YOLO 工作原理
- YOLO 的工作原理是,将图片输入到多层卷积以提取图片特征。然后直接在输出层回归目标框坐标及其所属的类别。最后通过NMS处理去掉重叠的目标框。
- 与 Faster-RCNN 不同,Faster-RCNN 是在提取特征图后,使用候选框去扫描特征图的方式去寻找目标。然后通过两个子网络进行回归分类。一个用于将候选框加上偏移缩放,以回归目标坐标。一个用来做目标分类。最后通过NMS处理去掉重叠的目标框。
YOLO 优缺点
优点:
- 网络简单直观,实现容易。
- 识别与训练速度快。
- 大物体的准确率较高。
缺点:
- 因为直接从特征图输出的分类,特征图分辨率较低,对应重叠度高,或目标细小密集的物体,检出率较低。
YOLO V1
网络结构:
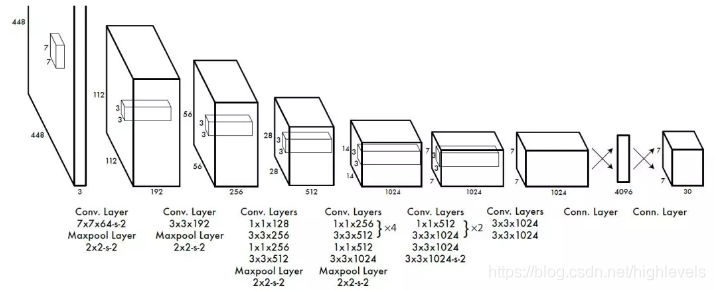
- 网络输入图片大小为 (448*448*3),经过卷积与最大值池化,得到 (7*7*1024) 的特征。
- 特征经过4096全连接层,转换成 (7*7*30) 结果。
- (7*7*30) 结果,对应 7*7=49 个特征点,最多可在图片检测到49个目标。这里的30包含了两部分信息,一部分是两个目标框坐标 (x,y,w,h) 及置信度,一部分是20个分类,因此(4+1)*2+20=30。
缺点:
- 较小密集的目标,检出率较低。
- 目标框不精准,会有一定偏差。
- 对长宽比差异较大的物体,泛化能力较差。
YOLO V2
改进内容:
- 由直接回归目标坐标 (x,y,w,h),改为预先设定候选框大小,每个特征图每个点对应3个大小与形状不同的候选框,再回归候选框的偏移量。这样可以优化检测长宽比差异较大的目标时,增加目标框的精度,加快训练速度。
- 图片特征提取网络改为Darknet-19网络,提供训练速度。
- 输入图片大小由 (448*448*3) 改为 (416*416*3)。
- 提取 (13*13) 的特征图。另外取前面的 (26*26) 特征图,转换成 (13*13) 特征图,用于预测更小的物体。
网络结构:
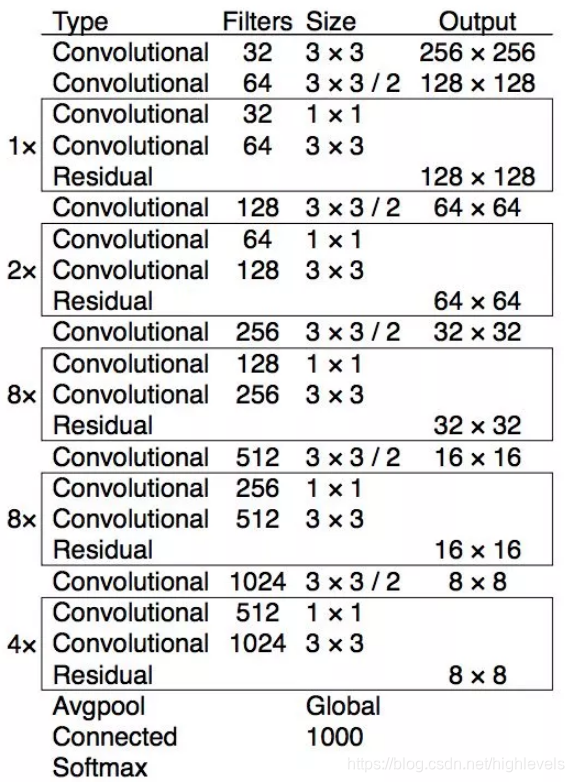
- Docknet19,最后是分类用的,一共1000个类别。YOLO网络去掉结尾部分作为特征提取网络:

- 然后接 (13*13*300) 卷积,得到目标框坐标与分类。 (4+1+20)*3=300。
速度比较:

YOLO V3
改进内容:
- 在 Pascal Titan X 上处理 608x608 图像速度可以达到 20FPS,在 COCO test-dev 上 [email protected] 达到 57.9%。
- 输入图片有3种大小,(320*320)、(416*416)、(608*608)。速度由快到慢,精度由低到高。
- 使用FPN特征金字塔结构,提取3层不同尺度的特征,每个特征采用3种不同大小形状的候选框。
- 特征提取网络由Darknet-19改为Darknet-53,增加了网络深度。
- 由每个框对应各自做 Softmax 分类,改为多个 Logistic 分类器。
- 分类损失采用 binary cross-entropy loss。
网络结构:
- Darknet-53,最后是分类用的,一共1000个类别。YOLO网络去掉结尾部分作为特征提取网络:
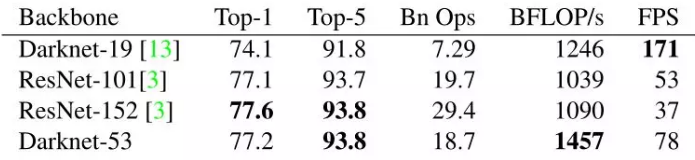
- darknet-53 与 ResNet-101 或 ResNet-152 准确率接近,但速度更快,对比如下:
- 完整网络如下:

速度比较:
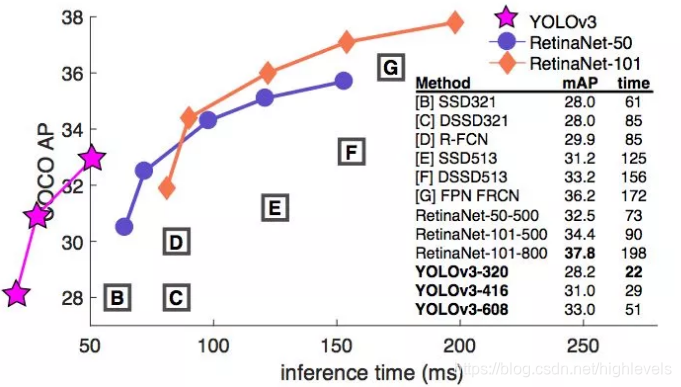
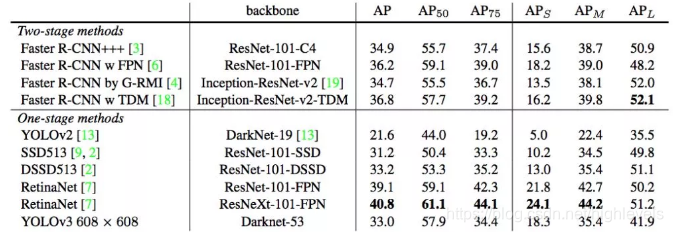
结论:
- YOLOv3 在 [email protected] 及小目标 APs 上具有不错的结果,但随着 IOU的增大,性能下降,说明 YOLOv3 不能很好地与 ground truth 切合.
参考资料:
