注:2019-08-27,浪了四五天…‘深入’的看了下Bilstm-CRF的ner结构,有一篇混合半条件随机场的论文复现看的有点崩溃,还是先回来搞搞neo4j
参考:1,cypher文档 || 2,cypher文档
回顾:在笔记1里面最后的问题:create语句创造节点会导致重复,所以一般使用merge语句,两者区别可能是执行速度吧(merge应该会涉及到查找步骤)
1 match
匹配符合条件的节点
1,匹配所有标签为person的节点
match (p:person)
2,根据属性匹配特定的节点
match( p:person {name:"ben shan zhao"})
2 delete
删除节点及其关系
1,删除无关系的单独节点,如果存在关系 报错
match (p:person {name : "ben shan zhao"})
delete p
如果p节点还有外界关系将会删除失败
2,直接暴力删除,不论是否有外界关系
detach delete p
3 count
计算符合条件的节点个数-[因为有的时候,并不需要返回具体对象,只需要其个数]
返回person节点总个数
MATCH (p:Person)
RETURN count(*)
返回有twitter账号的person节点个数
MATCH (p:Person)
RETURN count(p.twitter)
4 collect
返回符合条件的节点集合,下图右列(有种字典的意思)
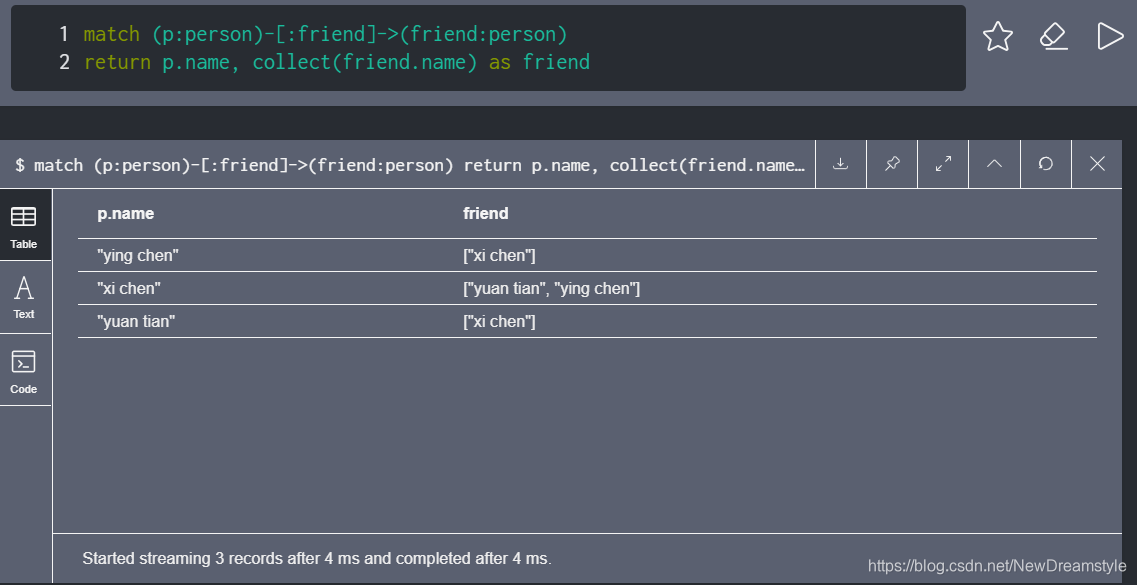
5,with
个人感觉算是一种承上启下的语法
官方的解释:【The WITH clause allows query parts to be chained together, piping the results from one to be used as starting points or criteria in the next.】
1 ,这里给出一个错误案例,下图
