声明式API
所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来“声明”,我所期望的状态是什么样子
“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML 文件的内容
Kubernetes 项目才可以基于对 API 对象的增、删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐(Reconcile)过程
声明式 API,才是 Kubernetes 项目编排能力“赖以生存”的核心所在
AdmissionControl机制
在K8S中 当一个Pod或者任何一个API对象提交给APIServer之后 总需要做一些
初始化的工作 比如在自动为Pod添加上某些标签
这些功能的实现依赖于一组Admission Controller来实现 可以选择性的编译到
APIServer中 在API对象创建之后会被立即调用
需要重新编译自己的APIServer添加自己的规则 比较麻烦
热插拔Admission机制(Dynamic Admission)
Istio实现机制
编写一个用来为所有Pod自动注入自己定义的容器的Initializer
这个Initializer的定义会以ConfigMap的方式进行保存在集群中
在Initializer更新用户的Pod对象的时候,必须使用PATCH API来完成
Istio将一个编写好Initializer做为一个Pod运行在k8s集群中
在Pod YAML文件提交给K8S之后 在创建好的Pod的API对象上自动添加Envoy容器配置
Initializer初始化器介绍
Initializer可以是以一个Pod的形式运行在集群当中
Initializer就是初始化器的意思 就是在任何一个API对象刚刚创建成功后马上调用初始化器给这个对象添加一些自定义的属性
Initializer 要做的工作,就是把这部分单独定义相关的字段,自动添加到用户提交的Pod的API对象里.可是,用户提交的 Pod 里本来就有containers字段和volumes字段
所以Kubernetes 在处理这样的更新请求时,就必须使用类似于git merge 这样的操作,才能将这两部分内容合并在一起 最后按照合并后的结果创建容器和挂载卷等
Initializer在更新用户pod对象的时候 必须使用PATCH API来完成 而PATCH API正是声明式API的最主要的能力
k8s能够对API对象进行在线更新的能力
Initializer逻辑流程
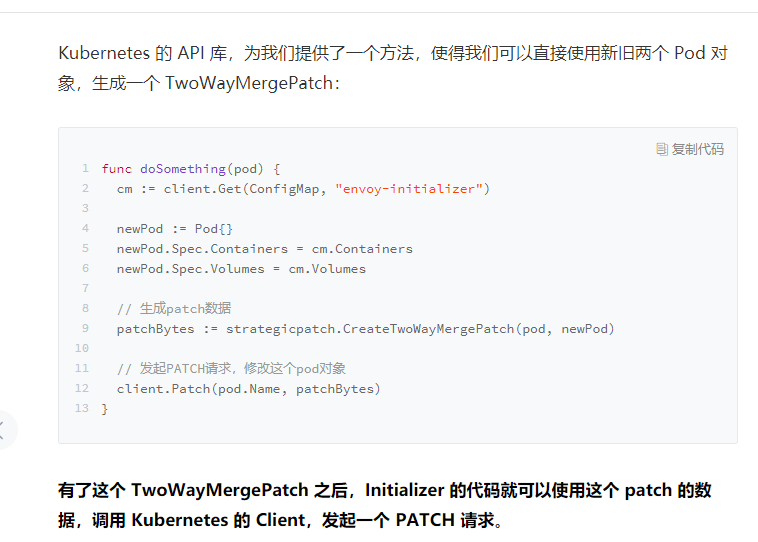
1.首先从ConfigMap中拿到相关数据创建一个空的Pod对象
2.使用新旧两个Pod对象做为参数调用k8s中TwoWayMergePatch返回patch数据
3.通过client发起PATCH请求更新原来的pod对象

一个用户提交的 Pod 对象里,就会被自动加上 Envoy 容器相关的字段 使用 Kubernetes 的 Initializer 特性,完成 Envoy 容器“自动注入”的原理
声明式API设计
API对象在Etcd里的完整路径由Group/Version/Resource组成 同一种API对象可以有多个Version k8s进行API版本化的重要手段
1.首先匹配API对象的组
Pod Node等核心API对象是不需要Group的 它们的Group是"" 直接从/api开始查找
2.根据完整路径找到k8s的类型定义后使用用户提交的YAML文件中的字段创建一个实例
在创建实例的过程中会进行一个Convert操作 把用户提交的YAML文件转成一个super version对象
