终于搞懂了,方差协方差,协方差矩阵都是些啥了,以及他们到底是怎样计算出来的,他们之间有什么样关系,接下来就将自己整理出来的知识点做整理,仅供参考,如若有什么问题,还请指教!
参考链接
方差
什么是方差?
一句话:方差是衡量源数据和期望值相差的度量值!
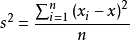
一组数组X1.X2.X3…Xn,各数据与平均数x的差的平方的和来衡量这组数据的波动大小,并且把它叫做这组数据的方差,方差越小越稳定!
标准方差:
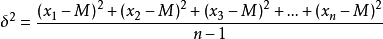
在计算方差时,可以用到numpy中的var()函数,np.var()默认是总体方差,若计算样本方差或标准方差时,需要加参数ddof=1
直接看代码
import numpy as np
num_array= np.array([1, 2, 3, 4, 5, 6])
variance = np.var(num_array) # 计算总体方差
print("variance", variance)
standard_variance = np.var(num_array, ddof=1) # 计算标准方差
print("standard_variance", standard_variance)
num_matrix = [[10, 11], [12, 13]]
matrix_variance = np.var(num_matrix) # 计算矩阵所有元素的方差
print("matrix_variance", matrix_variance)
row = np.var(num_matrix, axis=0) # 计算矩阵每一列的方差
print("row", row)
line = np.var(num_matrix, axis=1) # 计算矩阵每一行的方差
print("line", line)
打印结果

还可以利用pandas中的var计算方差
df = pd.DataFrame(
np.array([[91, 97, 89, 95, 89, 96, 557],
[89, 100, 90, 90, 88, 97, 554],
[88, 97, 93, 93, 89, 91, 551],
[96, 90, 97, 90, 86, 92, 551],
[89, 94, 95.5, 85, 85, 96, 544.5],
[89, 94, 93.5, 86, 81, 95, 538.5],
[87, 93, 93, 84, 77, 98, 532],
[81, 97, 90.5, 89, 75, 98, 530.5],
[83, 93, 94.5, 87, 74, 98, 529.5],
[87, 97, 92, 77, 77, 98, 528]]),
columns=['chinese','math','english','physics','chemistry','politics','total'],
index=['1','2','3','4','5','6','7','8','9','10'])
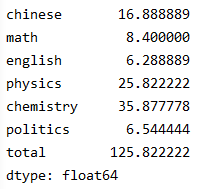
print(df.var()) #打印每一列的方差
print(df.var(axis=1)) #打印每一行的方差
print(df.iloc[0,:].var()) #打印第一行的方差
依次为每一列,每一行,第一行方差

