本文章跟本人前面两篇文章(文章1, 文章2)的思路大体相同,都是使用序列化的数据集来训练RNN神经网络模型,然后自动生成相关的序列化。这篇文章使用莎士比亚诗词作为训练集,使用keras和tensorflow作为深度学习框架,训练具有自动生成莎士比亚风格诗句的神经网络模型。
源码和数据集的下载地址1(需要从头开始训练):https://github.com/liangyihuai/deeplearning_liang/blob/master/src/rnn/dinosaur_name/models/LSTM_Shakespeare.py
源码和数据集的下载地址2(已经训练了350个epoch):https://github.com/liangyihuai/deeplearning_liang/blob/master/src/rnn/dinosaur_name/WritingLikeShakespeare.py
因为本文跟前面两篇文章有比较高的重合率,所以,在本文中,主要讲解输入模型的数据集的格式以及在训练好模型之后自动生成诗词的代码逻辑。
模型的输入数据集和输出数据集的格式、
训练的数据集是莎士比亚诗词(参考下面的小段文字)。因为数据集只是纯文本,不能直接用来作为模型的输入。我们需要构造模型的输入X和输出Y作为我们的训练集。那么如何使用原始的文本数据集来构造X和Y呢?
From fairest creatures we desire increase,
That thereby beauty's rose might never die,
But as the riper should by time decease,
His tender heir might bear his memory:
But thou contracted to thine own bright eyes,
Feed'st thy light's flame with self-substantial fuel,
Making a famine where abundance lies,
Thy self thy foe, to thy sweet self too cruel:
Thou that art now the world's fresh ornamen
构造X和Y
假设下面的图片中的这个字符串表示文本数据集。我们先定义两个变量,一是字符串x的长度Tx=10,另一个表示移动的步长stride=3。按照下面图片所示的方式,我们可以获得下面所示的x和y:

x1 = HelloWorld, y1=d # 向右边滑动3个字符之后进行x2的获取
x2 = loWorldTod, y2=d # 向右边滑动3个字符之后进行x3的获取
x3 = orldTodayI, y3=I # 向右边滑动3个字符之后进行x4的获取
...
以这样的方式滑动完整个诗词的数据集,我们就得到一组x,以及对应的一组y。下面的这段代码描述了这个过程。经过这一步之后,所得到的数据是字符的形式,我们还需要将它们转换成下标(索引),同时进行one-hot形式的编码。具体看下一节。
def build_data(text, Tx = 40, stride = 3):
"""
Create a training set by scanning a window of size Tx over the text corpus, with stride 3.
Arguments:
text -- string, corpus of Shakespearian poem
Tx -- sequence length, number of time-steps (or characters) in one training example
stride -- how much the window shifts itself while scanning
Returns:
X -- list of training examples
Y -- list of training labels
"""
X = []
Y = []
for i in range(0, len(text) - Tx, stride):
X.append(text[i: i + Tx])
Y.append(text[i + Tx])
print('number of training examples:', len(X))
return X, Y
数据向量化
在上一节中,我们得到了如下所示的数据:
x1 = HelloWorld, y1=d # 向右边滑动3个字符之后进行x2的获取
x2 = loWorldTod, y2=d # 向右边滑动3个字符之后进行x3的获取
x3 = orldTodayI, y3=I # 向右边滑动3个字符之后进行x4的获取
...
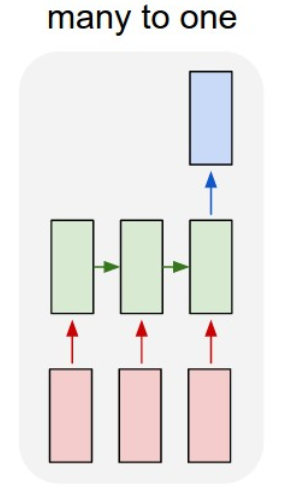
在这一步中我们需要做两件事,一是将字符转换成索引/下标,也就是把字符转换成int型的数字。二是将下标进行one-hot编码。所以,如果X表示所有的输入数据集,那么它的维度表示为(m, Tx, len(chars)),其中,len(chars)表示在所有的数据集中有多少种不同的字符。m表示有多少个训练数据,并且每一个训练数据x是长度为Tx的字符串。类似的,如果Y表示所有的训练的标签数据集,那么它的维度为(m, len(chars)), 所以,该模型是many to one模型。
下面的代码表示如何对字符数据向量化。
def vectorization(X, Y, n_x, char_indices, Tx = 40):
"""
Convert X and Y (lists) into arrays to be given to a recurrent neural network.
Arguments:
X --
Y --
Tx -- integer, sequence length
Returns:
x -- array of shape (m, Tx, len(chars))
y -- array of shape (m, len(chars))
"""
m = len(X)
x = np.zeros((m, Tx, n_x), dtype=np.bool)
y = np.zeros((m, n_x), dtype=np.bool)
for i, sentence in enumerate(X):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[Y[i]]] = 1
return x, y
构建模型
下面的代码表示构建一个LSTM神经网络的学习模型。
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(Tx, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback])
训练完成之后进行预测(或者说是自动生成句子)
本文的代码允许用户输入开头几个字来让模型根据这几个字进行自动生成其它的文字。(如果不明白这句话的意思,可以先执行一下代码),比如,用户输入“I am”, 那么模型就以这个为开头自动生成后面的文字,比如可能会生成“I am handsome and beautiful”。在模型中,每一次x的长度为Tx=40,所以,在最开始的时候,如果用户输入的字符不够40个,那么就是用0来填充。比如,用户输入hello,那么输入模型的第一个x为00000…000hello,其中有35个0。
下面的代码根据模型预测阶段所生成的y值来获取概率最大的数字的下标,使用到了softmax。其它内容请具体看源码。
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
out = np.random.choice(range(len(chars)), p=probas.ravel())
return out
# return np.argmax(probas)
谢谢!
reference
