文章目录
- 1、相关安装包以及规划
- 2、设置hostname
- 3、配置免密ssh
- 4、配置Java环境
- 5、配置Hadoop环境
- 5.1 配置hadoop-env.sh
- 5.2 core-site.xml
- 5.2 hdfs-site.xml
- 5.3 mapred-site.xml
- 5.4 yarn-site.xm;
- 5.5 workers
- 5.6 设置start-dfs.sh 和 stop-dfs.sh
- 5.7 设置start-yarn.sh 和 stop-yarn.sh
- 5.8 将hadoop包添加到linux环境变量,三个节点都需要加这个hadoop环境设置
- 5.9 初始化hadoop文件系统
- 6 启动hadoop服务
- 7、跑个wordcount 测试
- 7.1 在namenode节点上的hadoop文件系统的根目录路上创建一个目录
- 7.2 hdfs常用命令
- 7.1 将测试文件添加到hadoop系统的指定目录
- 7.2 运行word count java示例程序
- 最后
- Trouble shooting
1、相关安装包以及规划
考虑本地测试使用,这里所使用的三台服务器均有虚拟机创建,每台配置:1个vCPU+1G内存+9G硬盘
Hadoop:Hadoop-3.1.2
JDK: jdk1.8.0_161
| Ip | 角色 | hadoop路径 | Hostname | jdk路径 | linux版本 |
|---|---|---|---|---|---|
| 192.188.0.4 | NameNode,Datanode,NodeManager | /opt/hadoop-3.1.2 | nn | /opt/jdk1.8.0_161 | Centos7.5 |
| 192.188.0.5 | DataNode,ResourceManager,NodeManager,JobHistoryServer | /opt/hadoop-3.1.2 | dn1 | /opt/jdk1.8.0_161 | Centos7.5 |
| 192.188.0.6 | DataNode,Secondarynode,NodeManager | /opt/hadoop-3.1.2 | dn2 | /opt/jdk1.8.0_161 | Centos7.5 |
这里列出节点服务的基础介绍:
hadoop平台相关:
NameNode:
接收用户操作请求
维护文件系统的目录结构
管理文件与block之间关系,block与datanode之间关系
DataNode:
存储文件
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
Secondary NameNode:
合并来自namenode的fsimage和edits文件来更新namenode的metedata
yarn平台相关:
ResourceManager:
集群中所有资源的统一管理和分配,它接受来自各个节点的NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序,是整个yarn集群中最重要的组件之一。
JobHistoryServer:
历史服务器,可以通过历史服务器查看已经运行完成的Mapreduce作业记录,比如用了多少个Map、多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,历史服务器是没有启动的,需要进行参数配置才能启动
NodeManager:
运行在单个节点上的代理,管理hadoop集群中单个计算节点,它需要与相应用程序ApplicationMaster和集群管理者ResourceManager交互
从ApplicationMaster上接收有关Contioner的命令并执行
向ResourceManager汇报各个Container运行状态和节点健康状况,并领取有关的Container的命令并执行
2、设置hostname
分别对三个节点更改对应的hostname
[root@nn ~]# vi /etc/hostname
nn
[root@dn1 ~]# vi /etc/hostname
dn1
[root@dn2 ~]# vi /etc/hostname
dn2
配置域名解析,三个节点都需要配置
[root@dn2 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.188.0.4 nn
192.188.0.5 dn1
192.188.0.6 dn2
# 无需重启,直接ping主机名称
[root@dn2 ~]# ping nn
PING nn (192.188.0.4) 56(84) bytes of data.
