文章目录
在前面的 文章中,详细给出了HBase HA高可用部署以及测试的内容,本篇文章将对HBase架构进行分析。
1、有关HBase基本介绍
1.1 HBase解决的痛点:
- 解决随机近实时的高效的读写
- 解决非结构化的数据存储
1.2 HBase应用:
- 可以存储非结构化的数据
- 被用来做实时数据分析(整合flume、storm、streaming等)
引用HBase作为业务存储,则需要注意的点(按官方指引的翻译):
首先确保使用场景有足够多的数据,上亿或者十几亿行的数据,HBase将非常适合
第二,确保业务需求中不需要用到关系型数据库那种严格的索引、事务、高级查询等
第三点,确保足够多的硬件服务器,至少5台个HDFS节点以上,以便发挥HDFS性能。
1.3 Hbase特性:
-
Hadoop的分布式、开源的、多版本的非关系型数据库
-
Hbase存储Key-Value格式,面向列存储,Hbase底层为byte[]比特数组数据,不存在数据类型一说。
-
严格一致的读写
-
表的自动和可配置分片
-
RegionServer之间的自动故障转移支持
-
方便的基类,用于通过Apache HBase表备份Hadoop MapReduce作业
-
块缓存和布隆过滤器用于实时查询
2、HBase架构
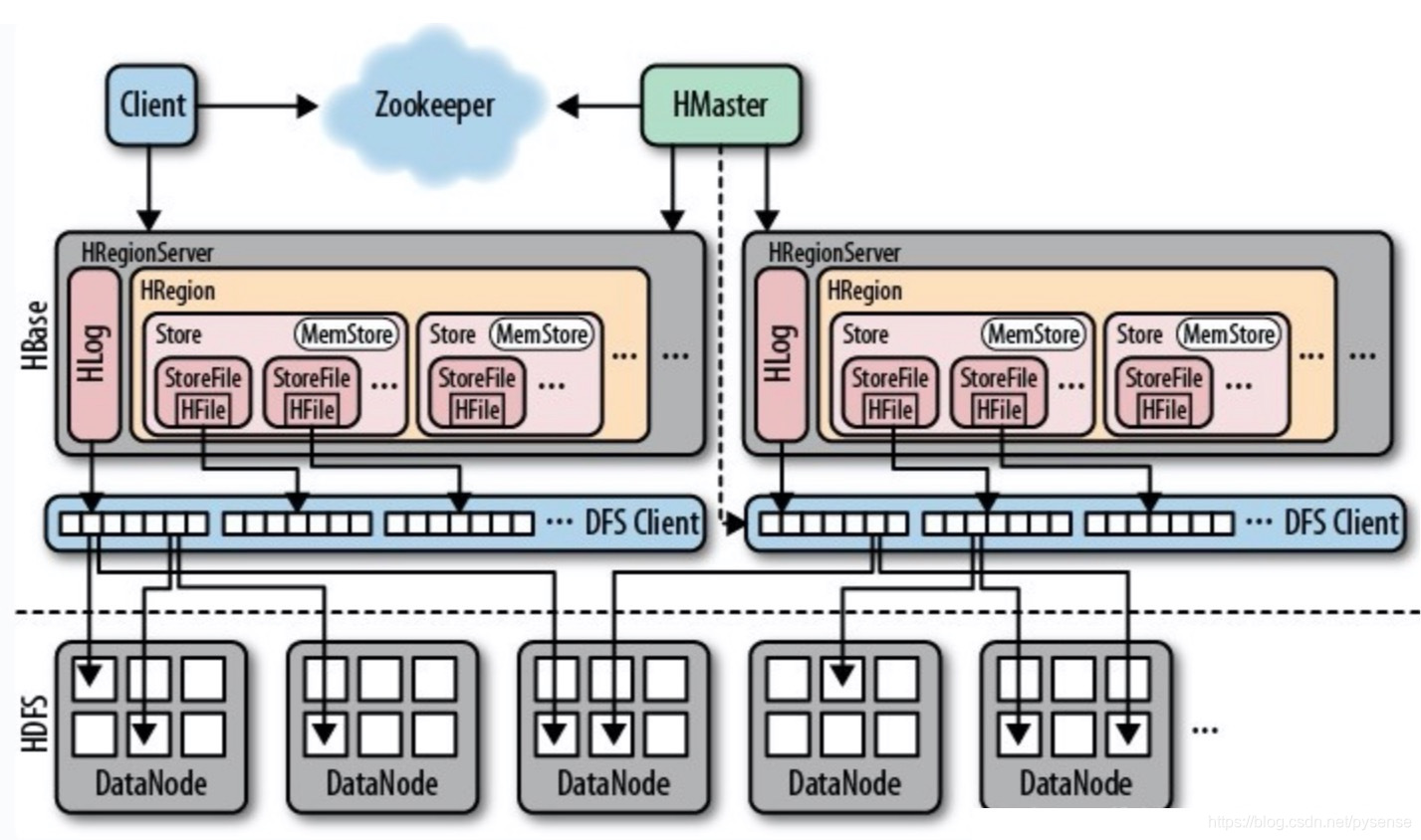 如上图所示,架构主要有以下4个部分
如上图所示,架构主要有以下4个部分
2.1 HMaster
- 负责管理HBase的元数据,表结构,表的Region信息
- 负责表的创建,删除和修改
- 负责为HRegionServer分配Region,分配后将元数据写入相应位置
2.1 HRegionServer
- 存储多个HRegion
- 处理Client端的读写请求(根据从HMaster返回的元数据找到对应的HRegionServer)
- 管理Region的Split分裂、StoreFile的Compaction合并。
- 一个RegionServer管理着多个Region,在HBase运行期间,可以动态添加、删除HRegionServer。
2.3 HRegion
- 一个HRegion里可能有1个或多个Store(参考上图)。
- HRegionServer维护一个HLog。
- HRegion是HBase分布式存储和负载的最小单元,但不是HBase数据存储到文件的最小单元。
- 表通常被保存在多个HRegionServer的多个Region中。
2.4 Store
- Store由内存中的MemStore和磁盘中的若干StoreFile组成(参考上图)
- 一个Store里有1个或多个StoreFile和一个memStore。
- 每个Store存储一个列族。
2.5 MemStore、StoreFile、HFile
- MemStore:
首先,memStore 是在内存中存在,保存修改key-value数据;当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,也就是存在磁盘上。 - StoreFile:
接上面内容,memStore的每次flush操作都会生成一个新的StoreFile,StoreFile底层是以HFile的格式保存,当有多个StoreFile后,将会触发为合并为一个大的StoreFile。 - HFile:
HFile是HBase中KeyValue数据的存储格式,在hdfs上是二进制格式文件,一个StoreFile对应着一个HFile。HFile有自己的数据结构。
HFile写入的时候,分一个块一个块的写入,每个Block块64KB,这样有利于数据的随机访问,不利于连续访问,若连续访问需求大,可将Block块设为较大值。
HFile物理文件形式参考下面4.3内容
2.6 WALs——Write-Ahead-Log预写日志(HLog)
数据库在事务机制中常见的一致性的实现方式就是通过记录日志,通过日志文件的方式实现写入一致性、数据恢复或者数据备份,那么对于HBases也有同样的逻辑,因为大型分布式系统中硬件故障很常见,如果MemStore还没有及时flush到HFile,服务器宕机或者断电,那么MemStore部分的数据肯会丢失。
HBase给出的解决方案:先写入MemStore中,然后更新hlog中,只有成功更新到hlog之后,写操作才能被认为是成功完成。如果在MemStore没有写到hlog之前宕机,HBase重启后可以从hlog恢复。Hbase集群中每台服务器维护一个hlog文件。
hlog过期
当数据从memstore写入到磁盘中,Hlog就已经没有用了,会把/hbase/WALs目录下的数据移动到/hbase/oldWALs 目录下,oldWALs目录下的数据会根据 hbase.master.cleaner.interval (默认1分钟)配置的时间定期去检查,如发现有数据会清除,清除前还会检验一个参数 hbase.master.logcleaner.ttl ,也就是说数据保存1分钟以上才会删除,如果一分钟内数据直接从memstore写入到了磁盘,oldWALs下的数据也不会被删除
2.7 zookeeper
- 通过选举(抢占zk临时节点),保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- RegionServer 向zookeeper的临时znode注册,提供RegionsSrver状态信息(是否在线)。
- 存放所有Region的寻址入口
- 存储HBase的schema和table元数据
- HMaster启动时候会将hbase系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表元信息的存储所对应的RegionServer信息。
3、数据模型
这里以Amandeep Khurana的《Introduction to HBase Schema Design》作为参考
HBase的表结构如下图3所示:
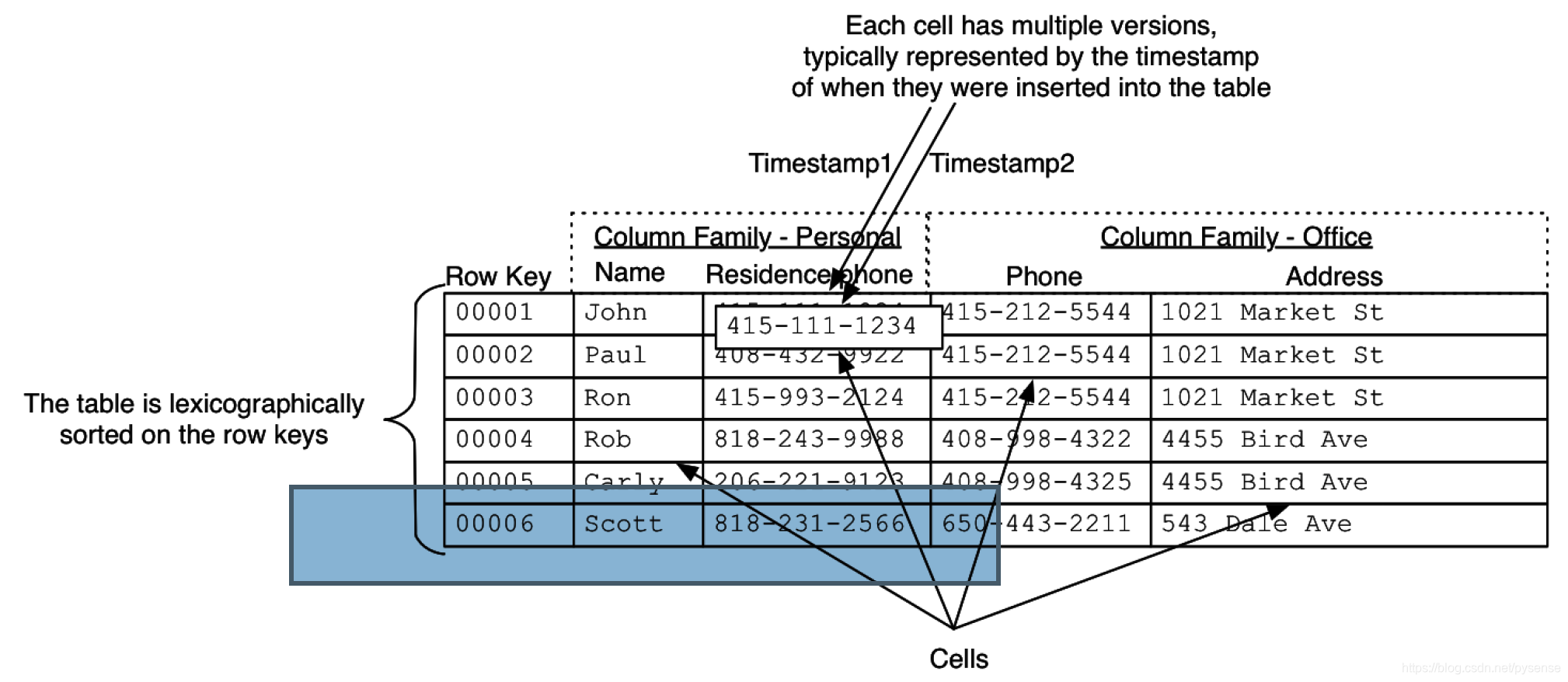 该表有两个列簇: Personal and Office,每个列簇有两个列,例如Personal:姓名和家庭电话,每个小格子cells用来存储真正数据,例如John及其电话,但Row Key 不属于cell。
