Hadoop文件系统(HDFS)
HDFS的概念和特性
- 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
- 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色
重要特性如下:
- HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
- HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:
hdfs://namenode:port/dir-a/dir-b/dir-c/file.data - **目录结构及文件分块信息(元数据)**的管理由namenode节点承担,namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
- 文件的各个block的存储管理由datanode节点承担, datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
- HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
文件系统基本操作命令
- 使用hadoop客户端上传文件到集群,hadoop客户端在
$HADOOP_HOME/bin下
# 查看所有支持命令
[hadoop@master test]$ hadoop fs
# hadoop fs 启动hadoop客户端,上传文件到dfs根目录
[hadoop@master test]$ hadoop fs -put test.md /
# 下载文件
[hadoop@master test]$ hadoop fs -get /test.md
# 查看文件
[hadoop@master test]$ hadoop fs -ls /
Found 1 items
-rw-r--r-- 3 hadoop supergroup 8 2019-11-30 15:16 /test.md
# 创建文件夹 上级目录不存在自动创建父目录
[hadoop@master test]$ hadoop fs -mkdir -p /wordcount/input
# 上传多个文件到指定目录
[hadoop@master test]$ hadoop fs -put wordCount.md wordCount.txt /wordcount/input
# 查看上传结果
[hadoop@master test]$ hadoop fs -ls /wordcount/input
Found 2 items
-rw-r--r-- 3 hadoop supergroup 111 2019-11-30 15:57 /wordcount/input/wordCount.md
-rw-r--r-- 3 hadoop supergroup 111 2019-11-30 15:57 /wordcount/input/wordCount.txt
#创建hadoop用户目录下的input
[hadoop@master hive]$ hadoop fs -mkdir -p /user/hadoop/input
# 上传到当前(hadoop)用户下的input目录
[hadoop@master hive]$ hadoop fs -put jdbc/hive-jdbc-2.3.6-standalone.jar input
常用命令参数介绍
- -help
功能:输出这个命令参数手册
示例: hadoop fs -ls -help - -ls
功能:显示目录信息
示例: hadoop fs -ls hdfs://master:9000/
备注:这些参数中,所有的hdfs路径都可以简写- hadoop fs -ls / 等同于上一条命令的效果
- -mkdir
功能:在hdfs上创建目录
示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd - -moveFromLocal
功能:从本地剪切粘贴到hdfs
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd - -moveToLocal
功能:从hdfs剪切粘贴到本地
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt - -appendToFile
功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt
可以简写为:
Hadoop fs -appendToFile ./hello.txt /hello.txt - -cat
功能:显示文件内容
示例:hadoop fs -cat /hello.txt - -tail
功能:显示一个文件的末尾
示例:hadoop fs -tail /weblog/access_log.1 - -text
功能:以字符形式打印一个文件的内容
示例:hadoop fs -text /weblog/access_log.1 - -chgrp
- -chmod
- -chown
