什么是redis
本质上来讲,redis就是一款数据库,用于存储我们程序中的数据,它属于nosql数据库的一种(即运行在内存中的数据库),在我们常见的关系型数据库(如MySQL)使用中,一旦出现上千并发量的情况,由于磁盘读写速度的限制,无法在极短时间内完成大量读写,数据库非常容易瘫痪,导致服务宕机。为了解决这个问题,非关系型数据库应运而生,nosql数据库直接运行在内存中,可以支持每秒十几万次的读写操作,因此被广泛应用在缓存,在高并发量的读写操作结束后一次性将数据写入关系型数据库,并且支持集群、分布式等配置,原则上可以做到无线扩展。
redis特点
- redis支持丰富的数据类型(list、hash、set等)
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- 支持集群
- 支持事务
- 支持主从分布,哨兵监控
- 单进程模式
为什么要使用redis
我们从高性能与高并发两方面来研究这个问题
高性能
redis运行在内存中,通过电流完成读写操作,每秒可完成十几万次读写操作,而关系型数据库则将数据存储在磁盘,通过机械来完成读写,从速度上来讲差了成百上千倍。程序与redis的缓存数据交互会大大提升程序性能,redis只需要在关系型数据变化时做一下同步就好。
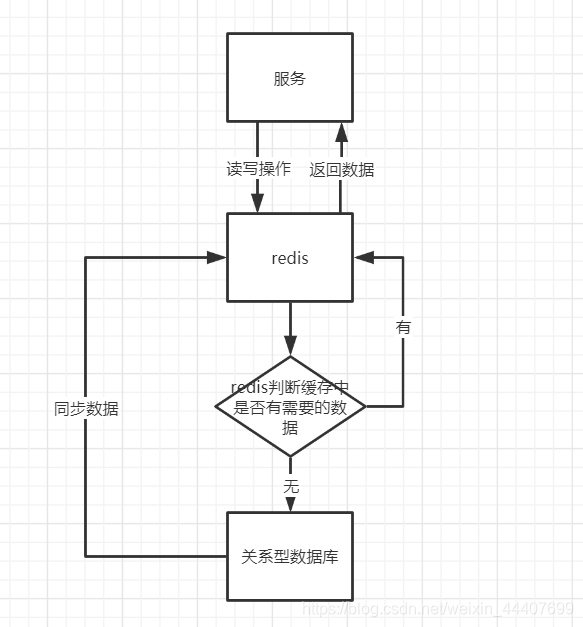
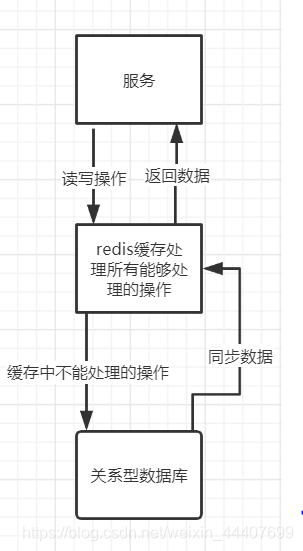
高并发
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
redis的基本数据类型
1.String
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。 常规key-value缓存应用;
2.Hash
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。
3.list
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
4.set
set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
5.sorted set
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列
