-
1. Kurze Beschreibung
-
2. Anti-Kletter-Verarbeitung für Schriftarten
-
2.1 Holen Sie sich den Link zur Schriftdatei
-
2.2 Erstellen Sie die Zuordnungsbeziehung zwischen drei Schriftarten und tatsächlichen Zeichen
-
3. Analyse von einseitigen Shopinformationen
-
4. Alle Seitendatenerfassung
-
4.1. Ermitteln Sie die Anzahl der Datenseiten
-
4.2. Sammeln Sie alle Daten
-
5. Zusammenfassung
Der Winter ist eine zum Skifahren geeignete Jahreszeit, aber das Skifahren muss vorsichtig sein. Anfänger sollten beispielsweise nicht auf fortgeschrittene Loipen gehen. Sie müssen ein wenig piepen, wenn Sie Ski fahren können.
Verwenden wir heute Skifahren als Schlüsselwort, um zu demonstrieren, wie mit einem Python-Crawler die Geschäftsinformationen von Dianping erfasst werden.
In den Suchergebnissen können die Seitendaten über request.get () in Form eines Umblätterns abgerufen werden, und dann kann die relevante Analyse der Seitendaten die von uns benötigten Geschäftsinformationen erhalten.
Während des Crawling-Vorgangs werden jedoch Informationen wie die Anzahl der Geschäftsbewertungen, der Pro-Kopf-Verbrauch und die Geschäftsadresse auf der Webseite als □ angezeigt, ähnlich wie & # xf622 in den Get-Daten Ich weiß nicht was es ist. Dies ist eigentlich eine Art Anti-Kletter-Schrift, dann werden wir sie alle brechen.
Die folgenden Datenfelder müssen gesammelt werden:
| Feld |
Beschreibung |
Methode zu erhalten |
Schriftart |
|---|
2. Anti-Kletter-Verarbeitung für Schriftarten
Öffnen Sie Dianping und suchen Sie nach Skifahren. Wir drücken F12 auf der Suchergebnisseite, um den Entwicklermodus aufzurufen. Nachdem Sie die Anzahl der Bewertungen ausgewählt haben, können Sie sehen, dass die Klasse shopNum und der Inhalt □ ist. In den Stilen auf der rechten Seite befinden Sie sich kann sehen, dass die Schriftfamilie PingFangSC-Regular-shopNum ist. Sie können den Link zur Schriftartdatei finden, indem Sie rechts auf den Link .css klicken. In Anbetracht der Tatsache, dass die Links zu Schriftdateien, die anderen Feldern im Zusammenhang mit dem Anti-Climbing von Schriftarten entsprechen, möglicherweise unterschiedlich sind, sammeln wir eine andere Möglichkeit für die einmalige Erfassung (Einzelheiten finden Sie im nächsten Absatz).

2.1 Holen Sie sich den Link zur Schriftdatei
Im Kopfbereich der Webseite finden wir gemischte Grafiken und Text-CSS. Die entsprechende CSS-Adresse enthält alle Links zu Schriftartdateien, die in Zukunft verwendet werden. Sie können direkt die Datei Requess.get () anfordern Ändern Sie die Adresse, um alle Schriftnamen und den Download-Link für die Schriftdatei zurückzugeben.

-Definieren Sie die Funktionsmethode get_html () zum Abrufen von Webseitendaten
# Webseiten-Daten abrufen def get_html (URL, Header): try: rep = request.get (URL, Header = Header) außer Ausnahme als e: print (e) text = rep.text html = re.sub ('\ s' , '', text) #Entfernen Sie Daten, die keine Zeichen sind, und geben Sie HTML zurück
- Holen Sie sich Webseiten-Daten
Importieren Sie Re-Import-Anforderungen # Cookie-Teil, kopieren Sie einfach den Inhalt in die Browser-Header = {"Benutzer-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537.36 (KHTML, wie Gecko) Chrome / 84.0. 4147.89 Safari / 537.36 "," Cookie ":" Ihr Browser-Cookie ",} # Suchschlüsselwort key = 'ski' # grundlegende URL url = f'https: //www.dianping.com/search/keyword/ 2/0_ { Schlüssel} '# Webseiten-Daten abrufen html = get_html (URL, Header)
- Holen Sie sich den Link zur Schriftdatei
# Regulärer Ausdruck, um den Link zur Schriftdatei im Text-Text-CSS im Kopf abzurufen. Text_css = re.findall ('<! --- css -> <linkrel = "stylesheet" type = "text \ / css" href = "(. *?)"> ', html) [0] #' http: //s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/29de4c2bc5d95d1e147c3c25a5f4a the font file link font_html = get_html (css_url, headers) # Ruft die Liste der Schriftinformationen mit dem regulären Ausdruck font_list = re.findall (r '@ font-face {(. *?))', font_html) ab. # Holen Sie sich die verwendeten Schriftarten und ihre Links font_dics = {} für Schriftart in font_list: # Regulärer Ausdruck, um den Namen der Schriftartdatei zu erhalten font_name = re.findall (r'font-family: "PingFangSC-Regular - (. *?)" ', font) [0] # Regulärer Ausdruck, um den entsprechenden Link der Schriftartdatei font_dics [font_name] = 'http:' + re.findall (r ', url \ ("(. *?)" \);', Font) [0] zu erhalten.
