머리말
속담처럼 우리 직업을 배우는 게이 남성은 파트너를 찾기가 쉬운가요?
새해가 거의 끝나가고 여자 친구를 찾을 때입니다.
여기서 웹사이트를 찾았습니다. 한 번 보실 수 있습니다.
일련의 단일 혜택을 보낼 필요가 없는 경우 이러한 데이터를 수집하는 방법도 배울 수 있습니다.

환경 및 모듈
환경 개발
- 파이썬 3.8
- 파이참
모듈 사용
import parsel --> pip install parsel
import requests --> pip install requests
import csv
import re
모듈 설치
모듈을 설치하지 않은 친구
win + R, cmd 입력, 설치 명령 pip install module name 입력(설치 속도가 느린 것 같으면 국내 미러 소스 전환 가능)
모듈 설치 문제:
-
Python 타사 모듈을 설치하는 경우:
1. Win + R, cmd를 입력하고 확인을 클릭한 다음 설치 명령 pip install module name(pip install requests)을 입력하고 Enter 키를 누릅니다
. 2. pycharm에서 터미널을 클릭하여 설치 명령을 입력합니다. -
설치 실패 이유:
-
실패 1: pip는 내부 명령이 아닙니다
해결 방법: 환경 변수 설정 -
실패 2: 빨간색(읽기 시간 초과) 솔루션이 많습니다
. 네트워크 연결 시간이 초과되었기 때문에 미러 소스를 전환해야 합니다.
칭화대: https://pypi.tuna.tsinghua.edu.cn/simple Alibaba
Cloud: https://mirrors.aliyun.com/pypi/simple/
중국과학기술대 https://pypi.mirrors. ustc.edu.cn /simple/
화중이공대학교: https://pypi.hustunique.com/
산둥이공대학교: https://pypi.sdutlinux.org/
Douban: https://pypi.douban. com/simple/
예: pip3 install - i https://pypi.doubanio.com/simple/ 모듈 이름
- 실패 3: cmd가 설치되었다고 표시하거나 설치에 성공했지만 여전히
pycharm에서 가져올 수 없습니다.파이썬 인터프리터가 설정되지 않았습니다.
pycharm에서 파이썬 인터프리터를 구성하는 방법은 무엇입니까?
- 파일 선택(file) >>> 설정(setting) >>> 프로젝트(project) >>> 파이썬 인터프리터(python interpreter)
- 기어를 클릭하고 추가를 선택합니다.
- 파이썬 설치 경로 추가
pycharm은 플러그인을 어떻게 설치합니까?
- 파일 선택(file) >>> 설정(setting) >>> 플러그인(plugins)
- Marketplace를 클릭하고 설치하려는 플러그인의 이름을 입력합니다.예: 번역 플러그인의 경우 translation을 입력하고 / Sinicization 플러그인의 경우 Chinese를 입력합니다.
- 해당 플러그인을 선택하고 설치를 클릭합니다.
- 설치가 성공적으로 완료되면 pycharm을 다시 시작하는 옵션이 팝업되고 확인을 클릭하면 다시 시작이 적용됩니다.
기본 사고 과정
1. 데이터 소스 분석:
- 명확한 요구 사항:
수집된 데이터란 —> 데이터 데이터 <정적 웹 페이지>
페이지의 소스 코드에서
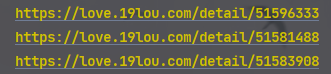
모든 ID를 취득하는 한 모든 데이터 정보를 수집할 수 있습니다.

모든 소녀의 세부 정보 페이지의 URL ID가 있습니다.
2. 코드 구현 단계:
- 요청 보내기
- 데이터 검색
- 분석 데이터
- 데이터를 저장
모든 상세 페이지 ID 가져오기:
- 요청을 보내고 URL 주소에 대한 요청을 보내도록 브라우저를 시뮬레이트합니다.

-
데이터 가져오기, 서버 개발자 도구 에서 반환한 응답 데이터 가져오기 -> 응답 -
데이터를 구문 분석하고 원하는 데이터 콘텐츠 추출
세부 정보 페이지 ID —> UID
세부 정보 페이지 정보 가져오기 -

요청 보내기, 데이터 세부 정보 페이지 의 URL 주소 URL 주소에 대한 요청을 보내도록 브라우저를 시뮬레이트 -
데이터 가져오기, 서버 웹 페이지 소스 코드 에서 반환된 응답 데이터 가져오기 -
데이터 파싱, 원하는 데이터의
기본 정보 추출 -
데이터 저장, 데이터 내용을 로컬에 저장,
기본 데이터 정보를 csv 형식
으로 저장, 사진 데이터 저장, 로컬 폴더 저장

