1.数据来源
今天分析的是国家统计局网站上的人口信息。
主要内容如下:
1.爬取1949-2019年的总人口数、男性人口、女性人口、城镇人口、乡村人口、人口出生率、人口死亡率、人口自然增长率、0-14岁人口、15-64岁人口、65岁及其以上人口、总抚养比、少儿抚养比、老年抚养比。
2.对爬取数据进行分析。分析内容主要有总人口、男女人口比例、人口城镇化、人口增长率。
3.其中会掺杂一些基本常识的介绍。
2.数据爬取
首先看一下我们爬取的网站,这是由国家统计局提供的网站,里面包含很多国家公开的数据信息。
2.1 请求单页数据
在国家数据网站中,有从新中国成立到2018年的人口相关数据。
在人口数据中,有三项是我们需要的数据:总人口、增长率、人口结构。
我们按F12查看一下请求的链接,然后复制链接使用requests请求数据。
链接是:http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=%5B%5D&dfwds=%5B%5D&k1=1580908890337&h=1
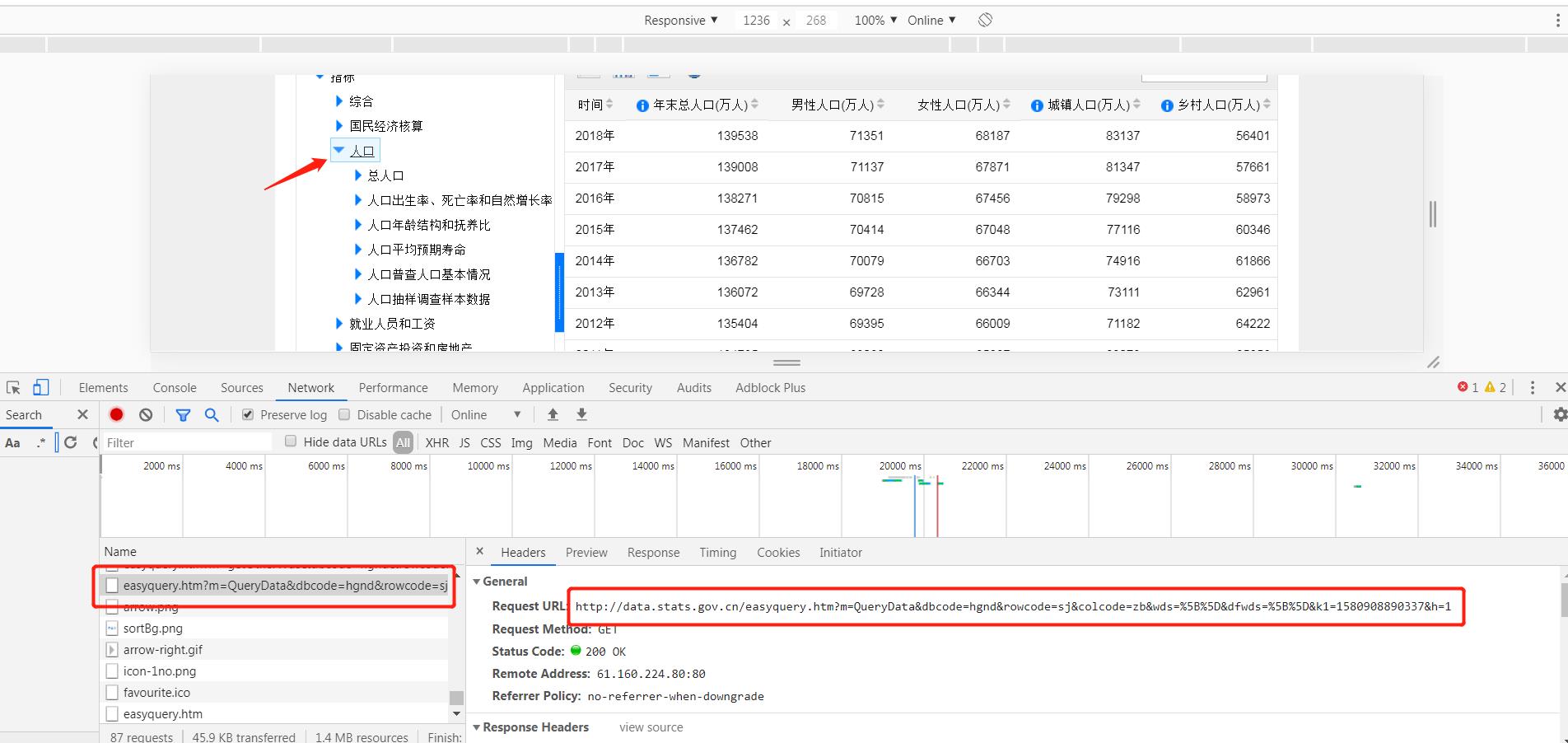
我们使用一个简单的get请求,就把数据获取了,而且返回的直接是json数据!
def spider_population():
