资源搜索
学习笔记:YOLO系列-V1、V2与V3:You Only Look Once
本人总结
在开始进入具体算法实现之前,我们还是先简单随便聊一聊。目标检测应该说是计算机视觉领域中比较好玩而且实际的方向,我们给定一张输入图像,目标检测系统就可以识别出图片中各个目标的位置。它主要的一个应用前景就是无人驾驶,因为在无人驾驶汽车上装载此系统,无人车就像有了眼镜,可以快速检测出前面的行人与车辆等,来实时做出相应的决策。
上面聊了什么是目标检测以及最可能实际应用的场景,那下面我们简单说一个传统目标检测和深度学习方法。其中传统目标检测方法有Viola-Jone(人脸检测)、HOG+SVM(行人检测)、DPM(物体检测)、Sofe-NMS(非极大抑制)等方法,它们主要的流程如下图:

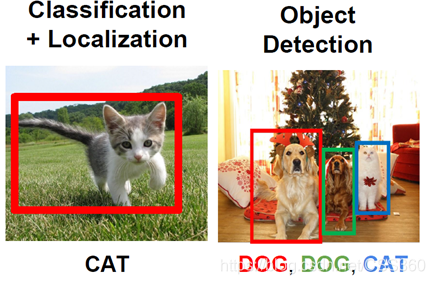
在这里说明一下候选框提取主要使用的方法一般是滑动窗口的方法。好了,如果想继续了解传统目标检测的,就请网上自己搜索一下吧,资料很多。其实,深度学习目标检测方法的时候,都是要在传统的基础上发展过来的。本人理解的是,把传统部分的关键步骤拿卷积网络实现一下,效果不错。然后,后面在继续优化,最终实现一个端到端的学习。好,那当前比较流行的深度学习目标检测网络有哪些呢?比较流行的分为两类:一类是基于Region Proposal的R-CNN系算法(R-CNN、Fast R-CNN、Faster R-CNN),即two-stage网络。为什么叫two-stage网络,主要是在实现过程中,先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal(产生后选区域并实现一个背景和目标的分类,以及初步确定目标的位置),然后在此基础上做分类和回归。另外一类就是以YOLO、SSD为代表的one-stage算法,只需要一个CNN网络就可以预测出不同目标的位置。讲了那么,还是来张图看一下,单目标和多目标的检测及分类的效果:
既然是两种不同实现方法,就存在各自优缺点,第一类two-stage就是准确度很高、但是速度比较慢;第二类one-stage就是速度很快,但是精度偏低。下面我们一起来看一下one-stage的代表YOLO的发展过程,但是在开始深入前,我们还是先解决一个疑问:是什么样的算法框架,造成了两类算法不同的性能?下面给出一张,深度学习目标检测的曲线,对哪个感兴趣,自己下去好好查查吧。

