一个人走得快,一群人走得远……
论文:DeepLabCut: markerless pose estimation of user-defined body parts with deep learning
Github:https://github.com/AlexEMG/DeepLabCut
安装:
pip3 install opencv-python==3.4.5.20
pip3 install deeplabcut
pip3 install matplotlib==3.0.3
pip3 install tables==3.4.3
pip3 install tensorflow-gpu==1.13.1
pip3 install imgaug
pip3 install wxpython
pip3 install ruamel.yaml网络结构:
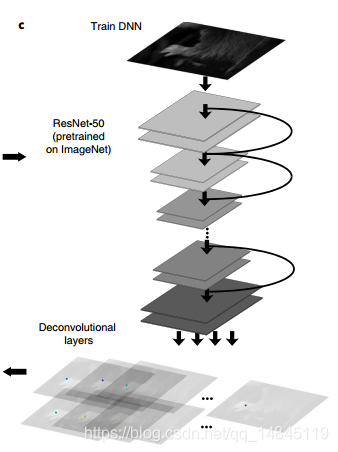
基础网络可以Resnet50,Resnet01,Resnet152,MobileNet_v2_1.0,MobileNet_v2_0.75,MobileNet_v2_0.5,MobileNet_v2_0.35
后续接入了1个反卷积层,对模型进行了1次上采样。其中,基础骨架模型进行了4次下采样,反卷积进行了1次上采样,最终,网络进行了3次下采样。
这里正常的resnet,mobilev2都是进行32倍的下采样,为何这里只进行了16倍呢?
因为作者想要保证16倍的下采样,也就是需要下采样4次,因此修改了原始结构中的第4个stage,将原来的stride = 2换成了stride = 1。最终基础骨架只进行了16倍的下采样。
网络输入为彩色图片,维度为[batch_size, height, width, 3],输出为2部分,预测特征图part_pred,维度为[batch_size, height/8, width/8, num_joints],预测特征图的微调,或者说,偏移locref,包含x,y的偏移,所以得乘以2,维度为[batch_size, height/8, width/8, num_joints * 2],其中,num_joints表示预测的点的个数,一个channel预测一个点。
损失函数:
因为网络最终有2个分支,所以这2个分支都需要进行loss的计算。特征图part_pred分支的损失函数是sigmoid_cross_entropy,偏移locref的损失函数是huber_loss或者MSE loss。
huber_loss,类似于smooth_L1,唯一的区别在于多了一个参数k。
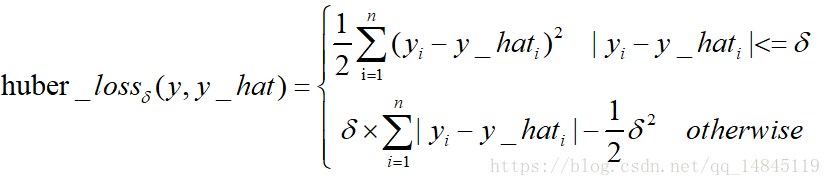
def huber_loss(labels, predictions, weight=1.0, k=1.0, scope=None):
"""Define a huber loss https://en.wikipedia.org/wiki/Huber_loss
tensor: tensor to regularize.
k: value of k in the huber loss
scope: Optional scope for op_scope.
Huber loss:
f(x) = if |x| <= k:
0.5 * x^2
else:
k * |x| - 0.5 * k^2
Returns:
the L1 loss op.
http://concise-bio.readthedocs.io/en/latest/_modules/concise/tf_helper.html
"""
with ops.name_scope(scope, "absolute_difference",
[predictions, labels]) as scope:
predictions.get_shape().assert_is_compatible_with(labels.get_shape())
if weight is None:
raise ValueError("`weight` cannot be None")
predictions = math_ops.to_float(predictions)
labels = math_ops.to_float(labels)
diff = math_ops.subtract(predictions, labels)
abs_diff = tf.abs(diff)
losses = tf.where(abs_diff < k,
0.5 * tf.square(diff),
k * abs_diff - 0.5 * k ** 2)
return TF.losses.compute_weighted_loss(losses, weight)
整体的loss为part_pred和locref的加权组合,
Total loss = part_pred loss +locref_loss_weight * locref loss
训练(train.py):
import deeplabcut
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6"
config_path = r'DeepLabCut\www\config.yaml'
deeplabcut.launch_dlc()
deeplabcut.create_new_project(www,'59', [r'DeepLabCut\www.mp4'], working_directory= r'DeepLabCut',copy_videos=True)
deeplabcut.extract_frames(config_path,'automatic','kmeans', crop=False)
deeplabcut.label_frames(config_path)
deeplabcut.check_labels(config_path)
deeplabcut.create_training_dataset(config_path,num_shuffles=1)
deeplabcut.train_network(config_path,shuffle=1)
deeplabcut.evaluate_network(config_path,[1], plotting=True)#保存结果图片
deeplabcut.analyze_videos(config_path,['DeepLabCut/videos/'], videotype='.mp4', save_as_csv=True)#保存csv,h5
deeplabcut.filterpredictions(config_path,['DeepLabCut/videos/tou.mp4'], shuffle=1)#保存csv,h5,并进行过滤
deeplabcut.create_labeled_video(config_path, ['DeepLabCut/videos/tou.mp4','DeepLabCut/videos/tou1.mp4'],filtered=True)#保存视频
deeplabcut.plot_trajectories(config_path,['DeepLabCut/videos/tou.mp4'],filtered=True)#得到曲线图
deeplabcut.extract_outlier_frames(config_path,['DeepLabCut/videos/tou.mp4'])
deeplabcut.refine_labels(config_path)
测试(test.py):
import cv2
import functools
import numpy as np
import tensorflow as tf
import tensorflow.contrib.slim as slim
import time
import sys
sys.path.append('DeepLabCut')
import mobilenet_v2, mobilenet, conv_blocks
from tensorflow.contrib.slim.nets import resnet_v1
vers = (tf.__version__).split('.')
if int(vers[0])==1 and int(vers[1])>12:
TF=tf.compat.v1
else:
TF=tf
def wrapper(func, *args, **kwargs):
partial_func = functools.partial(func, *args, **kwargs)
functools.update_wrapper(partial_func, func)
return partial_func
networks = {
'mobilenet_v2_1.0': (
mobilenet_v2.mobilenet_base,
mobilenet_v2.training_scope,
),
'mobilenet_v2_0.75': (
wrapper(mobilenet_v2.mobilenet_base,
depth_multiplier=0.75,
finegrain_classification_mode=True),
mobilenet_v2.training_scope,
),
'mobilenet_v2_0.5': (
wrapper(mobilenet_v2.mobilenet_base,
depth_multiplier=0.5,
finegrain_classification_mode=True),
mobilenet_v2.training_scope,
),
'mobilenet_v2_0.35': (
wrapper(mobilenet_v2.mobilenet_base,
depth_multiplier=0.35,
finegrain_classification_mode=True),
mobilenet_v2.training_scope,
),
'resnet_50': (resnet_v1.resnet_v1_50,resnet_v1.resnet_arg_scope()),
'resnet_101': (resnet_v1.resnet_v1_101,resnet_v1.resnet_arg_scope()),
'resnet_152': (resnet_v1.resnet_v1_152,resnet_v1.resnet_arg_scope())
}
class PoseNet(object):
def __init__(self):
self.scale = 0.4#0.8
self.batch_size = 1
self.location_refinement = True
self.init_weights = r"/models/snapshot-360000"
self.locref_stdev = 7.2801
self.stride = 8.0
self.net_type = 'resnet_50'#'mobilenet_v2_1.0'#
self.mean_pixel = [123.68, 116.779, 103.939]
self.weight_decay = 0.0001
self.num_joints = 17
self.graph_interface = True
self.intermediate_supervision = False