64 bytes from nn (192.188.0.4): icmp_seq=1 ttl=64 time=0.322 ms
64 bytes from nn (192.188.0.4): icmp_seq=2 ttl=64 time=0.347 ms
3、配置免密ssh
3.1 对三台服务器设置ssh公钥
[root@nn /]# ssh-keygen -t rsa
# 手动创建 authorized_keys文件
[root@nn .ssh]# ls
id_rsa id_rsa.pub
[root@nn .ssh]# cp id_rsa.pub authorized_keys
其他两个节点同样操作
3.2 在nn节点将自己公钥拷贝到其他两个节
# 三个节点都需要操作
[root@nn ~]# ssh-copy-id nn
[root@nn ~]# ssh-copy-id dn1
[root@nn ~]# ssh-copy-id dn2
# 测试免密登录
[root@nn ~]# ssh dn1
[root@nn ~]# ssh dn2
4、配置Java环境
本项目中,java包、hadoop包、spark包都放在/opt目录下,三个节点都需配置
# java包路径
[root@nn jdk1.8.0_161]# pwd
/opt/jdk1.8.0_161
# 配置环境变量
# vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# 生效配置
source /etc/profile
# 查看版本
[root@nn jdk1.8.0_161]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
5、配置Hadoop环境
Hadoop路径/opt/hadoop-3.1.2,以下为hadoop文件目录的简要说明
| Bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现 。用户可以直接使用这些脚本管理和使用Hadoop |
|---|---|
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| etc | Hadoop的配置文件所在的目录,各类**.xml配置文件夹 |
| lib | 该目录下存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本, |
| share | Hadoop各个模块编译后的jar包所在的目录,也官方自带的doc手册 |
| logs | (hadoop初始化之后才会自动生成)该目录存放的是Hadoop运行的日志,查看日志对寻找Hadoop运行错误非常有帮助。 |
| namenode_dir | 在hdfs-site.xml配置后,hadoop首次启动会创建该目录,目录下包含edit文件和fsimage |
| datanode_dir | 在hdfs-site.xml配置后,hadoop首次启动会创建该目录:存放数据文件 |
5.1 配置hadoop-env.sh
给hadoop配置Java路径,三个节点都需要配置,但无需每台去设置,因为后面会把整个/opt/hadoop-3.1.2/etc/hadoop拷贝到另外两个dn节点
[root@nn hadoop]# pwd
/opt/hadoop-3.1.2/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_161
5.2 core-site.xml
<configuration>
<!-- namenode用9000根datanode通信 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn:9000</value>
</property>
<!--hadoop临时文件路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.2/tmp</value>
</property>
</configuration>
5.2 hdfs-site.xml
<configuration>
<!-把dn2 设为secondary namenode,端口不能缺少 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>dn2:50090</value>
</property>
<!-- namenode 上存储 hdfs 名字空间元数据-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.1.2/namenode</value>
</property>
<!-- datanode 上数据块的物理存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-3.1.2/datanode</value>
</property>
<!-- 设置 hdfs 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
5.3 mapred-site.xml
<configuration>
<!-- 指定Yyarn运行-->
<property>
<name>mapreduce.framework.name</name>
<value>Yyarn</value>
</property>
<!-- 打开Jobhistory -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>dn1:10020</value>
</property>
<!-- 指定dn1作为jobhistory服务器 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>dn1:19888</value>
</property>
<!-- 注意这里的路径不是Linux文件路径,而是hdfs文件系统上的路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!-- mp所需要hadoop环境 -->
<property>
<name>Yyarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.2</value>
</property>
</configuration>
5.4 yarn-site.xm;
<configuration>
<!-- Site specific yarn configuration properties -->
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dn1</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.5 workers
三个节点都设为datanode,当然也生产环境中,负责数据物理文件存储DD不要跟DN放在同一台服务器
[root@nn hadoop-3.1.2]# vi etc/hadoop/workers
nn
dn1
dn2
5.6 设置start-dfs.sh 和 stop-dfs.sh
在/opt/hadoop-3.1.2/sbin/start-dfs.sh 文件开头
[root@nn hadoop-3.1.2]# vi sbin/start-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
5.7 设置start-yarn.sh 和 stop-yarn.sh
都是在文件开头处添加
[root@nn hadoop-3.1.2]# vi sbin/start-yarn.sh
yarn_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
yarn_NODEMANAGER_USER=root
5.8 将hadoop包添加到linux环境变量,三个节点都需要加这个hadoop环境设置
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
直接将以上的配置文件所在目录拷贝到另外两个节点上,避免繁琐配置
[root@nn hadoop-3.1.2]# scp -r /opt/hadoop-3.1.2/etc/hadoop/ dn1:/opt/hadoop-3.1.2/etc/