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=%5B%5D&dfwds=%5B%5D&k1=1580908890337&h=1'
response = requests.get(url)
print(response.json())
spider_population()

2.2分页数据
我们此次的目的是抓取从新中国至今的所有人口数据,而页面中最多可以获取近20年的数据,所以我们需要分析网页请求中关于分页的参数。
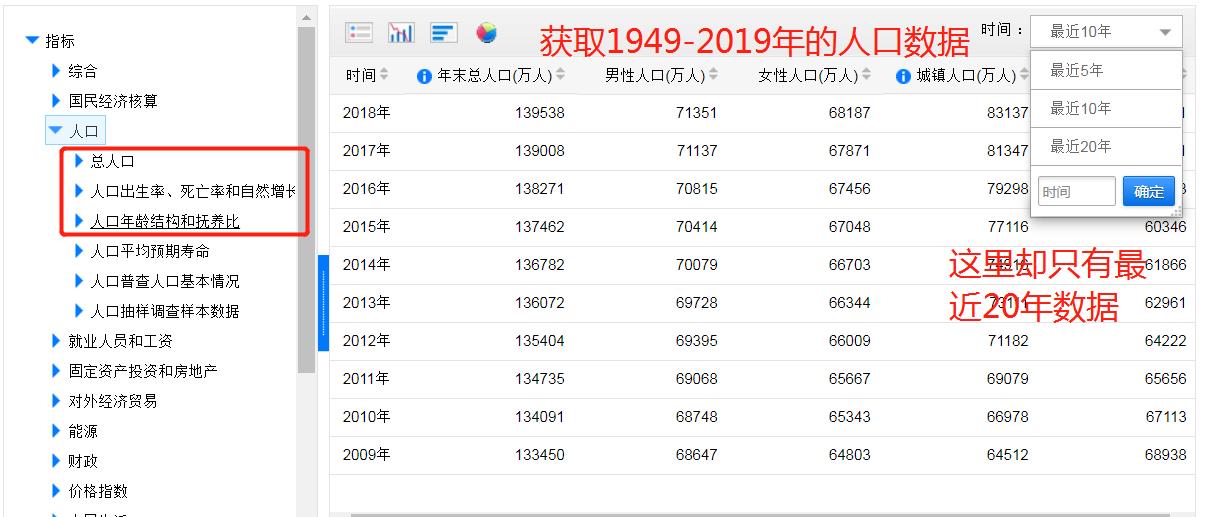 分析请求参数发现主要有两个参数:
分析请求参数发现主要有两个参数:zb、sj,分别表示指标和时间。
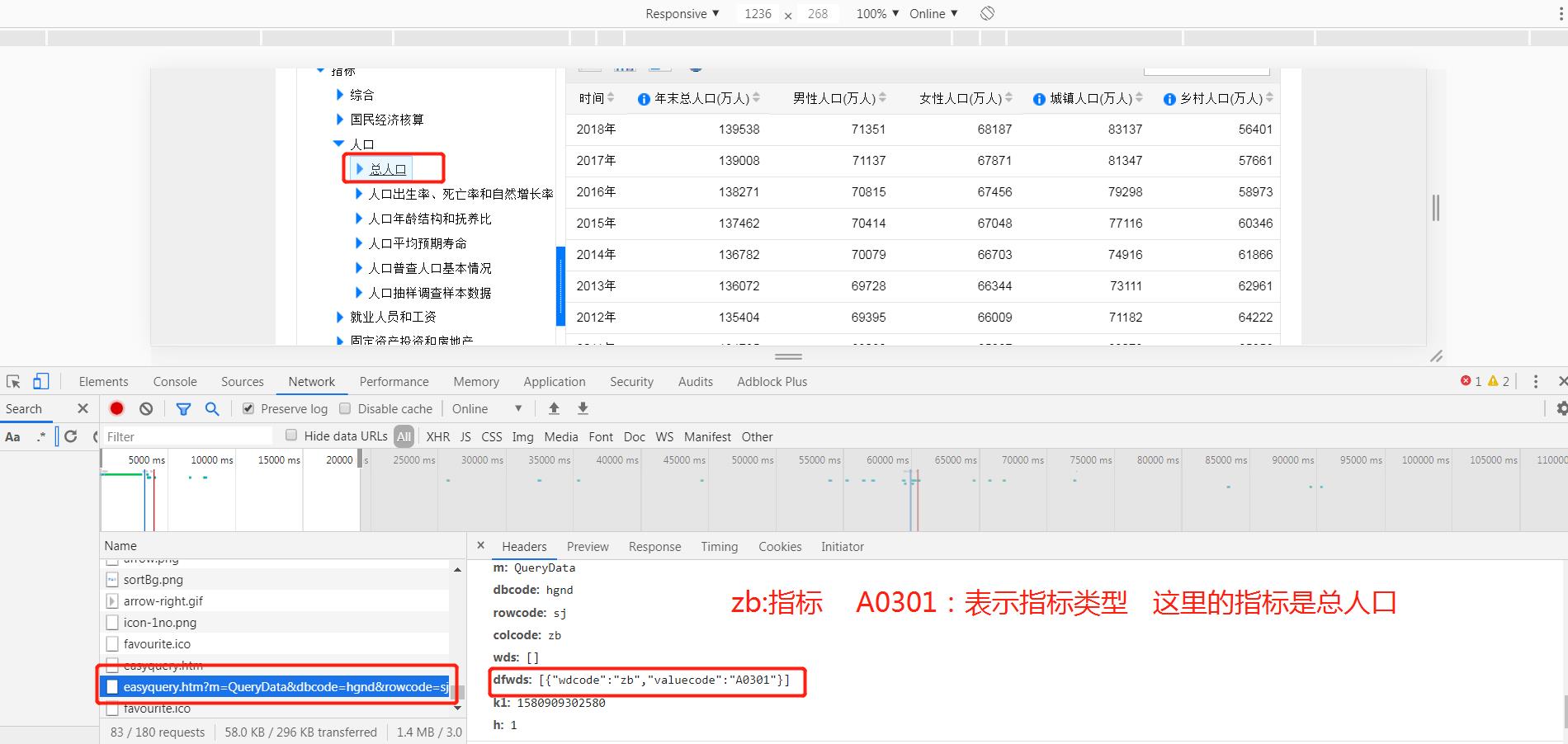
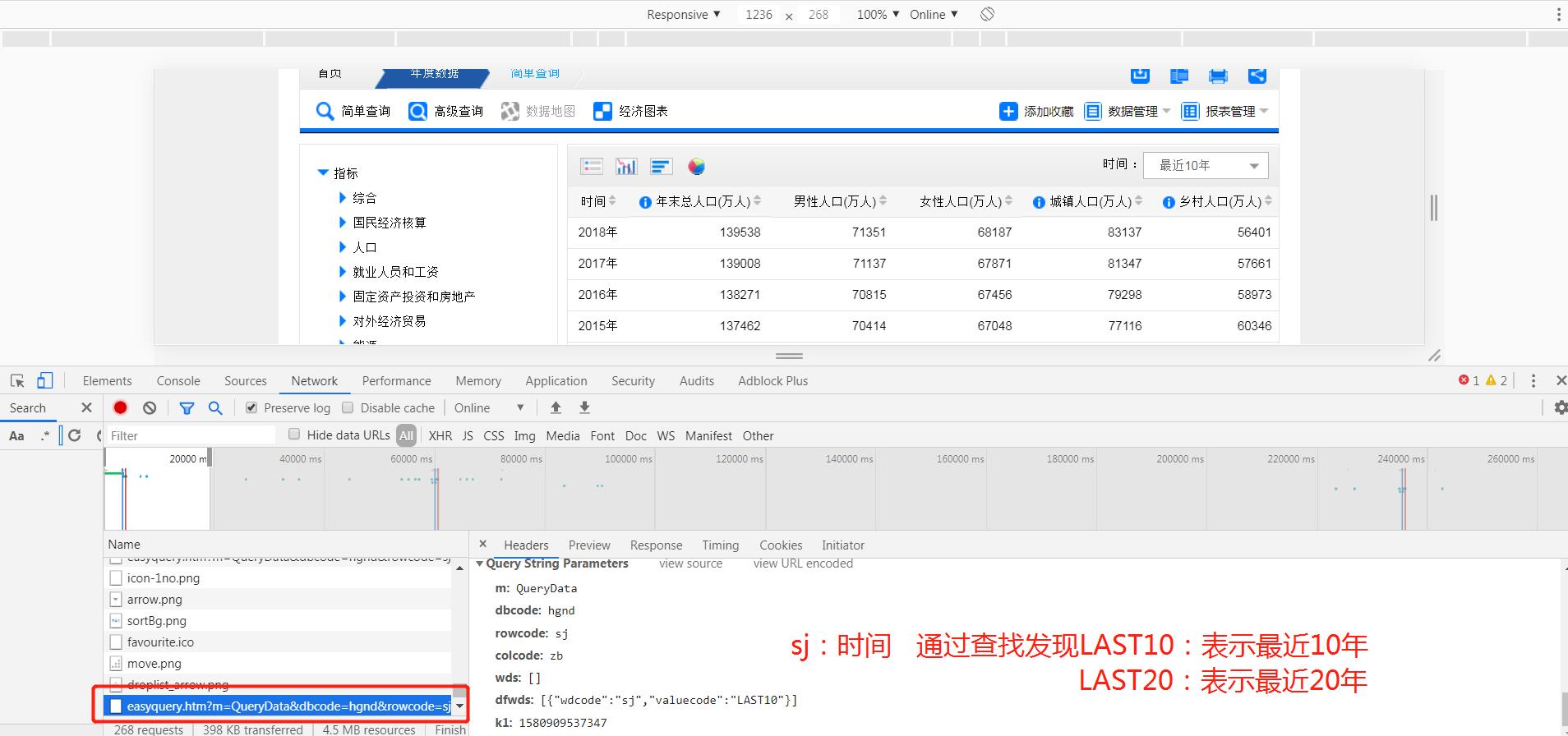
参数:sj=LAST0,表示近10年,于是猜想:sj=LAST70 是不是就可以获取70年的数据呢?
经过代码,发现确实可以找到70年的数据。
def spider_population():
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1))
print(response1.json())
spider_population()

然后我们再将zb参数更换,获取到所有的数据!
def spider_population():
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1))
response2 = requests.get(url.format(dfwds2))
response3 = requests.get(url.format(dfwds3))
spider_population()
3.保存Excel
获取到数据之后,我们先将数据清洗,提取出我们需要的数据,然后整理保存到Excel中,数据处理方面我们仍然使用pandas。
import pandas as pd
import requests
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = 'population.xlsx'
def spider_population():
"""
爬取人口数据
"""
# 请求参数 sj(时间),zb(指标)
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
# 将所有数据放这里,年份为key,值为各个指标值组成的list
# 因为 2019 年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出
# 数据顺序为历年数据
population_dict = {
'2019': [2019, 140005, 71527, 68478, 84843, 55162, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439,
25.74557483, 18.08384956]}
response1 = requests.get(url.format(dfwds1))
get_population_info(population_dict, response1.json())
response2 = requests.get(url.format(dfwds2))
get_population_info(population_dict, response2.json())
response3 = requests.get(url.format(dfwds3))
get_population_info(population_dict, response3.json())
save_excel(population_dict)
return population_dict
def get_population_info(population_dict, json_obj):
"""
提取人口数量信息
"""
datanodes = json_obj['returndata']['datanodes']
for node in datanodes:
# 获取年份
year = node['code'][-4:]
# 数据数值
data = node['data']['data']
if year in population_dict.keys():
population_dict[year].append(data)
else:
population_dict[year] = [int(year), data]
return population_dict
def save_excel(population_dict):
"""
人口数据生成excel文件
:param population_dict: 人口数据
:return:
"""
# .T 是行列转换
df = pd.DataFrame(population_dict).T[::-1]
df.columns = ['年份', '年末总人口(万人)', '男性人口(万人)', '女性人口(万人)', '城镇人口(万人)', '乡村人口(万人)', '人口出生率(‰)', '人口死亡率(‰)',
'人口自然增长率(‰)', '年末总人口(万人)', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)', '总抚养比(%)',
'少儿抚养比(%)', '老年抚养比(%)']
writer = pd.ExcelWriter(POPULATION_EXCEL_PATH)
# columns参数用于指定生成的excel中列的顺序
df.to_excel(excel_writer=writer, index=False, encoding='utf-8', sheet_name='中国70年人口数据')
writer.save()
writer.close()
if __name__ == '__main__':
result_dict = spider_population()
# print(result_dict)
我们来看看保存的excel文件数据。

4.数据分析
数据保存完毕后我们就可以开始数据分析步骤了,一般在我们数据分析之前我们需要有个思路:要分析什么?从哪些角度分析?选择何种可视化图形?得出了什么结论?(当然实际工作时的分析报告需要更为严谨,但大体思路类似。)
4.1 总人口
首先我们提取Excel中的“年末总人口”这一列的数据进行分析。
import numpy as np
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Line, Bar, Page, Pie
from pyecharts.commons.utils import JsCode
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = './population.xlsx'
# 读取标准数据
DF_STANDARD = pd.read_excel(POPULATION_EXCEL_PATH)
# 自定义pyecharts图形背景颜色js
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
# 自定义pyecharts图像区域颜色js
area_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#eb64fb'}, {offset: 1, color: '#3fbbff0d'}], false)"
)
def analysis_total():
"""
分析总人口
"""
# 1、分析总人口,画人口曲线图
# 1.1 处理数据
x_data = DF_STANDARD['年份']
# 将人口单位转换为亿
y_data = DF_STANDARD['年末总人口(万人)'].map(lambda x: "%.2f" % (x / 10000))
# 1.2 自定义曲线图
line = (
Line(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="总人口",
y_axis=y_data,
is_smooth=True,
is_symbol_show=True,
symbol="circle",
symbol_size=5,
linestyle_opts=opts.LineStyleOpts(color="#fff"),
label_opts=opts.LabelOpts(is_show=False, position="top", color="white"),
itemstyle_opts=opts.ItemStyleOpts(
color="red", border_color="#fff", border_width=1
),
tooltip_opts=opts.TooltipOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1),
# 标出4个关键点的数据
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="新中国成立(1949年)", coord=[0, y_data[0]], value=y_data[0]),
opts.MarkPointItem(name="计划生育(1980年)", coord=[31, y_data[31]], value=y_data[31]),
opts.MarkPointItem(name="放开二胎(2016年)", coord=[67, y_data[67]], value=y_data[67]),
opts.MarkPointItem(name="2019年", coord=[70, y_data[70]], value=y_data[70])
]
),
# markline_opts 可以画直线
# markline_opts=opts.MarkLineOpts(
# data=[[opts.MarkLineItem(coord=[39, y_data[39]]),
# opts.MarkLineItem(coord=[19, y_data[19]])],
# [opts.MarkLineItem(coord=[70, y_data[70]]),
# opts.MarkLineItem(coord=[39, y_data[39]])]],
# linestyle_opts=opts.LineStyleOpts(color="red")
# ),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="新中国70年人口变化(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16),
),
# x轴相关的选项设置
xaxis_opts=opts.AxisOpts(
type_="category",
boundary_gap=False,
axislabel_opts=opts.LabelOpts(margin=30, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(is_show=False),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=25,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# y轴相关选项设置
yaxis_opts=opts.AxisOpts(
type_="value",
position="left",
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# 图例配置项相关设置
legend_opts=opts.LegendOpts(is_show=False),
)
)
# 2、分析计划生育执行前后增长人口
# 2.1 数据处理
total_1949 = DF_STANDARD[DF_STANDARD['年份'] == 1949]['年末总人口(万人)'].values
total_1979 = DF_STANDARD[DF_STANDARD['年份'] == 1979]['年末总人口(万人)'].values
total_2010 = DF_STANDARD[DF_STANDARD['年份'] == 2010]['年末总人口(万人)'].values
increase_1949_1979 = '%.2f' % (int(total_1979 - total_1949) / 10000)
increase_1979_2010 = '%.2f' % (int(total_2010 - total_1979) / 10000)
# 2.2 画柱状图
bar = (
Bar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis([''])
.add_yaxis("前31年:1949-1979", [increase_1949_1979], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.add_yaxis("后31年:1980-2010", [increase_1979_2010], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.set_global_opts(
title_opts=opts.TitleOpts(
title="计划生育执行前31年(1949-1979)与后31年(1980-2010)增加人口总数比较(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16)
),
xaxis_opts=opts.AxisOpts(
# 隐藏x轴的坐标线
axisline_opts=opts.AxisLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
# y轴坐标数值
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
# y 轴 轴线
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
# y轴刻度横线
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 3、渲染图像,将多个图像显示在一个html中
# DraggablePageLayout表示可拖拽
page = Page(layout=Page.DraggablePageLayout)
page.add(line)
page.add(bar)
page.render('population_total.html')
analysis_total()
上面的代码和pyecharts自带曲线有点不同的是:添加了自定义曲线背景色和区域色的功能。
在下图中主要标注了四个点:
1949年:新中国成立,总人口 5.42亿
1980年:计划生育正式开始,总人口 9.87亿
2006年:全面放开二胎,总人口 13.83亿
2019年:总人口 14亿
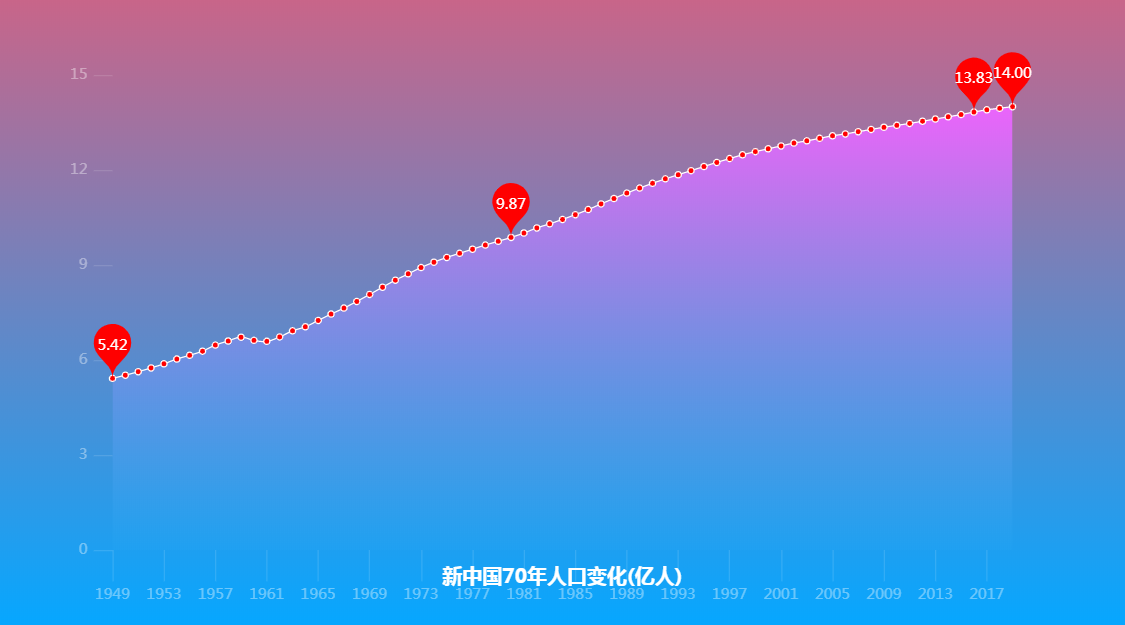
通过观察总人口曲线图得知:
1.人口总体在增加,但增长曲线慢慢放缓,据社科院预测:中国人口将在2029年达到峰值14.42亿,往后逐步下降
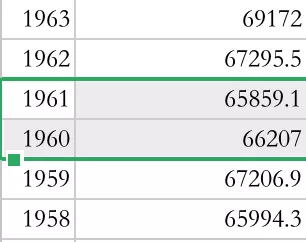
2.新中国成立至今(2020年)唯一出现人口减少的是1960和1961年,这两年是我国的自然灾害年。
3.根据总人口数,我们再来分析一下 执行计划生育前31年 与 后31年增长的人口分别是多少?
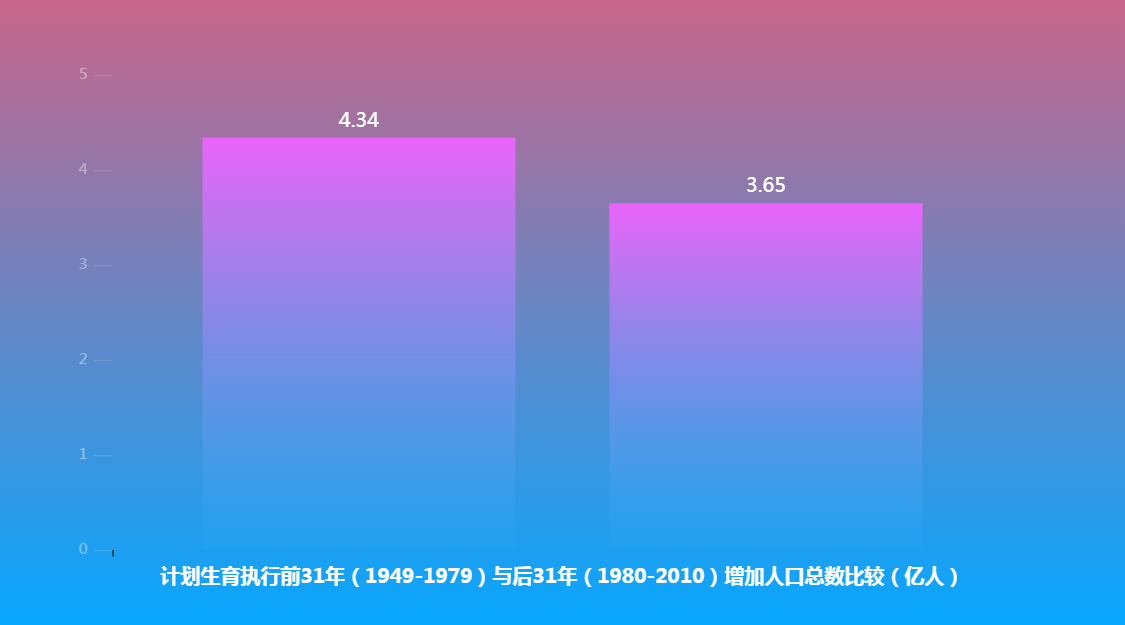
根据上图我们可以看出:计划生育确实控制了人口的增长!
