这篇文章是基于内部分享的逐字稿内容整理的,现在比较喜欢写逐字稿,方便整理成文章。
文章目录
好,那我们开始。
两周前 HG 分享了 QQ 空间的热修复框架,今天我来简单讲一下微信开源的热修复框架,Tinker。
-
目录
-
特点介绍
-
使用
-
patch 加载,分别讲下 dex resources 和 so
-
patch 的产生和合并
目录
讲的内容主要分为以下几节:
- 第一节: 特点介绍,简单介绍一下 Tinker 和其他热门框架对比的优点。
- 第二节:通过官方提供的 sample 了解 Tinker 的使用和基础 API
- 知道怎么用以后,我们再一起探究一下背后的原理
- 第三节:了解下运行时 Tinker 是如何加载补丁的,分为 dex,资源和 so 库
- 第四节:了解一下 patch 的格式和如何做 diff,以及运行时如何合成
- 时间够的话简单讲下 gradle plugin
- 第五节:总结
这次分析基于的是目前最新的
1.9.14.3版本
ok 我们首先来了解一下 Tinker。
Tinker 介绍
Tinker 是微信开源的热修复框架,Github 主页在 https://github.com/Tencent/tinker/wiki。
我们看下 Tinker 和其他热门框架的对比图:
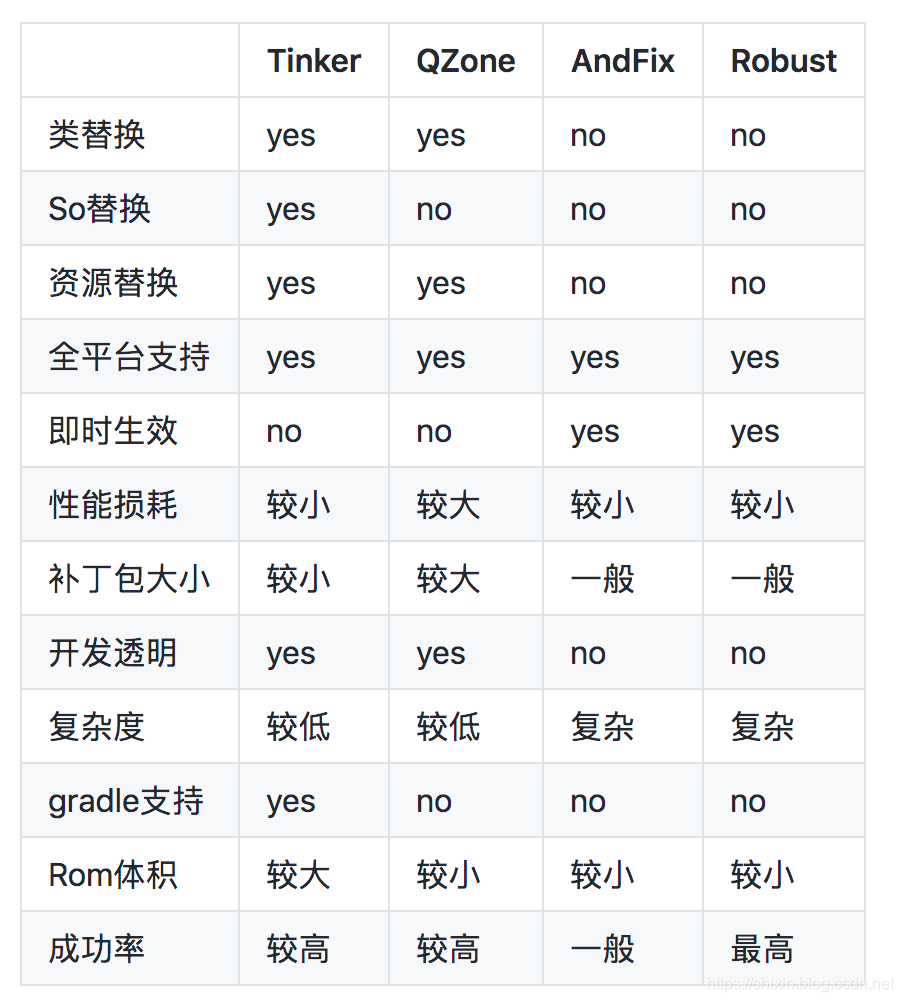
可以看到,Tinker 的特点是:
- 支持类替换、So 替换,资源替换是采用类似 instant-run 的方案
- 补丁包较小,自研 diff 方案,下发的是差量包,包括的是变更的内容
- 支持 gradle,提供了 gradle-plugin,允许我们配置很多内容
- 采用全量 Dex 更新,不需要额外处理
CLASS_ISPREVERIFIED问题
CLASS_ISPREVERIFIED问题大家可能也知道,如果 A 类引用的类都在一个 dex 里,就会被打上preverified,后面如果有引用其他 dex 的类,就会报错。(这句可以不说:这种情况只发生在 Dalvik 虚拟机上)QZone 采用的方案通过字节码插桩让可能被修复的类都不打上这个标志,会导致有性能影响。Tinker 在合并 dex 时,会创建一个新的几乎完整的 dex,从而规避了这个问题。
具体细节等下讲原理的时候说。
Tinker 还有一个优点就是一直在维护中,迭代更新还比较快。
缺点主要就是不支持即时生效。因为是在 Java 层做修复,而不是 native 层。
ok,简单了解了 Tinker 的特点后,我们来看下 Tinker 的使用。
使用
- gradle 配置
- 核心类介绍
TinkerApplicaitionApplicationLikeTinkerLoaderPatchListenerTinkerResultServiceReporter
这里使用的是官方提供的 sample,我们来看下接入 Tinker 需要做哪些。
(打开 tinker-sample-android)
首先打开根目录的 `build.gradle,可以看到,这里依赖了tinker-patch-gradle-plugin``:
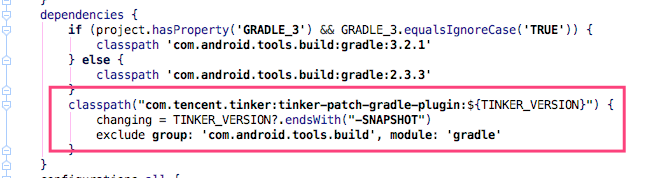
这个插件主要做的是提供了五个核心 Task,在编译期间对资源和代码做一些额外处理
接着打开 app 目录下的 build.gradle 文件,可以看到对 tinker 的依赖有三个:
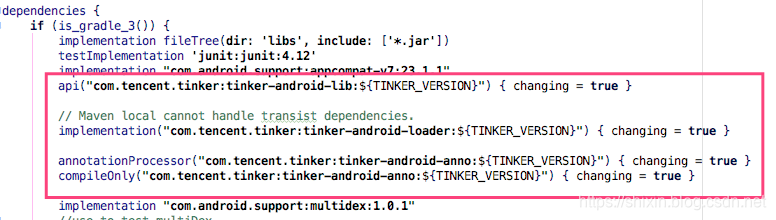
tinker-android-lib,这个主要是提供对外暴露的 API,等下使用到的 Tinker API 基本都在这个工程下tinker-android-loader,这个工程主要是完成 patch 的加载,稍后讲解 patch 加载原理时主要讲的就是这个工程tinker-android-anno,这个工程很简单,就是一个注解处理器,作用就是帮助我们生成一个Applicaition,可以看下它的代码(读取注解的信息,根据模板信息生成一个类)
添加了依赖后,还需要添加一些配置信息,我们继续看 build.gradle。
首先看到 ext 拓展属性里定义了几个属性,
def bakPath = file("${buildDir}/bakApk/")
/**
* you can use assembleRelease to build you base apk
* use tinkerPatchRelease -POLD_APK= -PAPPLY_MAPPING= -PAPPLY_RESOURCE= to build patch
* add apk from the build/bakApk
*/
ext {
//for some reason, you may want to ignore tinkerBuild, such as instant run debug build?