- Laden Sie die Schriftdateien auf lokal herunter
# Da wir nur shopNum, tagName und address verwenden, laden wir hier nur diese drei Arten von Schriftarten herunter. Font_use_list = ['shopNum', 'tagName', 'address'] für den Schlüssel in font_use_list: woff = request.get (font_dics [key ], headers = headers) .content mit open (f '{key} .woff', 'wb') als f: f.write (woff)
-
Schriftartdatei (lokal gespeichert, installieren Sie FontCreator, um die Schriftartdatei zu öffnen, den Schriftinhalt anzuzeigen und antworten Sie FontCreator, um die Download-Adresse des Installationspakets zu erhalten)

2.2 Erstellen Sie die Zuordnungsbeziehung zwischen drei Schriftarten und tatsächlichen Zeichen
Schauen wir uns zunächst den HTML-Inhalt der Bewertungsnummer in den angeforderten Webseitendaten wie folgt an:
# </ svgmtsi> </ b> 条 评价
Die entsprechende Webseite zeigt 4576 Bewertungen, und wir wissen, dass die entsprechende Beziehung 4 = & # xf8a1, 5 = & # xee4c, 7 = & # xe103, 6 = & # xe62a ist.
Wir verwenden FontCreator, um die shopNum-Schriftartdatei wie folgt zu öffnen:

Wir können im Vergleich feststellen, dass 4 in shopNum uniF8A1 entspricht und 5 uniEE4C ... usw. entspricht. Nachdem wir die Regel gefunden haben, wissen wir daher, dass die entsprechenden Dateninformationen in den angeforderten Daten, wie z. B. & # xf8a1, tatsächlich uniF8A1 sind. Die tatsächlich entsprechende Nummer oder der entsprechende Text muss einem Zeichen (4) in der Schriftartdatei entsprechen.
Hier müssen Sie die Schriftartverarbeitungsbibliothek fontTools von Drittanbietern von Python einführen, um die Zuordnungsbeziehung der drei Schriftarten zu ändern:
from fontTools.ttLib import TTFont # Ändern Sie die drei Arten der Schriftzuordnungsbeziehung real_list = {} für den Schlüssel in font_use_list: # Öffnen Sie die lokale Schriftartdatei font_data = TTFont (f '{key} .woff') # font_data.saveXML ('shopNum .xml ') # Alle Codes abrufen, die ersten 2 nicht nützlichen Zeichen entfernen uni_list = font_data.getGlyphOrder () [2:] # "" in den Anforderungsdaten und "uniF8A1" im entsprechenden Code, wir werden es ersetzen, und die angeforderten Daten haben Vorrang vor real_list [key] = ['& # x' + uni [3:] für uni in uni_list]
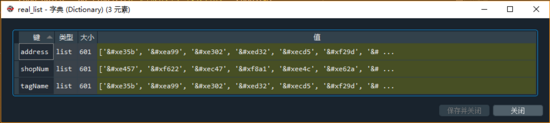
Beim Öffnen dieser drei Arten von Schriftdateien haben wir festgestellt, dass die entsprechende Zeichenfolge dieselbe ist (Reihenfolge und Zeicheninhalt). Kopieren Sie diese wie folgt:
# String words = '1234567890 shop Zhongmeijiaguan trolley Dashigongjiu Linie nationales Produkt Stromerzeugung Jinxinye Shangsi Chaosheng Kleidung Garten Essen hat neue begrenzte Himmel Nudeln Arbeitskleidung Haihua Wasserraum Dekoration Stadt Leqixiang Abteilung Lizi alte Kunst Blumen Spezielle Ost Fleischgerichte, lernen Segen Reis, Menschen hundert Mahlzeiten, Tee Wutongweisuoshan Bergmedizin Yinnonglong Stop Shangan Guangxin Yirongdong Nanguyuanxing frisch Timing geröstet Wenkang Xinguoyangli Topf Baoda Dieryi Spezialität West Niu Jiahua, Präfektur Pifang, 5 Meter, Xiu Aibei, Verkauf von Baumaterialien, Sanhui, Jishihongingang, Shaang Guangangu Gesellschaft, Hexing Cargo-Typ Dorf