而放开二胎后并未迎来生育高峰期,联合国相关机构发布的《世界人口展望》2017修订版给出了类似的预期。它倾向于认定中国人口已经开始了倒V型反转,在人口到达高峰后,2050年将会保持13亿多,然后就会加速下滑。
4.2 男女人口比例
我们经常会听到别人说:“中国男女比例失衡,将有3000万中国男性娶不到老婆”。
其实这是我国男女比例失衡造成的结果。
下面就从以下4个角度来分析我国男女比例的关系:
1.2019年男女比
2.男性占总人口比例
3.男女人口数曲线
4.男女人口数差值
def analysis_sex():
"""
分析男女比
"""
# 年份
x_data_year = DF_STANDARD['年份']
# 1、2019年男女比饼图
sex_2019 = DF_STANDARD[DF_STANDARD['年份'] == 2019][['男性人口(万人)', '女性人口(万人)']]
pie = (
Pie()
.add("", [list(z) for z in zip(['男', '女'], np.ravel(sex_2019.values))])
.set_global_opts(title_opts=opts.TitleOpts(title="2019中国男女比", pos_bottom="bottom", pos_left="center"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
# 2、历年男性占总人数比曲线
# (男性数/总数)x 100 ,然后保留两位小数
man_percent = (DF_STANDARD['男性人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100))
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis(
series_name="男性占总人口比",
y_axis=man_percent.values,
# 标出关键点的数据
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max")]),
# 画出平均线
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1949-2019)男性占总人数比", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(type_="value", max_=52, min_=50,
axislabel_opts=opts.LabelOpts(formatter='{value} %')),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 3、男女折线图
# 历年男性人口数
y_data_man = DF_STANDARD['男性人口(万人)']
# 历年女性人口数
y_data_woman = DF_STANDARD['女性人口(万人)']
line2 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("女性", y_data_woman)
.add_yaxis("男性", y_data_man)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1949-2019)男女人口数(万人)", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 4、男女人口差异图
# 两列相减,获得新列
y_data_man_woman = DF_STANDARD['男性人口(万人)'] - DF_STANDARD['女性人口(万人)']
line3 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis(
series_name="男女差值",
y_axis=y_data_man_woman.values,
# 标出关键点的数据
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="average")]),
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1949-2019)男女差值(万人)", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 5、渲染图像,将多个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(pie)
page.add(line1)
page.add(line2)
page.add(line3)
page.render('population_sex.html')