tinkerEnabled = true
//for normal build
//old apk file to build patch apk
tinkerOldApkPath = "${bakPath}/app-debug-0424-15-02-56.apk"
//proguard mapping file to build patch apk
tinkerApplyMappingPath = "${bakPath}/app-debug-1018-17-32-47-mapping.txt"
//resource R.txt to build patch apk, must input if there is resource changed
tinkerApplyResourcePath = "${bakPath}/app-debug-0424-15-02-56-R.txt"
//only use for build all flavor, if not, just ignore this field
tinkerBuildFlavorDirectory = "${bakPath}/app-1018-17-32-47"
}
tinkerEnabled和名字一样表示使用启用 tinkertinkerOldApkPath表示基准包的位置,这里的bakPath就是app/build/bakApk目录tinkerApplyMappingPath表示基准包使用混淆时的 mapping 文件所在路径,在做差量包时需要使用这个 mappingtinkerApplyResourcePath表示资源 R.txt 的路径,这个文件在 build 阶段处理资源processDebugResources时,会生成资源索引等信息输出到这个文件
翻到下面我们可以看到,这里有些一个 task 在编译生成 apk 后会拷贝 apk mapping 和 R.txt 文件到这个 bak 目录下
ok 接下来看一下最关键的 tinker-gradle 配置。
https://github.com/Tencent/tinker/wiki/Tinker-%E6%8E%A5%E5%85%A5%E6%8C%87%E5%8D%97
tinkerPatch 是 tinker 的拓展属性,允许我们对 build 过程做一些自定义。
(简单介绍两个比较重要的配置)
buildConfig里的是编译相关的配置keepDexApply是指开启补丁包根据基准包的类分部进行编译,避免补丁修改很多,导致类所在的 dex 和基准包不一样isProtectedApp是否使用加固模式,这种情况下只将变更的类合成补丁dex是对 dex 里的配置dexMode,输入的 dex 格式,jar 或者 rawpattern需要处理的 dex 路径loader是配置一些不会打入 patch 的类,默认放加载插件相关的类
其他的配置还有很多,这里就不 一一介绍了。
ok 了解了 gradle 文件的配置内容后,我们来看下项目代码。
首先看下 AndroidManifest.xml 文件:
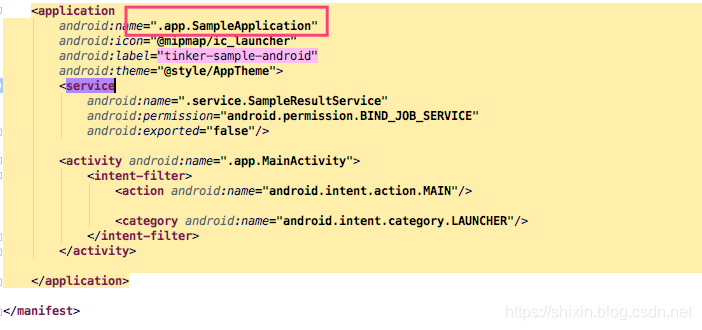
可以看到这个 sample 比较简单,先看下这个 Applicaition,这个类在 build 目录,就是我们前面提到的,通过 注解处理器生成的类。
这个 SampleApplication 继承了 TinkerApplicaitiopn,我们看下代码。
TinkerApplicaition
TinkerApplicaitiopn 需要讲解的点:
- 构造函数参数的意义
tinkerFlags表示要加载的类型,包括 dex , library 还是全部支持delegateClassName表示 Applicaition 代理类的 className,也就是 ApplicaitionLike- 第三个参数
loaderClassName表示 Tinker 加载类的 className,默认是TinkerLoader,我们也可以继承做些修改 - 最后一个参数