create (p:person {name:'yu han guo'})
create (w:person {name:'zhi qiang wu'})
create (z:location {name:'zhe jiang'})
create (n:location {name:'nan tong'})
create (g:location {name:"guang xi"})
with p,w,z ----------------------错误所在,没有连接 n,g
match (c:person {name:'ying chen'})
match (x:person {name:'jin xin chen'})
merge(c)-[:roomate]->(p)
merge(c)-[:roomate]->(w)
merge(x)-[:lived_in]->(z)
merge(p)-[:lived_in]->(n)------------------------创建失败
merge(w)-[:lived_in]->(g)------------------------创建失败
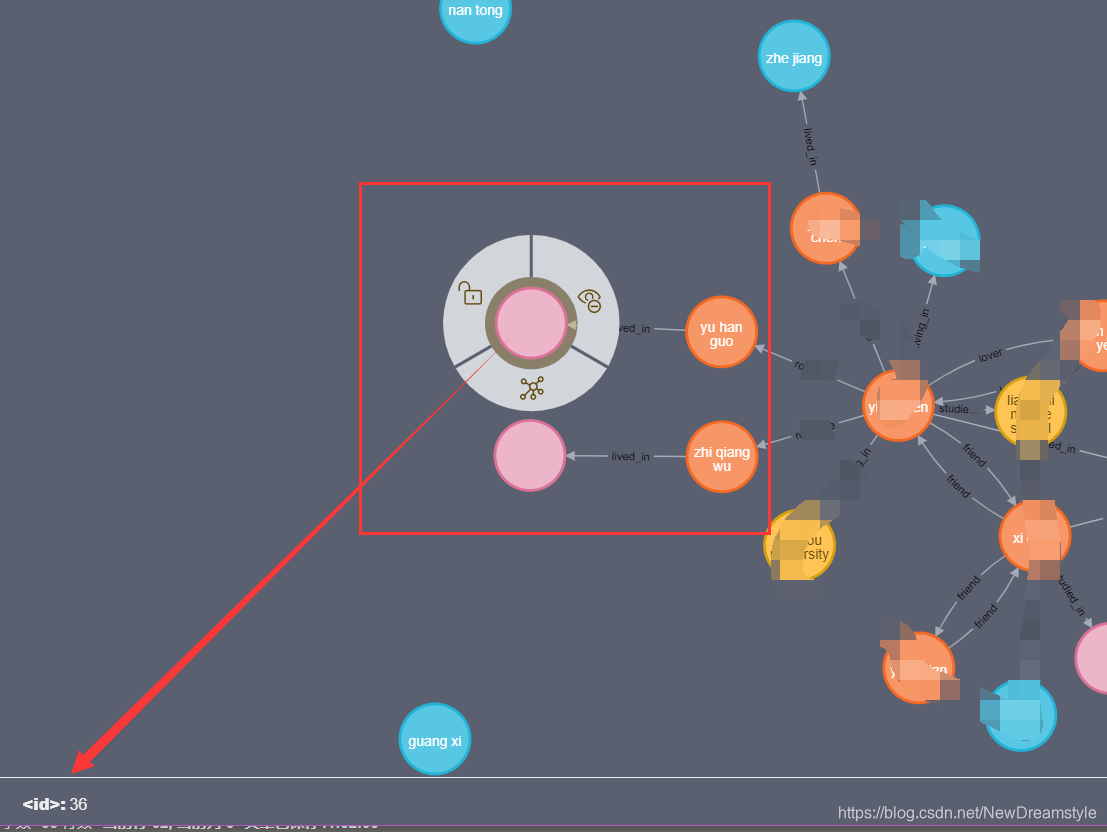
导致出现了两个空白节点,并且无法删除(我目前没找到删除的办法,群里大佬让我删库跑路,哈哈)
2,用WITH设置参数,很有用

6 unwind
与collect相反,将集合展开,就像for 循环,查询符合集合里面的条件的节点
官方解释:【If you have a list that you want to inspect or separate the values, Cypher offers the UNWIND clause. This does the opposite of collect() and separates a list into individual values on separate rows.】
先到这儿吧…
