1 Yarn 简介
YARN 是 Hadoop2.x 版本中的一个新特性。它的出现其实是为了解决第一代 MapReduce 编程 框架的不足,提高集群环境下的资源利用率,这些资源包括内存,磁盘,网络,IO等。Hadoop2.X 版本中重新设计的这个 YARN 集群,具有更好的扩展性,可用性,可靠性,向后兼容性,以 及能支持除 MapReduce 以外的更多分布式计算程序
1)YARN 并不清楚用户提交的程序的运行机制
2)YARN 只提供运算资源的调度(用户程序向 YARN 申请资源,YARN 就负责分配资源)
3)YARN 中的主管角色叫 ResourceManager
4)YARN 中具体提供运算资源的角色叫 NodeManager
5)YARN 其实就与运行的用户程序完全解耦,就意味着 YARN 上可以运行各种类 型的分布式运算程序,MapReduce 只是其中的一种,Spark、Storm 、flink等运算框架都可以整合在 YARN 上运行,只要他们各自的框架中有 符合 YARN 规范的资源请求机制即可。
6)yarn 就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整 合在一个物理集群上,提高资源利用率,方便数据共享
2 Yarn组件详解
2.1 Container
Container是Yarn框架的计算单元,是具体执行应用task(如map task、reduce task)的基本单位。Container和集群节点的关系是:一个节点会运行多个Container,但一个Container不会跨节点。一个Container指的是具体节点上的计算资源,这就意味着Container中必定含有计算资源的位置信息:计算资源位于哪个机架的哪台机器上。所以我们在请求某个Container时,其实是向某台机器发起的请求,请求的是这台机器上的CPU和内存资源。任何一个job或application必须运行在一个或多个Container中,在Yarn框架中,ResourceManager只负责告诉ApplicationMaster哪些Containers可以用,ApplicationMaster还需要去找NodeManager请求分配具体的Container。
2.2 Resource Manager
负责对各NM上的资源进行统一管理和调度,将AM分配空闲的Container运行并监控其运行状态。对AM申请的资源请求分配相应的空闲Container。主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager)。
调度器(Scheduler):调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位是Container,从而限定每个任务使用的资源量。Scheduler不负责监控或者跟踪应用程序的状态,也不负责任务因为各种原因而需要的重启(由ApplicationMaster负责)。总之,调度器根据应用程序的资源要求,以及集群机器的资源情况,为用程序分配封装在Container中的资源。调度器是可插拔的,例如CapacityScheduler、FairScheduler。(PS:在实际应用中,只需要简单配置即可)
应用程序管理器(Application Manager):ApplicationMaster的主要作用是向ResourceManager申请资源并和NodeManager协同工作来运行应用的各个任务然后跟踪它们状态及监控各个任务的执行,遇到失败的任务还负责重启它。
2.3 Node Manager
Node Manager是每个节点上的资源和任务管理器。它会定时地向Resource Manager汇报本节点上的资源使用情况和各个Container的运行状态;同时会接收并处理来自Application Manager的Container 启动/停止等请求。
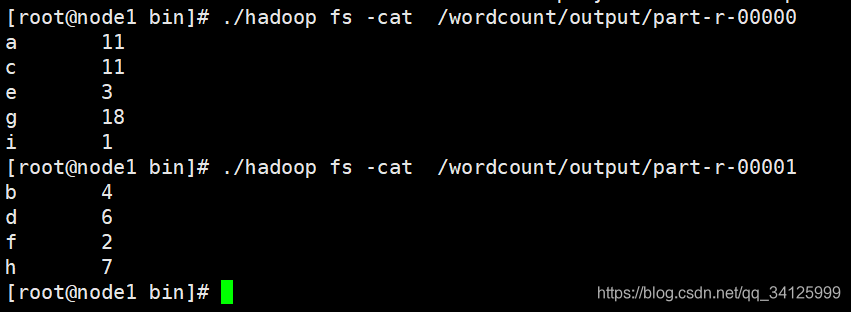
3 yarn的工作流程
步骤1,用户向Yarn提交应用程序,其中包括用户程序、相关文件、启动ApplicationMaster命令、ApplicationMaster程序等。
步骤2,ResourceManager为该应用程序分配第一个Container,并且与Container所在的NodeManager通信,并且要求该NodeManager在这个Container中启动应用程序对应的ApplicationMaster。
步骤3,ApplicationMaster首先会向ResourceManager注册,这样用户才可以直接通过ResourceManager查看到应用程序的运行状态,然后它为准备为该应用程序的各个任务申请资源,并监控它们的运行状态直到运行结束,即重复后面4~7步骤。
步骤4,ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5,一旦ApplicationMaster申请到资源后,便会与申请到的Container所对应的NodeManager进行通信,并且要求它在该Container中启动任务。
步骤6,任务启动。NodeManager为要启动的任务配置好运行环境,包括环境变量、JAR包、二进制程序等,并且将启动命令写在一个脚本里,通过该脚本运行任务。
步骤7,各个任务通过RPC协议向其对应的ApplicationMaster汇报自己的运行状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以再任务运行失败时重启任务。
步骤8,应用程序运行完毕后,其对应的ApplicationMaster会向ResourceManager通信,要求注销和关闭自己。
4 Yarn集群搭建
4.1 环境准备
192.168.0.38 namenode jdk1.8 node1 Resource Manager
192.168.0.39 datanode jdk1.8 node2 Node Manager
192.168.0.40 datanode jdk1.8 node3 Node Manager
192.168.0.41 datanode jdk1.8 node4 Node Manager
4.2 修改配置文件
cd /usr/local/hadoop-2.8.5/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.3 把配置文件复制到其它节点上