tinkerLoadVerifyFlag表示是否需要在加载时检查文件的 md5,默认是 false,因为在合成阶段就做了校验,所以这里一般不需要再校验
- 做了什么,先看
attachBaseContext()
- 反射创建
TinkerLoader,调用TinkerLoader#tryLoad方法加载补丁,具体细节稍后讲解 - 创建桥接类,回调桥接类各个生命周期方法
- 这里我们可以看到,是通过反射创建一个桥接类,在桥接类里又通过反射创建了代理类,原因我们等下讲
SampleApplicaitionLike
ok,我们接下来看一下 sample 里的 Application 代理类 SampleApplicaitionLike,它使用了 @DefaultLifeCycle 注解,参数就是要生成的 Applicaition 全路径,支持类型是全部,加载验证是 false。
SampleApplicaitionLike 继承了 DefaultApplicaitionLike,提供了一些类似 Application 的 API。里面也没有做什么额外处理,只是为了让我们把在 Applicaition 里的代码转移到这里。
为什么要通过这种方式呢?
主要有两个原因:
- 让 Tinker 可以对 Applicaition 初始化时使用到的类进行修复
- 应用 7.0 混合编译对热修复的影响
官方文档里的介绍是这样说的:
程序启动时会加载默认的 Application 类,这导致我们补丁包是无法对它做修改了。
如何规避?
在这里我们并没有使用类似InstantRun hook Application的方式,而是通过代码框架的方式来避免,这也是为了尽量少的去反射,提升框架的兼容性。
这里我们要实现的是完全将原来的Application类隔离起来,即其他任何类都不能再引用我们自己的Application。我们需要做的其实是以下几个工作:
- 将我们自己Application类以及它的继承类的所有代码拷贝到自己的ApplicationLike继承类中,例如SampleApplicationLike。你也可以直接将自己的Application改为继承ApplicationLike;
- Application的attachBaseContext方法实现要单独移动到onBaseContextAttached中;
- 对ApplicationLike中,引用application的地方改成getApplication();
- 对其他引用Application或者它的静态对象与方法的地方,改成引用ApplicationLike的静态对象与方法;
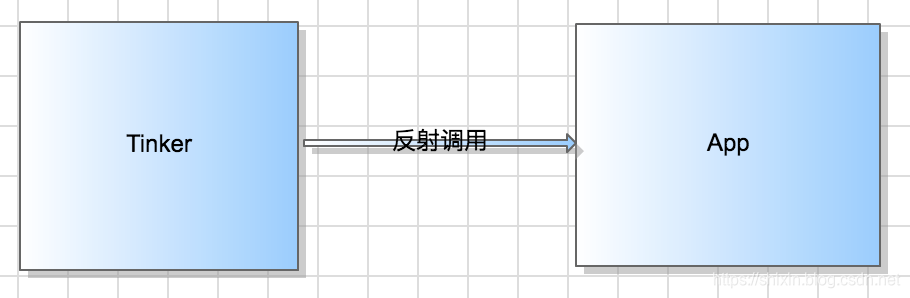
也就是说,通过反射,将Tinker组建和App隔离开,并且先后顺序是先Tinker后App,这样可以防止App中的代码提前加载,确保App中所有的代码都可以具有被热修复的能力包括ApplicationLike。
ok 回到 SampleApplicationLike 中,可以看到在 onBaseContextAttached() 方法中,调用了 TinkerManager#installTinker 进行初始化,然后调用 Tinker#with 初始化 Tinker 实例。
TinkerManager#installTinker 里有创建了一些自定义的监听器,包括 patch 加载监听、patch 验证监听 、收到 patch 的监听等
TinkerInstaller
TinkerInstaller#install 里创建了 Tinker 类,调用了 install 方法。
TinkerInstaller#onReceiveUpgradePatch 方法,在接收到新的 patch 后我们调用这个方法,传入路径,然后会进行 patch 的合成,我们稍后介绍。
还有其他监听类我们就不一一介绍了。
PatchListenerTinkerResultServiceReporter
OK,那我们接下来把项目运行起来看看效果。
有提供脚本 push 到设备
总结