구현 코드
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入csv
import csv
# 导入正则
import re
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['昵称',
'性别',
'年龄',
'身高',
'体重',
'出生日期',
'生肖',
'星座',
'籍贯',
'所在地',
'学历',
'婚姻状况',
'职业',
'年收入',
'住房',
'车辆',
'照片',
'详情页',
])
csv_writer.writeheader()
1. 요청을 보내고 URL 주소에 대한 요청을 보내는 브라우저를 시뮬레이트합니다.
- 안티 크롤링
을 방지하기 위해 개발자 도구에 복사하여 붙여넣을 수 있는 브라우저 헤더 요청 헤더 시뮬레이션 - <Response [200]>
응답 객체의 200 상태 코드는 요청이 성공했음을 나타냅니다.
for page in range(1, 11):
# 请求链接
url = f'https://********.com/valueApp/api/love/searchLoveUser?page={page}&perPage=12&sex=0'
# 伪装模拟
headers = {
# User-Agent 用户代理, 表示浏览器基本信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
print(response)
2. 데이터 가져오기, 서버에서 반환된 응답 데이터 가져오기
개발자 도구 —> 응답
response.json() 응답 json 데이터 가져오기, 사전 데이터 유형
3. 데이터를 구문 분석하고 원하는 데이터의 내용을 추출합니다.
详情页ID ---> UID
因为得到数据: 字典数据类型
所以解析数据: 键值对取值 ---> 根据冒号左边的内容[键], 提取冒号右边的内容[值]
# for循环遍历, 把列表里面元素一个一个提取出来
for index in response.json()['data']['items']:
# https://love.19lou.com/detail/51593564 format 字符串格式化方法
link = f'https://****.com/detail/{index["uid"]}'
4. 요청을 보내고 URL 주소에 대한 요청을 보내는 브라우저를 시뮬레이트합니다.
https://love.19lou.com/detail/51593564 资料详情页url地址
5. 데이터 가져오기, 서버에서 반환된 응답 데이터 가져오기
웹 페이지 소스 코드
- response.text 응답 텍스트 데이터를 가져오고 문자열 데이터 유형을 반환합니다.
- response.json() 응답 json 데이터 가져오기, 사전 데이터 유형
html_data = requests.get(url=link, headers=headers).text
6. 데이터를 구문 분석하고 원하는 데이터 콘텐츠 추출
기본 정보
css 선택기: 레이블 속성 내용에 따라
데이터 추출 xpath: 레이블 노드
re regular 에 따라 데이터 추출
- 데이터에 해당하는 레이블을 찾습니다.
- 복사를 선택하십시오.
획득한 html 문자열 데이터 <html_data>를 파싱 가능한 객체로 변환
selector = parsel.Selector(html_data)
name = selector.css('.username::text').get()
info_list = selector.css('.info-tag::text').getall()
. 호출 메서드 속성을 나타냅니다.
gender = info_list[0].split(':')[-1]
age = info_list[1].split(':')[-1]
height = info_list[2].split(':')[-1]
date = info_list[-1].split(':')[-1]
info_list 요소의 개수를 판단하여 요소의 개수가 4인 경우 weight에 대한 열이 없음을 의미합니다.
if len(info_list) == 4:
weight = '0kg'
else:
weight = info_list[3].split(':')[-1]
info_list_1 = selector.css('.basic-item span::text').getall()[2:]
zodiac = info_list_1[0].split(':')[-1]
constellation = info_list_1[1].split(':')[-1]
nativePlace = info_list_1[2].split(':')[-1]
location = info_list_1[3].split(':')[-1]
edu = info_list_1[4].split(':')[-1]
maritalStatus = info_list_1[5].split(':')[-1]
job = info_list_1[6].split(':')[-1]
money = info_list_1[7].split(':')[-1]
house = info_list_1[8].split(':')[-1]
car = info_list_1[9].split(':')[-1]
img_url = selector.css('.page .left-detail .abstract .avatar img::attr(src)').get()
7. 사진을 저장하고 사진의 바이너리 데이터를 가져옵니다.
img_content = requests.get(url=img_url, headers=headers).content
with open('data\\' + new_name + '.jpg', mode='wb') as img:
img.write(img_content)
print(dit)
효과
감각적인 Baozi는 시각적 차트를 스스로 만들 수도 있습니다.

마침내
Xiaoyuan은 또한 여기에서 배울 수있는 제로 기반 친구를위한 사례 자습서를 권장합니다. 관심이 있으시면 살펴볼 수 있습니다. 소스 코드가 필요하면 아래 명함을 클릭하여 얻을 수도 있습니다 ~
[Python 사례 교육] Zero-Based Learning, Hands-on Practice에 가장 적합한 실제 사례를 통해 다음 Python 마스터가 될 수 있습니다.
