当你知道的越多, 你不知道的也越多.
什么是缓存?
在维基百科中这样解释: 缓存是存储在计算机上的一个原始数据复制集, 以便于访问.
其实缓存随处可见, 比如CPU缓存, 浏览器缓存等等, 不管存在何处, 其目的都是唯一的提高访问的性能. 在本篇文章中我们的重点将放在分布式缓存中, 并且会介绍在分布式缓存中使用到的一些缓存技术, 大致可以分为两类: 平台级缓存以及应用级缓存
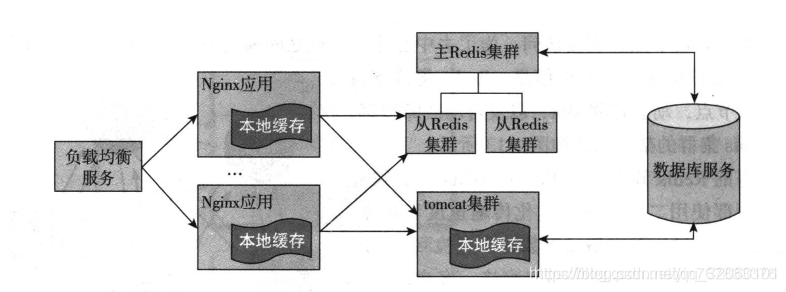
上面的一张图便是一个很经典的多级缓存案例, 在图中nginx服务的缓存以及tomcat的缓存都可以理解为是本地缓存或者说叫平台级缓存, 而 redis便是应用级的缓存.
缓存的访问顺序依次是, 用户首先通过负载均衡服务将请求分发到对应的Nginx应用中, 并且首先从nginx应用缓存中寻找请求的内容, 如果找到便返回响应, 如果找不到继续再由nginx将请求转发到tomcat集群中的一台tomcat服务上, 再从tomcat本地缓存中获取请求内容,如果找到便返回响应, 如果找不到, 继续从Redis缓存中查找请求内容, 如果依旧找不到, 才会去数据库中查找, 当从数据库中查询到数据之后, 返回响应, 随后更新缓存中的数据.
从用户访问的顺序来区分的话, 上述图分为三级缓存, 为什么要采取多级缓存? 使用缓存的目的是为了提高性能, 但是在使用缓存的时候又有这一系列的问题, 如果你并发比较高, 很容易发生缓存击穿, 缓存穿透, 缓存雪崩等等问题, 一旦缓存出现问题, 会导致缓存不可用, 所有请求会直接落到数据库上, 发生不可预估的问题. 所以多级缓存主要是为了提高缓存的可用性.
下面我们简单总结一下缓存都有哪些:
- 平台式:
- Ehcache
- Guava Cache
- 集中式
- Memecached
- Redis
- Tair
- EVCache
- Aerospike
这么多缓存的实现原理、实现机制以及应用场景也是不太相同的, 但是有一点可以肯定的就是, 不管什么缓存, 它保存的数据是具有一定的时效性的, 缓存里面的数据会不断的被更新替换删除. 那缓存更新删除的策略又有哪几种呢? 一下便是常用的几种:
FIFO: 根据数据的写入时间, 数据先进先出LUF: 最少被使用, 最少使用的数据会被清空LRU: 最近最少使用, 根据时间戳以及使用清空进行清空Lazy Expiration: 惰性删除, 缓存被命中之后, 去判断是否要清空
下面我们在分别介绍一下上述几种缓存
Ehcache

Guava Cache

Memecached

Tair

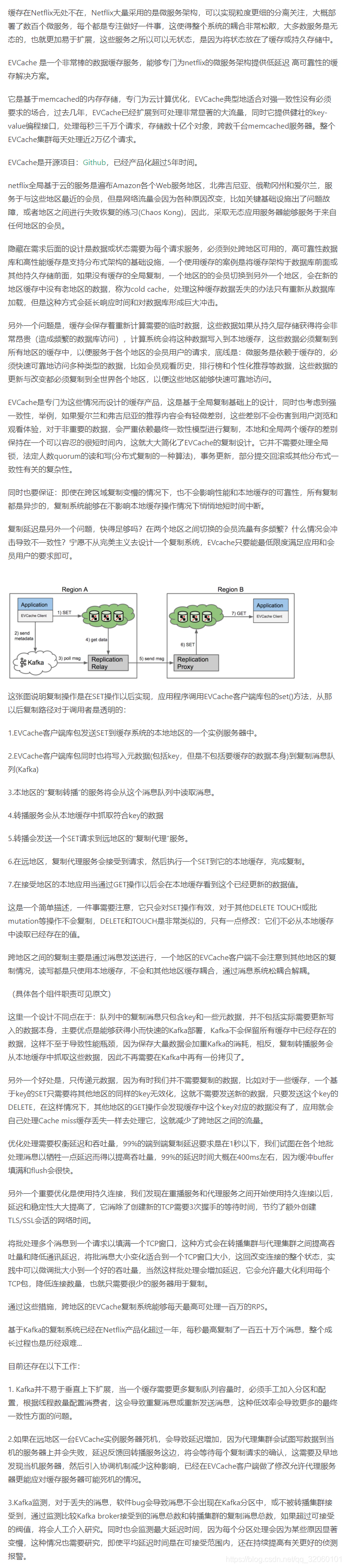
EVCache
Aerospike

Redis
这一部分涉及较多内容,大家可以访问这里查看: Redis汇总
以上便是对几种缓存的介绍, 因为很多优秀的网友总结的比较详细, 所以我没有再重复的总结
参考文献
https://www.jianshu.com/p/8d843d7a6a27
https://www.jdon.com/47913
https://www.jianshu.com/p/ccb17daed766
https://blog.csdn.net/zhaohong_bo/article/details/91801997
https://www.jianshu.com/p/154c82073b07
https://segmentfault.com/a/1190000011105644
《深入分布式缓存 从原理到实践》 —于君泽、曹洪伟等著名
