1. re模块
定义: 在Python中,通过内置的re模块提供对正则表达式的⽀持。正则表达式会被编译成⼀系列的字节码,然后由通过C编写的正则表达式引擎进⾏执⾏。该引擎⾃从Python1.6被内置以来,近20年时间未有发⽣过变化。
re模块支持的正则语法:
1 "."
2 "^"
3 "$"
4 "*"
5 "+"
6 "?"
7 *?,+?,??
8 {m,n}
9 {m,n}?
10 "\\"
11 []
12 "|"
13 (...)
14 (?aiLmsux)
15 (?:...)
16 (?P<name>...)
17 (?P=name)
18 (?#...)
19 (?=...)
20 (?!...)
21 (?<=...)
22 (?<!...)
23 (?(id/name)yes|no)
2. 常见用法
2-1. 常见用法
字符串的查找、替换和分割等各种处理操作:
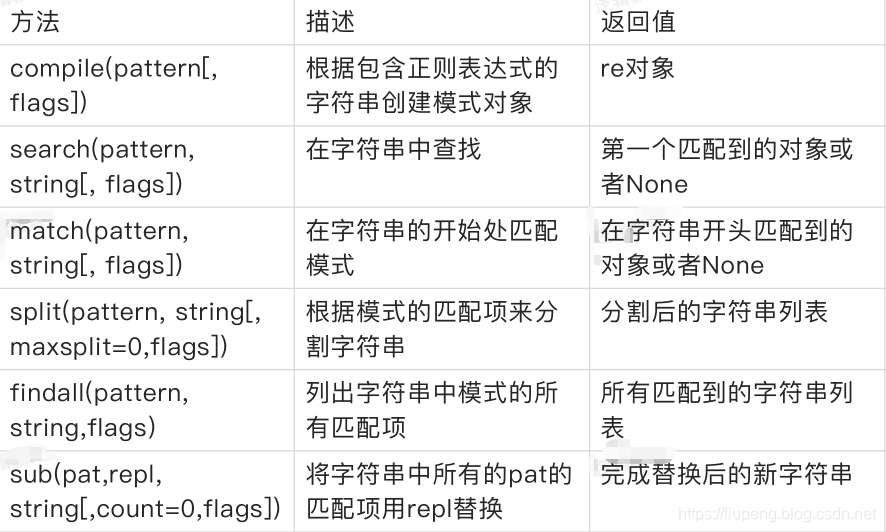
反斜杠的困扰:
与⼤多数编程语⾔相同,正则表达式⾥使⽤\作为转义字符,这可能造成反斜杠困扰。假如需要匹配⽂本中的字符\,那么使⽤编程语⾔表示的正则表达式⾥将需要4个反斜杠\\。前两个和后两个分别⽤于在编程语⾔⾥转义成反斜杠,转换成两个反斜杠后再在正则表达式⾥转义成⼀个反斜杠。为了⽅便我们使⽤个,Python提供了原⽣字符串的功能,很好地解决了这个问题,这个例⼦中的正则表达式可以使⽤r"\“表示。同样,匹配⼀个数字的”\d"可以直接写成r"\d"。有了原⽣字符串,你再也不⽤担⼼是不是漏写了反斜杠,写出来的表达式也更直观。
2-2. 用法详解
2-2-1. compile(pattern,flags=0)
定义: 这个⽅法是re模块的⼯⼚⽅法,⽤于将字符串形式的正则表达式编译为Pattern模式对象,可以实现更⾼效率的匹配。第⼆个参数flag是匹配模式。
说明及用法: 使⽤compile()完成⼀次转换后,再次使⽤该匹配模式的时候就不⽤进⾏转换了。经过compile()转换的正则表达式对象也能使⽤普通的re⽅法。其⽤法如下:
import re
pat = re.compile(r"abc")
pat.match("abc123")
<_sre.SRE_Match object; span=(0, 3), match='abc'>
经过compile()⽅法编译过后的返回值是个re对象,它可以调⽤match()、search()、findall()等其他⽅法,但其他⽅法不能调⽤compile()⽅法。实际上,match()和search()等⽅法在使⽤前,Python内部帮你进⾏了compile的步骤。
re.match(r"abc","abc123).compile()
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
re.match(r"abc","abc123").compile()
AttributeError: '_sre.SRE_Match' object has no attribute 'compile'
2-2-2. flag匹配模式
定义: Python的re模块提供了⼀些可选的标志修饰符来控制匹配的模式。可以同时指定多种模式,通过与符号|来设置多种模式共存。如re.I | re.M被设置成I和M模式。
常见模式:
| 匹配模式 | 描述 |
|---|---|
| re.A | ASCII字符模式 |
| re.I | 使匹配对⼤⼩写不敏感,也就是不区分⼤⼩写的模式 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多⾏匹配,影响 ^ 和 $ |
| re.S | 使 . 这个通配符能够匹配包括换⾏在内的所有字符,针对多⾏匹配 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w,\W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
2-2-3. match(pattern,srtring,flags0)
定义: match()⽅法会在给定字符串的开头进⾏匹配,如果匹配不成功则返回None,匹配成功返回⼀个匹配对象,这个对象有个group()⽅法,可以将匹配到的字符串给出。
用法:
ret = re.match(r"abc","ab1c123")
print(ret)
2-2-4. search(pattern,srtring,flags0)
定义: 在⽂本内查找,返回第⼀个匹配到的字符串。它的返回值类型和使⽤⽅法与match()是⼀样的,唯⼀的区别就是查找的位置不⽤固定在⽂本的开头。
用法:
obj = re.search(r"abc","123abc456abc789")
obj
<_sre.SRE_Match object; span=(3, 6), match='abc'>
obj.group()
'abc'
obj.start()
3
obj.end()
6
1obj.span()
(3, 6)
2-2-5. findall(pattern,srtring,flags0)
定义: 作为re模块的三⼤搜索函数之⼀,findall()和match()、search()的不同之处在
于,前两者都是单值匹配,找到⼀个就忽略后⾯,直接返回不再查找了。⽽findall是全⽂查找,它的返回值是⼀个匹配到的字符串的列表。这个列表没有group()⽅法,没有start、end、span,更不是⼀个匹配对象,仅仅是个列表!如果⼀项都没有匹配到那么返回⼀个空列表。
用法:
obj = re.findall(r"abc","123abc456abc789")
print(obj)
2-2-6. split(pattern, string, maxsplit=0, flags=0)
定义: re模块的split()⽅法和字符串的split()⽅法很相似,都是利⽤特定的字符去分割字符串。但是re模块的split()可以使⽤正则表达式,因此更灵活,更强⼤,⽽且
还有“杀⼿锏” 。
用法:
s = "8+7*5+6/3"
import re
a_list = re.split(r"[\+\-\*\/]",s)
a_list
['8', '7', '5', '6', '3']
split有个参数maxsplit,⽤于指定分割的次数:
a_list = re.split(r"[\+\-\*\/]",s,maxsplit= 2)
a_list
['8', '7', '5+6/3']
2-2-7. sub(pattern, repl, string, count=0, flags=0)
定义: sub()⽅法类似字符串的replace()⽅法,⽤指定的内容替换匹配到的字符,可以指定替换次数。
用法:
s = "i am jack! i am nine years old ! i like swiming!"