scp ./yarn-site.xml node2:/usr/local/hadoop-2.8.5/etc/hadoop/
scp ./yarn-site.xml node3:/usr/local/hadoop-2.8.5/etc/hadoop/
scp ./yarn-site.xml node4:/usr/local/hadoop-2.8.5/etc/hadoop/
4.4 启动yarn
cd /usr/local/hadoop-2.8.5/sbin
#启动,在哪个节点上运行这个命令,这个节点会启动ResourceManager并且读取slaves配置的节点启动DataNode
./start-yarn.sh

4.5 进入UI页面
http://192.168.0.38:8088/cluster/nodes

5 wordcount案例
5.1 数据准备
cd /usr/local/
vim word.txt
a a a a a a a a a a a
b b b b
c c c c c c c c c c c
d d d d d d
e e e
f f
g g g g g g g g g g g g g g g g g g
h h h h h h h
i
cd /usr/local/hadoop-2.8.5/bin
./hadoop fs -mkdir -p /wordcount/input
./hadoop fs -put /usr/local/word.txt /wordcount/input
5.2 java代码
package com.hadoop.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1、读取当前行
String line = value.toString();
//2、切割单词
String[] words = line.split(" ");
//3、统计
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
package com.hadoop.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
IntWritable value = iterator.next();
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
package com.hadoop.mapreduce;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobSubmitter {
public static void main(String[] args) throws Exception {
// 在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份
System.setProperty("HADOOP_USER_NAME", "root");
//======================1 创建Configuration====================
Configuration conf = new Configuration();
// 1.1、设置job运行时要访问的默认文件系统
conf.set("fs.defaultFS", "hdfs://192.168.0.38:9000");
// 1.2、设置job提交到哪去运行
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "http://192.168.0.38");
// 1.3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数
conf.set("mapreduce.app-submission.cross-platform", "true");
//======================2 创建Job===============================
Job job = Job.getInstance(conf);
// 2.1、封装运行时jar的计算class
job.setJarByClass(JobSubmitter.class);
// 2.2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 2.3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 2.4、创建输出路径,如果输出路径已经存在那么删除
Path output = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.0.38:9000"), conf, "root");
if (fs.exists(output)) {
fs.delete(output, true);
}
// 2.5、封装输入输出路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在
// 2.6、封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(2);
//======================3 提交===============================
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : -1);
}
}
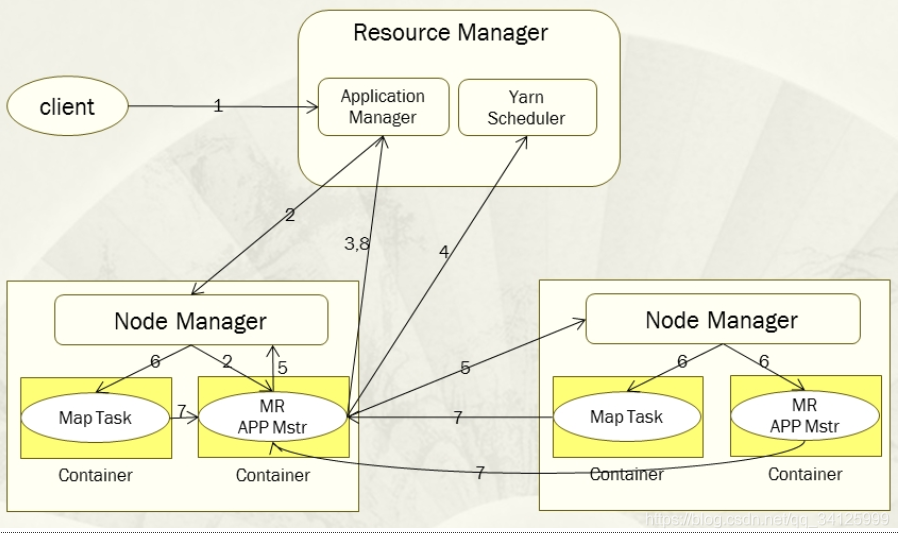
5.3 运行mapreduce
#把打的包上传到/usr/local
cd /usr/local/hadoop-2.8.5/bin
./hadoop jar /usr/local/mr.jar com.hadoop.mapreduce.JobSubmitter
#运行两个reduce任务生成两个文件
./hadoop fs -cat /wordcount/output/part-r-00000
./hadoop fs -cat /wordcount/output/part-r-00001