analysis_sex()
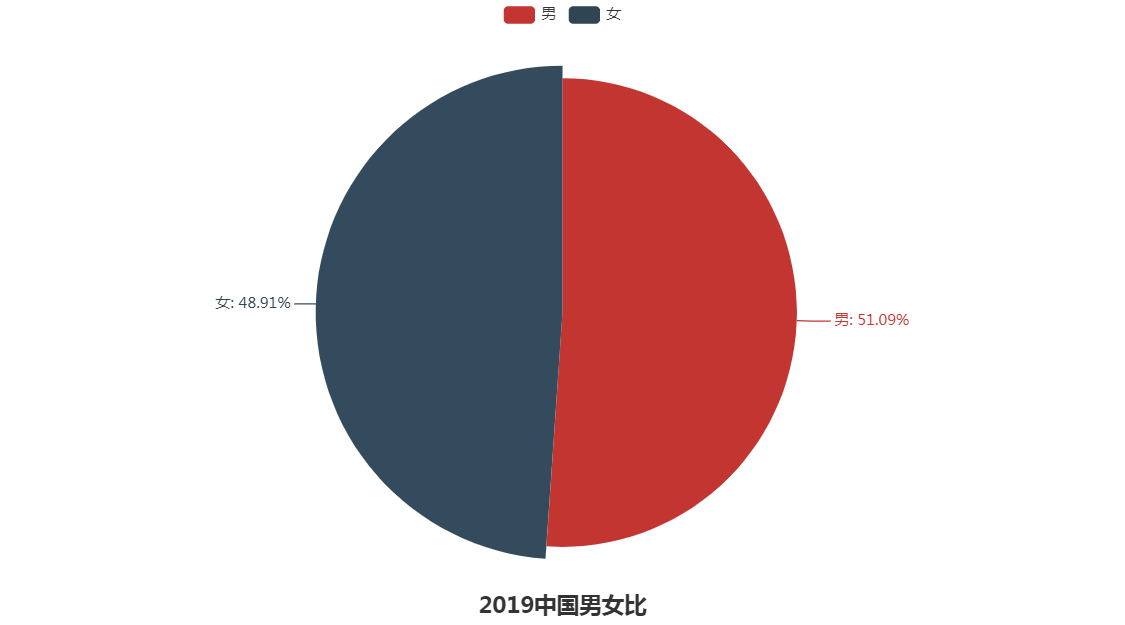
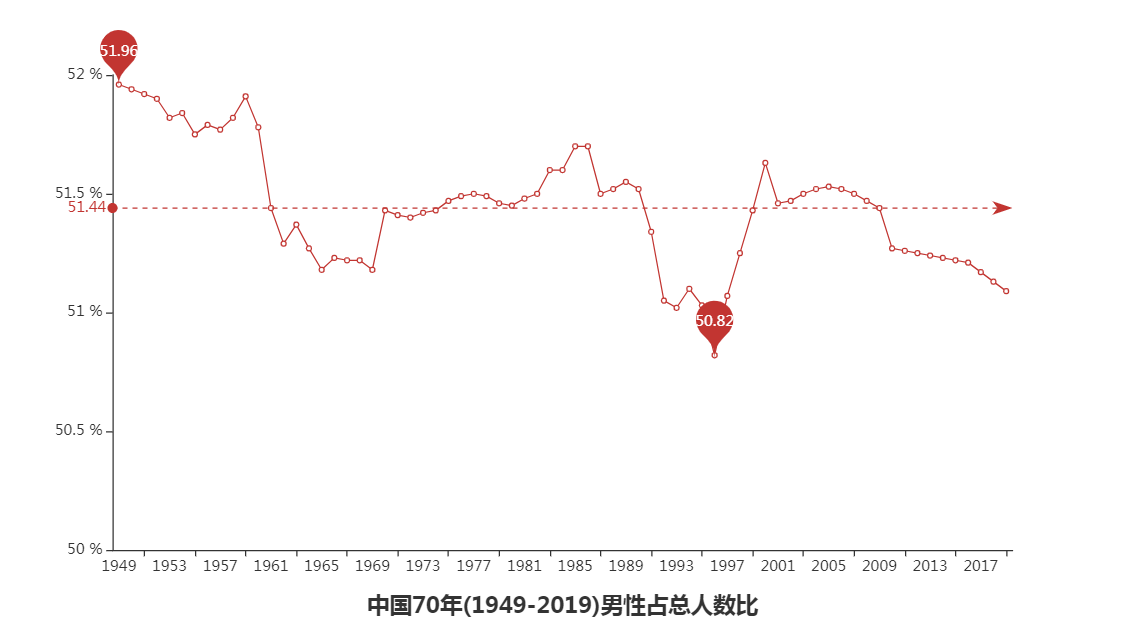
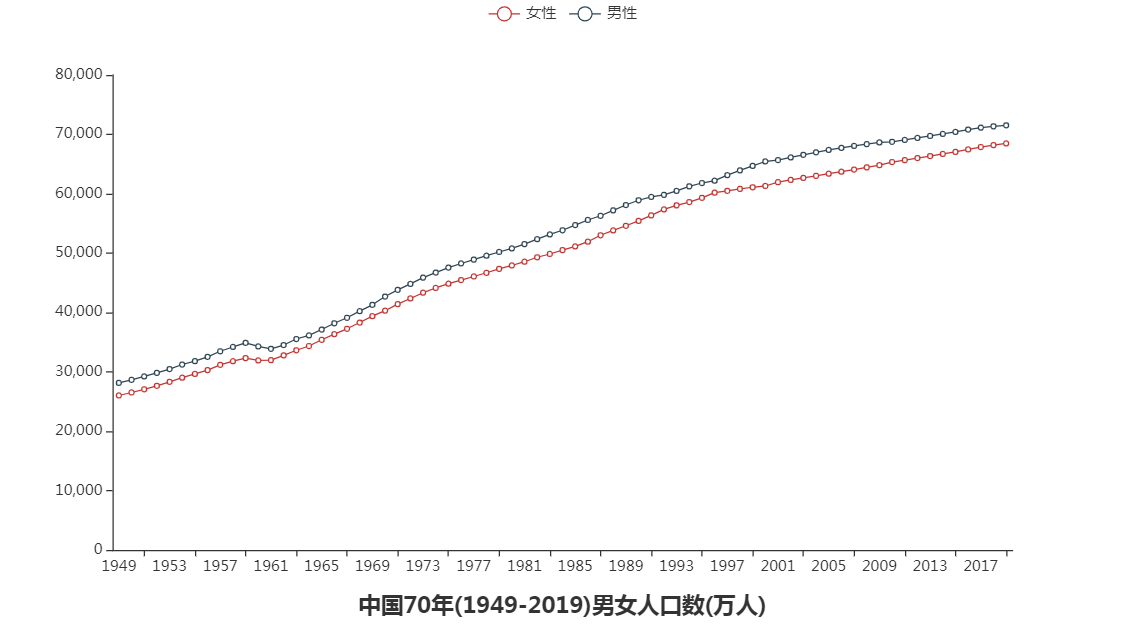
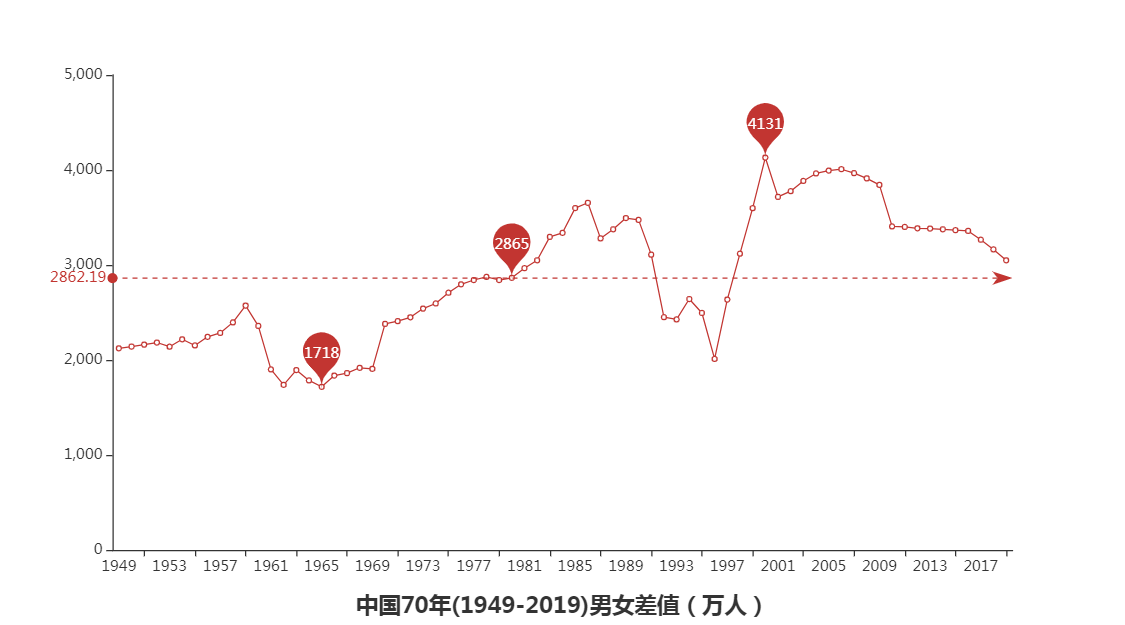
根据上面4图我们可以得出一些结论:
1.新中国成立以来男性人口一直比女性人口多,可能与我国重男轻女思想有一定关系。
2.2000年我国男女人口差值最大为4131万人,最小差值是在1965年为1718万人。
3.2006年以来我国男女比例失衡状况逐年缓解
4.3人口城镇化
有很多人不理解何为“人口城镇化”,下面猪哥引用百度百科的介绍:
人口城镇化是指农村人口转变为城镇人口、农业人口转变为非农业人口的过程,它是社会生产力发展到一定阶段的产物。
城镇化是一个综合指标,可以用来衡量当地经济发展情况、基础设施和人民生活水平。
同时,城镇化的进程也是房地产市场在需求层面的重要支撑力量。
根据美国地理学家诺瑟姆对世界各国城市化的研究,世界城市化分为三个阶段:
1.初期(人口城镇化在30%以下):农村人口占优势,工农业生产力水平较低,工业提供就业机会少,农业剩余劳动力得不到释放。
2.中期(人口城镇化30%~70%):工业基础比较雄厚,经济实力明显增强,农村劳动生产率提高,剩余劳动力转向工业,城市人口比重快速突破50%,而后上升到70%。
3.后期(人口城镇化70%~90%):农村人口向城镇人口的转化趋于停止,农村人口占比稳定在10%左右,城市人口可以达到90%左右,趋于饱和,这个过程的城市化不再是人口从农村流向城市,而是城市人口在产业之间的结构性转移,主要是从第二产业向第三产业转移。
来看看我国人口城镇化数据分析:
def analysis_urbanization():
"""
分析我国人口城镇化
"""
# 年份
x_data_year = DF_STANDARD['年份']
# 2019年我国人口城镇化
urbanization_2019 = DF_STANDARD[DF_STANDARD['年份'] == 2019][['城镇人口(万人)', '乡村人口(万人)']]
pie = (
Pie()
.add("", [list(z) for z in zip(['城镇人口', '乡村人口'], np.ravel(urbanization_2019.values))])
.set_global_opts(title_opts=opts.TitleOpts(title="2019中国城镇化比例", pos_bottom="bottom", pos_left="center", ),
legend_opts=opts.LegendOpts(is_show=False))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
# 2、城镇化比例曲线
y_data_city = DF_STANDARD['城镇人口(万人)'] / 10000
y_data_countryside = DF_STANDARD['乡村人口(万人)'] / 10000
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("城镇人口", y_data_city)
.add_yaxis(series_name="乡村人口", y_axis=y_data_countryside,
# 标记线
markline_opts=opts.MarkLineOpts(
# 去除标记线的箭头
symbol='none',
label_opts=opts.LabelOpts(font_size=16),
data=[[opts.MarkLineItem(coord=[46, 0]),
opts.MarkLineItem(name='1995', coord=[46, y_data_countryside[46]])],
[opts.MarkLineItem(coord=[61, 0]),
opts.MarkLineItem(name='2010', coord=[61, y_data_countryside[61]])]],
# opacity不透明度 0 - 1
linestyle_opts=opts.LineStyleOpts(color="red", opacity=0.3)
),
# 标出关键点的数据
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="1995年", coord=[46, y_data_countryside[46]],
value="%.2f" % (y_data_countryside[46])),