[root@nn hadoop-3.1.2]# scp -r /opt/hadoop-3.1.2/sbin dn1:/opt/hadoop-3.1.2/
5.9 初始化hadoop文件系统
因为nn是作为namenode管理节点,因此只需在nn节点进行相应的格式化
[root@nn bin]# pwd
/opt/hadoop-3.1.2/bin
[root@nn bin]# hdfs namenode -format
****
*** INFO common.Storage: Storage directory /opt/hadoop-3.1.2/namenode has been successfully formatted.
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at nn/192.188.0.4
以上说明namenode格式化成功
6 启动hadoop服务
6.1 在namenode上启动服务
一键启动所有:如果使用start-all.sh,表示把集群的所有配置的服务都启动,它会调用start-dfs.sh和start-yarn.sh
单个节点启动:使用start-dfs.sh和start-yarn.sh,这里要注意,比如nn节点是作为namenode节点,那么在nn节点执行start-dfs.sh,无需执行start-yarn.sh
网上绝大部分教程会教你用start-all.sh启用集群服务,但这不是官方的推荐方式,个人推荐在每个节点启动相应服务
nn节点:NameNode,Datanode,NodeManager,只需运行start-dfs.sh
[root@nn ~]# start-dfs.sh
dn1节点:DataNode,ResourceManager,NodeManager,因为需要使用yarn服务,且作为ResourceManager节点(本身也是NodeManager),需运行start-yarn.sh
此外:dn1节点还是作为yarn主节点的JobHistoryServer服务,还需通过命令mapred --daemon start historyserver启动之,启动JobHistoryServer后,可以在yarn的web服务直观查看每个job的运行历史,后面会给截图
[root@dn1 ~]# start-yarn.sh
[root@dn1 sbin]# pwd
/opt/hadoop-3.1.2/sbin