self.intermediate_supervision_layer = "12"
if self.graph_interface == True:
self.sess, self.inputs, self.outputs = self.setup_pose_prediction_graph()
#update the true graph
#self.restorer.save(self.sess, "./20w/20w", global_step=200000)
else:
self.sess, self.inputs, self.outputs = self.setup_pose_prediction()
self.POSE_COLORS = [(255, 0, 85), \
(255, 0, 0), \
(255, 85, 0), \
(255, 170, 0), \
(255, 255, 0), \
(170, 255, 0), \
(85, 255, 0), \
(0, 255, 0), \
(0, 255, 85), \
(0, 255, 170), \
(0, 255, 255), \
(0, 170, 255), \
(0, 85, 255), \
(0, 0, 255), \
(255, 0, 170), \
(170, 0, 255), \
(255, 0, 255)]
self.POSE_LINES = [(0,1), \
(1,2), \
(2,3), \
(3,4), \
(4,5), \
(5,6), \
(6,7), \
(7,8), \
(6,9), \
(9,10), \
(11,12), \
(12,13), \
(14,15), \
(15,16), \
(0,11), \
(0,14)]
#def __del__(self):
# self.sess.close()
def process(self,image):
if self.graph_interface == True:
pose ,qulv, cov= self.infer_graph(image)
else:
pose ,qulv, cov= self.infer(image)
return pose ,qulv, cov
def infer(self,image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image -np.ones_like(image)*self.mean_pixel
if self.scale!=1:
image =cv2.resize(image,(int(image.shape[1]*self.scale),int(image.shape[0]*self.scale)),interpolation=cv2.INTER_AREA)
image_batch = np.expand_dims(image, axis=0).astype(float)#(batch,height,width,3)
outputs_np = self.sess.run(self.outputs, feed_dict={self.inputs: image_batch})
scmap, locref = self.extract_cnn_output(outputs_np)#scmap:(height/8,width/8,4) locref:(height/8,width/8,4,2)
print("image_batch",image_batch.shape,"scmap",scmap.shape,"locref",locref.shape)
pose = self.argmax_pose_predict(scmap, locref)
pose[:,:-1]=pose[:,:-1]/self.scale
#print(np.asarray(pose[2:7,:-1]))
qulv, cov = self.compute_curvature_cov(np.asarray(pose[2:7,:-1]))
return pose ,qulv, cov
def infer_graph(self,image):
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image -np.ones_like(image)*self.mean_pixel
if self.scale!=1:
image =cv2.resize(image,(int(image.shape[1]*self.scale),int(image.shape[0]*self.scale)),interpolation=cv2.INTER_AREA)
image_batch = np.expand_dims(image, axis=0).astype(float)#(batch,height,width,3)
pose = self.sess.run(self.outputs, feed_dict={self.inputs: image_batch})
#print(pose)
pose[:,:-1]=pose[:,:-1]/self.scale
#print(np.asarray(pose[2:7,:-1]))
qulv, cov = self.compute_curvature_cov(np.asarray(pose[0:4,:-1]))
return pose ,qulv, cov
def prediction_layer(self, input, name, num_outputs):
with slim.arg_scope([slim.conv2d, slim.conv2d_transpose], padding='SAME',
activation_fn=None, normalizer_fn=None,
weights_regularizer=slim.l2_regularizer(self.weight_decay)):
with tf.variable_scope(name):
pred = slim.conv2d_transpose(input, num_outputs,
kernel_size=[3, 3], stride=2,
scope='block4')
return pred
def get_net(self, inputs):
out = {}
net_fun, net_arg_scope = networks[self.net_type]
if self.net_type == 'resnet_50' or self.net_type == 'resnet_101' or self.net_type == 'resnet_152':
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
net, end_points = net_fun(inputs,
global_pool=False, output_stride=16,is_training=False)
else:
with slim.arg_scope(net_arg_scope()):
net, end_points = net_fun(inputs)
with tf.variable_scope('pose', reuse=False):
out['part_pred'] = tf.sigmoid(self.prediction_layer(net, 'part_pred',self.num_joints))
if self.location_refinement:
out['locref'] = self.prediction_layer(net, 'locref_pred',self.num_joints * 2)
if self.intermediate_supervision:
#print(end_points.keys()) >> to see what else is available.
