一、结构体的类型与变量定义
使用UDT时都是先定义类型再使用,使用结构体也一样:先定义结构体类型再用类型定义变量,有以下两种使用方式:
1.1 方式一:类型和变量独立定义
struct student
{
char name[20];
int age;
};
struct student s1;
注意:类型一般定义在主函数外面,变量根据实际需求来决定定义在哪里。
1.2 方式二:类型和变量同时定义
struct student
{
char name[20];
int age;
}s1;
以上代码段在定义结构体类型struct student的同时也定义了一个类型为struct student的变量s1,注意与以下代码段区分:
typedef struct student
{
char name[20];
int age;
}s1;
上述代码段一下定义了两个类型名:struct student和s1;如果区分不开上面两个代码段,建议先去看一下typedef的应用
二、结构体中元素的访问
2.1 下标式访问
在C语言中规定:
- 当变量为结构体类型时,使用
.来访问元素- 当为结构体指针类型时,使用
->访问元素
struct student
{
char name[20];
int age;
};
int main(void)
{
struct student s1, *s2;
s2 = &s1;
s1.age = 20;
printf("s1.age = %d\n", s1.age);
s2->age = 21;
printf("s1.age = %d\n", s1.age);
(*s2).age = 19;
printf("s1.age = %d\n", s1.age);
return 0;
}
测试结果从略。
2.2 指针式访问
其实,不管是数组还是结构体,在C语言内部都是通过指针来访问的。只是因为结构体的指针访问很麻烦,所以在实际应用中只用下标访问,但是,指针访问也是非常有必要去掌握的(指针都不会那还会个P的C语言啊)!!!先不多说,直接上测试代码:
2.2.1 测试代码
#include <stdio.h>
typedef struct struct_test1
{
int a;
double b;
char c;
}ST1;
int main(void)
{
ST1 st1;
st1.a = 203;
st1.b = 2.03;
st1.c = 'b';
printf("st1.a = %d\n", st1.a);
int *p1 = (int *)&st1;
printf("*p1 = %d\n", *p1);
printf("st1.b = %lf\n", st1.b);
double *p2 = (double *)((char *)&st1 + sizeof(double));
printf("*p2 = %lf\n", *p2);
printf("st1.c = %c\n", st1.c);
char *p3 = (char *)((char *)&st1 + 2 * sizeof(double));
printf("*p3 = %c\n", *p3);
return 0;
}
2.2.2 测试结果
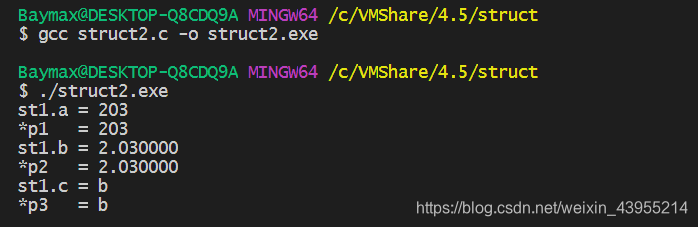
理解数组的指针式访问的同伴门基本上都能看出点东西(如果没看出来的话就面壁吧),这里不解释为什么地址加的是sizeof(double),后面讲了内存对齐大家就都清楚了。下面解释一下两个东西:
1. int *p1 = (int *)&st1;中对&st1进行强制类型转换是因为&st1是ST1 *类型的。
2. double *p2 = (double *)((char *)&st1 + sizeof(double));中为什么对&st1进行强制类型装换呢?(其实明白int *p; p ++;是什么意思的同伴们应该都能看明白)。&st1是ST1 *类型的,如果进行&st1 ++运算,其地址会位移sizeof(ST1)个字节。但是我们实际需要访问的是st1.b这个元素,实际只需偏移sizeof(double)个字节,所以我们将ST1 *类型的指针变量转化为char *类型的(char本身长度为一个字节,可消除附加的偏移量)
三、结构体的内存对齐
结构体中元素的访问本质上还是通过指针方式的,结合元素在整个结构体中的偏移量和这个元素的实际类型就可以对一个元素进行精确访问。但是实际上结构体元素的偏移量往往没有我们想象中的那么简单,因为结构体中每个元素所占的字节数和其本身类型的字节数不一定是一样的(char在结构体中可能只占一个字节,也可能是4个字节也可能8字节),这就涉及到一个内存对齐的问题。
3.1 结构体为什么要内存对齐
- 硬件本身有物理上的限制,内存对齐会大大提升访问效率
Cache的一些缓存特性、MMU、LCD的一些内存依赖特性要求内存对齐
3.2 结构体对齐规则和运算
3.2.1 结构体默认的对齐规则
- 64位操作系统上64位编译器:默认8字节对齐
- 64位操作系统上32位编译器:默认8字节对齐
- 32位操作系统上32位编译器:默认4字节对齐
- 32位操作系统上64位交叉编译:没测过…
3.2.2 结构体对齐的要求
以下两点是对于64位操作系统上64位编译器:默认8字节对齐而言的,如果是4字节对齐,只需要将8改成4即可:
- 结构体整体本身安置在
8字节对齐处,结构体对齐后的大小必须是8的倍数- 结构体中每个元素占的字节大小是自身对齐参数的整数倍
以下是32/64位Linux上GCC编译环境下各类型变量的自身对齐参数