[root@dn1 sbin]# mapred --daemon start historyserver
dn2节点:DataNode,Secondarynode,NodeManager,因为nn节点的hdfs-site.xml已经配置了dn2节点作为sn节点,那么nn节点启动服务时,就已经自动在dn2节点启动了Secondarynode进程。
查看各个节点服务进程:
[root@nn ~]# jps
9957 NameNode
10553 Jps
10092 DataNode
10430 NodeManager
[root@dn1 ~]# jps
31792 DataNode
32133 NodeManager
32492 Jps
31998 ResourceManager
17428 JobHistoryServer
[root@dn2 ~]# jps
31105 NodeManager
30898 DataNode
31235 Jps
31005 SecondaryNameNode
也可通过查看web服务来确认NameNode服务和yarn服务
NN入口:http://192.188.0.4:9870/
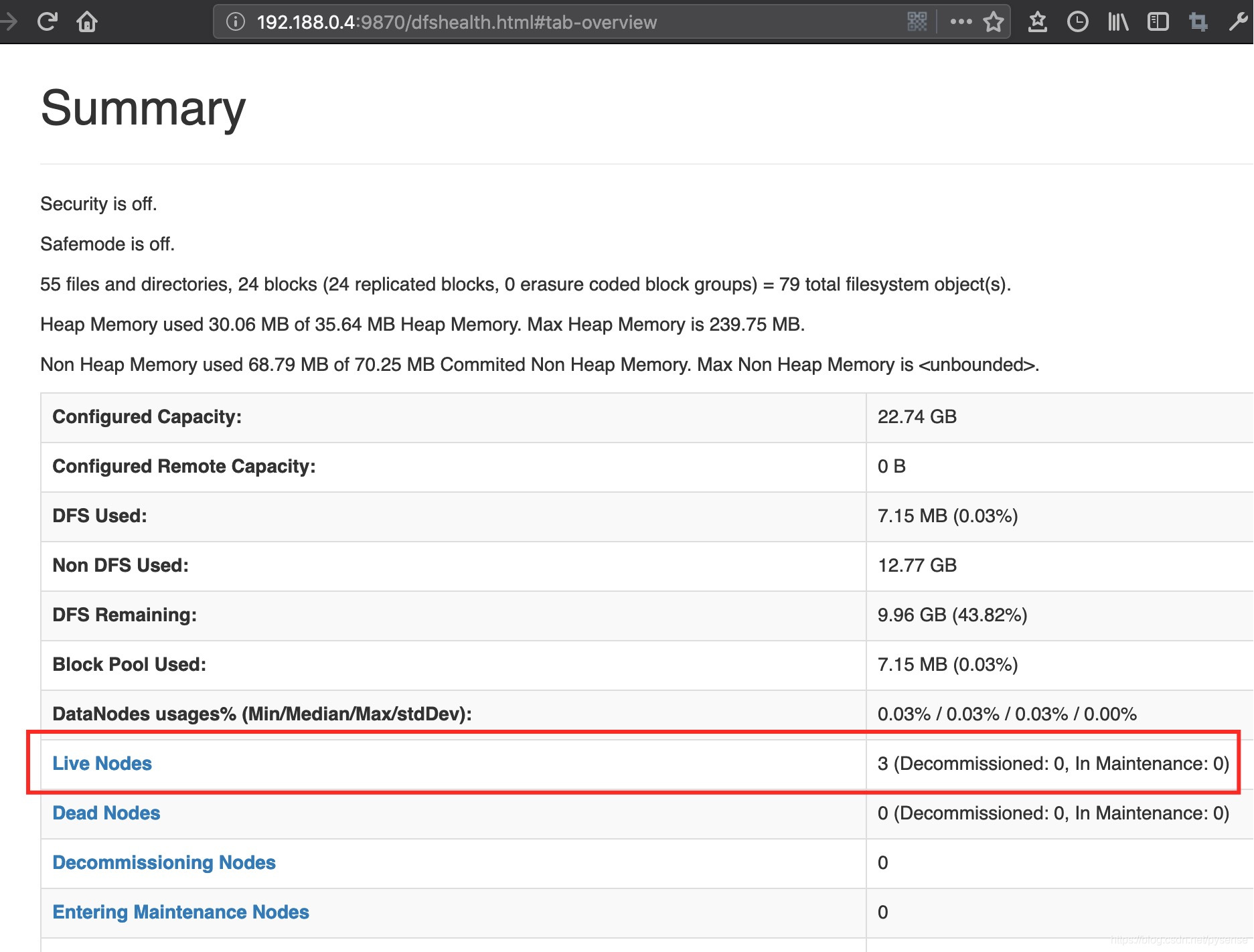
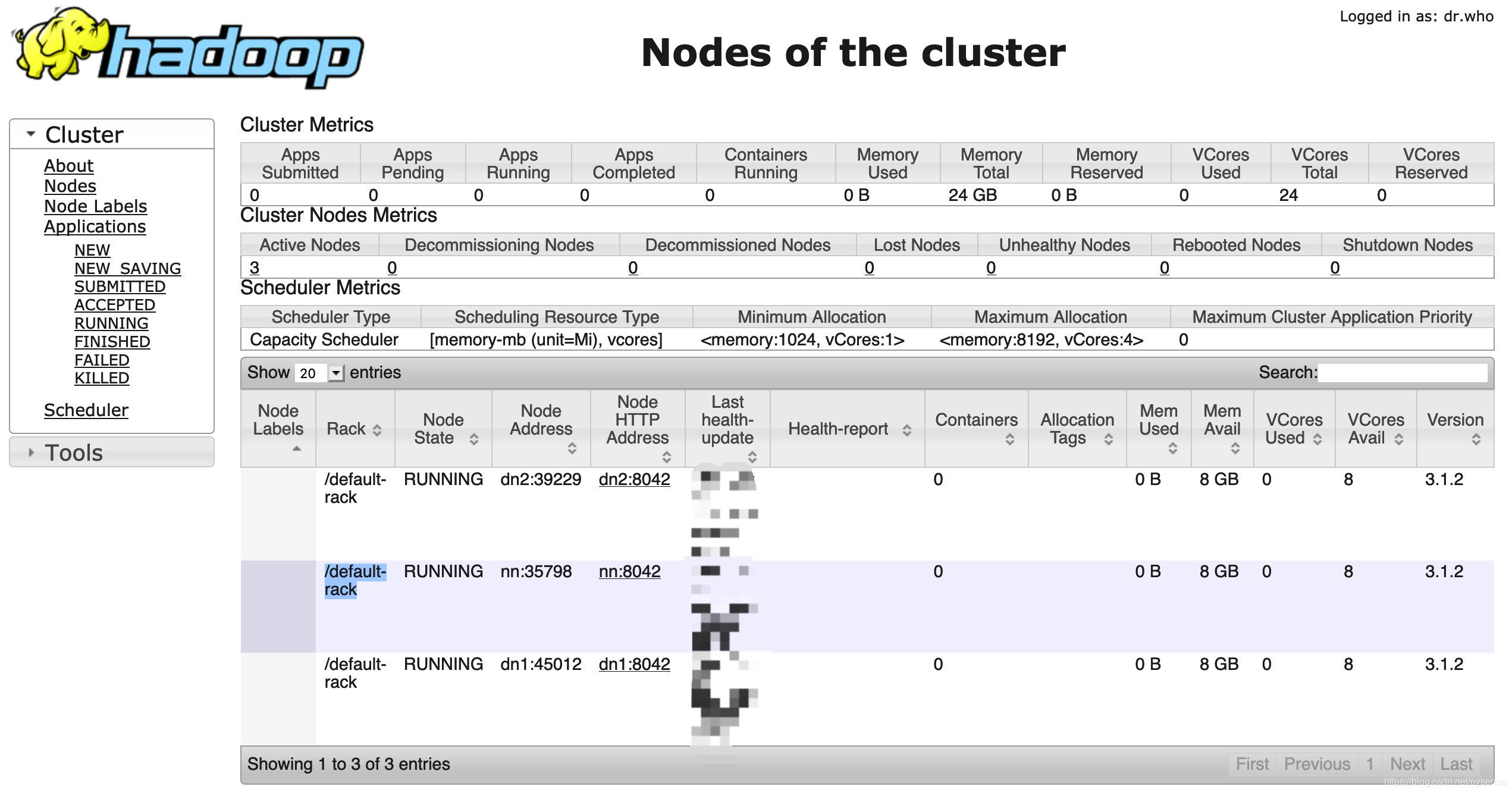
yarn入口:http://192.188.0.5:8088
也可通过起一个python http服务查看hadoop自带的手册,手册html文件在
/opt/hadoop-3.1.2/share/doc/hadoop,里面有index.html,故只需在该目录下,开启一个后台web 服务,即可在 浏览器打开其网页
[root@nn hadoop]# ls
api hadoop-fs2img
css hadoop-gridmix
dependency-analysis.html hadoop-hdfs-httpfs
***
***
hadoop-dist images
hadoop-distcp index.html
hadoop-extras project-reports.html
[root@nn hadoop]# python -m SimpleHTTPServer 8000 &
7、跑个wordcount 测试
7.1 在namenode节点上的hadoop文件系统的根目录路上创建一个目录
# 创建测试目录,可以使用
[root@nn hadoop-3.1.2]# hadoop fs -mkdir /app
