贪心算法(英语:greedy algorithm),又称贪婪算法,是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。
—— 维基百科
背包相关问题
经典背包问题
求最优装载,给出n个物体,第i个物体重量为wi。选择尽量多的物体,使得总重量不超过C。
- 分析
由于只关心物体的数量,所以装重的没有装轻的划算。只需把所有物体按重量从小到大排序,依次选择每个物体,直到装不下为止。这是一种典型的贪心算法,它只顾眼前,但却能得到最优解。
部分背包问题
有n个物体,第i个物体的重量为wi,价值为vi。在总重量不超过C的情况下让总价值尽量高。每一个物体都可以只取走一部分,价值和重量按比例计算。
- 分析
不能简单地先拿轻的(轻的可能价值也小),也不能先拿价值大的(可能它特别重),而应该综合考虑两个因素。一种直观的贪心策略是:优先拿价值除以重量的值最大的,直到重量和正好为C。
乘船问题
有n个人,第i个人重量为wi。每艘船的最大载重量均为C,且最多只能乘两个人。用最少的船装载所有人。
- 分析
考虑最轻的人i,他应该和谁一起坐呢?如果每个人都无法和他一起坐船,则唯一的方案就是每人坐一艘船。否则,他应该选择能和他一起坐船的人中最重的一个j。这样的方法是贪心的,因此它只是让“眼前”的浪费最少。可以分为以下两种情况:
- i不和任何一个人坐同一艘船,那么可以把j拉过来和他一起坐,总船数不会增加(而且可能会减少)。
- i和另外一人k同船。由贪心策略,j是可以和i一起坐船的人中最重的,因此k比j轻。把j和k交换后k所在的船仍然不会超重(因为k比j轻),而i和j所在的船也不会超重(由贪心法过程),因此所得到的新解不会更差。
程序实现
在以上的分析中,比j更重的人只能每人坐一艘船。这样,只需用两个下标i和j分别表示当前考虑的最轻的人和最重的人,每次先将j往左移动,直到i和j可以共坐一艘船,然后将i加1,j减1,并重复上述操作。
例题
题目描述:
n个人,已知每个人体重。独木舟承重固定,每只独木舟最多坐两个人,可以坐一个人或者两个人。显然要求总重量不超过独木舟承重,假设每个人体重也不超过独木舟承重,问最少需要几只独木舟?
原题链接:51Nod独木舟
代码如下:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
constexpr auto maxn = 10010; // 相当于#define maxn 10010
int n, m, in;
vector<int> vec; // 存储人的体重
bool vis[maxn]; // 用于标记上船的人
bool cmp(int a, int b) {
return a > b;
}
int main()
{
ios::sync_with_stdio(false);
cin >> n >> m; // 上船人数和船的承重
for (int i = 0; i < n; i++) {
cin >> in;
vec.push_back(in);
}
sort(vec.begin(), vec.end(), cmp);
int start = 0, end = vec.size() - 1, ans = 0;
while (start < end) {
++ans;
int sum = vec[start] + vec[end];
if (sum <= m) {
vis[start] = vis[end] = true;
start++;
end--;
}
else {
vis[start] = true;
start++;
}
}
if (start == end && vis[start] == false) {
ans++;
}
cout << ans;
return 0;
}
区间相关问题
选择不相交区间
数轴上有n个开区间(ai, bi)。选择尽量多个区间,使得这些区间两两没有公共点。
- 分析
首先明确一个问题:假设有两个区间x,y,区间x完全包含y。那么,选x是不划算的,因为x和y最多只能选一个,选x还不如选y,这样不仅区间数目不会减少,而且给其他区间留出了更多的位置。接下来,按照bi从小到大的顺序给区间排序。贪心策略是:一定要选第一个区间。现在区间已经排序成b1≤b2≤b3…了,考虑a1和a2的大小关系:
- a1>a2,如图8-7(a)所示,区间2包含区间1。前面已经讨论过,这种情况下一定不会选择区间2。不仅区间2如此,以后所有区间中只要有一个i满足a1>ai,i都不要选。在今后的讨论中,将不考虑这些区间。
- 排除了情况1,一定有a1≤a2≤a3≤…,如图8-7(b)所示。如果区间2和区间1完全不相交,那么没有影响(因此一定要选区间1),否则区间1和区间2最多只能选一个。如果不选区间2,黑色部分其实是没有任何影响的(它不会挡住任何一个区间),区间1的有效部分其实变成了灰色部分,它被区间2所包含!由刚才的结论,区间2是不能选的。依此类推,不能因为选任何区间而放弃区间1,因此选择区间1是明智的。
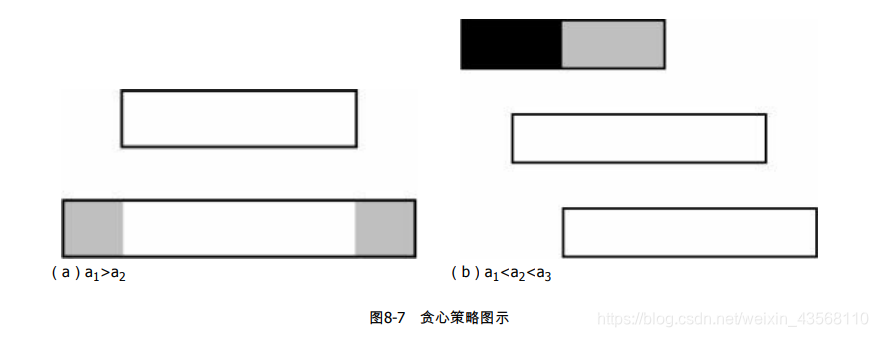
选择了区间1以后,需要把所有和区间1相交的区间排除在外,需要记录上一个被选择的区间编号。这样,在排序后只需要扫描一次即可完成贪心过程,得到正确结果。
例题1
题目描述
X轴上有N条线段,每条线段有1个起点S和终点E。最多能够选出多少条互不重叠的线段。(注:起点或终点重叠,不算重叠)。
原题链接:51Nod不重叠的线段
代码如下:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
typedef struct
{
int s, e;
}Line;
Line L[50005];
bool cmp(Line a, Line b)
{
return a.e < b.e;
}
int main()
{
ios::sync_with_stdio(false);
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> L[i].s >> L[i].e;
}
sort(L, L + n, cmp);
int end = L[0].e;
int ans = 1;
for (int i = 1; i < n; i++) {
if (L[i].s >= end) {
ans++;
end = L[i].e;
}
}
cout << ans;
return 0;
}
例题2(用优先队列解决)
优先队列用法详解(priority_queue)
题目描述
有若干个活动,第i个开始时间和结束时间是[Si,fi),同一个教室安排的活动之间不能交叠,求要安排所有活动,最少需要几个教室?