import re
s = re.sub(r"i","I",s)
s
'I am jack! I am nIne years old ! I lIke swImIng!'
tips:
使用时,若是列表,需先将其取出来在进行操作
3. 分组功能
3-1. 定义:
定义: Python的re模块有⼀个分组功能。所谓的分组就是去已经匹配到的内容⾥⾯再筛选出需要的内容,相当于⼆次过滤。实现分组靠圆括号(),⽽获取分组的内容靠的是group()、groups(),其实前⾯我们已经展示过。re模块⾥的⼏个重要⽅法在分组上,有不同的表现形式,需要区别对待。
3-2. 各种方法用法参考:
3-2-1. match()方法
不分组时的情况:
import re
origin = "hasdfi123123safd"
# 不分组时的情况
r = re.match("h\w+", origin)
print(r.group()) # 获取匹配到的整体结果
print(r.groups()) # 获取模型中匹配到的分组结果元组
结果:
hasdfi123123safd
()
有分组的情况:
import re
origin = "hasdfi123123safd123"
# 有分组
r = re.match("h(\w+).*(?P<name>\d)$", origin)
print(r.group()) # 获取匹配到的整体结果
print(r.group(1)) # 获取匹配到的分组1的结果
print(r.group(2)) # 获取匹配到的分组2的结果
print(r.groups()) # 获取模型中匹配到的分组结果元组
执⾏结果:
hasdfi123123safd123
asdfi123123safd12
('asdfi123123safd12', '3')
3-2-2. search()方法
有分组的情况:
import re
origin = "sdfi1ha23123safd123" # 注意这⾥对匹配对象做了下调整
# 有分组
r = re.search("h(\w+).*(?P<name>\d)$", origin)
print(r.group())
print(r.group(0))
print(r.group(1))
print(r.group(2))
print(r.groups())
执⾏结果:
ha23123safd123
ha23123safd123
a23123safd12
3
('a23123safd12', '3')
3-2-3. findall()⽅法
不分组时的情况:
import re
origin = "has something have do"
# ⽆分组
r = re.findall("h\w+", origin)
print(r)
执⾏结果:
['has', 'hing', 'have']
有一个分组的情况:
import re
origin = "has something have do"
# ⼀个分组
r = re.findall("h(\w+)", origin)
print(r)
执⾏结果:
['as', 'ing', 'ave']
有多个分组的情况:
import re
origin = "hasabcd something haveabcd do" # 字符串调整了⼀下
# 两个分组
r = re.findall("h(\w+)a(bc)d", origin)
print(r)
运⾏结果:
[('as', 'bc'), ('ave', 'bc')]
4. 拆分多种分隔符的字符串方法:
问题:
- s = ‘ab;cd|efg|hi|hi,jkl\topq;str,ubw\asyd’
- 其中<,>,<;>,<|>,<\t> 都是分隔符号,如何处理?
方法1: 连续使⽤str.split()⽅法,每次处理⼀种分割符号
def mySplit(s,ds):
res = [s]
for d in ds:
t = []
list(map(lambda x:t.extend(x.split(d)),res))
res = t
return res
s = 'ab;cd|efg|hi|hi,jkl\topq;str,ubw\x07syd'
print(mySplit(s,',;|\t'))
如果出现连续的分割符号,会出现空字符的情况,这时候如果我们想去掉空字符串。
return [x for x in res if x]
⽤列表推导式可以完成这个需求。
方法2: 正则表达式的re.split()⽅法,⼀次性拆分字符串
import re
re.split(r'[,;\t|+',s)
案例:
某软件要求,从⽹络抓取各个城市⽓温信息,并依次显示
北京:15-17
天津:17-22
⻓春:12-18
如果⼀次抓取所有城市天⽓再显示,显示第⼀个城市⽓温时,有很⾼的延迟,并且浪费存储空间,我们期望以⽤时访问的策略,并且能把所有城市⽓温封装到⼀个对象⾥,可⽤for语句进⾏迭代,如何解决?
import requests
def getWeather(city):
r = requests.get('http://wthrcdn.etouch.cn/weather_mini?city='+city)
data = r.json()['data']['forecast'][0]
return '%s:%s,%s'%(city,data['low'],data['high'])
print(getWeather('北京'