# 或者
[root@nn hadoop-3.1.2]# hdfs dfs -mkdir /app
# 查看hadoop文件系统的根目录下的结构
[root@nn hadoop-3.1.2]# hadoop fs -ls /
Found 2 items
drwxr-xr-x - root supergroup ** /app
drwxr-xr-x - root supergroup ** /word-count-app
以上目录的创建,也会在datanode同步创建
[root@dn1 ~]# hadoop fs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 ** /app
drwxr-xr-x - root supergroup 0 ** /word-count-app
7.2 hdfs常用命令
具体详细命令用户,官网给出非常仔细的说明:
http://hadoop.apache.org/docs/r3.1.2/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
列出 hdfs 下的文件
$ hdfs dfs -ls
列出 hdfs / 路径下的所有文件,文件夹
$ hdfs dfs -ls -R /
创建目录 /app
$ hdfs dfs -mkdir /app
列出 hsfs 名为 input 的文件夹中的文件
$ hadoop dfs -ls app
将 words.txt 上传到 hdfs 中
$ hdfs dfs -put /hadoop_test/words.txt /app
将 hsdf 中的 words.txt 文件保存到本地
$ hdfs dfs -get /app/words.txt /hadoop_test/words.txt
删除 hdfs 上的 test.txt 文件
$ hadoop dfs -rmr /hadoop_test/words.txt
查看 hdfs 下 app 文件夹中的内容
$ hadoop fs -cat app/*
进入安全模式
$ hadoop dfsadmin –safemode enter
退出安全模式
$ hadoop dfsadmin -safemode leave
报告 hdfs 的基本统计情况
$ hadoop dfsadmin -report
7.1 将测试文件添加到hadoop系统的指定目录
[root@nn opt]# cat hadoop_example/words.txt