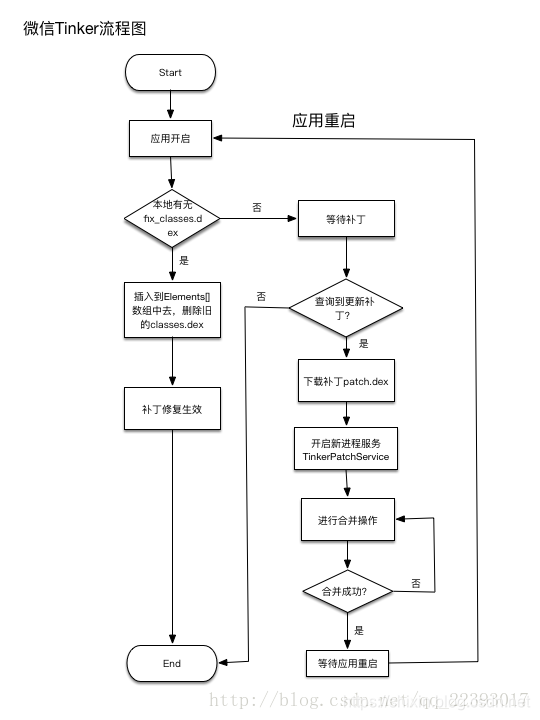
Tinker流程图
ok,了解了 Tinker 的基本使用后,我们来看下背后的原理。
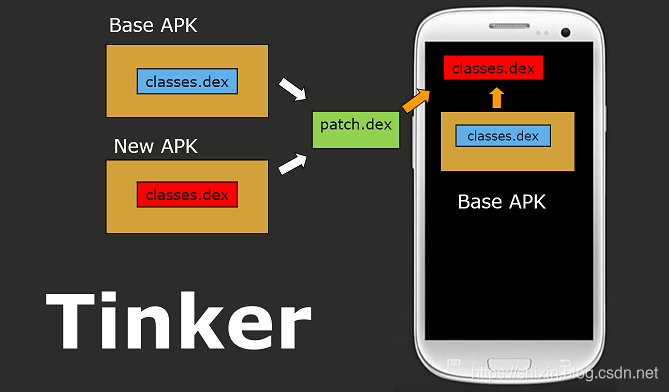
tinker.png
这张图来自 Tinker Github。
Tinker 将 old.apk 和 new.apk 做了 diff,生成一个 patch.dex,然后下发到手机,将 patch.dex 和本机 apk 中的 classes.dex 做了合并,生成新的 classes.dex,然后加载。
首先看下 Tinker 加载补丁的代码。因相交于生成,这部分更简单些。
运行时 Tinker 是如何加载补丁
前面我们在介绍生成的 Application 时就提到,TinkerApplication#attachBaseContext 中辗转会调用到 loadTinker()方法,在该方法内部,反射调用了 TinkerLoader#tryLoad 方法加载 patch。
TinkerLoader 相关的代码在 tinker-android-loader:
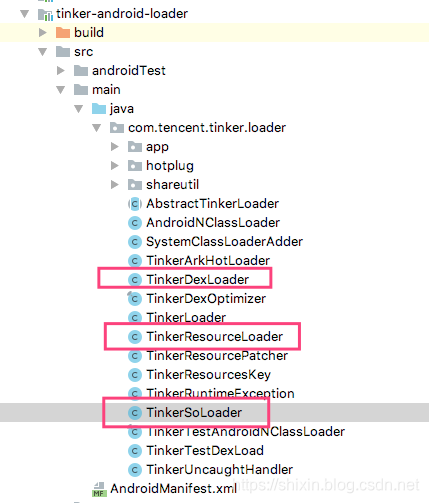
看下加载相关的类图。TinkerLoader 是加载对外暴露的 API,它内部调用了 TinkerDexLoader, TinkerResourceLoader 和 TinkerSoLoader 分别用于加载 dex 资源和 so。
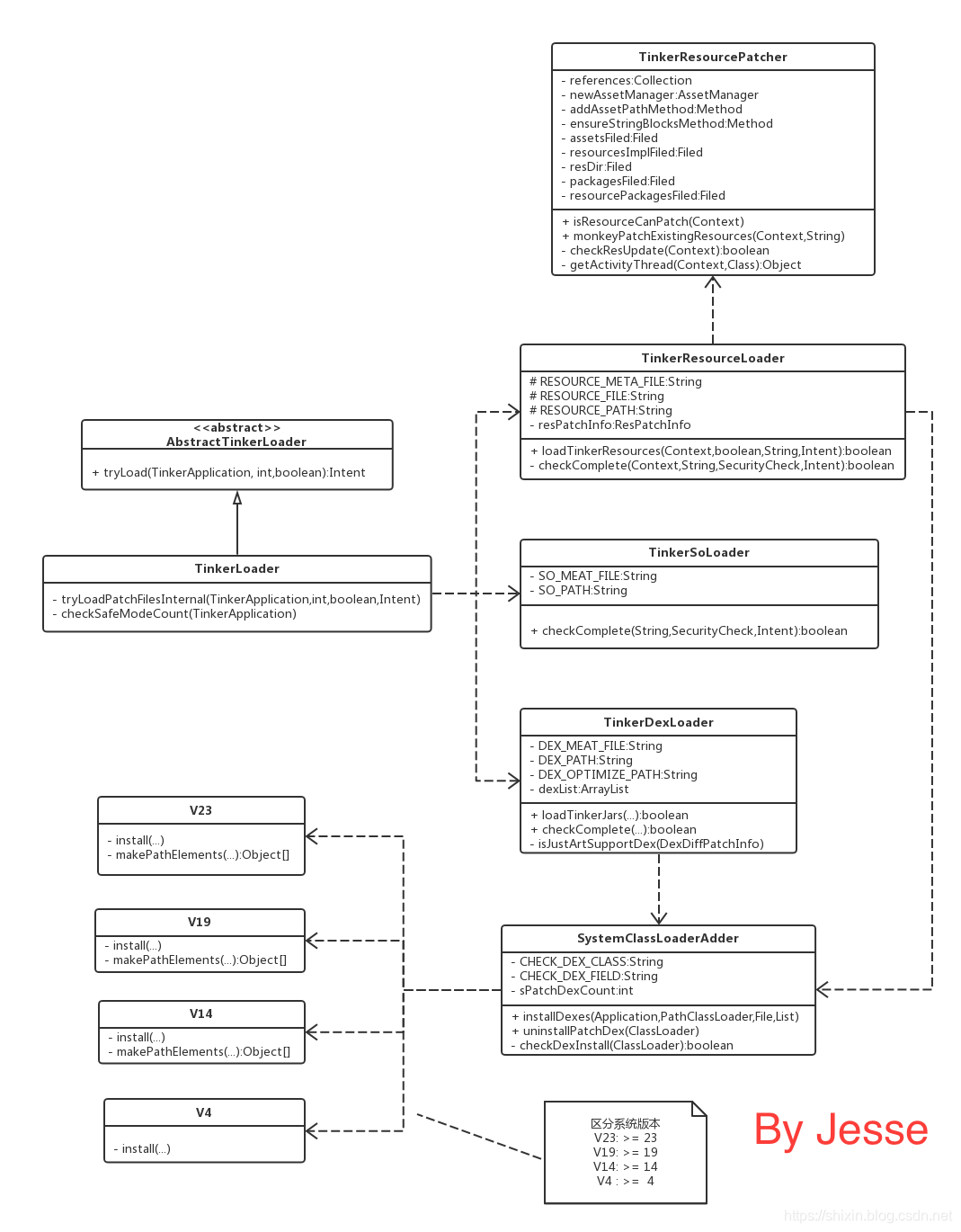
我们看下代码, TinkerLoader#tryLoad ,它调用了 TinkerLoader#trylLoadPatchFilesInternal ,这个方法内容很多,主要做了两件事:
- 会判断补丁是否存在,检查补丁信息中的数据是否有效,校验补丁签名以及tinkerId与基准包是否一致。在校验签名时,为了加速校验速度,Tinker只校验 *_meta.txt文件,然后再根据meta文件中的md5校验其他文件
- 根据开发者配置的Tinker可补丁类型判断是否可以加载dex,res,so。然后分别分发给TinkerDexLoader、TinkerSoLoader、TinkerResourceLoader分别进行校验是否符合加载条件进而进行加载
很多校验我们就不细看了。主要看下对 TinkerDexLoader, TinkerResourceLoader 和 TinkerSoLoader 的调用。
TinkerLoader里搜TinkerDexLoader
首先看下 TinkerDexLoader 是如何校验、加载的 dex。
加载 dex
TinkerDexLoader 的两个方法:
TinkerDexLoader#checkComplete检查 dex 补丁文件和优化过的 odex 文件是否可以加载TinkerDexLoader#loadTinkerJar把补丁 dex 插入到 ClassLoader 里
我们重点看下 TinkerDexLoader#loadTinkerJar。
选中
classloader变量
前面都是做一些校验和 OTA 的处理,直接看方法的最后,调用了 SystemClassLoaderAdder#installDexes 这个核心方法。
点进去看一下,可以看到,它区分不同版本做了不同的处理。
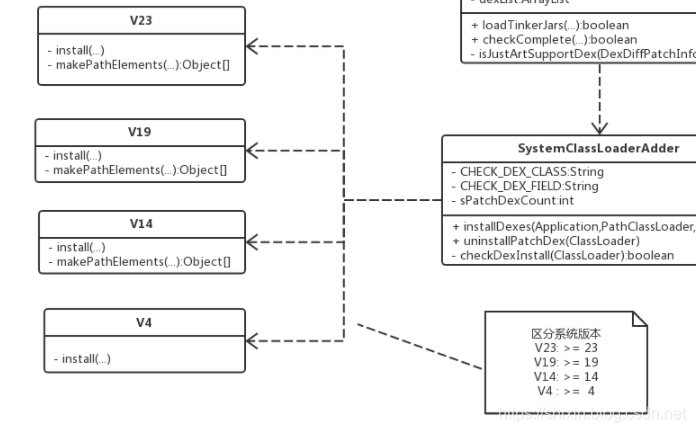
我们重点看下 19 和 24 的处理。
- V19
- 找到 classLoader.pathList
- 然后调用
makeDexElements创建新的 Element[] 数组 - 然后调用
ShareReflectUtil#expandFieldArray插入,重点看下这个方法 - 创建一个新的数组,把 patch 相关的 dex 放在前面,然后将合并后的数组设置给 pathList
- V23
- 和 19 的区别在于
makeDexElements->makePathElements,方法的名称、参数做了调整 - V24 (7.0)的特殊点在于