该表有两个列簇: Personal and Office,每个列簇有两个列,例如Personal:姓名和家庭电话,每个小格子cells用来存储真正数据,例如John及其电话,但Row Key 不属于cell。
HBase行记录的数据结构,其实就是一个嵌套map(嵌套字典),HBase用这种方式组织了数据,以上图的第一行John为例,该0001行字典如下:
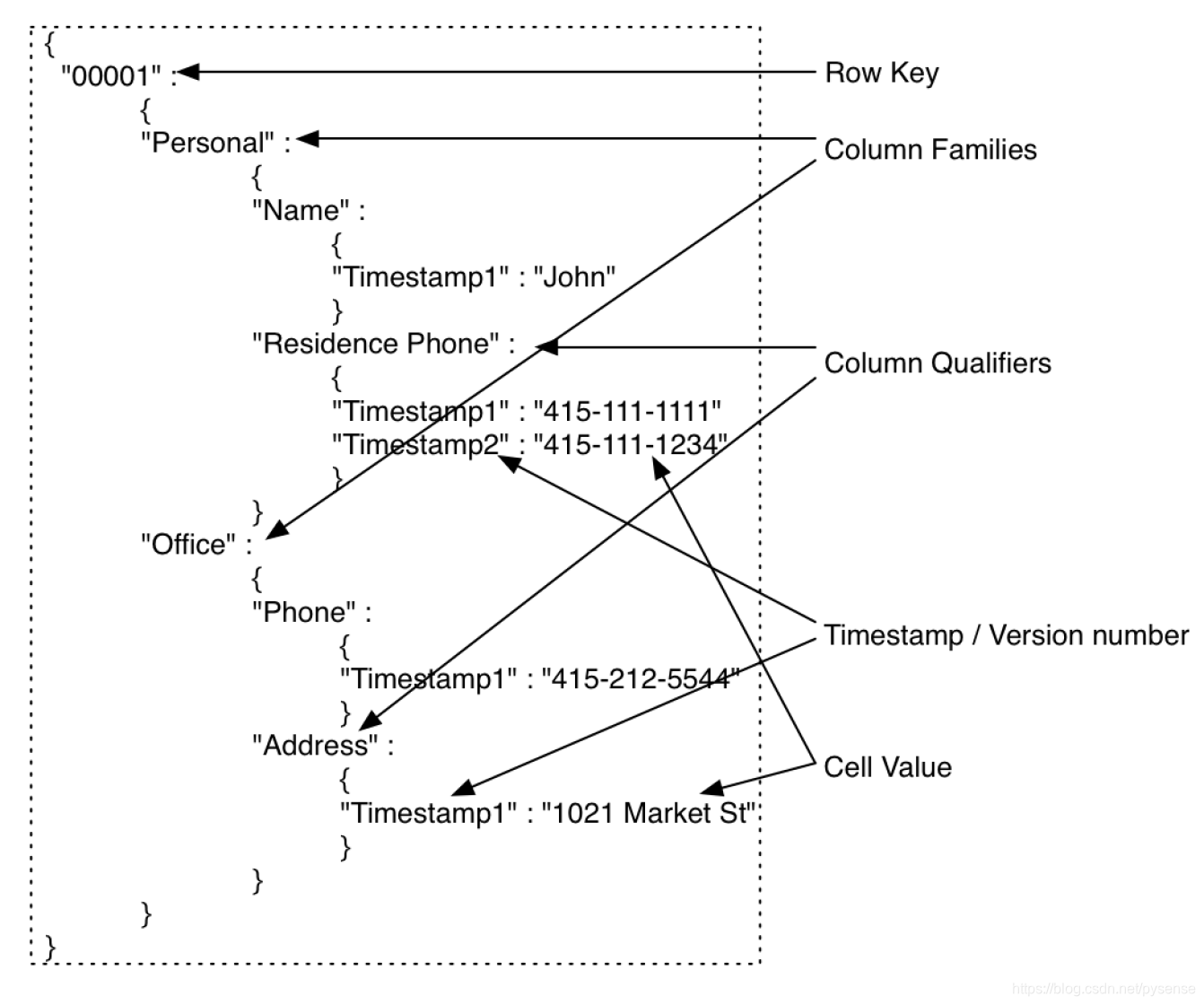 因为大家更熟悉hash map或字典结构,从上图可以看到,HBase的数据单元cell,通过把timestamp作为最里层字典的key,从而数据多版本的控制。看到该map结构,大家可以联想到mangodb,这伙计大有赶超hadoop之势,同样具备分布式大数据的存储、查询能力,它也用这种结构来存储数据,只不过mangodb用的粒度更小是json结构。
因为大家更熟悉hash map或字典结构,从上图可以看到,HBase的数据单元cell,通过把timestamp作为最里层字典的key,从而数据多版本的控制。看到该map结构,大家可以联想到mangodb,这伙计大有赶超hadoop之势,同样具备分布式大数据的存储、查询能力,它也用这种结构来存储数据,只不过mangodb用的粒度更小是json结构。
4、表结构组成(对应图3)
Table(表格)
一个HBase表格由多行组成。
Row(行)
RowKey没有特定的数据类型,都是字节数组类型,任何字符串都可以作为行键表的中行数据按照Rowkey的字节(byte order) 排序存储HBase中的行里面包含一个key和一个或者多个包含值的列。行按照行的key字母顺序存储在表格中。因为这个原因,行的key的设计就显得非常重要。数据的存储设计目的是让数据类型相近的数据存储到一起。
Column Family(列族)
因为性能的原因,列族物理上包含一组列和它们的值。每一个列族拥有一系列的存储属性,例如值是否缓存在内存中,数据是否要压缩或者他的行key是否要加密等等。表格中的每一行拥有相同的列族,尽管一个给定的行可能没有存储任何数据在一个给定的列族中。