foo is foo
bar is not bar
hadoop file system is the infrastructure of bigdata
[root@nn opt]# hdfs dfs -put hadoop_example/words.txt /app
[root@nn opt]# hdfs dfs -ls /app
Found 1 items
-rw-r--r-- 3 root supergroup 76 ** /app/words.txt
也可以通过web端查看fs目录结构和文件内容,直观易用
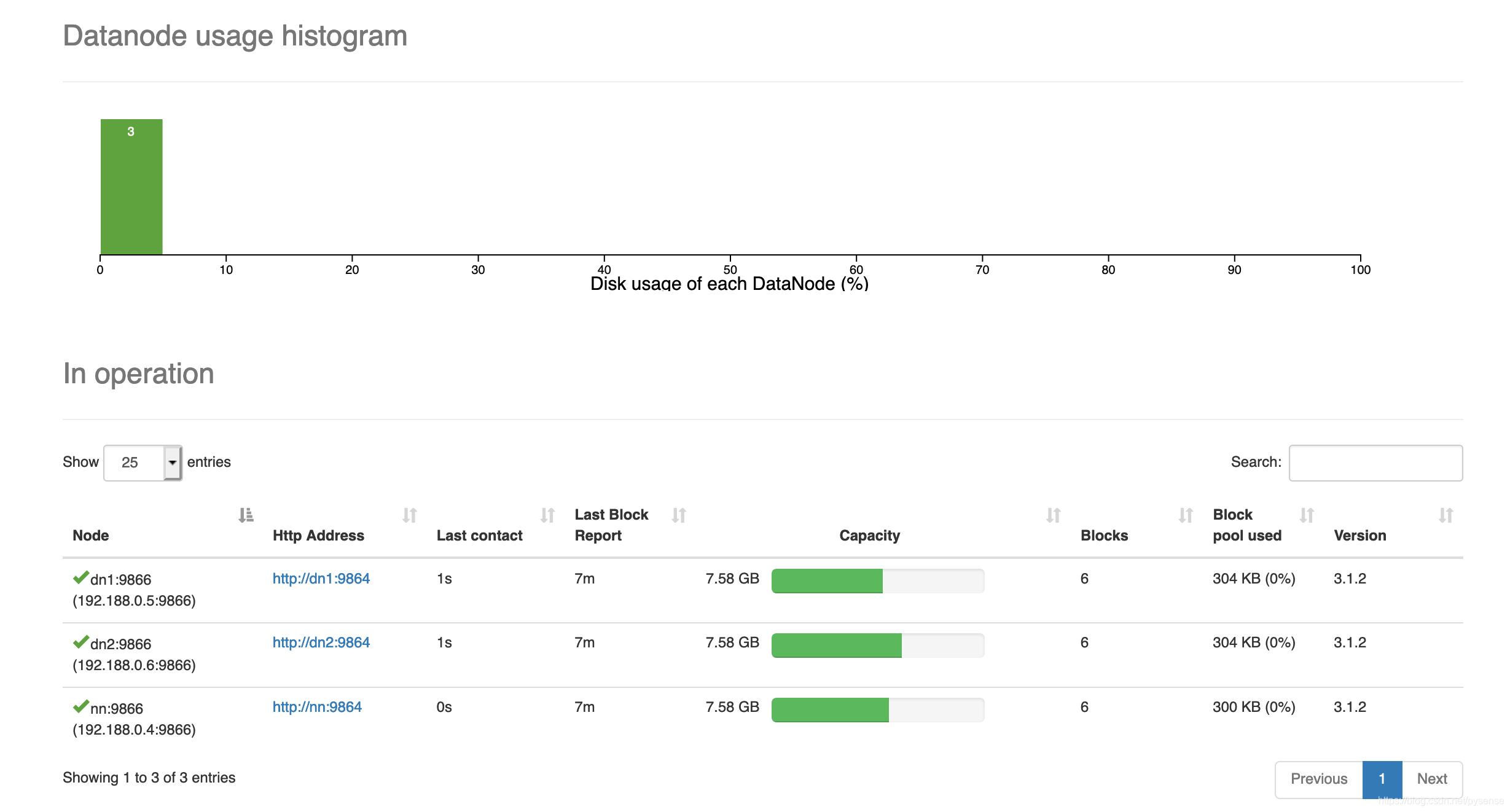
7.2 运行word count java示例程序
例程序在此路径:/opt/hadoop-3.1.2/share/hadoop/mapreduce
[root@nn mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /app /result
**,500 INFO mapreduce.Job: map 50% reduce 0%
**,653 INFO mapreduce.Job: map 100% reduce 0%
**,685 INFO mapreduce.Job: map 100% reduce 100%
**,715 INFO mapreduce.Job: Job job_1***** completed successfully
**,837 INFO mapreduce.Job: Counters: 55
以上表示成功运行一个计算实例
查看计算结果,计算放在hdfs文件系统/result目录下,其中 /result/part-r-00000为计算结果,可以查看其输出内容:
[root@nn ~]# hdfs dfs -cat /result/part-r-00000
bar 2
big 1
data 1
file 1
foo 2
hadoop 2
infrastructure 1
is 3
not 1
spark 2
system 1
the 1
zookeeper 2
当然,因为我们引入yarn调度框架,并且有dn1节点提供yarn服务,当然可以对此次map-reduce计算任务job在web端查看。
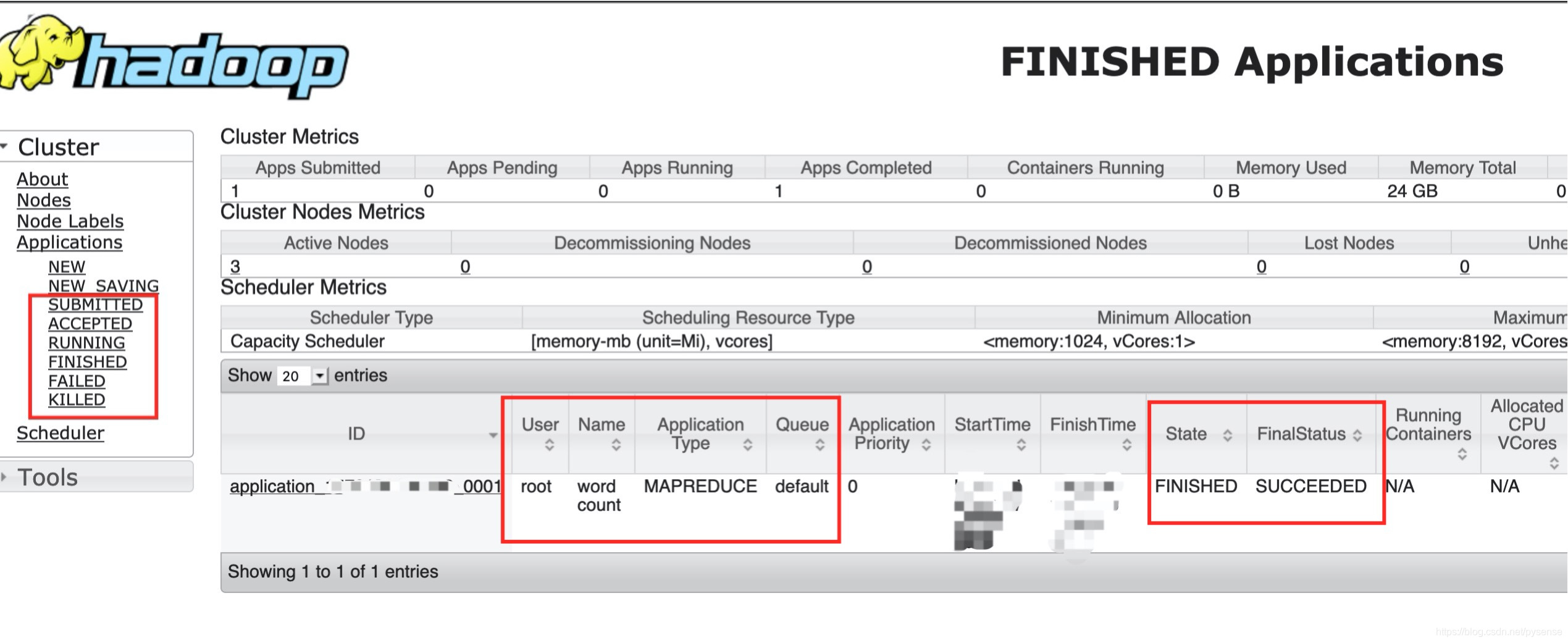
最后