- 为每个 patch 创建了一个新的
AndroidNClassLoader - 这是由于安卓 7.0 支持混合编译 ,混合编译对热修复的影响
简单了解下混合编译。
混合编译与热修复
- 为什么有混合编译
- 混合编译对热修复的影响
- 如何解决
我们知道:
- Dalvik 虚拟机,运行时通过 JIT 把字节码编译成机器码再执行,运行时速度比较慢
- ART 虚拟机上,改为 AOT 提前编译 ,即在安装应用或者 OTA 系统升级的时候把字节码翻译 成 机器码,这样运行时就可以直接执行了
- 但 ART 的缺点是,可能会导致安装时间过长,而且全量编译占用的 ROM 空间更大
所以在 Android N 上提出了混合编译,AOT 编译, JIT 编译和解释执行配合使用。
在应用运行时分析运行过的代码以及“热代码”,并将配置存储下来。在设备空闲与充电时,ART仅仅编译这份配置中的“热代码”
简单来说,就是在应用首次安装、运行时不做 AOT 编译,然后把运行中 JIT 解释执行的代码记录下来,设备空闲时通过 dex2oat 编译生成名为 app_image 的 base.art 文件,这个文件主要为了 加快应用对“热代码”的加载和缓存。
在 apk 启动时,会加载应用的 oat 文件和可能存在的 app_image 文件,如果存在 app_image 文件,则把这个文件里的 class 插入到 ClassTable,在类加载时,会先从 ClassTable 中查找,找不到才会去走 defineClass
app image的作用是记录已经编译好的“热代码”,并且在启动时一次性把它们加载到缓存。预先加载代替用时查找以提升应用的性能,到这里我们终于明白为什么base.art会影响热补丁的机制。
无论是使用插入pathlist还是parent classloader的方式,若补丁修改的class已经存在于 app image,它们都是无法通过热补丁更新的。它们在启动app时已经加入到PathClassloader的ClassTable中,系统在查找类时会直接使用base.apk中的class。
从刚才的代码我们也看到了,Tinker 的解决方案是,新建一个 ClassLoader,也就是不使用之前的 cache。
可以看到,加载 dex 其实和 QZone 的方案差不多,都是通过反射将 dex 文件放置到加载的 dexElements 数组的前面。
微信Tinker原理图
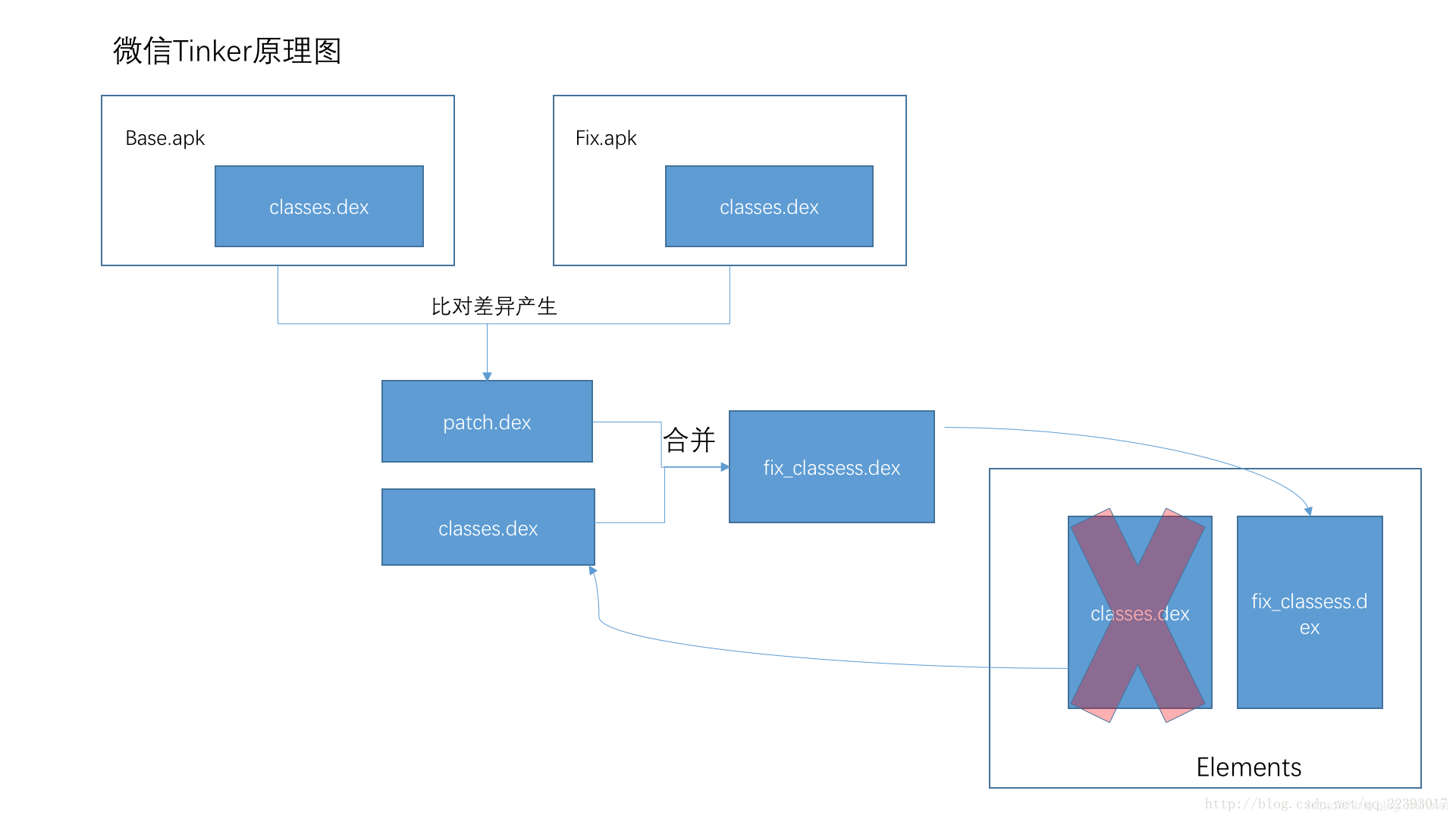
区别在于:
- QZone 是将 patch.dex 插到数组的前面,也就是说没修改的类还是在之前的 dex 里,这就可能导致那个
CLASS_ISPREVERIFIED问题,QZone 通过插桩解决这个问题,这里就不多说了 - Tinker 则是将合并后的全量 dex 插在数组前,这样就避免了这个问题的出现
加载资源
Tinker的资源更新采用的
InstantRun的资源补丁方式,全量替换资源
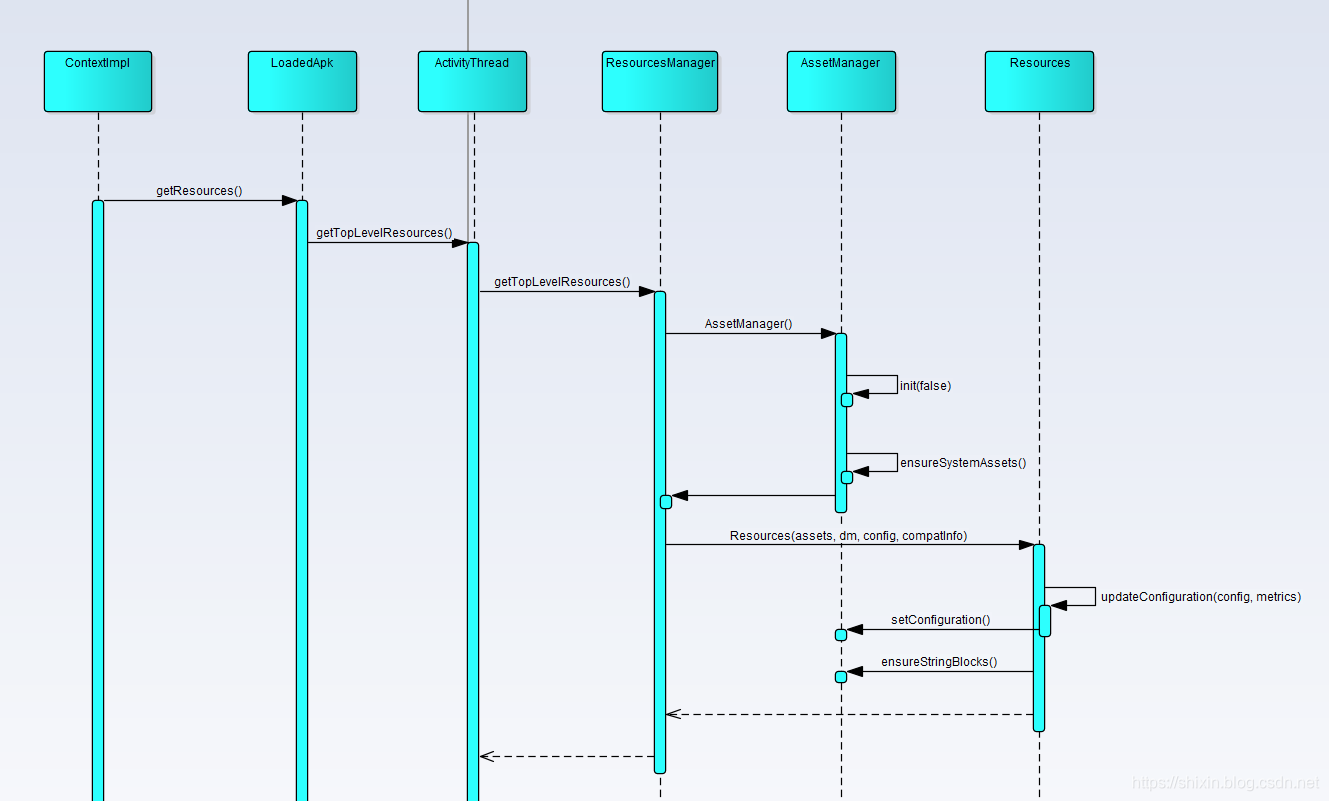
首先回顾一下,应用加载资源是通过 Context.getResources() 返回的 Resources 对象, Resources 内部包装了 ResourcesImpl, 间接持有了 AssetManager 对象,最终由 AssetManager 从 apk 文件中加载资源。
要加载资源,需要做 2 步:
- 新建一个 AssetManager ,通过
addAssetPath()方法把补丁资源目录传递进去 - 替换所有 Resources 对象中的 AssetManager
看下代码,资源加载部分主要在 TinkerResourceLoadr 中,两个方法:
TinkerResourceLoader#checkComplete检查资源补丁是否存在,存在的话,调用TinkerResourcePatcher#isResourceCanPatch区分版本拿到Resources对象的集合,同时创建新 AssetsManager- 看一下代码