opts.MarkPointItem(name="2010年", coord=[61, y_data_countryside[61]],
value="%.2f" % (y_data_countryside[61]))]
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1949-2019)城乡人口曲线(亿人)", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 3、城镇化曲线
y_data_urbanization = (DF_STANDARD['城镇人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100))
line2 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis(
series_name="中国人口城镇化比例曲线",
y_axis=y_data_urbanization.values,
markline_opts=opts.MarkLineOpts(symbol='none', data=[opts.MarkLineItem(y=30), opts.MarkLineItem(y=70)])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国(1949-2019)人口城镇化比例曲线", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(type_="value", max_=100, min_=10,
axislabel_opts=opts.LabelOpts(formatter='{value} %')),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 4、渲染图像,将多个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(pie)
page.add(line1)
page.add(line2)
page.render('population_urbanization.html')
analysis_urbanization()
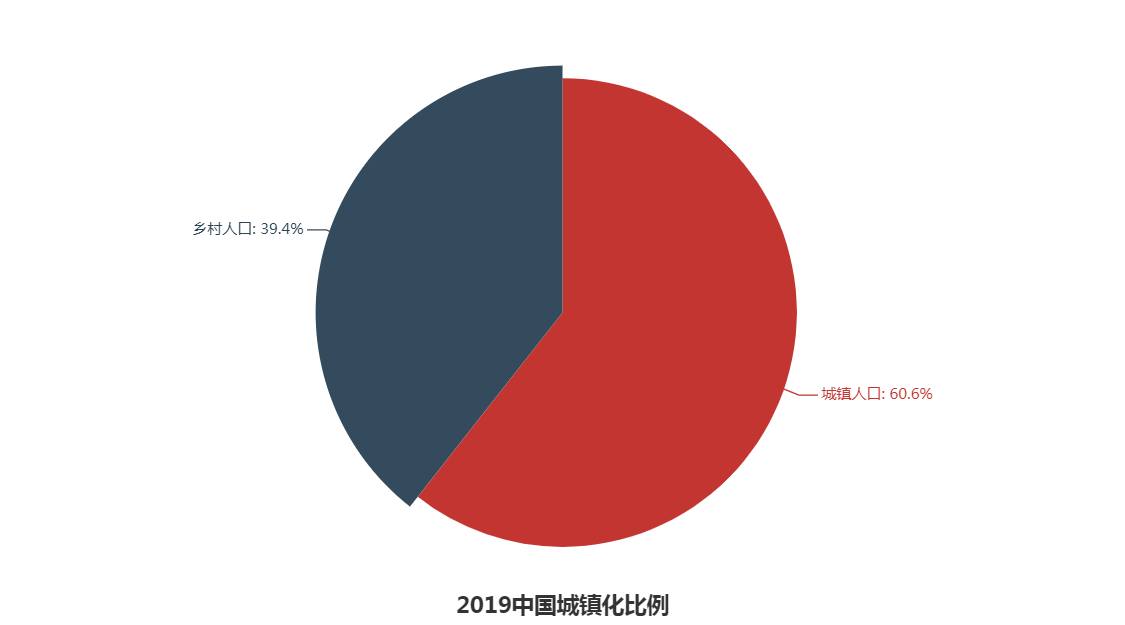
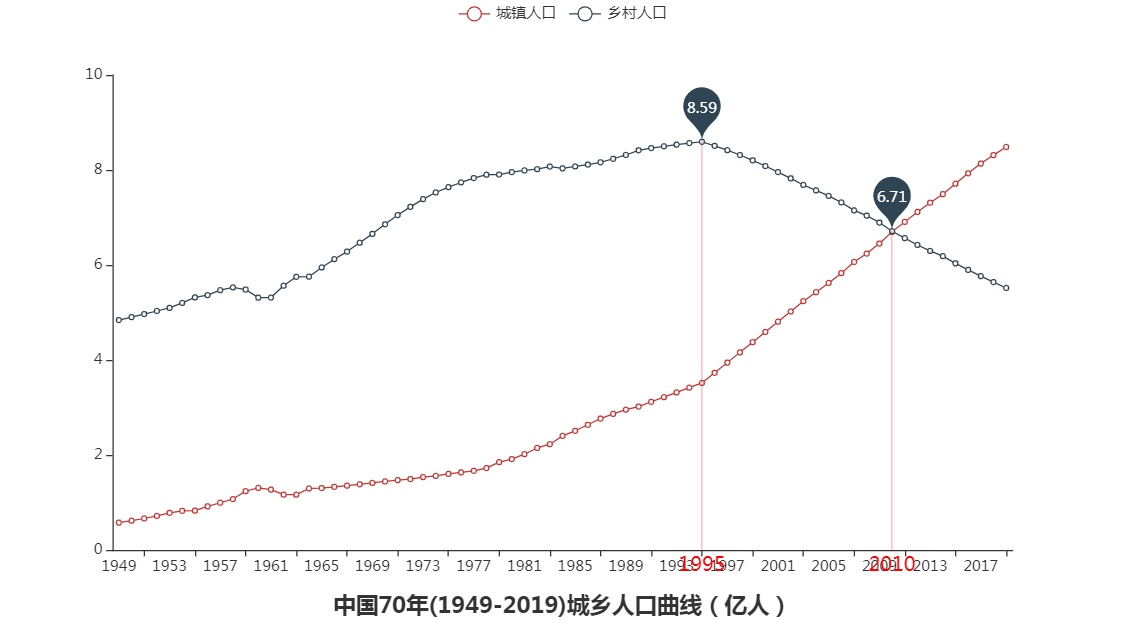
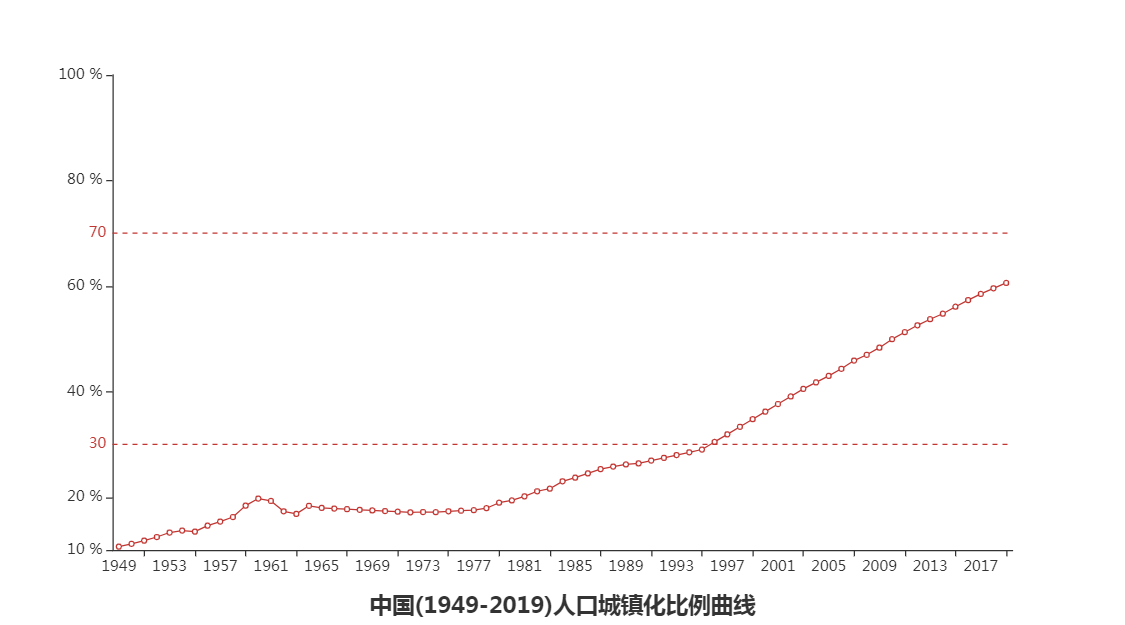
由上图分析可知:
1.2019年我国人口城镇化达到60.6%,处于人口城镇化的中期。
2.1995年我国乡村人口达到峰值:8.59亿。
3.1996年我国城镇化步伐加快,同年城镇化超过30%,进入城镇化的中期。
4.在2010年我国城市人口与乡村人口持平约为6.7亿,城镇化为50%。
联合国对中国人口城镇化进程进行了预测:我国城镇化初期是1949年~1995年,中期是1996年~2032年,后期是2033年以后。
4.4 人口增长率
def analysis_growth():
"""
分析人口增长率
"""
# 1、三条曲线
x_data_year = DF_STANDARD['年份']
y_data_birth = DF_STANDARD['人口出生率(‰)']
y_data_death = DF_STANDARD['人口死亡率(‰)']
y_data_growth = DF_STANDARD['人口自然增长率(‰)']
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("人口出生率", y_data_birth)
.add_yaxis("人口死亡率", y_data_death)
.add_yaxis("人口自然增长率", y_data_growth)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value} ‰')),
title_opts=opts.TitleOpts(title="中国70年(1949-2019)出生率、死亡率及增长率变化", subtitle="1949-2019年,单位:‰",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 2、渲染图像,将两个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(line1)
page.render('analysis_growth.html')
analysis_growth()
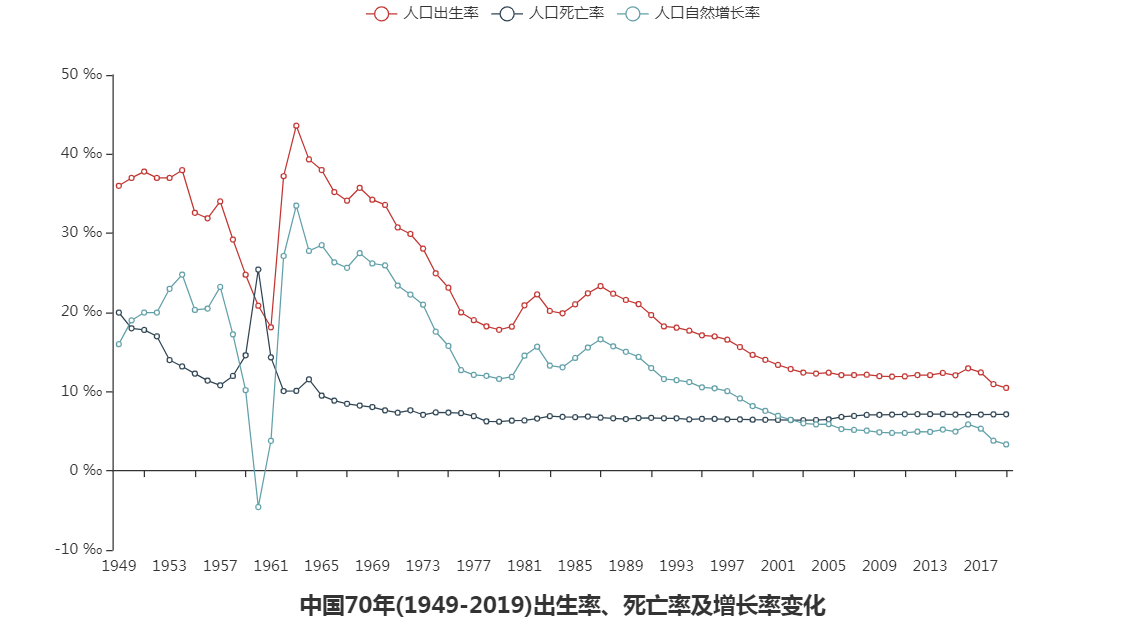
由上图得知:
1.在自然灾害三年(1959、1960、1961)我国人口死亡率陡增,出生率也下降,人口出现新中国成立以来第一次负增长!