功能:linux文件系统中的用法一样,对文件所属权限
示例:
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt - -copyFromLocal
功能:从本地文件系统中拷贝文件到hdfs路径去
示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ - -copyToLocal
功能:从hdfs拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz - -cp
功能:从hdfs的一个路径拷贝hdfs的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 - -mv
功能:在hdfs目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz / - -get
功能:等同于copyToLocal,就是从hdfs下载文件到本地
示例:hadoop fs -get /aaa/jdk.tar.gz - -getmerge
功能:合并下载多个文件
示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum - -put
功能:等同于copyFromLocal
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 - -rm
功能:删除文件或文件夹
示例:hadoop fs -rm -r /aaa/bbb/ - -rmdir
功能:删除空目录
示例:hadoop fs -rmdir /aaa/bbb/ccc - -df
功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h / - -du
功能:统计文件夹的大小信息
示例:
hadoop fs -du -s -h /aaa/* - -count
功能:统计一个指定目录下的文件节点数量
示例:hadoop fs -count /aaa/ - -setrep
功能:设置hdfs中文件的副本数量
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量>
HDFS原理
hdfs的工作机制
工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能力,形成一定的集群运维能力
注:很多不是真正理解hadoop技术体系的人会常常觉得HDFS可用于网盘类应用,但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解
概述
- HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
- NameNode负责管理整个文件系统的元数据
- DataNode 负责管理用户的文件数据块
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
HDFS写数据流程
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
详细步骤图
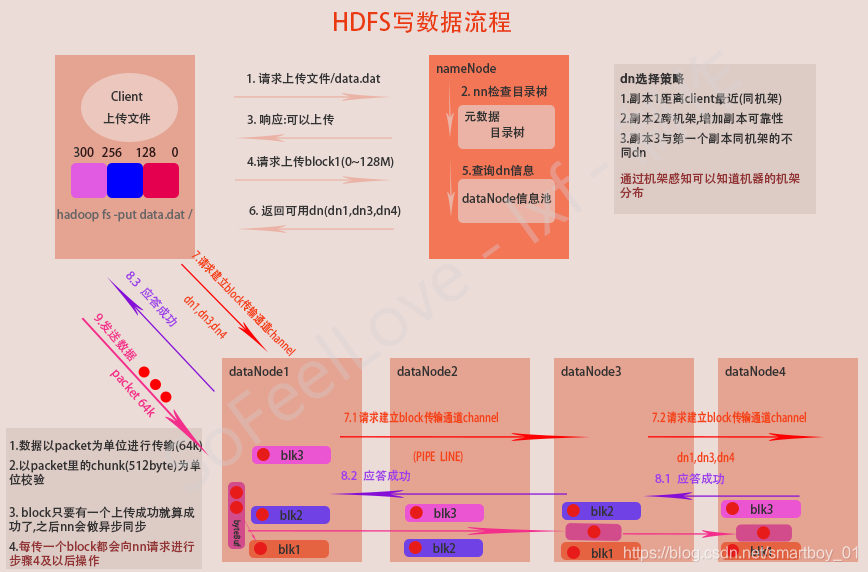
详细步骤解析
- 与namenode通信请求上传文件
- namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求namenode第一个 block该传输到哪些datanode服务器上
- namenode查询datanode信息
- namenode返回3个datanode服务器ABC
- client请求3台datanode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成
- 逐级返回响应内容直到客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器(重复步骤4及以后步骤)
HDFS读数据流程
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
详细步骤图
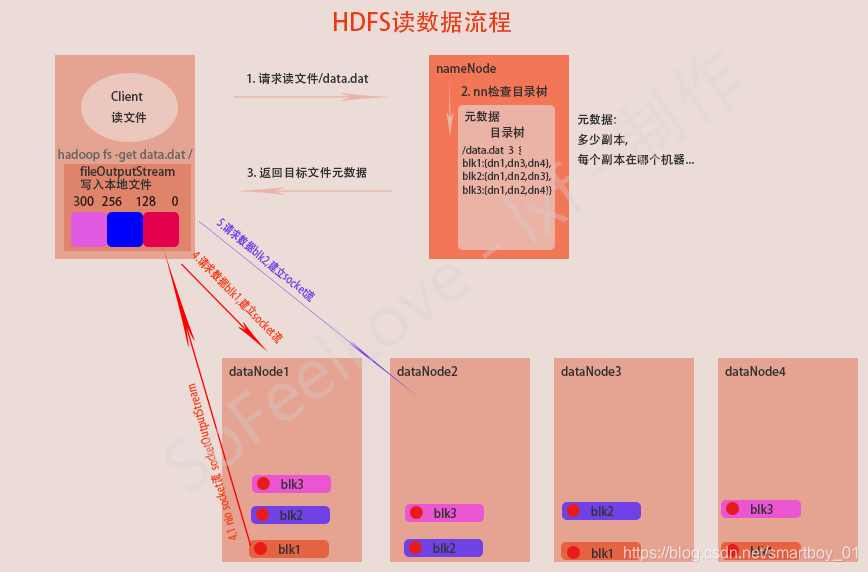
详细步骤解析
- 跟namenode通信请求下载文件
- nn查询元数据,找到文件块所在的datanode服务器
- 返回要下载文件元数据给客户端
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流,下载block1
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
- 重复步骤4及以后步骤下载其他剩余block
NAMENODE工作机制
理解namenode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优”、“namenode”故障问题的分析解决能力
问题场景:
- 集群启动后,可以查看文件,但是上传文件时报错,打开web页面可看到namenode正处于safemode状态,怎么处理?