- 拿到
addAssetPathMethod方法留着后面调用 - 4.4 以上通过
ResourcesManager获取mActiveResources变量,它是 ArrayMap 类型;在 7.0 上这个变量名称为mResourceReferences - 4.4 以下通过
ActivityThread获取mActiveResources变量,是一个 HashMap - 保存这些集合后
TinkerResourceLoader#loadTinkerResource调用TinkerResourcePatcher#monkeyPatchExistingResources- (这个方法的名字跟 InstantRun 的资源补丁方法名是一样的)
- 反射调用新建的
AssetManager#addAssetPath将路径穿进去 - 循环遍历持有Resources对象的references集合,依次替换其中的AssetManager为新建的AssetManager
- 最后调用Resources.updateConfiguration将Resources对象的配置信息更新到最新状态,完成整个资源替换的过程
加载补丁要替换的Resources对象在KITKAT之下是以HashMap的类型作为ActivityThread类的属性.其余的系统版本都是以ArrayMap被ResourcesManager持有的.所以要按照系统区分开.
市面上大多数的热补丁框架都采用 instant-run 的这套资源更新方案
加载 so
Tinker 加载 SO 补丁提供了两个入口,
TinkerLoadLibraryloadArmLibraryTinkerApplicationHelper#loadLibraryFromTinker(看下它的代码)
比较简单,最终都是调用 System#load
dex diff
- dex 格式
- diff 简单思路
- 代码

Tinker 的亮点之一就是它的 diff 算法,补丁里只包含改变的信息,非常小。这一节我们来了解下如何实现的 dex diff。
开始之前,先简单介绍下 dex 的格式。
dex 格式
先 javac 生成 class 文件,再通过 dx 工具生成 dex 文件。
dx --dex --output=Hello.dex Hello.class
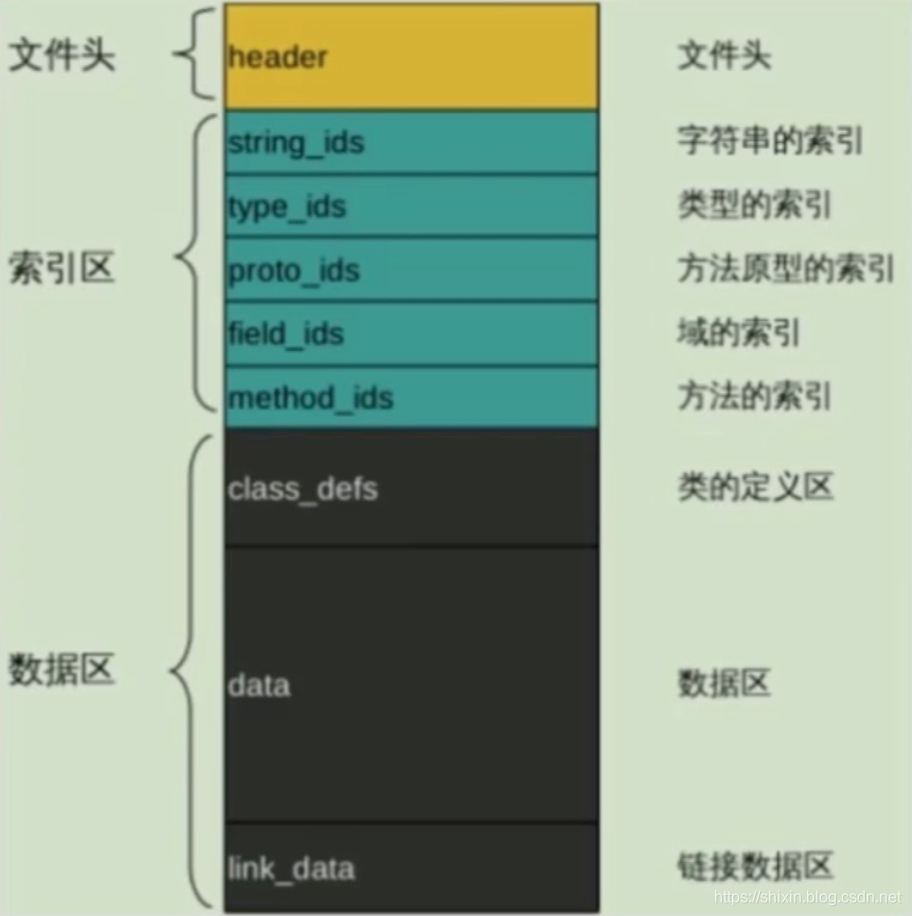
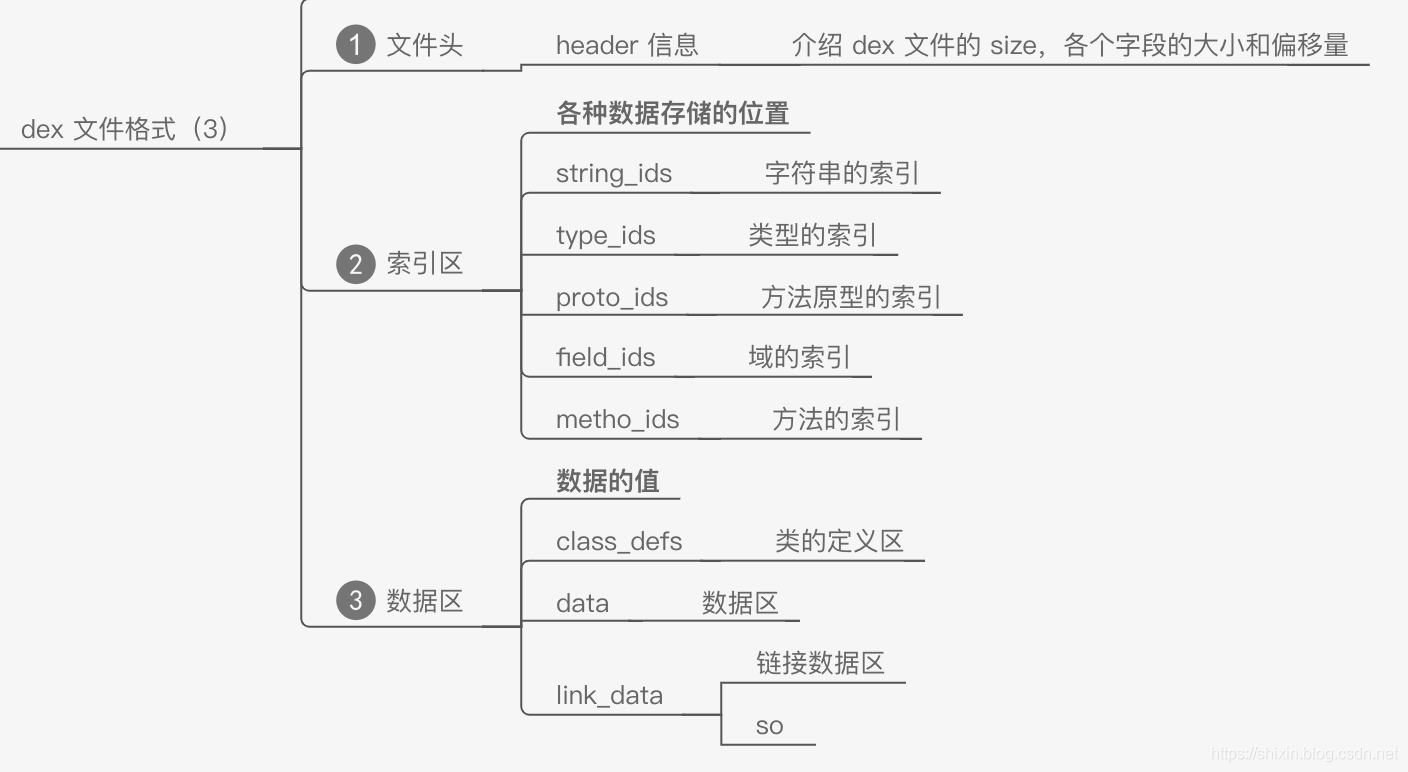
如图所示,dex 文件主要包括三个区域:
文件头记录了包含了一些校验相关的字段,和整个dex文件大致区块的分布
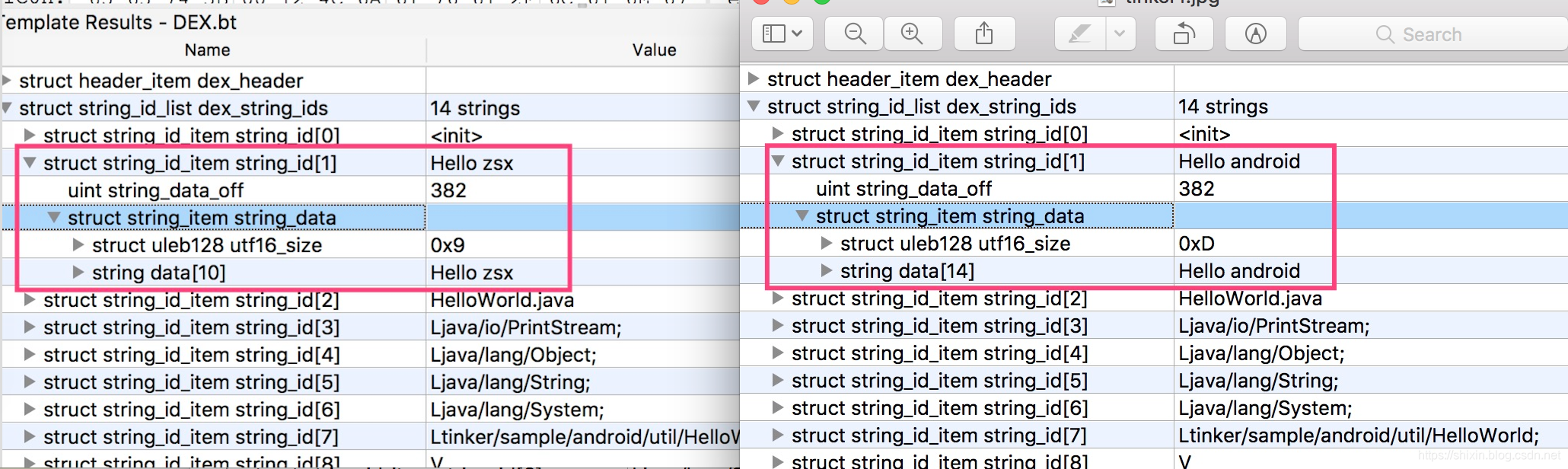
结合 010Editor 打开的 HelloWorld.dex 文件介绍下内容。
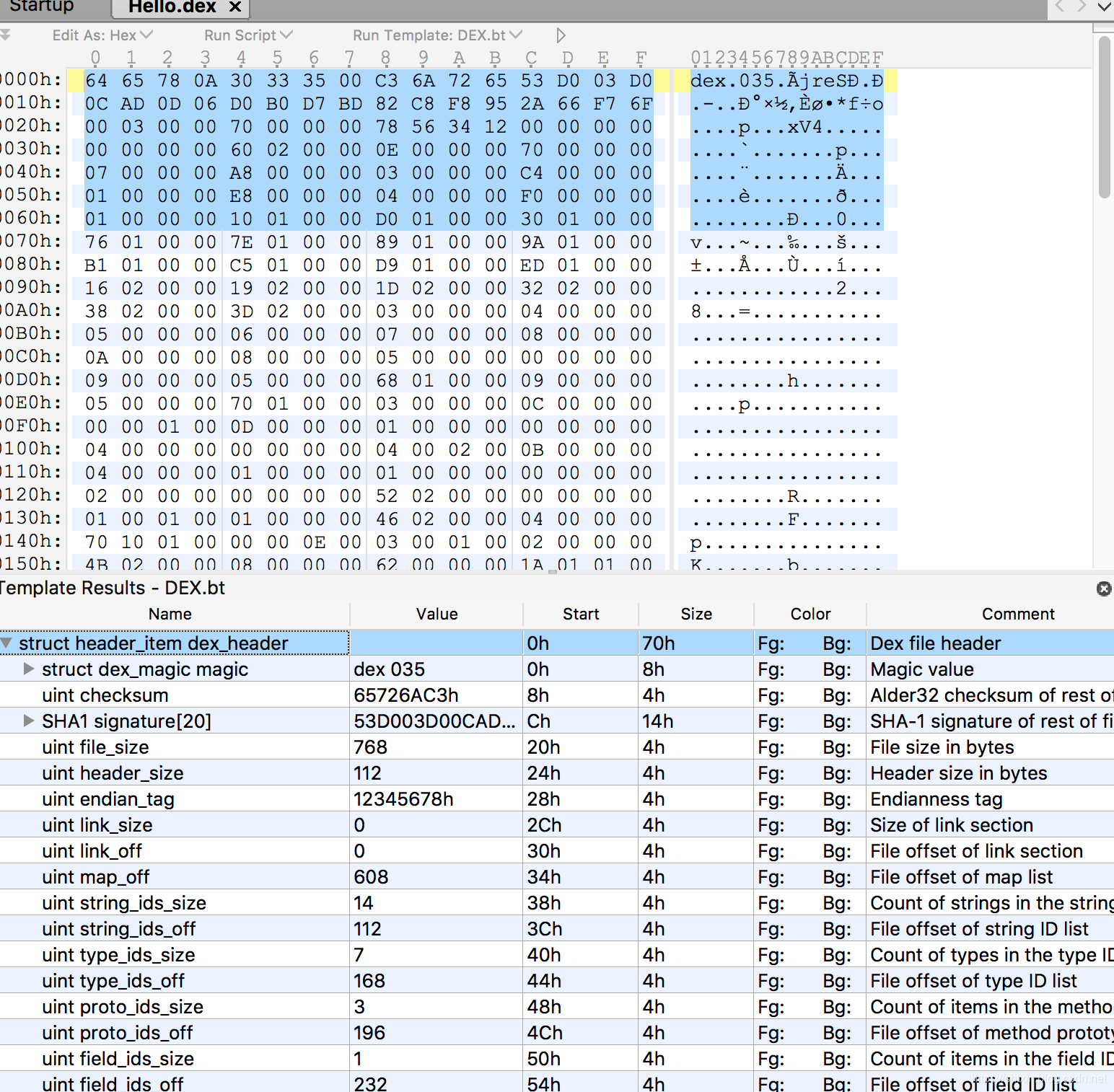
header 定长 112。
magic是用于表示 dex 文件和版本。checksum是文件检验和- 其余的根据名字就可以看出来意义
成对出现的size和off,大多代表各区块的包含的特定数据结构的数量和偏移量。例如:string_ids_off为112,指的是偏移量112开始为string_ids区域;string_ids_size为14,代表string_id_item的数量为14个
紧接着 header 后面的是索引区,描述了 dex 文件中 各种格式的数据和 id。
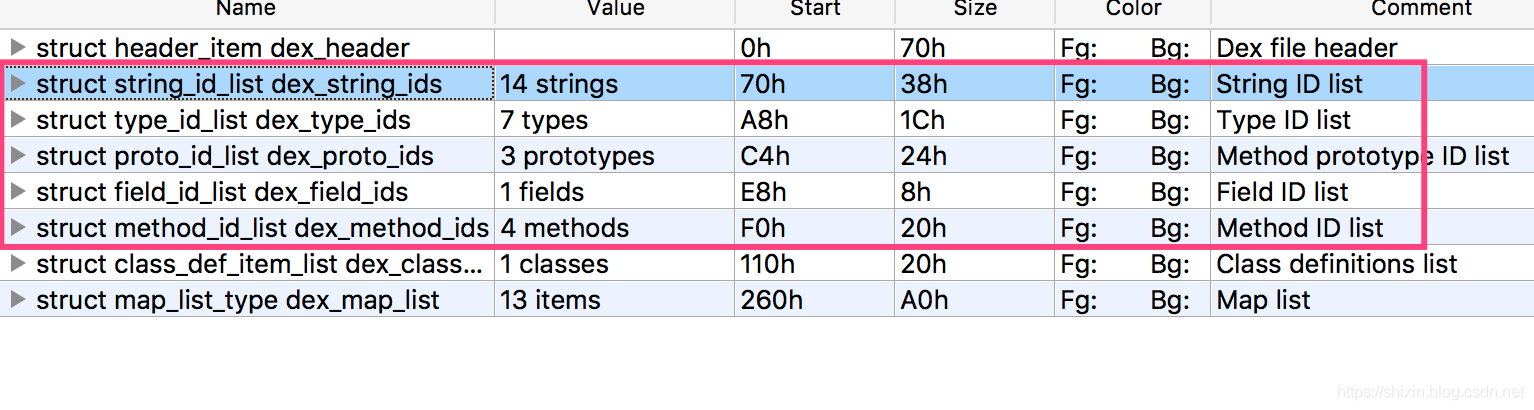
- string_id_list,描述了 dex 文件中所有的字符串,格式很简单只有一个偏移量,偏移量指向了 string_data 区段的一个字符串
- type_id_list,描述 dex 中所有的文件类型,内容也很简单,只有一个 string_id 里的序号
- proto_id_list,描述了方法原型,内容包括 method 原型名称、返回值和参数,参数 0 表示没有