2.在自然灾害过后的两年(1962、1963)迎来我国最大的一波生育潮,我们通过2010年人口第五次普查的数据也可以验证这个结论。
3.自然灾害三年过后我国的死亡率一直趋于稳定,维持在6-7‰左右。
4.我国出生率整体一直在下降,在计划生育之前出生率就在下降。
5.在2016年我国全面放开二胎之后的三年(2017-2019),出生率并没有出现好转,反而持续走低。
目前的育龄妇女基本都是85-90后,受计划生育(1980年)影响,育龄妇女人数比以前少了,生孩子的数量自然就比以前少了,这一情况会持续下去。
出生率降低,死亡率增加,人口增长就慢慢放缓,社科院预测在2029年左右我国人口达到峰值(14.42亿)之后慢慢减少!
4.5 年龄结构
人口年龄结构是衡量 老龄化 与 人口红利 的指标。
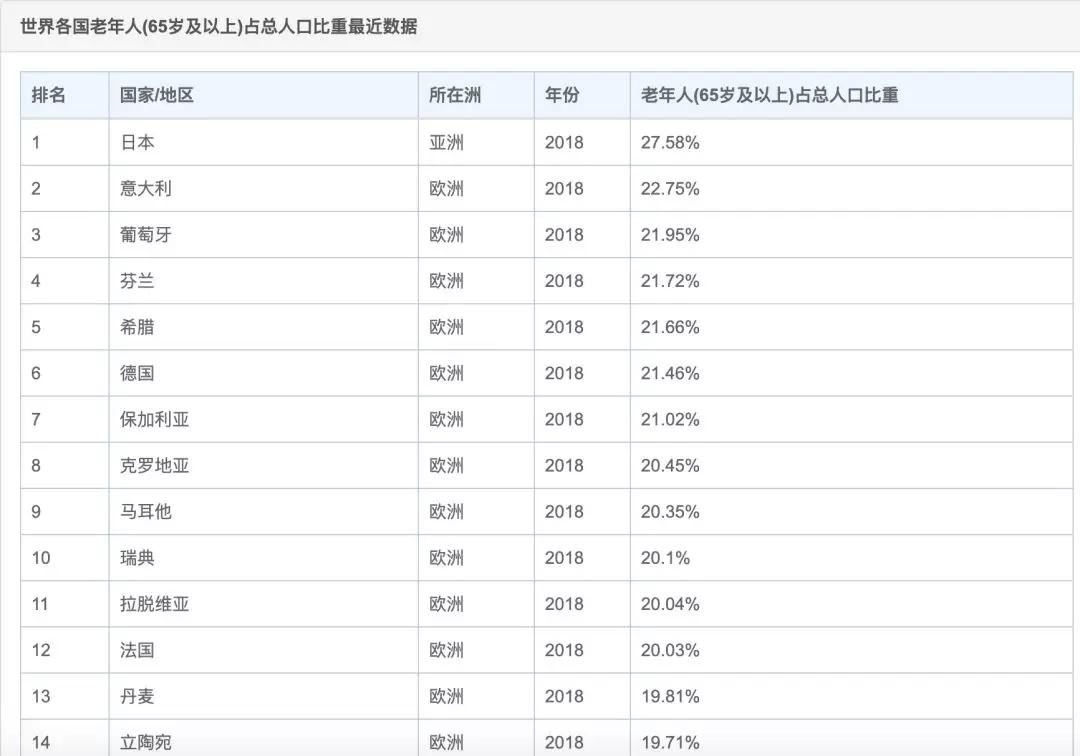
老龄化:指老年人口相对增多,在总人口中所占比例不断上升的过程,国际上通常看法是,当一个国家或地区60岁以上老年人口占人口总数的10%,或65岁以上老年人口占人口总数的7%,即意味着这个国家或地区的人口处于老龄化社会。
老龄化是每个国家每个社会都会经历的阶段,目前来讲发达国家的老龄化问题比发展中国家更严重,据快易数据提供的一份 世界各国老龄化排名来看,中国只排到了65名,第一名是日本,而前几名基本都是欧洲国家。
人口红利:经济学术语,是指一个国家的劳动年龄人口占总人口比重较大,抚养率比较低,为经济发展创造了有利的人口条件,整个国家的经济呈高储蓄、高投资和高增长的局面。
人口红利简单来说就是 劳动力人口数 大于 非 劳动力人口,劳动人口比例较高,保证了经济增长中的劳动力需求,劳动力资源丰富和成本优势已经使中国成为世界工厂和世界经济增长的引擎。
def analysis_age():
"""
分析年龄结构
"""
new_df = DF_STANDARD[DF_STANDARD['0-14岁人口(万人)'] != 0][['年份', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
x_data_year = new_df['年份']
y_data_age_14 = new_df['0-14岁人口(万人)']
y_data_age_15_64 = new_df['15-64岁人口(万人)']
y_data_age_65 = new_df['65岁及以上人口(万人)']
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("0-14岁人口", y_data_age_14)
.add_yaxis("15-64", y_data_age_15_64)
.add_yaxis("65岁及以上人口", y_data_age_65)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}万')),
title_opts=opts.TitleOpts(title="中国人口年龄结构变化图(万人)",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 2、1982年龄结构与2019年龄结构
age_1982 = DF_STANDARD[DF_STANDARD['年份'] == 1982][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
age_2019 = DF_STANDARD[DF_STANDARD['年份'] == 2019][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
pie = (
Pie()
.add(
"1982",
[list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_1982.values))],
center=["20%", "50%"],
radius=[60, 80],
)
.add(
"2019",
[list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_2019.values))],
center=["55%", "50%"],
radius=[60, 80],
)
.set_series_opts(label_opts=opts.LabelOpts(position="top", formatter="{b}: {d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(title="中国1982、2019年年龄结构对比图", pos_left="center",