原题链接:51Nod活动安排问题
代码如下:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
typedef struct
{
int s, f;
}Line;
Line L[50005];
bool cmp(Line a, Line b)
{
return a.s < b.s;
}
int main()
{
ios::sync_with_stdio(false);
int n;
priority_queue<int, vector<int>, greater<int> > myqueue;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> L[i].s >> L[i].f;
}
sort(L, L + n, cmp);
myqueue.push(L[0].f);
int ans = 1;
for (int i = 1; i < n; i++) {
if (L[i].s < myqueue.top()) {
ans++;
myqueue.push(L[i].f);
}
else {
myqueue.pop();
myqueue.push(L[i].f);
}
}
cout << ans;
return 0;
}
区间选点问题
数轴上有n个闭区间[ai, bi]。取尽量少的点,使得每个区间内都至少有一个点(不同区间内含的点可以是同一个)。
- 分析
如果区间i内已经有一个点被取到,则称此区间已经被满足。受上一题的启发,下面先讨论区间包含的情况。由于小区间被满足时大区间一定也被满足,所以在区间包含的情况下,大区间不需要考虑。把所有区间按b从小到大排序(b相同时a从大到小排序),则如果出现区间包含的情况,小区间一定排在前面。第一个区间应该取哪一个点呢?此处的贪心策略是:取最后一个点,如图8-8所示。
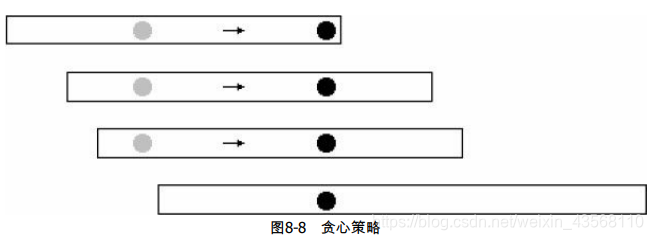
根据刚才的讨论,所有需要考虑的区间的a也是递增的,可以把它画成图8-8的形式。如果第一个区间不取最后一个,而是取中间的,如灰色点,那么把它移动到最后一个点后,被满足的区间增加了,而且原先被满足的区间现在一定被满足。不难看出,这样的贪心策略是正确的。
区间覆盖问题
数轴上有n个闭区间[ai, bi],选择尽量少的区间覆盖一条指定线段[s,t]。
- 分析
突破口仍然是区间包含和排序扫描,不过先要进行一次预处理。每个区间在[s, t]外的部分都应该预先被切掉,因为它们的存在是毫无意义的。预处理后,在相互包含的情况下,小区间显然不应该考虑。
把各区间按照a从小到大排序。如果区间1的起点不是s,无解(因为其他区间的起点更大,不可能覆盖到s点),否则选择起点在s的最长区间。选择此区间[ai, bi] 后,新的起点应该设置为bi,并且忽略所有区间在bi之前的部分,就像预处理一样。虽然贪心策略比上题复杂,但是仍然只需要一次扫描,如图8-9所示。s为当前有效起点(此前部分已被覆盖),则应该选择区间2。
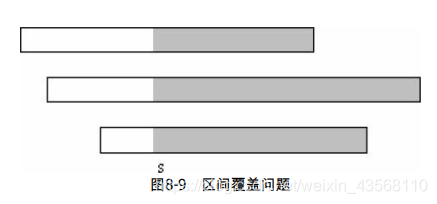
例题
题目描述
给出N条线段的起点和终点,从中选出2条线段,这两条线段的重叠部分是最长的。输出这个最长的距离。如果没有重叠,输出0。
原题链接:51No线段的重叠
代码如下:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
using namespace std;
typedef struct
{
int s, e;
}Line;
Line L[50005];
bool cmp(Line a, Line b)
{
if (a.s < b.s)return true;
if (a.s == b.s && a.e < b.e)return true;
return false;
}
int main()
{
ios::sync_with_stdio(false);
int n;
int a, b;
int Max = 0;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> L[i].s >> L[i].e;
}
sort(L, L + n, cmp);// 按起点的大小排序,若起点相同则按终点
for (int i = 0; i < n; i++) {
int l = 0;
for (int j = i + 1; j < n; j++) { // j代表i的下一个起点
if (L[j].s > L[i].e) break; // 线段无交集
if (L[i].e - L[j].s < Max) break; // 交集小于Max就退出循环
a = min(L[i].e, L[j].e);
b = max(L[i].s, L[j].s);
l = a - b;
if (l > Max)
Max = l;
}
}
cout << Max << endl;
return 0;
}