- field_id_list,描述了 dex 文件引用的所有 field,内容包括 field 的所在的 class,field 的类型和 field 的名称
- method_id_list,描述了 dex 文件里所有的 method,内容包括方法所属的 class,类型和名称
最后是数据区,010 Editor 中没有展示 data 的数据。
- class_def,描述了 dex 文件中的 class 信息
- map_list(对应上图中的 link_data ),大部分 item 跟 header 中的相应描述相同,都是介绍了各个区的偏移和大小,但是 map_list 中描述的更加全面,包括了 HEADER_ITEM 、TYPE_LIST、STRING_DATA_ITEM、DEBUG_INFO_ITEM 等信息。
- 类型
- 个数
- 偏移量
- **通过
map_list,可以将一个完整的dex文件划分成固定的区域(本例为13),且知道每个区域的开始,以及该区域对应的数据格式的个数
了解了 dex 格式后,看下 tinker 中讲 dex 文件读取到内存中的类 TableOfContents,可以看到,使用 Section 描述不同类型的区域。
tinker patch 格式了解
tinker dex format
tinker patch 里主要包括两部分内容 :
- header,magic 和 version ,记录各个 Section 的偏移量
- 其余部分是不同类型的变更情况,item 包括操作类型、索引和变更内容
使用
java -jar tinker-dex-dump.jar --dex classes.dex
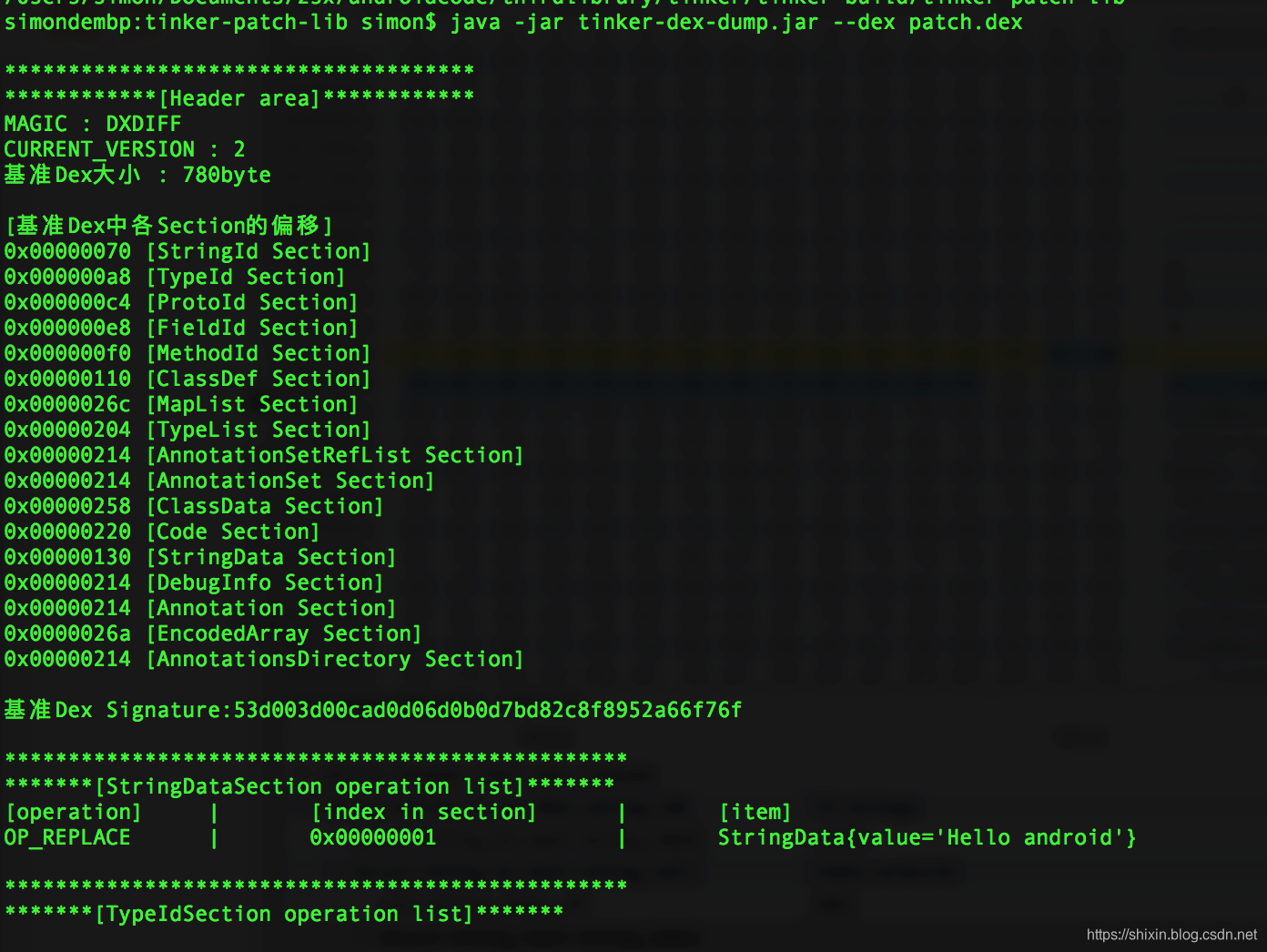
可以看到,patch 主要记录的是对不同数据类型的数据进行的新增、删除或者修改操作,和修改的内容。
对应 tinker 里的 PatchOperation 类:
public final class PatchOperation<T> {
public static final int OP_DEL = 0;
public static final int OP_ADD = 1;
public static final int OP_REPLACE = 2;
public int op;
public int index;
public T newItem;
}
diff 和合并简单思路
了解 tinker-patch 的内容后,就基本可以了解到 tinker dex-diff 的思路了。
逐个对比新旧 dex 每个 Section 的变更情况,然后再 patch 里把每个区域变更的类型和索引、内容写到 patch 里。
运行时拿到 patch,根据变更 Section 里的数据,去修改对应的索引的数据,生成最终 dex。
看看代码是不是这样。
源码分析
前面的例子我们知道,在执行完 tinker 的 tinkerPatchDebug task 后 ,就生成了 patch。
顺着代码看下,
- TinkerPatchSchemaTask
- Runner#tinkerPatch
- ApkDecoder#patch
- DexDiffDecoder#onAllPatchesEnd
- DexDiffDecoder#generatePatchInfoFile
- DexDiffDecoder#diffDexPairAndFillRelatedInfo
- DexPatchGenerator#executeAndSaveTo
最后发现,真正生成 patch 是在 DexPatchGenerator 这个类中。
DexPatchGenerator
-
dex 读取到内存,
Dex#loadFrom,TableOfContents#readFrom,将 dex 文件内容,按照 map-list 分到不同的 Section 中 -
DexPatchGenerator构造函数,初始化了 15 个对不同区域的算法,目的就是前面说的,计算出每个区域的变更情况 -
