由于没有相应的Tutorial,学习Milo库的唯一方式就是通过阅读源码来学习。接着说之前的
1.添加命名空间:
命名空间的定义参考的是OPC Foundation官方:
Namespaces are used by OPC UA to create unique identifiers across different naming
authorities. — The NodeId and BrowseName Attributes are identifiers
大意就是说Namespace是通过创建相应的指示量来定义地址空间的浏览名称和结点ID。
看个例子就知道了:
Standard UA Namespace (0:http://opcfoundation.org/UA/) – 加粗的就是一个典型的命名空间,就类似URL
然后是在Server中定义Namespace的方式,examples里面已经有一个预定义好的Namespace:ExampleNamespace
我们在ExampleServer里面找到如下代码:
ExampleNamespace exampleNamespace = new ExampleNamespace(server);
exampleNamespace.startup();
将server传入其中,然后启动对应的命名空间,example里面是(urn:eclipse:milo:hello-world)
如果我们又定义了一个机床的命名空间,那么就在其下添加
CncNamespace cncNamespace = new CncNamespace(server);
cncNamespace.startup();
之后server又会得到另一个命名空间。相应的index如下,我们将断点放在ExampleServer中的这一行:
server.startup().get();
执行一步,或者用Evaluate Expression,我们看到定义的命名空间:
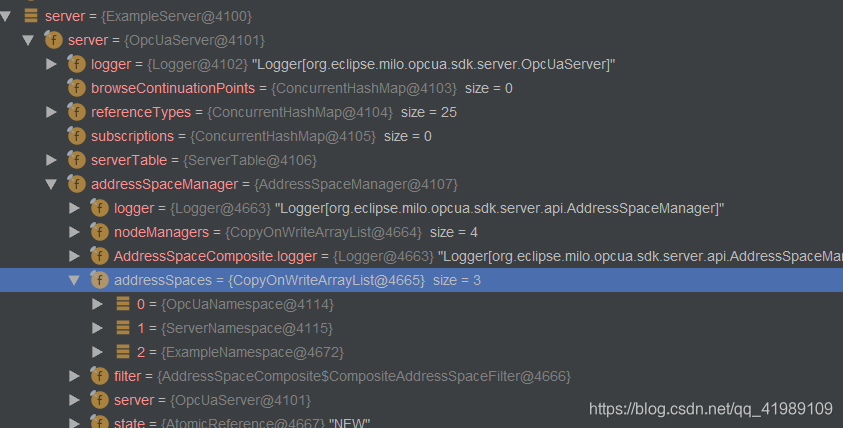
有三个,其中编号0是基础的命名空间,第二个是服务器的命名空间,而第三个则是我们定义的命名空间,命名空间可以依次累加。
2.结点定义
接下来我们深入了解命名空间,也就是OPC UA中结点定义的地方。在ExampleNamespace中,最核心的就是它的onStartup方法:
@Override
protected void onStartup() {
super.onStartup();
可以看到,首先是唤醒了父类汇总的onStartup方法,查看源码可知:
@Override
protected void onStartup() {
super.onStartup();
registerAddressSpace(this);
}
父类的方法主要用于注册地址空间。
folder结点的定义上一篇已经讲过,接下来来看variable结点
addVariableNodes(folderNode);
对应的方法再本类中找到
private void addVariableNodes(UaFolderNode rootNode) {
addArrayNodes(rootNode);
addScalarNodes(rootNode);
addAdminReadableNodes(rootNode);
addAdminWritableNodes(rootNode);
addDynamicNodes(rootNode);
addDataAccessNodes(rootNode);
addWriteOnlyNodes(rootNode);
}
可以发现它添加了很多种类的结点,这里主要介绍ScarlarNode,即单值的标量变量结点
UaFolderNode scalarTypesFolder = new UaFolderNode(
getNodeContext(),
newNodeId("HelloWorld/ScalarTypes"),
newQualifiedName("ScalarTypes"),
LocalizedText.english("ScalarTypes")
);
getNodeManager().addNode(scalarTypesFolder);
rootNode.addOrganizes(scalarTypesFolder);
for (Object[] os : STATIC_SCALAR_NODES) {
String name = (String) os[0];
NodeId typeId = (NodeId) os[1];
Variant variant = (Variant) os[2];
//添加结点的性质
UaVariableNode node = new UaVariableNode.UaVariableNodeBuilder(getNodeContext())
//NodeId需要加在folder结点下面,folder结点又是HelloWorld的子节点
.setNodeId(newNodeId("HelloWorld/ScalarTypes/" + name))
//权限为读写
.setAccessLevel(ubyte(AccessLevel.getMask(AccessLevel.READ_WRITE)))
.setUserAccessLevel(ubyte(AccessLevel.getMask(AccessLevel.READ_WRITE)))
.setBrowseName(newQualifiedName(name))
.setDisplayName(LocalizedText.english(name))
.setDataType(typeId)
//添加结点的类型定义