out['part_pred_interm'] = self.prediction_layer(end_points['layer_'+self.intermediate_supervision_layer],
'intermediate_supervision',
self.num_joints)
#print("out['part_pred']",out['part_pred'],"out['locref']",out['locref'])
return out
def get_net_graph(self,inputs):
''' Direct TF inference on GPU. Added with: https://arxiv.org/abs/1909.11229'''
heads = self.get_net(inputs)
with tf.variable_scope('post_process', reuse=False):
locref= tf.transpose(heads['locref'],(0,2,1,3))
probs = tf.transpose(heads['part_pred'],(0,2,1,3))
probs = tf.squeeze(probs, axis=0)
locref = tf.squeeze(locref, axis=0)
l_shape = tf.shape(probs)
locref = tf.reshape(locref, (l_shape[0]*l_shape[1], -1, 2))
probs = tf.reshape(probs , (l_shape[0]*l_shape[1], -1))
maxloc = tf.argmax(probs, axis=0)
loc = tf.reshape(tf.concat([tf.cast(maxloc/tf.cast(l_shape[1], tf.int64), tf.int64),maxloc - tf.cast(l_shape[1], tf.int64)*(tf.cast(maxloc/tf.cast(l_shape[1], tf.int64), tf.int64))],0),(2,-1))
#loc = tf.unravel_index(maxloc, (tf.cast(l_shape[0], tf.int64) ,tf.cast(l_shape[1], tf.int64)))
maxloc = tf.reshape(maxloc, (1, -1))
joints = tf.reshape(tf.range(0, tf.cast(l_shape[2], dtype=tf.int64)), (1,-1))
indices = tf.transpose(tf.concat([maxloc,joints] , axis=0))
offset = tf.gather_nd(locref, indices)
offset = tf.gather(offset, [1,0], axis=1)
#likelihood = tf.reshape(tf.gather_nd(probs, indices), (-1,1))
likelihood = tf.reshape(tf.reduce_max(probs, axis=0), (-1,1))
pose = self.stride*tf.cast(tf.transpose(loc), dtype=tf.float32) + self.stride*0.5 + offset*self.locref_stdev
pose = tf.concat([pose, likelihood], axis=1)
#print("xxxxx",pose)
return {'pose': pose}
def setup_pose_prediction_graph(self):
TF.reset_default_graph()
#inputs = TF.placeholder(tf.float32, shape=[self.batch_size, 720*0.4, 1280*0.4, 3])
inputs = TF.placeholder(tf.float32, shape=[self.batch_size, None, None, 3])
pose = self.get_net_graph(inputs)
outputs = pose['pose']
self.restorer = TF.train.Saver()
sess = TF.Session()
sess.run(TF.global_variables_initializer())
sess.run(TF.local_variables_initializer())
# Restore variables from disk.
self.restorer.restore(sess, self.init_weights)
return sess, inputs, outputs
def setup_pose_prediction(self):
TF.reset_default_graph()
inputs = TF.placeholder(tf.float32, shape=[self.batch_size, None, None, 3])
net_heads = self.get_net(inputs)
outputs = [net_heads['part_pred']]
if self.location_refinement:
outputs.append(net_heads['locref'])
self.restorer = TF.train.Saver()
sess = TF.Session()
sess.run(TF.global_variables_initializer())
sess.run(TF.local_variables_initializer())
# Restore variables from disk.
self.restorer.restore(sess, self.init_weights)
return sess, inputs, outputs
def extract_cnn_output(self, outputs_np):
''' extract locref + scmap from network '''
scmap = outputs_np[0]
scmap = np.squeeze(scmap)
locref = None
if self.location_refinement:
locref = np.squeeze(outputs_np[1])
shape = locref.shape
locref = np.reshape(locref, (shape[0], shape[1], -1, 2))
locref *= self.locref_stdev
if len(scmap.shape) == 2: # for single body part!
scmap = np.expand_dims(scmap, axis=2)
return scmap, locref
def argmax_pose_predict(self, scmap, offmat):
"""Combine scoremat and offsets to the final pose."""