Column Qualifier(列名)
列族必须定义表时给出,每个列族可以有一个或多个列成员(Column Qualigier),列成员不需要在定义表时给出,新的列族成员(name、phone)可以随后按需动态加入。列族Personal在创建表格时已被确定,但是列名则可以以后业务需要时动态追加,例如给Personal增加一个列名:company字段,用于存储个人的公司信息
Cell(单元)
单元是由行、列族、列限定符、值和代表值版本的时间戳组成的。Cell由RowKey,列族:列名(Column Qualifier),时间戳唯一决定。Cell中的数据是没有类型的,全部以字节码形式存储。每个单元格保存着同一份数据的多个版本
,不同时间版本的数据按照时间顺序倒序排序。
Timestamp(时间戳)
每个Cell可能有多个版本,它们之间用时间戳区分。
5、HBase物理文件存储过程
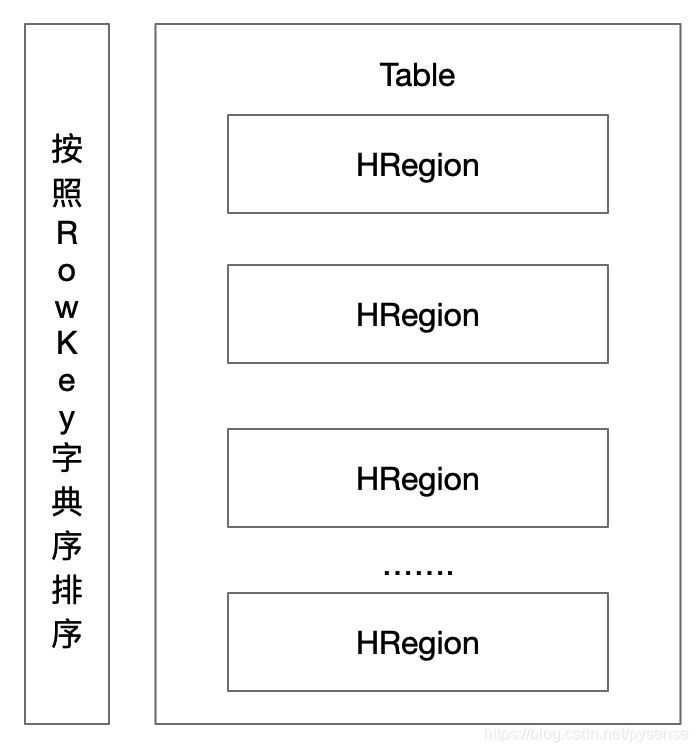
5.1 HRegion在表的上位置
HBase的一个典型Big Table 在行的方向上水平分割为多个HRegion,所有行都按照row key的字典序排列。(注意如果Table表刚建初期,数据量不多,此时Table仅有一个HRegion)
4.2 HRegion自动拆分
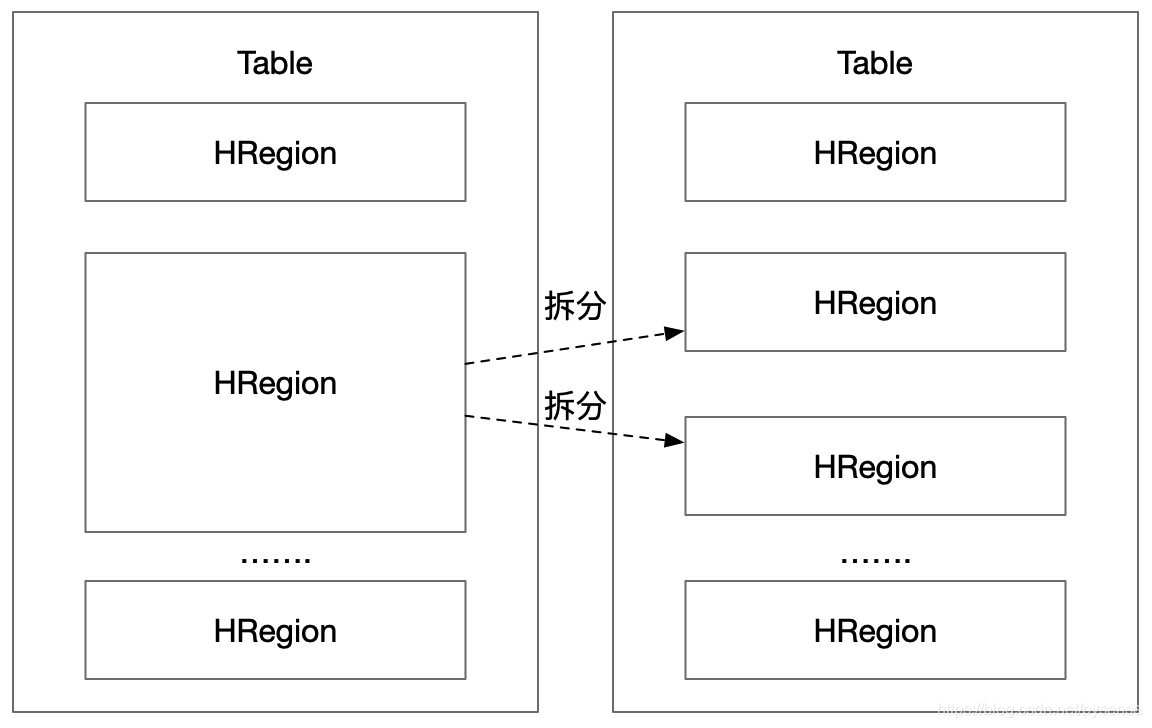
HRegion按照大小拆分,每个Table初始只有一个HRegion,随着数据不断插入表,Rowkey越来越多,HRegion不断增大,当增大到一个阀值(默认256M)的时候,HRegion会被拆分为两个新的HRegion,如下图所示,所以当Table中的行不断增多,就会有越有更多HRegion,这些HRegion分布式存在多台HRegion Server上,只要有足够的节点服务器,那么HBase就可以继续被扩容,存下百亿行都OK。在传统关系型数据库中,这种体量的行数,很难想象!