pos_top="bottom"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="20%", pos_left="80%", orient="vertical"
),
)
)
# 3、抚养比曲线
new_df = DF_STANDARD[DF_STANDARD['总抚养比(%)'] != 0][['年份', '总抚养比(%)', '少儿抚养比(%)', '老年抚养比(%)']]
x_data_year2 = new_df['年份']
y_data_all = new_df['总抚养比(%)']
y_data_new = new_df['少儿抚养比(%)']
y_data_old = new_df['老年抚养比(%)']
line2 = (
Line()
.add_xaxis(x_data_year2)
.add_yaxis(series_name="总抚养比", y_axis=y_data_all, markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="1995年", coord=[22, y_data_all.values[22]],
value="%.2f" % (y_data_all.values[22]))
]
))
.add_yaxis("少儿抚养比", y_data_new)
.add_yaxis("老年抚养比", y_data_old)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}%')),
title_opts=opts.TitleOpts(title="中国抚养比变化曲线图",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 4、渲染图像,将两个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(line1)
page.add(line2)
page.add(pie)
page.render('analysis_age.html')
analysis_age()
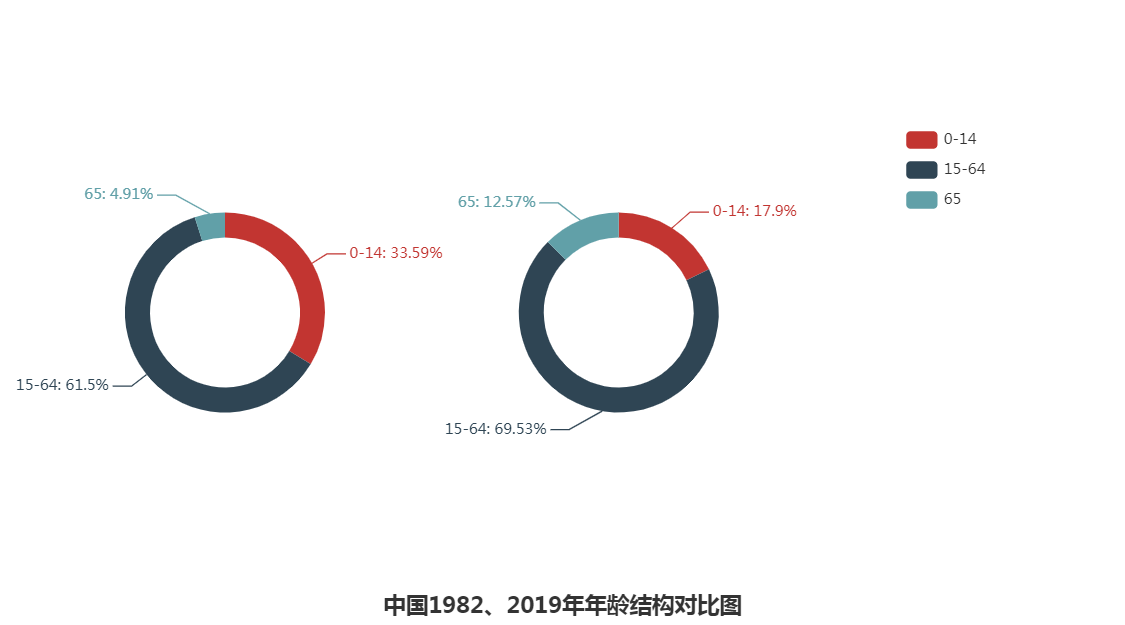
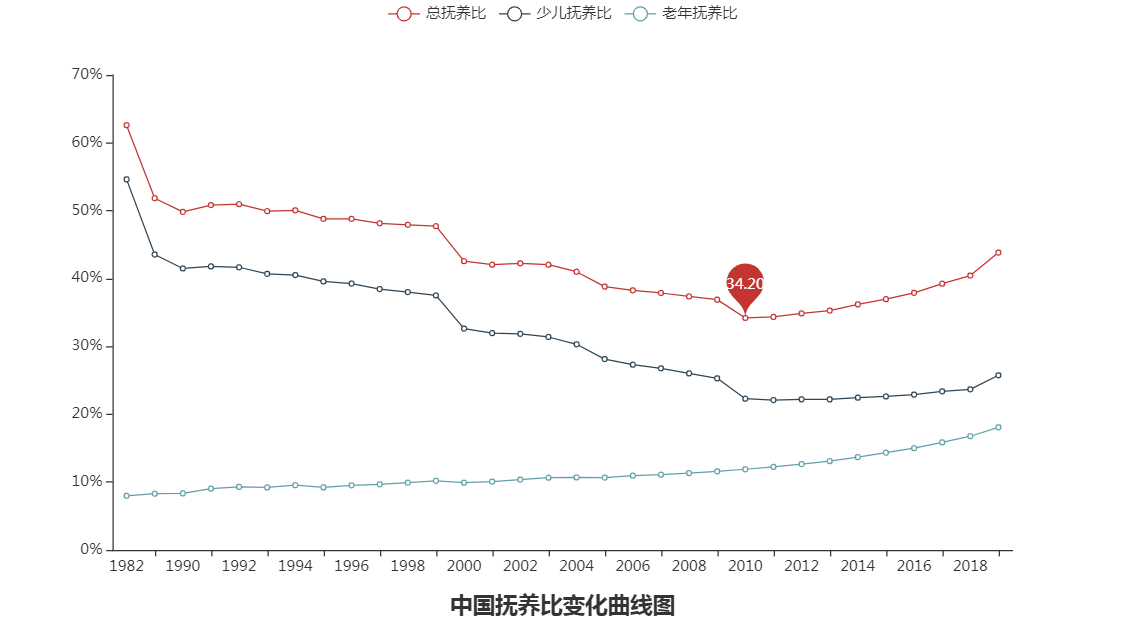
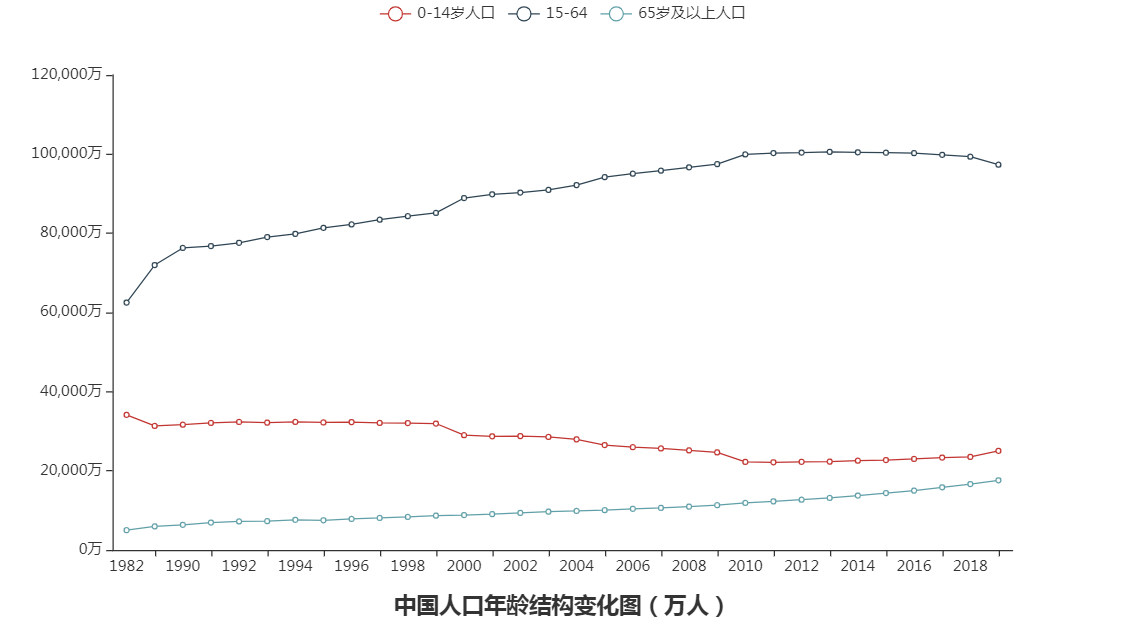
从上面三图分析我们可得:
1.1982年我国 0-14岁少儿占比33.59%,而2019年减至17.9%,比例减至近半。
2.2019年我国65岁以上人口占比为12.57%,已经进入老龄化社会。世界有92个国家进入老龄化,中国排在65。
3.2010年我国总抚养比达到最低为:34.2%,意味着每3个劳动力需要养一个老人或小孩。
4.人口红利在2010年达到顶峰,之后在慢慢降低。
2019年我国老年人口为1.76亿,中国的老龄化即将进入快速老龄化阶段,目前我国多个省的养老金告急,我国养老金体系改革迫在眉睫。
5 总结
我们来总结一下分析的结果:
1.总人口:我国总人口稳步增长,据社科院预测:中国人口将在2029年达到峰值14.42亿,往后逐步下降.
2.男女比例:我国自新中国成立以来,一直处于男多女少的状态中,2019年男女差为3000万。因为老年人中女性多于男性,所以年轻男女的差值应该会更大。
3.人口城镇化:2019年我国城镇化超过60%,处于城镇化发展的中期阶段。联合国对中国人口城镇化进程进行了预测:我国城镇化初期是1949年~1995年,中期是1996年~2032年,后期是2033年以后。
4.人口增长率:我国出生率持续走低,在全面放开二胎之后并未出现生育潮,人口增长慢慢放缓,据社科院预测在2029年人口增长率为0,之后出现负增长,生育率低使得我的老龄化进程加快。
5.人口年龄结构:人口年龄结构影响着两个重要的指标:人口红利、老龄化。我国人口红利在2010年达到顶峰,之后慢慢减少。老龄化问题是国际普遍存在的问题,尤其是发达国家。据快易数据显示:2018年全世界有92个国家进入老龄化,排在第一的日本老龄化为:27.58%,我国老龄化排在第65位。但随着时间推移我国即将进入快速老化期,养老问题日益凸显!
总结来说我国人口结构存在三个严峻的问题:
1.生育率低:生育率低、劳动力萎缩、老龄化加速、人口红利消失加快。
2.养老问题:老龄化加速、劳动力萎缩,导致多省养老金告急,需中央补贴!
3.剩男问题:计划生育实行后男女人口差拉大,男女失衡,剩男问题严峻,越南买媳妇新闻屡见不鲜!
如果你也对中国的人口兴趣感兴趣的话,也可以找相关的书籍来阅读。