- Namenode服务器的磁盘故障导致namenode宕机,如何挽救集群及数据?
- Namenode是否可以有多个?namenode内存要配置多大?namenode跟集群数据存储能力有关系吗?
- 文件的blocksize究竟调大好还是调小好?
……
诸如此类问题的回答,都需要基于对namenode自身的工作原理的深刻理解
NAMENODE职责
NAMENODE职责:
- 负责客户端请求的响应
- 元数据的管理(查询,修改)
元数据管理
namenode对数据的管理采用了三种存储形式:
- 内存元数据(NameSystem)
- 磁盘元数据镜像文件
- 数据操作日志文件(可通过日志运算出元数据)
元数据checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
一条元数据block平均150Byte,1000条 150k,100万条 150M,1亿 15G ,元数据单纯保存在内存中不安全,写入文件很耗时又很耗时,为解决此问题,使用secondary namenode
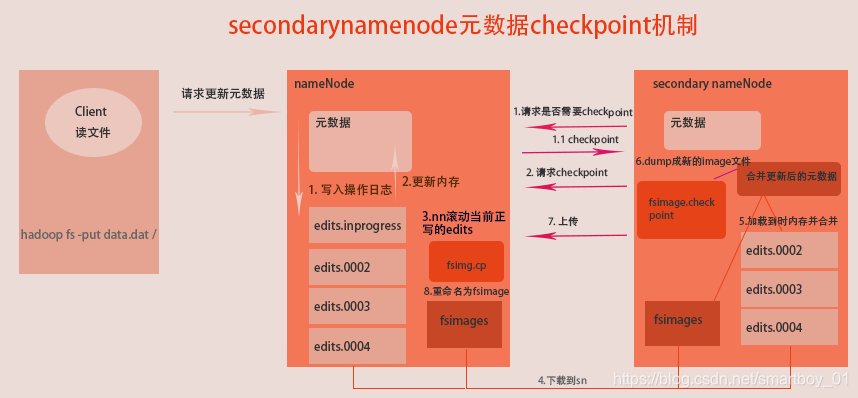
元数据checkpoint流程详解
客户端发送更新元数据请求,nameNode执行过程如下
- 更新内存中的元数据
- 记录操作日志到edits.inprogress(正在写入的文件),操作文件会滚动更新
edits.001 edits.002. edits.003 ....
为确保元数据实时性与安全性使用secondary namenode机制,具体流程如下
- sn(定时默认30min)请求nn是否checkpoint,nn返回响应结果
- 若nn返回checkpoint,sn再次请求nn开始checkpoint
- 为了一次同步更多的元数据,nn立即滚动
edits.inprogress生成edits.004(假设),edits.inprogress继续提供服务 - 下载所有操作日志
edits.001 edits.002 edits.003 edits.004与镜像文件fsimage到sn上(sn操作) - 加载得到的所有文件
edits.001 edits.002 edits.003 edits.004 fsimage到内存合并更新(sn操作) - dump内存中更新后的元数据到本地生成新的
image文件fsimage.checkpoint(sn操作) - sn上传新的镜像文件到nn上(
sn操作) - nn重命名
fsimage.checkpoint为fsimage更新本地镜像文件为合并后的新文件
这样就确保了更新元数据而不影响nn对外提供服务
- 第一次checkpoint时由于
fsimage中只存储了30分钟的数据,所以向sn传递时并不会消耗太多时间 - 除第一次,以后每次由于sn与nn具有相同内容的镜像文件
fsimage所以只需要同步上次同步后的操作日志文件到sn,这样就节省了大量的时间
思考
- namenode宕机,hdfs服务不能正常提供服务
sn虽然存在元数据信息,但不能更新元数据,不能充当nn使用 - nn硬盘损坏,可以通过sn恢复部分元数据(将sn的元数据目录cp到nn上)
- 在
hdfs-site.xml配置namenode的工作目录时,应该配置在多块磁盘上,同时向2块(多块)磁盘上写数据,数据都一致
<property>
<name>dfs.name.dir</name>
# 各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存
<value>/home/hadoop/dfs/name1,/home/hadoop/dfs/name2</value>
</property>
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
<property>
<name>dfs.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
hadoop.tmp.dir是在core-site.xml中配置的,默认值如下
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
元数据存储机制
- A、内存中有一份完整的元数据(内存meta data)
- B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
- C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
元数据手动查看
可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml
checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
元数据目录说明
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
$HADOOP_HOME/bin/hdfs namenode -format
格式化完成之后,将会在$dfs.name.dir/current目录下如下的文件结构
current/
|-- VERSION
|-- edits_*
|-- fsimage_0000000000008547077
|-- fsimage_0000000000008547077.md5
|-- seen_txid
$dfs.namenode.name.dir/current/目录下的文件进行解释
VERSION文件是Java属性文件,内容大致如下:
#Thu Nov 28 21:04:14 CST 2019
# namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的
namespaceID=1833565797
# clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它
clusterID=CID-29cdee79-3898-431e-9997-0aad46d4709c
# (升级时使用)cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳
cTime=0
# storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE)
storageType=NAME_NODE
# 是针对每一个Namespace所对应的blockpool的ID
blockpoolID=BP-1432876390-192.168.80.10-1574861222170
# (升级时使用)layoutVersion表示HDFS永久性数据结构的版本信息,只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用
layoutVersion=-47
-clusterid使用说明
- 使用如下命令格式化一个
Namenode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。 - 升级集群至最新版本。在升级过程中需要提供一个
ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID
$dfs.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资源。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载
$dfs.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
DATANODE的工作机制
datanode工作职责:
存储管理用户的文件块数据,定期向namenode汇报自身所持有的block信息(通过心跳信息上报,这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
- datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval大小为5分钟,dfs.heartbeat.interval默认为3秒。 - 需要注意的是
hdfs-site.xml配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
datanode 存储原理
- 文件在机器的真实存储路径为
/home/hadoop/bigdata/data/dfs/data/current/BP-1432876390-192.168.80.10-1574861222170/current/finalized/subdir0/subdir0,/home/hadoop/bigdata/data/dfs/data为~/bigdata/hadoop/etc/hadoop/hdfs-site.xml文件中设置的数据节点元数据存储位置,查看其中内容
[hadoop@node1 subdir0]$ cd /home/hadoop/bigdata/data/dfs/data/current/BP-1432876390-192.168.80.10-1574861222170/current/finalized/subdir0/subdir0
[hadoop@node1 subdir0]$ ls
blk_1073741825 blk_1073741825_1001.meta
## 查看文件内容,文件内容与test.md内容完全一致
[hadoop@node1 subdir0]$ cat blk_1073741825
export
- Hadoop默认文件
>128M时会拆分,若文件存储时被拆分为blk_1073741826 blk_1073741827,手动合并为一个文件后与原始文件一致,实际hadoop内容也是这个机制(对多个拆分文件分别下载在客户端完成拼接组合)
## 合并文件内容
[hadoop@node1 subdir0]$ cat blk_1073741826 >> tmp.file
[hadoop@node1 subdir0]$ cat blk_1073741827 >> tmp.file
# 查看文件内容 与原始上传文件内容一致 ,hadoop没有进行特殊处理
[hadoop@node1 subdir0]$ cat tmp.file
观察验证DATANODE功能
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/bigdata/data/dfs/data/current/BP-1432876390-192.168.80.10-1574861222170/current/finalized
hadoop自带示例
# 示例所在路径
[hadoop@master mapreduce]$ pwd
/home/hadoop/bigdata/hadoop-2.7.7/share/hadoop/mapreduce
[hadoop@master mapreduce]$ ll
总用量 4984
-rw-r--r-- 1 hadoop hadoop 540117 7月 19 2018 hadoop-mapreduce-client-app-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 773735 7月 19 2018 hadoop-mapreduce-client-common-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 1556812 7月 19 2018 hadoop-mapreduce-client-core-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 189951 7月 19 2018 hadoop-mapreduce-client-hs-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 27831 7月 19 2018 hadoop-mapreduce-client-hs-plugins-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 62388 7月 19 2018 hadoop-mapreduce-client-jobclient-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 1556921 7月 19 2018 hadoop-mapreduce-client-jobclient-2.7.7-tests.jar
-rw-r--r-- 1 hadoop hadoop 71617 7月 19 2018 hadoop-mapreduce-client-shuffle-2.7.7.jar
-rw-r--r-- 1 hadoop hadoop 296044 7月 19 2018 hadoop-mapreduce-examples-2.7.7.jar
drwxr-xr-x 2 hadoop hadoop 4096 7月 19 2018 lib
drwxr-xr-x 2 hadoop hadoop 30 7月 19 2018 lib-examples
drwxr-xr-x 2 hadoop hadoop 4096 7月 19 2018 sources
# 运行wordcount示例
# hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount(主类名) /wordcount/input(输入路径) /wordcount/output(输出路径output必须不存在)
[hadoop@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /wordcount/input /wordcount/output
wordcount运行结果
