自己配置成功hadoop3.x后顺便写了个shell脚本,开始只是好玩而已,没想到后面派上了大用场,很多同学配置半天各种错误,后面运行了我这脚本后都很快把hadoop跑起来了,快的5s,慢点的30s。码云地址:hadoop-install.sh。用法及注意事项里面都写了,自己用编辑器查看。deepin,ubuntu都可以
。centos,fedora支持不是很好,只有一部分能跑起来(比如笔记本上的centos7不能跑起来,但是云端的centos7服务器却能一次性跑起来)
自动安装如下
由于最大只能上传5M的gif,所以只录了一部分,反正最后结果如下
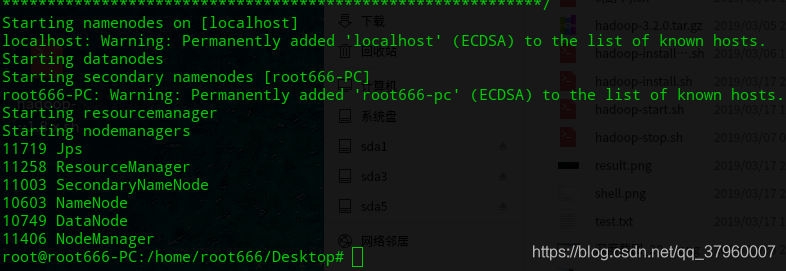
可以看到进程都启动了
卸载配置
如果不想用脚本的配置了,还原配置的方法是:1.清除/tmp目录下的所有有关hadoop的文件 2.清除root的 ~/.ssh目录下生成的相关密钥数据 3.删除hadoop安装的目录
如果你仍然不是很清楚,之前也没有搞过什么其他重要配置,可以直接3步还原:

1. rm -rf /user/local/hadoop (如果hadoop启动了,先stop后再执行,记得多stop几遍确保完全关闭,文件在hadoop的sbin目录下,叫stop-all.sh)
2. rm -rf ~/.ssh/*
3. rm -rf /tmp/*
关于一些其他问题
如果确实是deepin或者ubuntu,又执行脚本失败,那可能是你之前的hadoop配置没删干净,还有种就是因为系统升级出了点看似不影响的小问题,然后确确实实导致hadoop启动失败,哪怕是执行hadoop -version也会报conf_dir不完整,或是log4j.properties的警告,又或是invalid yarn等错误,而且网上相关的资料和解决方案都不是很好,因为升级导致的问题还是建议重装一下。但是一般情况下还是能一次性成功的
(额外:由于5M的上传限额,gif录了四五次,每录一次gif都要卸载一次hadoop,清理一些配置,后面卸载的太频繁导致残留有hadoop的进程关不掉,最后还得重启,制作不易,如果有帮助,还请支持下呗)