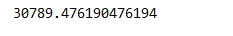
在这里要注意的是pandas操作的数据集是Series,本质上是列表与字典的混合,常用DataFrame,numpy操作的是数组或者矩阵。
同时需要注意:总体方差:方差公式根号内除以n,是有偏的。
样本方差:方差公式根号内除以n-1,是无偏的。
numpy需要制定ddof的值,当ddof为0时,计算总体方差,当ddof为1时计算样本方差
pandas,计算方差时,与numpy时相反的,这是在用numpy和pandas计算时需要注意的地方!!!!
协方差
协方差与相关性
先放原文链接!!!
https://www.zhihu.com/question/20852004/answer/134902061
方差是衡量一个数据的,协方差就是衡量两个数据
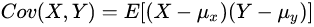
可以理解为,两个变量在变化过程中是相同还是相反方向变化。
XY同时变大,说明两个变量同向变化,这时协方差就是正的
X变大Y变小,说明两个变量是反向变化,这时协方差就是负的
协方差的数值越大,两个变量同向程度也就越大。反之亦然。
假如有两个变量XY,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每个时刻的乘积求和并求出均值
下边是原文,讲解的非常透彻!!!
https://www.zhihu.com/question/20852004/answer/134902061
简单来说就是协方差如果为正 说明X,Y同向变化,协方差越大说明同向程度越高,协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高!
那么,如果X,Y同向变化,但是X大于均值,Y小于均值,那么X-μx与Y-μy的乘积为负,
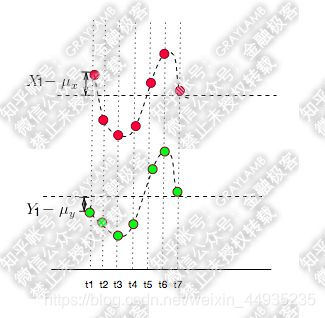
此时我们看到在t1时刻他们的乘积为负值,但不能说明他们是反向运动的,此时你还要计算t2到t7时刻的值,显然最后很大可能是正的,所以t1时刻的值为负,其他时刻的值为正,就不能说明他们是反向的运动
如果t1-t7时刻X,Y都在增大,X都比均值大,Y都比均值小,这种情况怎么考虑,7个负值求平均还是负值啊????但XY又都是增大的?这是不是就矛盾了???
其实这就很好理解了 因为你的均值计算错了,看图
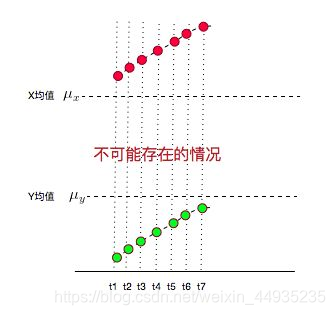
不可能出现这种情况,此时你的X和Y应该分布在均值两侧,说明你的均值计算的有问题。
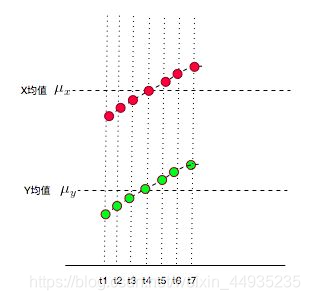
所以应该是这样的才对XY都在增大,做同向运动。
那什么是相关系数
先看公式
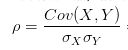
就是X,Y的协方差除以X,Y的标准差
所以,可以理解为一种特殊的协方差,那么也可以反映两个变量的方向,只是单纯反应两个变量每单位变化时的相似程度。
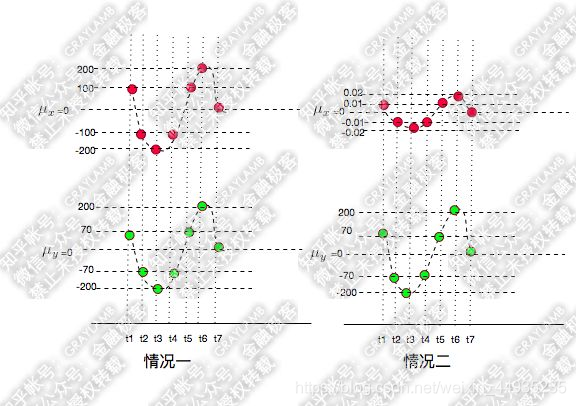
此时XY都是同向变化的,而且他们极度的相似。
计算一下他们的协方差:
第一种情况下:
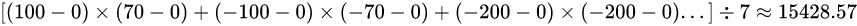
第二种情况下:

只能判断出XY在做同向变化,但不能判断XY都具有相似性这一特点,这两种差距太大了!
那么此时为了研究两个变量在变化过程中的相似程度,我们就要消除变化幅度对协方差的影响,此时就用到了相关系数!
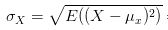
标准差计算方法为,每一时刻变量值与变量均值之差在平方,在将每一个时刻这个数值相加后求平均,在开方
X-μx就是偏离均值的幅度,下边这个情况就是X-μx为负值,平方后就消除这个负号了,这样在后边求平均时,每一项才不会正负抵消,最后才能看出每次变化偏离均值的情况。
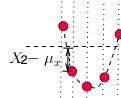
所以就有了标准差的公式了,所以标准差描述了变量在整体变化过程中偏离均值的幅度,协方差除以标准差,也就是把协方差中变量变化幅度对协方差的影响剔除掉,这样协方差就标准化了。它反映的就是两个变量每单位变化时的情况,也就是相关系数公式的含义了。
他们的相关系数范围在1到-1之间变化,当相关系数为1时,说明两个变量整箱相似度最大,当相似度为0时说明他们没有任何的相关性,当相似度为-1时,说明他们反向相似度最大。
此时我们计算X的标准差:
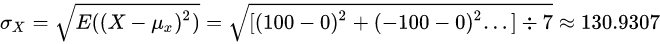
Y的标准差为:
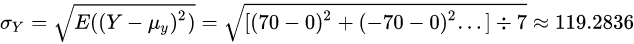
相关系数为:
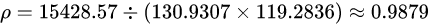
这是第一种情况的下的相似度,XY具有很高的相似性。
第二种情况:
X的标准差:
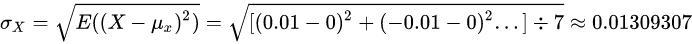
Y的标准差:
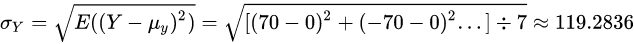
相关系数为:
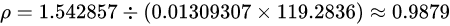
此时我们也可以看到XY具有很高的相似性。但很明显比第一种情况下变化幅度小了很多倍,依然具有很高的相似性。
再一次放上原文链接讲的太透彻了
原文链接
那么了解了方差和协方差之后再来了解一下什么叫协方差矩阵!
协方差矩阵
因为后边要做一些数据分析的项目,所以这边也是找了点资料来看看,接下来就通俗易懂的解释一下协方差矩阵
根据方差定义,随机给出一组变量,这些随机变量的方差为:
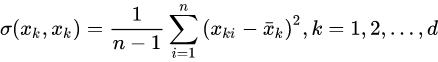
其中Xki为随机变量Xk中的第i个观测样本,n表示样本量,每个随机变量所对应的观测样本量均为n
根据协方差定义,算出两两之间的协方差:
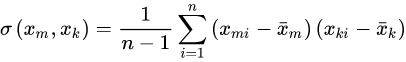
所以协方差矩阵为:
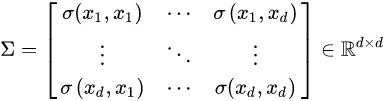
其中,对角线上的元素为各个随机变量的方差,非对角线上的元素为两两随机变量之间的协方差,根据协方差定义,矩阵Σ为对称矩阵,其大小为d*d
python的numpy.cov()函数
numpy.cov(m, y=None, rowvar=True, bias=False, ddof=None, fweights=None, aweights=None)
(1) m :array_like
包含多个变量和观察值的1-D或2-D数组。M的每一行代表一个变量(即特征),每一列都是对所有这些变量的单一观察(即每一列代表一个样本)。 另见下面的rowvar。
(2) y :array_like, optional
另外一组变量和观察结果。 y具有与m相同的形式。至于有什么作用,参考后面的实例。
(3) rowvar : bool,optional
如果rowvar为True(默认值),则每行代表一个变量,并在列中显示(即每一列为一个样本)。 否则,关系被转置:每列代表变量,而行包含观察值。
(4) bias : bool,optional
默认归一化(False)为(N-1),其中N为给定观测次数(无偏估计)。如果bias为True,则归一化为N. 这些值可以通过使用numpy版本> = 1.5中的关键字ddof来覆盖。
(5) ddof : int,optional
如果不是,偏移所隐含的默认值将被覆盖。请注意,ddof = 1将返回无偏估计,即使指定了权重和权重,ddof = 0将返回简单平均值。详见附注。 默认值为None。
(6) fweights :array_like, int, optional
整数频率权重组成的1-D数组; 代表每个观察向量应重复的次数。
(7) aweights :array_like, optional
观测矢量权重的1-D数组。对于被认为“重要”的观察,这些相对权重通常很大,而对于被认为不太重要的观察,这些相对权重较小如果ddof = 0,则可以使用权重数组将概率分配给观察向量。
具体看官网的例子:
官网链接
首先要明确协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间,因为拿到一个样本矩阵,我们要先确定样本矩阵每行代表一个样本还是每列代表一个样本。
实例:
x=[4,5,3]
y=[6,2,1]
print(np.cov(x,y))
输出结果

那么cov函数到底给我们做了些什么,此时就用到我们之前整理的知识了,明确了方差和协方差的定义后我们也可以通过笔算得到我们想要的结果。
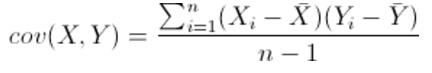
明确了这个公式的定义就对我们理解协方差矩阵起到非常大的作用,协方差矩阵就是多个协方差组成的矩阵,上边代码中讨论的是两个变量之间的协方差矩阵。

我们看到计算的结果和上边的一样的,如果还不知道怎么计算,自己拿出笔写写画画就会了!
那对于多维数组的计算也是一样的
import numpy as np
x=np.array([[1,2,3,4],
[3,4,7,2],
[6,4,1,3]])
print(np.cov(x))
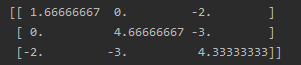
这就是计算的结果,这里不写详细过程了,不会的可以到前边看看,然后自己算算就可以了。
