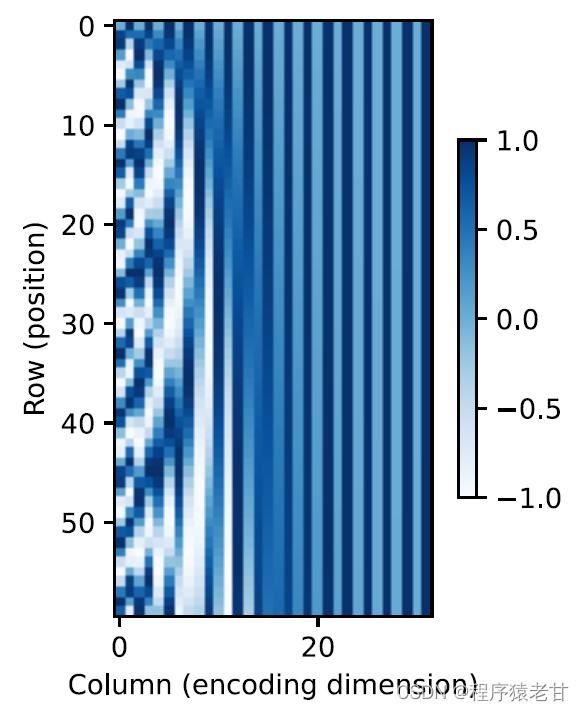
Hier werden die höheren Bits weniger häufig gewechselt als die niedrigeren Bits. Durch die Verwendung der Positionscodierung wird die Codierung verschiedener Dimensionen der Etymologie auf der Grundlage einer Frequenztransformation realisiert, und dann wird die Hinzufügung von Positionsinformationen realisiert. Die relative Positionscodierung wird hier nicht im Detail beschrieben.
4. Transformatormodell
Es ist endlich Zeit, sich zu freuen! Nachdem wir das oben genannte Wissen verstanden haben, haben wir den Grundstein für das Erlernen von Transformer gelegt. Verglichen mit dem vorherigen Selbstaufmerksamkeitsmodell, das immer noch auf dem zyklischen neuronalen Netzwerk beruht, um die Eingabedarstellung zu realisieren, basiert das Transformer-Modell vollständig auf dem Selbstaufmerksamkeitsmechanismus ohne jede Faltungsschicht oder zyklische neuronale Netzwerkschicht.
Das Transformer-Modell ist eine Codec-Architektur, und das allgemeine Architekturdiagramm sieht wie folgt aus:
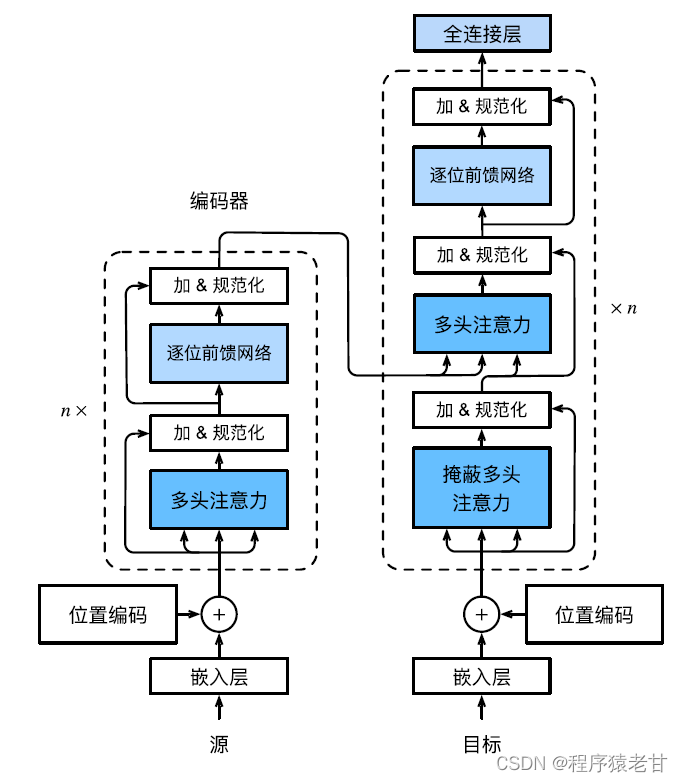
Der Transformer besteht aus einem Encoder und einem Decoder. Er ist auf der Grundlage eines Selbstaufmerksamkeitsmoduls aufgebaut. Die Quellen- (Eingabe-) Sequenz und die Ziel- (Ausgabe-) Sequenz-Einbettungsdarstellung werden mit Positionskodierung hinzugefügt und dann in das eingegeben Encoder und Decoder bzw. Der Encoder wird durch Stapeln mehrerer identischer Schichten mit jeweils zwei Unterschichten aufgebaut. Die erste Teilschicht ist Multi-Head Self-Attention Pooling, und die zweite Teilschicht ist ein positionsbasiertes Feedforward-Netzwerk. Die von der Encoder-Schicht berechneten Abfragen, Schlüssel und Werte stammen aus der Ausgabe der vorherigen Schicht. Jede Unterschicht verwendet Restverbindungen. Ähnlich wie der Encoder besteht auch der Decoder aus mehreren identischen Schichten und verwendet Restverbindungen und Schichtnormalisierung. Zusätzlich zu den beiden