Jingwu Jingju Juzhuang Shishun Liner County Hand Office verkauft gastfreundliches Feuer Yasheng Sportreiseschuhe würzig für Pulver Paketbau Schulfisch flache Farbe auf der Bar Baoyong alle Dinge zu lehren, Essen und Medizin aufzubauen ist Fengjian Punkt Suppennetz gemacht Qing Jisi Waschmittelverteilungsaustausch Holzkante plus Leinen Weichuantai Farbe Shifang Yufeng junge Schafe blanchiert nach Gaochang Lan Abepi, alle Frauen La Chengyun Wei Handelsstraße Shuyun Dukou Bohe Ruihong Jingji Straße Xiangqing Stadt Küche Peili Huilian Ma Hong Gang Xun Ying Jia Zhu Fenster Bu Fu Pai Tou Si Duo Make-up Ji Yuan Sha Heng Long Chun Qian Bing Shi Li Er Guan Cheng Produktion und Verkauf Jia Chang Xuan Stellvertretender Qing Ji Huang Xun Tai Ya Hao Straßenkreuzung und in Bodennähe neben der gegenüberliegenden Gasse Donghuan Die Innenseite des Xiafu Yuan kaufte das vordere Gebäude und das vordere Gebäude. Das vordere Gebäude ist dem Sitz zugewandt. Jingquantang Fangchang Linie Wanzhengbu Ningjie Baitian Dingxi Achtzehn alte Doppelgewinne dieses Einzel und neun begrüßen die erste Plattform Yujin Am Ende der sieben schrägen Periode, Wuling Songjiao Ji Chaofeng Sechs Zhenzhu Büro Gangzhou Hengbian Jijing Büro Han-Dynastie Linong Tuan Wai Pagode Yang Tiepu Zi Nian Ling Yuan Mei Jin Rong Sie Hong Yang Gui Yan Shi Jin Kailian Ding Xiuliu Ji Lila Flagge Zhang Gu ist nicht gut, es ist auch gut, ich denke nur, dass ich nie am falschen Ort gewesen bin, ich fühle mich zweitrangig, ich habe es gesehen, aber es ist wahr, aber ich mag es am meisten. Zwei Arten von Denkern empfehlen, die Sortierung durchzuführen, die Süße ist voll und die Hitze ist beendet, die Empfehlung lautet, zu trinken, auf ein paar weitere Freunde zu warten, darauf zu warten und es in der Menge zu kaufen, in der ich so wütend bin dass deine Schwester immer versuchen wird, es zu versuchen. Es ist eine vollwertige Garnele, und es ist besser, ein besserer Vertrauter zu sein, aber es ist nicht sauer. Geh zurück zum späten Wei Zhou-Wertetisch, um mit einem Stück Kuchen zu klopfen. '
Wenn wir für Zahlen (tatsächlich gibt es nur 10 in den Top 10 der Schriftartenzuordnung und der Wortfolge) das entsprechende Anti-Kletter-Zeichen als & # xf8a1 erhalten, das eigentlich uniF8A1 ist, finden wir zuerst die entsprechende Position in shopNum und ersetzen Sie dann das Äquivalent. Die Zeichen in der Wortfolge an der Position sind ausreichend.
für i im Bereich (10): s.replace (real_list ['shopNum'] [i], words [i])
Für den chinesischen Zeichentyp (höchstens len (real_list ['tagName'])) ähnelt die Ersetzungslogik dem Zahlentyp. Ersetzen Sie einfach dieselbe Position.
für i im Bereich (len (real_list ['tagName'])): s.replace (real_list ['tagName'] [i], words [i])
3. Analyse von einseitigen Shopinformationen
Durch die Verarbeitung von Anti-Climbing für Schriftarten in Teil 2 in Kombination mit den direkt erhältlichen Geschäftsinformationsfeldern können wir die Analyse und Erfassung aller Geschäftsinformationen abschließen. Hier verwenden wir reguläre Ausdrücke zum Parsen. Interessierte Schüler können auch xpath, bs4 und andere Werkzeugbibliotheken verwenden.
