
看看文章的研究机构就知道这不是一篇简单的文章,本文在之前多种相关的预训练模型的基础上,提出了一种基于DAE的Seq2Seq预训练模型。模型整体上采用标准的基于Transformer的机器翻译模型架构,既和之前的预训练模型存在一定的联系,同时又指出了两种最为有效的对输入加噪的方法,最后通过实验证明了模型在文本生成上的卓越性能(特别是在文本摘要任务上取得了SOTA),同时也指出BART在阅读理解和机器翻译中同样可以取得不俗的效果。
随着数据集获取的便捷性和算法的快速进步,自然语言处理在最近几年取得了很大的发展,虽然很多的任务在学术上都取得了不错的效果,但真正落地到生产生活中往往效果差强人意。然而世界总是在一直前进,我们在看到现有问题的同时,更要认可目前已取得的诸多成就。
以BERT、GPT为代表的诸多强大的预训练模型显示,深层的模型借助海量的数据和强大的算力进行预训练后,模型在下游诸多的任务上效果可以出现显著的提升。例如:GPT适用于文本生成任务,而BERT更适合文本分类等相关任务,如何将预训练模型结合到具体的任务中逐渐成为了一种新范式。
而本文的BART总结了已有的多种预训练方式,并使用了两种最为有效的方式在海量的数据上训练基于多层Transformer的模型,通过在多个标准数据集上进行实验证明了BART的优越性。
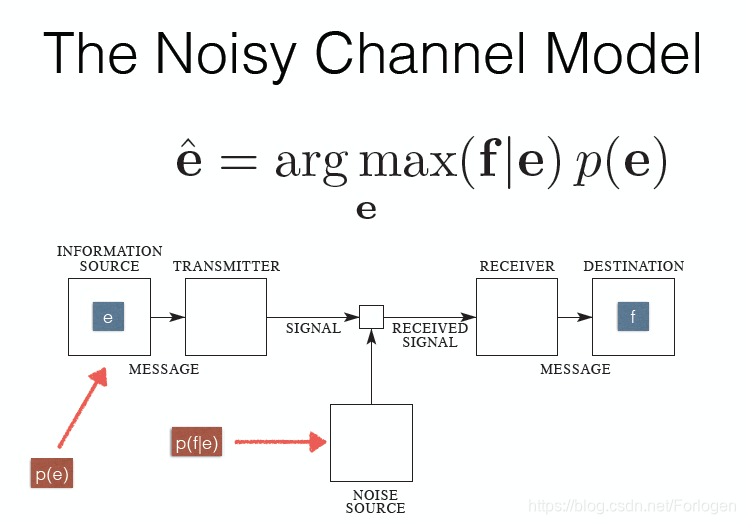
BART的思想来自于去噪自编码器(Denoising Auto-encoder,DAE),即在Encoder的输入中通过不同的方式加入噪声,希望Decoder可以重建加噪的文本。另外这种思想和信息论中的Noisy Channel Model也有一定的相似之处,不同之处在于加噪的环节。
首先我们来看一下BART中使用的加噪方法和BERT、GPT中使用的方法有何区别,同时对比一下它们效果的优劣。BERT主要采用的是Mask Language Model和Predict Next Sentence两种方式来进行预训练,但在BERT之后的研究指出后一种方式对于预训练的效果影响很小,所以这里主要回顾一下前一种方式。
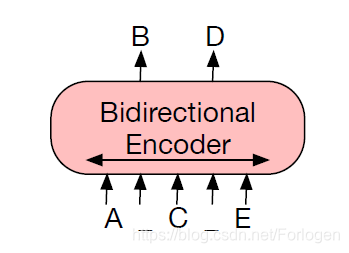