DexPatchGenerator#executeAndSaveTo,调用 15 个算法的execute()和simulatePatchOperation()
以 stringDataSectionDiffAlg 为例,看下做了什么。
DexSectionDiffAlgorithm
看下它的 execute() 和 simulatePatchOperation() 方法 。
execute() 做的工作:
- 拿到旧、新 dex 的 Section Item 列表,排序
- 遍历,对比每个 item
- 做一些排序处理,合并相同 index 的 ADD 和 DEL 为 REPLACE
- 把不同类型的操作,保存到三个 map
经历完成 execute 之后,我们主要的产物就是 3 个Map,
indexToDelOperationMap,indexToAddOperationMap,indexToReplaceOperationMap
分别记录了:oldDex 中哪些index需要删除;newDex中新增了哪些item;哪些item需要替换为新item。
simulatePatchOperation() 做的工作:根据前面的 3 个 map,计算变更数据 index 和 offset,计算下一个 Section 需要依赖前面的 offset。
经过这两个方法 ,得到了这个 Section 的 patchOperationList 和 patchSectionSize。
执行完所有算法,就可以得到整个 patch 所有 Section 的变更操作和对应的偏移量,
写 patch 文件
执行完所有算后,进入 DexPatchGenerator#writeResultToStream 生成 patch 文件。
DexPatchGenerator#writePatchOperations 中,主要完成三步(看代码):
可以看到,和我们前面看的那个图对应的数据一样。
patch 的合成
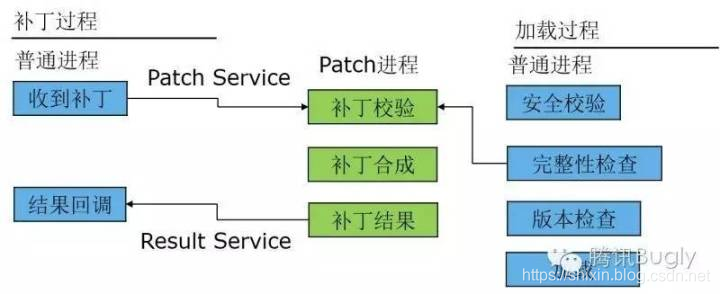
前面提到,TinkerInstaller#onReceiveUpgradePatch 方法,在接收到新的 patch 后我们调用这个方法,传入路径,然后会进行 patch 的合成。
补丁合成在单独的 patch 进程工作,包括 dex,so 还有资源,主要完成补丁包的合成以及升级。
patch 里关于变更信息的数据:
1.del操作的个数,每个del的index
2.add操作的个数,每个add的index
3.replace操作的个数,每个需要replace的index
4.最后依次写入newItemList.
DexPatchApplier
- Dex File ->
DexPatchFile - 检查 patch 是否能作用到当前的 oldDex(通过比较 oldDex 签名和 patch 里记录的 oldDex 签名,签名使用
SHA-1算法) - 把 patch 里记录的合并后的各个 Section 的值复制给合并后 dex 的
TableOfContents - 创建 15 个合并算法处理器,处理不同区域的数据合并
- 最后,写入 header mapList 和 合并后 dex 的签名和校验和
每个 Section 的合并算法类似,继承自 DexSectionPatchAlgorithm:
- 读取保存 del add replace 操作 index 的数组
- 计算出合并后的 itemCount:
newItemCount=oldItemCount-deleteItemCount+addItemCount - 往合并后的 dex 对应的 xxData 区域写最终内容(包括没变的、新增的和替换的)
从 0 开始,按顺序写合并后的内容规则:
- 首看先这个位置是否有新增的
- 然后看这个位置是否需要替换为 newItem
- 如果这个位置包含在 del/replace 数组里,那就跳过这个位置 oldItem
- 否则说明这个位置的 oldItem 元素没动,写到合并后的 dex 里