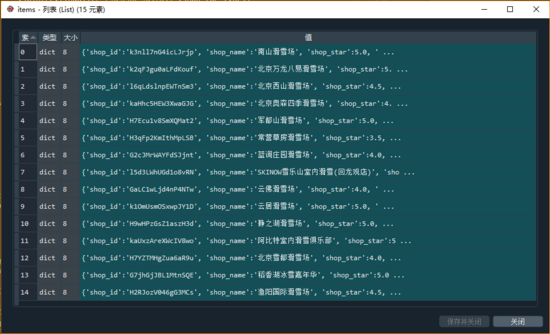
Wir erstellen eine Funktion get_items (html, real_list, words), um alle Geschäftsinformationsdaten auf einer einzigen Seite abzurufen:
# Alle Informationen auf einer einzigen Seite abrufen def get_items (html, real_list, words): # Alle HTML-Informationen aller Shops auf einer einzigen Seite abrufen shop_list = re.findall (r '<divclass = "shop-listJ_shop-listshop- all-list "id =" shop-all-list "> (. *) <\ / div> ', html) [0] # Ruft eine Liste aller Shop-HTML-Informationen auf einer einzelnen Seite ab shop = re.findall (r '<liclass = ""> (. *?) <\ / li>', shop_list) items = [] für Shop in Shops: # Analysieren Sie die Informationen eines einzelnen Shops # shop = shop [0] item = {} # Shop-ID (eindeutig, wird in der Datenbereinigungsphase verwendet Re) item ['shop_id'] = re.findall (r '<divclass = "txt"> <divclass = "tit">. * Data-shopid = "(. * ?) "', shop) [0] # Shopname item [' shop_name '] = re.findall (r' <divclass =" txt "> <divclass =" tit ">. * <h4> (. *) < \ / h4> ', shop) [0] # Shop-Stern, da es sich um eine zweistellige Zahl handelt, muss diese durch 10,0 geteilt und in ein Gleitkommazahlelement umgewandelt werden. [' shop_star '] = re.findall (r '<divclass = "nebula_star"> <divclass = "star_icon"> <spanclass = "starstar _ (\ d +) star_sml"> <\ / span> ', shop) [0] item [' shop_star '] = int (item [' shop_star ']) / 10.0 # Eigentlich In Bezug auf die Shop-Adressinformationen ist die Datenadresse in class = "operiere J_operate Hide" einige # Daher müssen wir die Schriftart nicht zum Umkehren des Crawls verwenden, sondern sie direkt abrufen # shop address item ['shop_address'] = re.findall ('<divclass = "operatorJ_operateHide">. *? data-address = "(. *?)"', shop) [0] shop_name = item ['shop_name'] # Die Anzahl der Bewertungen und der Pro-Kopf-Preis Verwenden Sie shopNum: shop_review = re.findall (r '<b> (. *?) <\ / b> review', shop) [0] außer: print (f '{shop_name} no review data') shop_review = '' try: shop_price = re.findall (pro Kopf <b> ¥ (. *?) <\ / b> ', shop) [0] außer: print (f' {shop_name} Pro-Kopf-Verbrauchsdaten ') shop_price = '' für i in Bereich (10): shop_review = shop_review.replace (real_list ['shopNum '] [i], Wörter [i]) shop_price = shop_price.replace (real_list [' shopNum '] [i], Wörter [i]) # Bewertungsnummer und Pro-Kopf-Preis, nehmen Sie einfach die Nummer und kombinieren Sie den Artikel ['shop_review'] = ''. join (re.findall (r '\ d', shop_review)) item ['shop_price'] = ''. join (re.findall (r '\ d', shop_price)) # Shop-Standort Der Bereich und die Shop-Klassifizierung verwenden tagName shop_tag_site = re.findall (r '<spanclass = "tag">. * data-click-name = "shop_tag_region_click" (. *?) <\ / span>', shop) [ 0] # Shop-Klassifizierung shop_tag_type = re.findall ('<divclass = "tag-addr">. *? <Spanclass = "tag"> (. *?) </ Span> </a>', shop) [0 ] für i in range (len (real_list ['tagName'])): shop_tag_site = shop_tag_site.replace (real_list ['tagName'] [i], words [i]) shop_tag_type = shop_tag_type.replace (real_list ['tagName'] [i],Wörter [i]) # Regulärer Ausdruck, der mit chinesischen Schriftzeichen übereinstimmt: [\ u4e00- \ u9fa5] item ['shop_tag_site'] = ''. join (re.findall (r '[\ u4e00- \ u9fa5]', shop_tag_site)) item ['shop_tag_type'] = ''. join (re.findall (r '[\ u4e00- \ u9fa5]', shop_tag_type)) items.append (item) return items
Im Folgenden finden Sie die Informationsdaten aller Geschäfte auf der Homepage, die wir am Beispiel des Skifahrens erhalten haben:
4. Alle Seitendatenerfassung
In den meisten Fällen bestehen unsere Suchergebnisse aus mehreren Datenseiten. Zusätzlich zum Sammeln einzelner Seitendaten müssen Daten auf allen Seiten abgerufen werden. In diesem Fall ermitteln Sie im Allgemeinen zuerst die Anzahl der Seiten und führen dann einen Seitenwechselzyklus durch, um alle Datenseiten zu crawlen.