4.3 HRegion 分布式存储
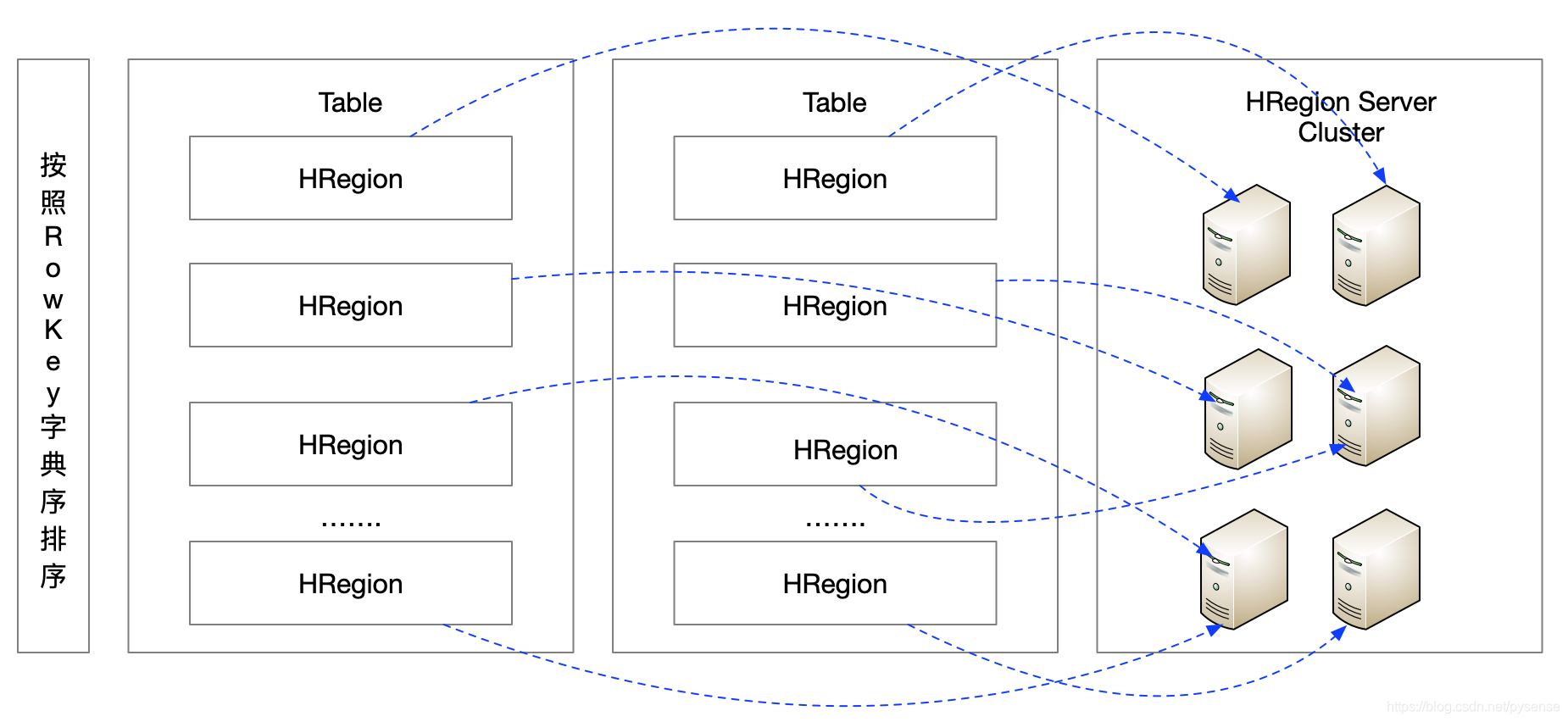
HRegion是Hbase中分布式存储和负载均衡的最小单元,同一个table的不同HRegion可以分布式存储在不同的HRegion Server上,这里说的“负载均衡”是指:例如下图,如果table的所有HRegion都扔到一台服务器上存储,容易出现不平衡分布(数据倾斜),因此需要考虑所有的Region平衡分布到每个节点上,如下图所示,但一个HRegion是不会拆分到多个节点上,因为HRegion是HMaster分布式存储可以管理的最小单元。(机灵的同学此时会想到:同一个HRegion需要拷贝三份或多份再存到不同节点上吗?注意:这里完全不需要,因为HRegion最终存放是在HDFS上的一个二进制文件block,hdfs本身就会将这个block自动拷贝多份,再存到其他节点。)
5.2 Hbase数据在HDFS的存储
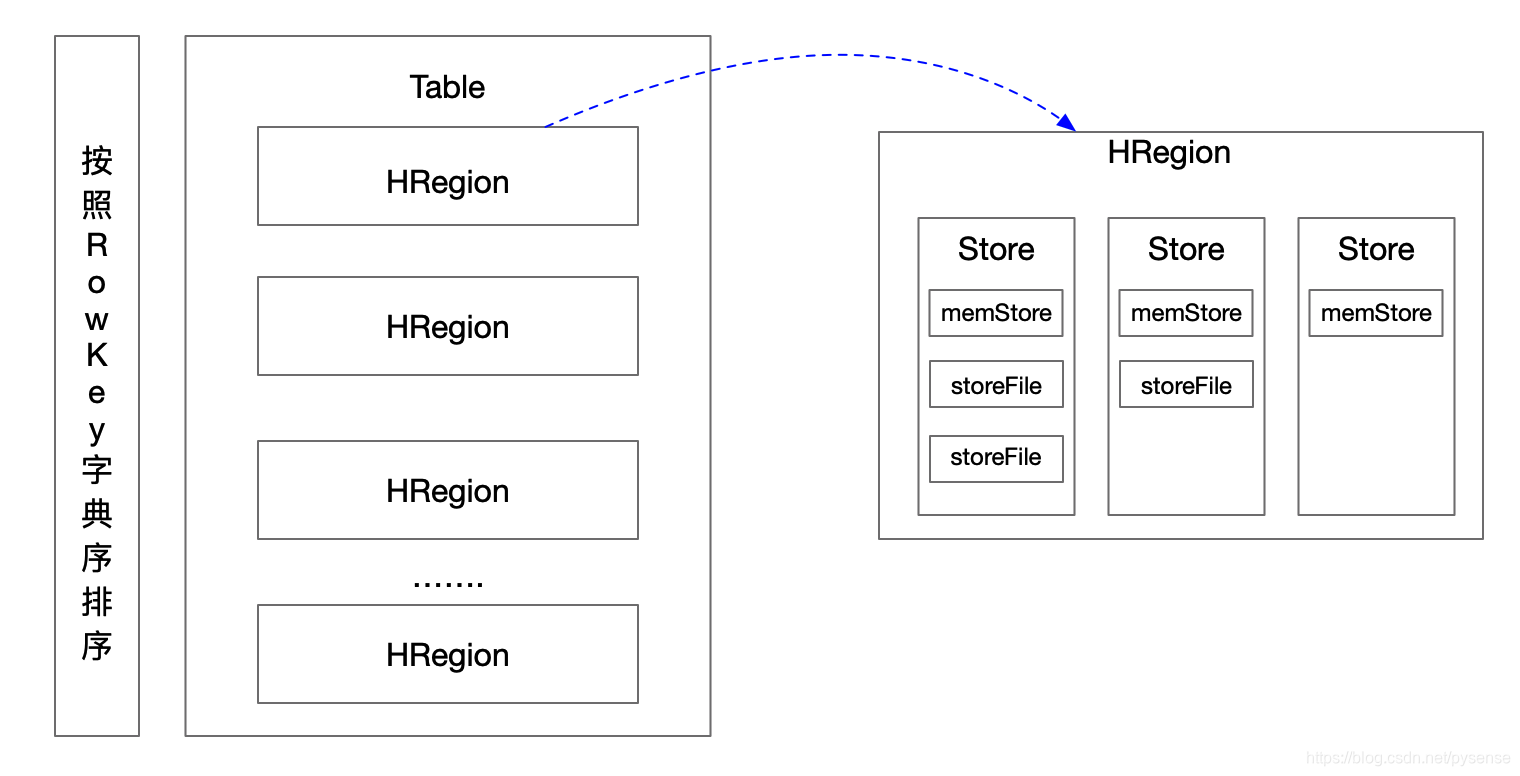
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。HRegion由一个或者多个Store组成,每个Store保存一个Columns Family。每个Store又由一个memStore和0至多个StoreFile组成。StoreFile最终以HFile格式保存在HDFS上
 对于company表,上面提到每个Store保存一个Columns Family,那么在HDFS上是怎样的文件呢?通过查看HBase在hdfs文件系统创建的data目录如下所示:
对于company表,上面提到每个Store保存一个Columns Family,那么在HDFS上是怎样的文件呢?通过查看HBase在hdfs文件系统创建的data目录如下所示:
[root@dn2 ~]# hdfs dfs -ls /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/
Found 4 items
-rw-r--r-- 3 root supergroup 42 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/.regioninfo
