腾讯视频《银河补习班》的评论爬取实战
需要点击加载更多(如腾讯视频评论)看新内容的,或是不断下滑看到新内容的(如微博),这些都是异步请求。
1.进入要爬取某电影评论的界面,点击源代码,搜索发现没有评论的内容,内容是放到了js包里,需要使用fiddler工具抓包分析。
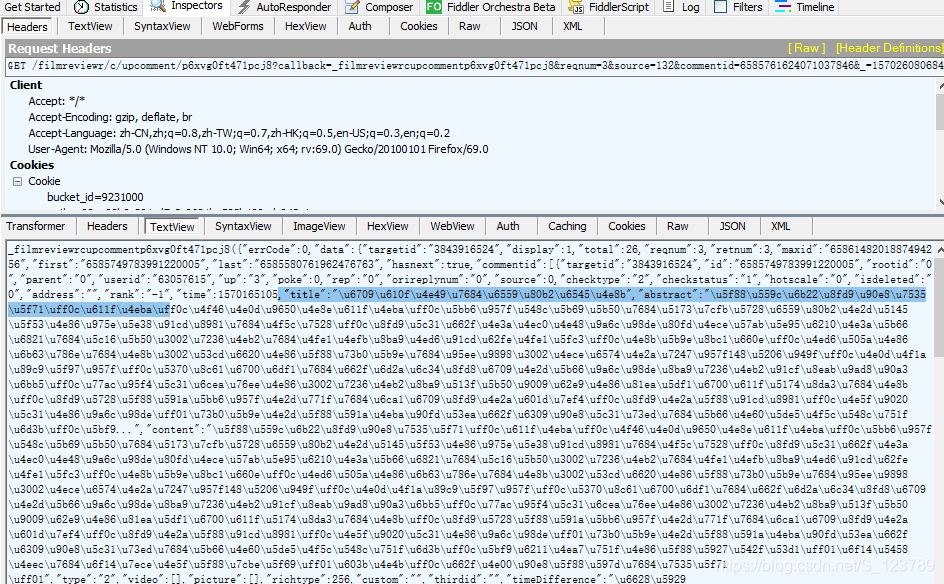
2.在fiddler中找到抓到的js包,查看textview内容,都类似于这种的"title":"\u6709\u610f\u4e49\u7684\u6559\u80b2\u6545\u4e8b",“abstract”:"\u5f88\u559c\u6b22\u8fd9\u90e8\u7535\u5f71\uff0c\u611f\u4eba\uf,一般而言,带有\u的是想找的内容。
不过我们可以验证一下,打开idle,在TextView找一句,前面加上u,进行解码,如下:
>>> u"\u6709\u610f\u4e49\u7684\u6559\u80b2\u6545\u4e8b"
'有意义的教育故事'
3.成功找到了,不过我们要用到url,所以进入fiddler,右击上面用的js包——>copy——>just url,粘贴到word。
4.clear Fiddler内容,进入某电影评论区点击加载更多,然后再重复一下以上的三个步骤。
5.此时得到两个url,可以对url的字段进行简单分析,得到url的最终格式。
https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?&reqnum=[评论个数]&
commentid=[评论id]
6.代码
#1.爬取单页评论
import re,urllib.request
#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?&reqnum=[评论个数]& commentid=[评论id]
vid = 'p6xvg0ft471pcj8'
req = '30'
comid = '6585761624071037846'
#构造当前评论网址
url = "https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?&reqnum="+req+"& commentid=+comid"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0",
"Content-Type":"application/javascript"
}
head = []
for i in headers.items():
head.append(i)
opener = urllib.request.build_opener()
opener.addheaders = head
#将opener安装为全局
urllib.request.install_opener(opener)
#爬取评论
url = "https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?&reqnum="+req+"& commentid=+comid"
data = urllib.request.urlopen(url).read().decode("utf-8")
titlepat = '"title":"(.*?)"'
contentpat = '"abstract":"(.*?)"'
#lastpat = '"last":"(.*?)"'
titleall = re.compile(titlepat,re.S).findall(data)
contentall = re.compile(contentpat,re.S).findall(data)
#cid = re.compile(lastpat,re.S).findall(data)
#comid = cid
for i in range(0,len(titleall)-1):
print(eval('u"'+titleall[i]+'"'))
print(eval('u"'+contentall[i]+'"'))
7.利用BlueMC工具生成词云图