# 查看执行结果 _SUCCESS成功标识,part-r-00000结果文件
[hadoop@master mapreduce]$ hadoop fs -ls /wordcount/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2019-11-30 16:06 /wordcount/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 105 2019-11-30 16:06 /wordcount/output/part-r-00000
# 查看计算结果
[hadoop@master mapreduce]$ hadoop fs -cat /wordcount/output/part-r-00000
also 2
datanode 6
fast 2
good 2
hadoop 2
is 12
master 2
namenode 2
node1 2
node2 2
node3 2
spark 2
too 2
[hadoop@master mapreduce]$
HDFS的Java操作
https://gitee.com/SoFeelLove/hadoop_itcast/tree/master
hdfs在生产应用中主要是客户端的开发,其核心步骤是从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件
搭建开发环境
- 引入依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
注:如需手动引入jar包,hdfs的jar包----hadoop的安装目录的share下
- window下开发的说明
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
- A. 在windows的某个目录下解压一个hadoop的安装包
- B. 将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换https://github.com/SweetInk/hadoop-common-bin
- C. 在window系统中配置
HADOOP_HOME指向你解压的安装包 - D. 在windows系统的path变量中加入hadoop的bin目录
获取api中的客户端对象
在java中操作hdfs,首先要获得一个客户端实例
Configuration conf = new Configuration()
FileSystem fs = FileSystem.get(conf)
而我们的操作目标是HDFS,所以获取到的fs对象应该是DistributedFileSystem的实例;get方法是从何处判断具体实例化那种客户端类呢?
从conf中的一个参数 fs.defaultFS的配置值判断;
如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为: file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象
HDFS客户端操作数据代码示例
文件的增删改查
public class HdfsClient {
FileSystem fs = null;
@Before
public void init() throws Exception {
// 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI
// 从而FileSystem.get()方法就知道应该是去构造一个访问hdfs文件系统的客户端,以及hdfs的访问地址
// new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml
// 然后再加载classpath下的hdfs-site.xml
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hdp-node01:9000");
/**
* 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
*/
conf.set("dfs.replication", "3");
// 获取一个hdfs的访问客户端,根据参数,这个实例应该是DistributedFileSystem的实例
// fs = FileSystem.get(conf);
// 如果这样去获取,那conf里面就可以不要配"fs.defaultFS"参数,而且,这个客户端的身份标识已经是hadoop用户
fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop");
}
/**
* 往hdfs上传文件
*
* @throws Exception
*/
@Test
public void testAddFileToHdfs() throws Exception {
// 要上传的文件所在的本地路径
Path src = new Path("g:/redis-recommend.zip");
// 要上传到hdfs的目标路径
Path dst = new Path("/aaa");
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* 从hdfs中复制文件到本地文件系统
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"), new Path("d:/"));
fs.close();
}
@Test
public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException {
// 创建目录
fs.mkdirs(new Path("/a1/b1/c1"));
// 删除文件夹 ,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/aaa"), true);
// 重命名文件或文件夹
fs.rename(new Path("/a1"), new Path("/a2"));
}
/**
* 查看目录信息,只显示文件
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// 思考:为什么返回迭代器,而不是List之类的容器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation location : blockLocations) {
System.out.println("块名称:" + location.getNames());
System.out.println("block-length:" + location.getLength() + "--" + "block-offset:" + location.getOffset());
String[] hosts = location.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------为angelababy打印的分割线--------------");