drwxr-xr-x - root supergroup 0 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/depart_info
drwxr-xr-x - root supergroup 0 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/recovered.edits
drwxr-xr-x - root supergroup 0 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/staff_info
Hbase的数据在HDFS中的路径结构如下:
hdfs://dn2:9000/hbase/data/{名字空间}/{表名}/{区域名称}/{列族名称}/{文件名}
具体说明:
hdfs://dn2:9000:hdfs分布式节点dn2为该HBase提供底层文件服务
- {名字空间}:在本文的示例中,因为在hbase shell建表做测试时,没有创建新的名字空间(相当于关系型数据库的database),所以hbase为company table提供默认default空间
- {表名}:具体的HBase table名称,如本例的company table
- {区域名称}:指HRegion的字符串名称:38445bbc84c64c82b8273edafbd19b07 由每张表切割形成,table创建开始阶段,仅有一个HRegion,当table越来越大,路径
hdfs://dn2:9000/hbase/data/{名字空间}/{表名}/下将会有多个“区域名称”(也即分割为多个HRegion),这就是HRegion在hdfs的存在形式。 - {列族名称}:例如本例创建的depart_info和staff_info 这两个列簇
- {文件名}:这个文件就是Hfile,每个列簇下有自己存放key-value数据的最终物理文件,这里就是HBase存放数据的最小物理文件。
以depart_info列簇查看它包含的文件有:bdccf10bf1a344baa68c4404b385da7b和dddb8e7e43134c16823db24416
[root@nn ~]# hdfs dfs -ls /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/depart_info