它是API资源类型所有版本的字段全集 方便用户提交不同API版本的YAML
3.进行API对象的Initializer操作和Validation操作
validation操作验证对象中各个字段的合法性 验证后保存到Registry数据结构中 一个API对象的定义能在Registry里能查到 那么它就是一个有效的k8s API对象
4.把super version对象转换成用户提交版本的对象 序列化后保存到etcd中
自定义API资源类型(CRD)
成功创建CRD之后 只是完成声明式API的一半工作
因为还没有为这个CRD创建控制器 所以在k8s中只能对这个CRD进行增删改查操作
但无法对CRD对象发生增删改的操作时触发对应的业务逻辑 必须为每个CRD创建一个对应的CRD控制器来实现当CRD对象发生变化时候触发控制器里面的业务逻辑代码
“registry”的作用就是注册一个类型(Type)给 APIServer.其中Network(CRD)资源类型在服务器端的注册的工作APIServer 会自动帮我们完成
但与之对应的,我们还需要让客户端也能“知道”Network 资源类型的定义.这就需要我们在项目里添加一个 register.go 文件(v1/register.go)
自定义控制器
1.编写main函数
2.编写自定义控制器定义
3.编写控制器的业务逻辑
Informer机制
Reflector使用ListAndWatch方法来获取并监听对象实例的变化 一旦任何一个实例有任何变化Reflector都会收到事件通知
收到通知后把(事件和对象)的组合存入一个先进先出的队列中
Informer不断从队列中读取对象 判断事件的类型 然后创建或者更新本地对象的缓存 同步本地缓存的工作 是Informer的重要职责
Informer的第二个职责 就是根据事件的类型 触发事先注册好的ResourceEventHandler
通过监听到的事件变化,Informer 就可以实时地更新本地缓存,并且调用这些事件对应的EventHandler了
每经过 resyncPeriod 指定的时间,Informer 维护的本地缓存,都会使用最近一次 LIST 返回的结果强制更新一次,从而保证缓存的有效性
所谓的 Informer,就是一个自带缓存和索引机制,可以触发 Handler 的客户端库。
这个本地缓存在 Kubernetes 中一般被称为 Store,索引一般被称为 Index.Informer 使用了 Reflector 包,它是一个可以通过 ListAndWatch 机制获取并监视 API 对象变化的客 户端封装.Reflector 和 Informer 之间,用到了一个“增量先进先出队列”进行协同.
而 Informer与你要编写的控制循环之间,则使用了一个工作队列来进行协同.在实际应用中,除了控制循环之外的所有代码,实际上都是 Kubernetes 为你自动生成的
控制循环的逻辑
1.等待Informer完成一次本地缓存的数据同步操作
2.通过goroutine启动一个或多个无限循环任务
3.在每一个循环周期中 执行的就是用户真正关心的业务逻辑代码
1.如果控制循环在Informer缓存中获取不到相应的对象的信息 说明要执行删除逻辑
2.如果从缓存中获取到对象信息 就执行控制器模式对比期望状态和实际状态 期望状态来自于etcd 实际状态来自于集群本身
这套流程不仅可以用在自定义API资源上也完全可以用在Kubernetes原生的默认API 对象上
这就使得在这个自定义控制器里面,我可以通过对自定义API对象和默认API 对象进行协同,从而实现更加复杂的编排功能
只需要关注如何拿到“实际状态”,然后如何拿它去跟“期望状态”做对比,从而决定接下来要做的业务逻辑即可 这个就是Kubernetes API编程范式的核心思想