.setTypeDefinition(Identifiers.BaseDataVariableType)
.build();
node.setValue(new DataValue(variant));
node.setAttributeDelegate(new ValueLoggingDelegate());
//调用NodeManager添加结点
getNodeManager().addNode(node);
//由folder结点添加Orgnize引用
scalarTypesFolder.addOrganizes(node);
}
这段代码的意思是先添加一个folder结点,然后再在folder结点的基础上,添加以下结点
private static final Object[][] STATIC_SCALAR_NODES = new Object[][]{
{"Boolean", Identifiers.Boolean, new Variant(false)},
{"Byte", Identifiers.Byte, new Variant(ubyte(0x00))},
{"SByte", Identifiers.SByte, new Variant((byte) 0x00)},
{"Integer", Identifiers.Integer, new Variant(32)},
{"Int16", Identifiers.Int16, new Variant((short) 16)},
{"Int32", Identifiers.Int32, new Variant(32)},
{"Int64", Identifiers.Int64, new Variant(64L)},
{"UInteger", Identifiers.UInteger, new Variant(uint(32))},
{"UInt16", Identifiers.UInt16, new Variant(ushort(16))},
{"UInt32", Identifiers.UInt32, new Variant(uint(32))},
{"UInt64", Identifiers.UInt64, new Variant(ulong(64L))},
{"Float", Identifiers.Float, new Variant(3.14f)},
{"Double", Identifiers.Double, new Variant(3.14d)},
{"String", Identifiers.String, new Variant("string value")},
{"DateTime", Identifiers.DateTime, new Variant(DateTime.now())},
{"Guid", Identifiers.Guid, new Variant(UUID.randomUUID())},
{"ByteString", Identifiers.ByteString, new Variant(new ByteString(new byte[]{0x01, 0x02, 0x03, 0x04}))},
{"XmlElement", Identifiers.XmlElement, new Variant(new XmlElement("<a>hello</a>"))},
{"LocalizedText", Identifiers.LocalizedText, new Variant(LocalizedText.english("localized text"))},
{"QualifiedName", Identifiers.QualifiedName, new Variant(new QualifiedName(1234, "defg"))},
{"NodeId", Identifiers.NodeId, new Variant(new NodeId(1234, "abcd"))},
{"Variant", Identifiers.BaseDataType, new Variant(32)},
{"Duration", Identifiers.Duration, new Variant(1.0)},
{"UtcTime", Identifiers.UtcTime, new Variant(DateTime.now())},
};
注意这里的有一行代码
node.setAttributeDelegate(new ValueLoggingDelegate());
这里是采用了委托模式,可以看一下这篇博文委托模式讲解
也就是说,实际进行赋值操作的将会是ValueLoggingDelegate定义的对象。可以在对象里面打个断点,然后运行client-Example中的WriteExample,可以看到实际上用的ValueLoggingDelegate中的方法。
其他结点的定义方式大家可以自己去了解,我把比较重要的列一下:
//为结点添加一个建模规则,例子是强制建模,当对象生成的时候必须包含该对象
foo.addReference(new Reference(
foo.getNodeId(),
Identifiers.HasModellingRule,
Identifiers.ModellingRule_Mandatory.expanded(),
true
));
//添加一个类型引用,表示objectTypeNode是BaseObjectType的一个子类
objectTypeNode.addReference(new Reference(
objectTypeNode.getNodeId(),
Identifiers.HasSubtype,
Identifiers.BaseObjectType.expanded(),
false
));