num_joints = scmap.shape[2]
pose = []
for joint_idx in range(num_joints):
maxloc = np.unravel_index(np.argmax(scmap[:, :, joint_idx]),
scmap[:, :, joint_idx].shape)
offset = np.array(offmat[maxloc][joint_idx])[::-1]
pos_f8 = (np.array(maxloc).astype('float') * self.stride + 0.5 * self.stride +
offset)
pose.append(np.hstack((pos_f8[::-1],
[scmap[maxloc][joint_idx]])))
return np.array(pose)
def draw_results(self,image,pose ,qulv, cov):
for num,point in enumerate(self.POSE_LINES):
cv2.line(image, (int(pose[self.POSE_LINES[num][0]][0]),int(pose[self.POSE_LINES[num][0]][1])),(int(pose[self.POSE_LINES[num][1]][0]),int(pose[self.POSE_LINES[num][1]][1])), self.POSE_COLORS[num],4, 0)
for num,point in enumerate(pose):
cv2.circle(image, (int(point[0]),int(point[1])),12, self.POSE_COLORS[num],-1, 0)
font = cv2.FONT_HERSHEY_SIMPLEX
image = cv2.putText(image, 'qulv:{} cov:{}'.format(qulv,cov), (int(pose[6][0]), int(pose[6][1])), font, 0.8, (128, 128, 0), 2)
return image
def compute_curvature_cov(self, input_numpy):
#曲率越大,越弯曲
# |y''|
#k= -----------
# 3/2
# (1+y'2)
#y’(i) = (y(i+1)-y(i))/h
#y’’(i) = (y(i+1)+y(i-1)-2*y(i))/h^2
#双线性插值
chazhi_ratio = 10#每2个点之间插值10个点
input_list = []
#print(input_numpy.shape)
for i in range(input_numpy.shape[0]-1):
k = (input_numpy[i+1,1]-input_numpy[i,1])/(input_numpy[i+1,0]-input_numpy[i,0])
b = input_numpy[i+1,1]-k*input_numpy[i+1,0]
line_space = (input_numpy[i+1,0]-input_numpy[i,0])/chazhi_ratio
for d in list(range(chazhi_ratio)):
input_list.append(k * (input_numpy[i,0]+d)+b )
input_numpy = np.asarray(input_list)
input_numpy_yijie = (input_numpy[1:]-input_numpy[:-1])/1.0
input_numpy_yijie = input_numpy_yijie[:-1]
input_numpy_erjie = (input_numpy[2:]+input_numpy[:-2]-2*input_numpy[1:-1])/(1.0*1.0)
#print(input_numpy_yijie.shape,input_numpy_erjie.shape)
K = np.abs(input_numpy_erjie) /np.power((np.ones_like(input_numpy_yijie)+input_numpy_yijie*input_numpy_yijie),3.0/2.0)
mean = np.mean(np.asarray(input_numpy))
std = np.std(np.asarray(input_numpy))
cov = std/mean
return round(np.mean(K),3) ,round(cov,3)
def test_image():
posenet = PoseNet()
image = cv2.imread(r"img068734.png")
pose ,qulv, cov= posenet.process(image)
print(pose)
image = posenet.draw_results(image, pose ,qulv, cov)
cv2.imshow("aa",image)
cv2.waitKey()
def test_video():
posenet = PoseNet()
cap=cv2.VideoCapture("../t.mp4")
while (True):
ret,image=cap.read()
if ret == True:
time_start=time.time()
pose ,qulv, cov= posenet.process(image)
print('totally cost{} s'.format(time.time()-time_start))
#print(pose)
image = posenet.draw_results(image,pose ,qulv, cov)
cv2.imshow("video",image)
cv2.waitKey(1)
# 在播放每一帧时,使用cv2.waitKey()设置适当的持续时间。如果设置的太低视频就会播放的非常快,如果设置的太高就会播放的很慢。通常情况下25ms就ok
if 0xFF==ord('q'):
break
else:
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
#test_image()
test_video()实验结果:
总结:
DeepLabCut一个基于关键点的检测网络。可以用于人体,动物的姿势估计。
优点,需要的打标数据少,训练速度很快,效果惊人的好,支持任意多个点。
缺点,测试的时候,只能进行单个目标的检测,对于多个目标也可以检测出关键点,但是点和点之间的连接问题,就没法解决,这点不像openpose这种自底向上更好。当然训练的时候,也可以进行多个目标的关键点的打标,而且这样做还有助于提高训练精度。