编译器考虑结构体存放时,以满足以上2点要求的最少内存需要来存放。
3.2.3 具体分析
测试结构体一
如2.2.1测试代码中的结构体
#include <stdio.h>
typedef struct struct_test1
{
int a;
double b;
char c;
}ST1;
int main(void)
{
printf("sizeof(ST1) = %d\n", (int)sizeof(ST1));
int *p = NULL;//根据指针长度来辨别编译器和操作系统位数
printf("sizeof(p) = %d\n", (int)sizeof(p));
return 0;
}
64位操作系统上的编译结果

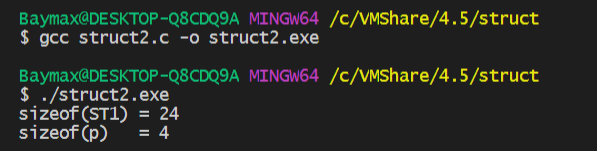
64位操作系统上默认是8字节对齐,整体所占字节数分析如下:
- 首先整个结构体本身安置在
8字节对齐处,这个是由编译器保证的。- 然后是第一个元素
a,a的开始地址就是整个结构体的开始地址,所以自然是8字节对齐的。但是a的结束地址要由下一个元素具体决定- 之后是第二个元素
b,b为double型的,自身对齐长度是8,所以不能自接放在a的后面,也就是说a需要另外填充4个字节空间再结束,然后放b,由于b本身就是对齐的,所以无需另外填充,直接结束- 直接放
c,c放完之后也不能自接结束,因为要保证整个结构体大小是8的整数倍,所以c后面需填充7个字节的内存空间。
如下图所示(实际上的内存是连续分布的):
所以sizeof(ST1) = (4 + 4) + 8 + (1 + 7) = 24;
32位操作系统上的编译结果
分析过程和上面是一样的,这里给出图示:

这里sizeof(ST1) = 4 + 2 * 4 + (1 + 3) = 16;
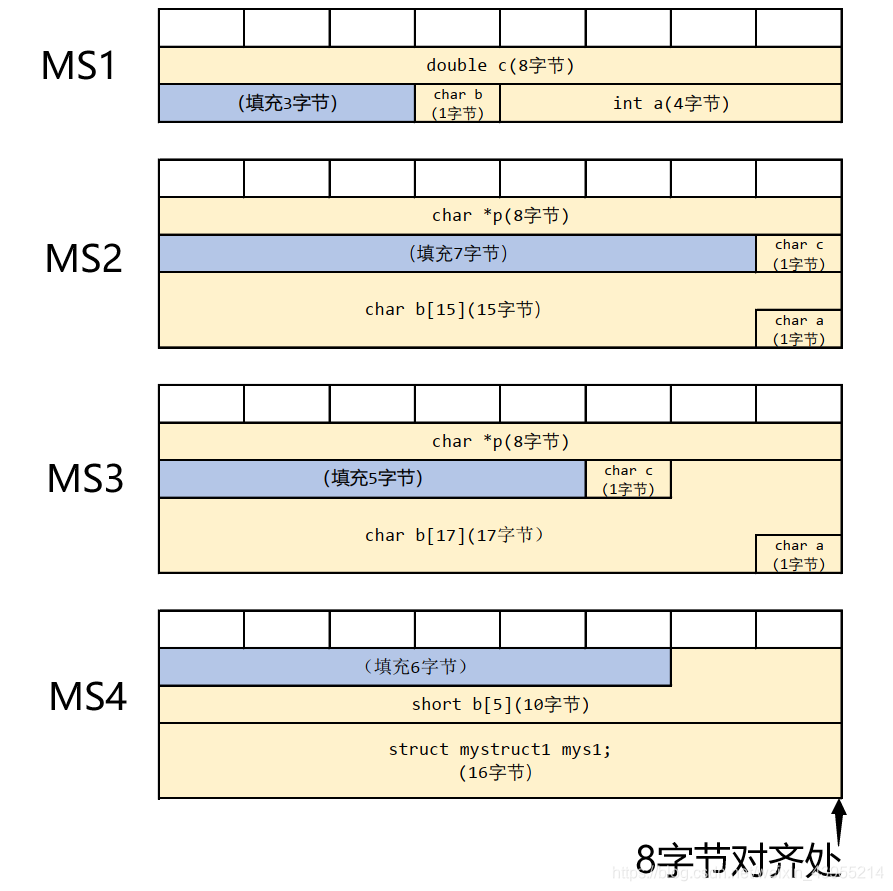
测试结构体二:基于64位操作系统64位编译器
#include <stdio.h>
typedef struct mystruct1
{
int a;
char b;
double c;
}MS1;//16
typedef struct mystruct2
{
char a;
char b[15];
char c;
char *p;
}MS2;//(1+15)+(1+7)+8 = 32
typedef struct mystruct3
{
char a;
char b[17];
char c;
char *p;
}MS3;//(1+17+1+5)+8 =32
typedef struct mystruct4
{
struct mystruct1 mys1;
short b[5];
}MS4;//32
int main(void)
{
printf("sizeof(MS1) = %ld\n", sizeof(MS1));
printf("sizeof(MS2) = %ld\n", sizeof(MS2));
printf("sizeof(MS3) = %ld\n", sizeof(MS3));
printf("sizeof(MS4) = %ld\n", sizeof(MS4));
return 0;
}
以下为测试结果:
以下为图解分析:对于数组,我们只需要将其先拆分成一个个独立类型的数再整合即可,着重看一下MS2和MS3。
结
关于默认的字节对齐方式就阐述到这里,接下来我会再写两篇博文分别阐述按需进行内存对齐:
1.编译指令#pragma pack的简单使用
2.用__attribute__()指令设置类型属性