以上为完整的基于hadoop3.1.2真实集群并引入yarn管理的文章讨论,给出了完整部署流程和测试案例,保证本次部署过程的可行性。注意到本文的hadoop集群中还不是HA模式,生产环境需要部署HA模式,后面的文章中我们将引入Zookeeper,给出HA模式的部署过程(zk文章在本博客已经有深入的探讨,目的也是为了后面大数据架构部署)
Trouble shooting
1、运行word count时,yarn提示任务虚拟运行内存不足
Container [pid=17786,containerID=container_****002_01_000003] is running 459045376B beyond the ‘VIRTUAL’ memory limit. Current usage: 61.8 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container
回答这个问题前,首先要理解yarn集群中Container的概念
-
在yarn的NodeManager节点上,会将集群中所有节点的CPU和内存的一定值抽离出来,组成一个“资源池”,例如资源池是100,这个资源池根据配置(例如设置大哥容器申请的资源最大值为10)可以分成多个Container(100/10=10个可供Job使用的容器),当Application(在MapReduce时期叫Job)提出申请时,就会分配相应的Container资源,因此Container其实是yarn中的一个动态资源分配的概念,其拥有一定的内存,核数,由RM分配给ApplicationMaster或者MapTask或者ReduceTask使用,这些task就在Container为基础的容器中运行起来。
-
通俗点说,Container就是“一组资源:内存+CPU”,它跟Linux Container没有任何关系,仅仅是yarn提出的一个概念,当有一个Application来想RM节点申请资源是,第一个Container用来跑ApplicationMaster,然后ApplicationMaster再申请一些Container来跑Mapper,之后再申请一些Container来跑Reducer。
-
当Mapper或者Reducer所需的“资源之一虚拟内存大于Container默认提供值时”,以上问题就会出现:beyond the ‘VIRTUAL’ memory limit.
解决办法有两种
A、降低Mapper或者Reducer所需内存资源配置值,在mapred-site.xml 进行配置