im Codierer beschriebenen Unterschichten fügt der Decodierer eine Zwischen-Unterschicht hinzu, die als Codierer-Decodierer-Aufmerksamkeitsschicht bezeichnet wird. Die Abfragen in dieser Schicht stammen aus der Ausgabe der vorherigen Decoderschicht, während die Schlüssel und Werte aus der Ausgabe des gesamten Encoders stammen. Bei der Decoder-Selbstaufmerksamkeit werden Abfragen, Schlüssel und Werte alle aus der Ausgabe der vorherigen Decoderschicht abgeleitet. Jede Position im Decoder kann nur alle vorherigen Positionen berücksichtigen. Diese maskierte Aufmerksamkeit bewahrt die autoregressiven Eigenschaften und stellt sicher, dass Vorhersagen nur von generierten Ausgabetoken abhängen. Die spezifische Implementierung verschiedener Module wird nicht im Detail beschrieben.
Hinweis: Die obige Begriffserklärung, prinzipielle Einführung und Formel zum Aufmerksamkeitsmechanismus beziehen sich hauptsächlich auf das Lehrbuch von Lehrer Li Mu [2].
Basierend auf dem oben erwähnten Prinzip des Aufmerksamkeitsmechanismus wird ein Deep-Learning-Modell des Aufmerksamkeitsmechanismus für Aufgaben der Punktwolkenverarbeitung vorgeschlagen. Wir werden verwandte Arbeiten im nächsten Blog im Detail vorstellen, herzlich willkommen, weiterhin auf meinen Blog zu achten.
Referenz
[1] M. H. Guo, TX, Xu, JJ. Liu, et al. Aufmerksamkeitsmechanismen in Computer Vision: Eine Umfrage [J]. Computational Visual Media, 2022, 8(3): 331-368.
[2] A. Zhang, ZC. Lipton, M. Li und AJ. Smola, Dive into Deep Learning [B], https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf .
[3] EA. Nadaraya. Zur Schätzung der Regression[J]. Theory of Probability & Its Applications, 1964, 9(1): 141-142.
[4]GS. Watson. Glatte Regressionsanalyse. Sankhyā: The Indian Journal of Statistics, Reihe A, S. 359‒372.
[5] A. Vaswani, N. Shazeer, N. Parmar, et al. Aufmerksamkeit ist alles, was Sie brauchen. Fortschritte bei neuronalen Informationsverarbeitungssystemen, 2017,5998‒6008.