}
}
/**
* 查看文件及文件夹信息
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "d-- ";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile()) flag = "f-- ";
System.out.println(flag + fstatus.getPath().getName());
}
}
}
通过流的方式访问hdfs
mapreduce切片计算时需要支持随机定位进行文件读取并且可以方便读取指定长度,进行计算,所以提供流方式访问hdfs
/**
* 相对那些封装好的方法而言的更底层一些的操作方式
* 上层那些mapreduce spark等运算框架,去hdfs中获取数据的时候,就是调的这种底层的api
* @author
*
*/
public class StreamAccess {
FileSystem fs = null;
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "hadoop");
}
/**
* 通过流的方式上传文件到hdfs
* @throws Exception
*/
@Test
public void testUpload() throws Exception {
FSDataOutputStream outputStream = fs.create(new Path("/angelababy.love"), true);
FileInputStream inputStream = new FileInputStream("c:/angelababy.love");
IOUtils.copy(inputStream, outputStream);
}
@Test
public void testDownLoadFileToLocal() throws IllegalArgumentException, IOException{
//先获取一个文件的输入流----针对hdfs上的
FSDataInputStream in = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
//再构造一个文件的输出流----针对本地的
FileOutputStream out = new FileOutputStream(new File("c:/jdk.tar.gz"));
//再将输入流中数据传输到输出流
IOUtils.copyBytes(in, out, 4096);
}
/**
* hdfs支持随机定位进行文件读取,而且可以方便地读取指定长度
* 用于上层分布式运算框架并发处理数据
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testRandomAccess() throws IllegalArgumentException, IOException{
//先获取一个文件的输入流----针对hdfs上的
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
//可以将流的起始偏移量进行自定义
in.seek(22);
//再构造一个文件的输出流----针对本地的
FileOutputStream out = new FileOutputStream(new File("c:/iloveyou.line.2.txt"));
IOUtils.copyBytes(in,out,19L,true);
}
/**
* 显示hdfs上文件的内容
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testCat() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
IOUtils.copy(in, System.out);
//IOUtils.copyBytes(in, System.out, 1024);
}
}
再说明
集群NameNode
[hadoop@master current]$ pwd
/home/hadoop/bigdata/data/dfs/name/current
[hadoop@master current]$ more VERSION
#Thu Nov 28 21:04:14 CST 2019
namespaceID=1833565797
# 集群Id
clusterID=CID-29cdee79-3898-431e-9997-0aad46d4709c
cTime=0
storageType=NAME_NODE
# 块Id与dataNode的目录一致/home/hadoop/bigdata/data/dfs/data/current/BP-1432876390-192.168.80.10-1574861222170
blockpoolID=BP-1432876390-192.168.80.10-1574861222170
layoutVersion=-63
[hadoop@master current]$
DataNode
[hadoop@node1 current]$ more /home/hadoop/bigdata/data/dfs/data/current/VERSION
#Fri Nov 29 05:04:47 CST 2019
storageID=DS-be8af9a9-5858-4fda-af72-5fd4c376161c
# DataNode的集群Id与/home/hadoop/bigdata/data/dfs/name/current/VERSION中的一致
clusterID=CID-29cdee79-3898-431e-9997-0aad46d4709c
cTime=0
datanodeUuid=0b44d56f-7f14-4943-a3e5-916113d1eb3b
storageType=DATA_NODE
layoutVersion=-56
[hadoop@node1 current]$
获取api中的客户端对象
在java中操作hdfs,首先要获得一个客户端实例
Configuration conf = new Configuration()
FileSystem fs = FileSystem.get(conf)
而我们的操作目标是HDFS,所以获取到的fs对象应该是DistributedFileSystem的实例;get方法是从何处判断具体实例化那种客户端类呢?
- 从conf中的一个参数
fs.defaultFS的配置值判断 - 若代码中没有指定
fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为:file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象 - 副本数由客户端的参数
dfs.replication决定(优先级: 代码中conf.set> 自定义配置文件 > jar包中的hdfs-default.xml)