<property>
<name>mapreduce.map.memory.mb</name>
<value>100</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>200</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx100m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx200m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
B、配置RM针对单个Container能申请的最大资源或者RM本身能配置的最大内存
配置解释:单个容器可申请的最小与最大内存,Application在运行申请内存时不能超过最大值,小于最小值则分配最小值,例如在本文测试中,因计算任务较为简单,无需太多资源,故最小值设为50M,最大值设为100M
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>100</value>
</property>
配置解释:NM的内存资源配置,主要是通过下面两个参数进行的
第一个参数:每个节点可用的最大内存,默认值为-1,代表着yarn的NodeManager占总内存的80%,本文中,物理内存为1G
第二个参数:NM的虚拟内存和物理内存的比率,默认为2.1倍
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
vmem-pmem-ratio的默认值为2.1,由于本机器中,每个节点的物理内存为1G,因此单个RM拿到最大虚拟内存为2.1G,从2.5 GB of 2.1 GB virtual memory used. Killing container,可知,Container申请的资源为2.5G,已经超过默认值2.1G,当改为3倍时,虚拟化够用,故解决了问题。
2、org.apache.hadoop.yarn.exceptions.yarnException:Unauthorized request to start container
出错原因:Hadoop集群(本文也包含yarn集群)中多个节点的时间不同步导致.
解决:修改多个节点的时间为相同的时间
# 将硬件时间写到系统时间
[root@dn1 ~]# hwclock -s
保存时钟
[root@dn1 ~]# clock -w