4.1. Ermitteln Sie die Anzahl der Datenseiten
Bei Einzelseitendaten gibt es keine Gesamtzahl von Seiten. Bei Mehrseitendaten ziehen wir an den unteren Rand der Seite, wählen das Steuerelement auf der letzten Seite aus, um den HTML-Knoten zu finden, in dem sich der Wert befindet, und verwenden dann "Regular" Ausdrücke, um den Wert zu erhalten.

# 获取 页数 def get_pages (html): try: page_html = re.findall (r '<divclass = "page"> (. *?) </ Div>', html) [0] pages = re.findall (r '<ahref =. *> (\ d +) <\ / a>', page_html) [0] außer: pages = 1 gibt Seiten zurück
4.2. Sammeln Sie alle Daten
Wenn wir die erste Seite der Webseitendaten analysieren, können wir die Anzahl der Datenseiten abrufen, die Anti-Climbing-Schriftart herunterladen, die tatsächliche Zuordnungsbeziehung zwischen real_list und den aus echten Zeichen zusammengesetzten Zeichenfolgenwörtern abrufen. Gleichzeitig erhalten wir auch die Datenzusammensetzung aller Shops auf der ersten Seite. Liste. Dann können wir von der zweiten Seite zur letzten Seite wechseln und die erhaltenen Einzelseitendaten zur ersten Liste hinzufügen.
# Die Liste der Shopdaten auf der ersten Seite shop_data = get_items (html, real_list, words) # Von der zweiten Seite zur letzten Seite für Seite im Bereich (2, Seiten + 1): aim_url = f '{url} / p {page} 'html = get_html (aim_url, headers) items = get_items (html, real_list, words) shop_data.extend (items) print (bereits gecrawlt {page} page data') # konvertiert in den Datenframe-Typ df = pd. DataFrame (shop_data)
Der Datenrahmentyp, der aus allen erfassten Daten besteht, lautet wie folgt:
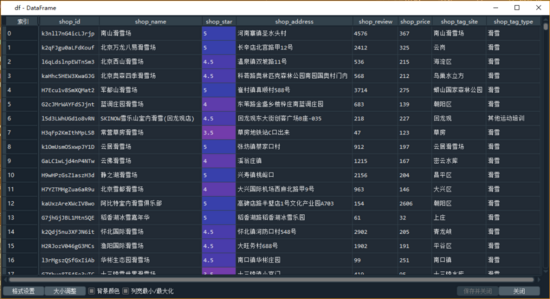
Unter dem Anti-Climbing-Mechanismus des öffentlichen Kommentars und der Schriftart erhalten wir zuerst die Schriftdatei, um die dem Zeichencode entsprechende Beziehung zur Zuordnung der realen Zeichen zu analysieren, und ersetzen dann den Code durch die realen Zeichen.
Tatsächlich können beim tatsächlichen Betrieb von Python, bei dem die Informationen der Dianping-Shops gecrawlt werden, kompliziertere Situationen auftreten, z. B. das Verifizierungscenter zur Überprüfung auffordern oder das IP-Limit des Kontos veranlassen usw. In diesem Fall durch Festlegen von Cookies, Vorgängen B. das Hinzufügen eines IP-Proxys kann verarbeitet werden.
Kürzlich haben sich viele Freunde über Python-Lernprobleme durch private Nachrichten beraten. Um die Kommunikation zu erleichtern, klicken Sie auf das Blau, um an der Diskussion teilzunehmen und die Ressourcenbasis selbst zu beantworten