BERT中的MLM采用随机选择token进行mask,这里根据不同的概率使用不同的方式填充mask的位置([MASK]、random token或not change)。基于双向Transformer的BERT独立的预测每一个mask掉的token,这也导致了BERT不太适合于文本生成类任务。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
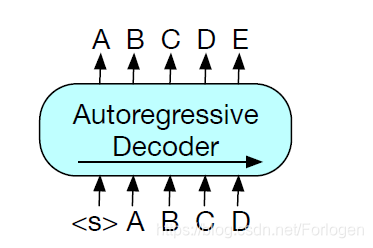
GPT倔强的采用基于单向Transformer的模型架构方式,通过自回归的方式预测下一时刻应该出现的token,这样的方式和生成任务正好是契合的,因此也决定了它在文本生成中的优异效果。但是它天生单向的特性使得GPT只能依赖于左面的内容,因此GPT无法学习到双向的交互。
BART采用在机器翻译中广泛使用的Seq2Seq的架构方式,它使用双向的Encoder来编码采用mask处理后的文本,然后使用基于自回归的Decoder来预测mask的部分,希望可以很好的重建原始文本。在fine-tune阶段使用无损的文本作为Encoder和Decoder的输入,最后使用Decoder最后一个隐状态的表示作为输入文本的表示。
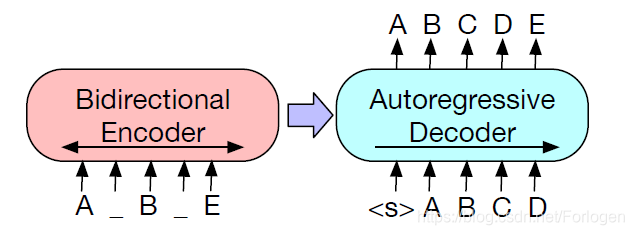
其中mask的部分不是只mask单个的token,而是随机的选择某一部分的tokens进行连续的mask,这种方式类似于同样出产于FacebookAI的SpanBERT中预训练的方式。
SpanBERT: Improving Pre-training by Representing and Predicting Spans
SpanBERT github
此外文本还介绍了其他的几种其他加噪的方式
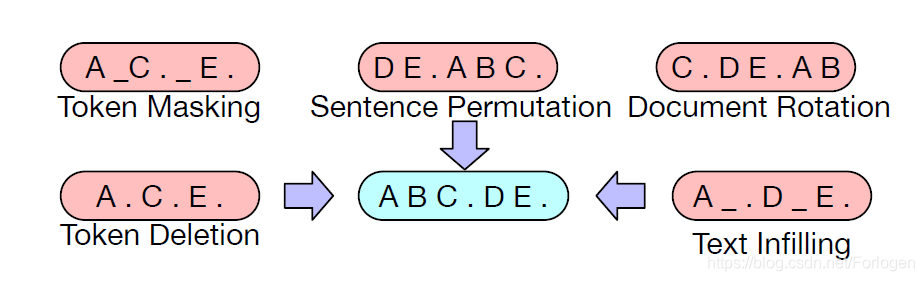
如:
- Token Deletion:随机的删除输入中的tokens,只需要决定tokens的位置即可
- Text Infilling:从泊松分布中采样一段长度,然后使用[MASK] 替换选择的部分,希望摩西可以学习到某一段文本中多少tokens是被替换的
- Sentence Permutation:随机的打乱句子的顺序,这也是XLNet中主要采用的预训练方式
- Document Rotation:文本内部的旋转,希望模型学习到如何识别文档的开始之处
当模型预训练结束之后,在下游不同的任务中使用时需要根据具体的任务进行fine-tune,文中主要介绍了四种:
- Sequence Classification :Encoder和Decoder端接收同样的输入,将Decoder最后一个隐状态的表示送到MLP组成的分类器中进行分类。在BERT中采用的是使用[CLS]的表示向量作为以它为开头的序列的表示。本文中又加入了一个end,这样Decoder就可以从完整的输入中选择关注Encoder的哪些状态
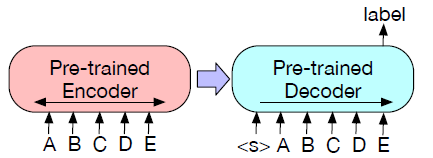
- Token Classification :使用decoder最顶层的隐状态作为每个词的表示,然后用获得的表示进行后续的分类
- Sequence Generation:因为BART的Decoder采用自回归的方式进行训练,它和语言建模的方式是一致的,因此可以很好的使用用文本生成任务,例如对话生成和文本摘要等
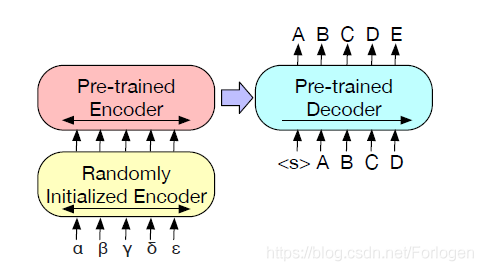
- Machine Translation:BART整体上就是采用了标准的NMT的Seq2Seq的架构方式,所以天生适合NMT。本文将BART整体上看做一个预训练的Decoder,使用一个随机初始化的Encoder代替传统的Embedding层,模型仍可进行端到端的训
实验部分作者首先对比了BART和不同的语言建模方式之间的效果,从结果中可以看出,BART的方式在不同的数据集上效果都优于之前的方式,特别是Text filling可以取得更好的结果。
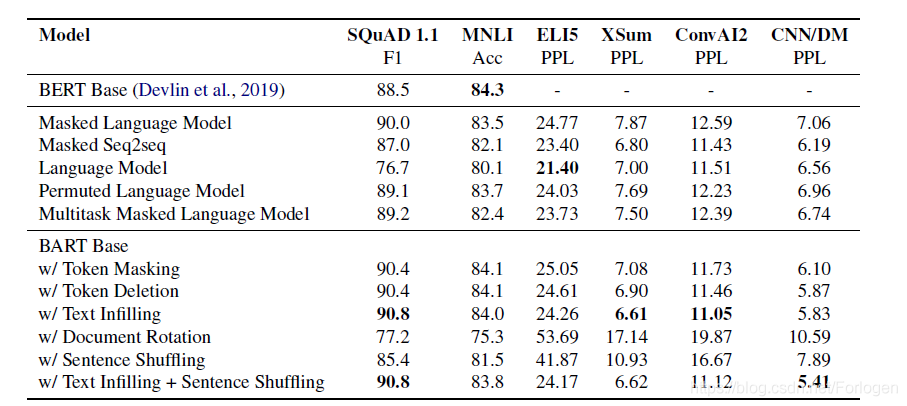
在阅读理解任务中,BART的效果和XLNet、RoBERTa相差不大,而且广泛的优于BERT和UNILM。实验结果证明,Decoder单向的训练方式对于最终的效果影响并不大。
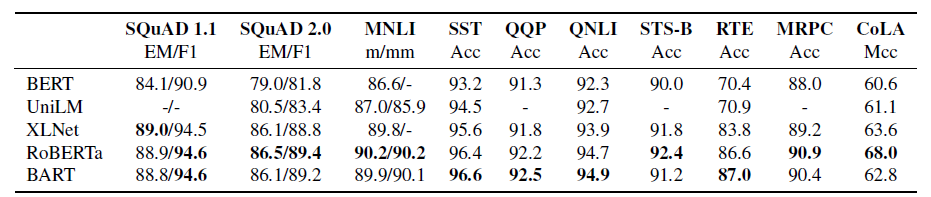
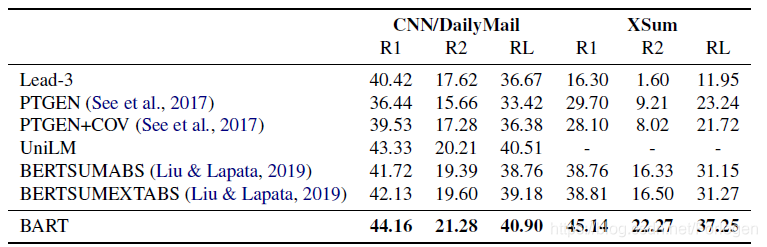
在文本摘要任务中,BART在CNN/DailMail和XSum两个数据集上达到了SOTA,特别是以较大的差距超过了今年EMNLP上的BERTSum。
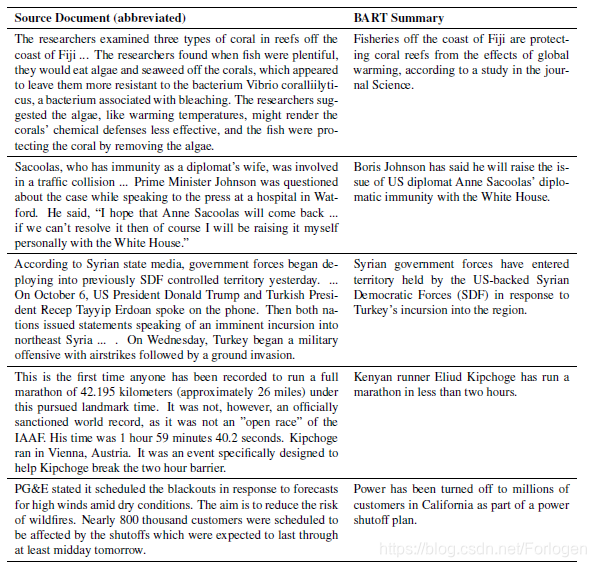
而且从文中给出的摘要示例中可以看出,BART生成的摘要在语法和可读性上都要更好。
本文通过大量的实验证明,重建加入噪声的输入对于预训练模型和下游的任务十分重要,如何设计出更好的加噪方法是一个未来的研究热点。