Found 2 items
-rw-r--r-- 3 root supergroup 5082 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/depart_info/bdccf10bf1a344baa68c4404b385da7b
-rw-r--r-- 3 root supergroup 4859 ** /hbase/data/default/company/38445bbc84c64c82b8273edafbd19b07/depart_info/dddb8e7e43134c16823db24416
继续查看depart_info路径下bdccf10bf1a344baa68c4404b385da7b文件内容,该文件为二进制文件,从内容可以大致看到该文件已经存储了R1和R2两行数据内容以及一些元信息等
DATABLK*ˇˇˇˇˇˇˇˇ@""R1
depart_infoinner_telm̵çS108
R1
depart_infolevelm̵q19
R1
depart_infonamem̵WOHR
"R2
depart_infoinner_telmÌ∑£106
R2
depart_infolevelmÌ∑äF9
R2
depart_infonamemÌ∑n6Finance$©…]BLMFBLK2ˇˇˇˇˇˇˇˇ@%ÈíT@3+D4IDXROOT23/ˇˇˇˇˇˇˇˇ@P&"R1
depart_infoinner_telm̵çS…
“?IDXROOT2O@!ÁµãÏFILEINF2îêˇˇˇˇˇˇˇˇ@±PBUFä
BLOOM_FILTER_TYPEROW
DELETE_FAMILY_COUNT
EARLIEST_PUT_TSm̵WO
KEY_VALUE_VERSION
LAST_BLOOM_KEYR2
MAJOR_COMPACTION_KEY
MAX_MEMSTORE_TS_KEY
MAX_SEQ_ID_KEY
TIMERANGEm̵WOmÌ∑£
hfile.AVG_KEY_LEN
hfile.AVG_VALUE_LEN
hfile.CREATE_TIME_TSmÌÔ∂
.
hfile.LASTKEY
R2
depart_infonamemÌ∑n6˙x%ªBLMFMET2<8ˇˇˇˇˇˇˇˇ@Y&)R1Z8˚TRABLK"$H»œ/ Ú&(08@HPZ-org.apache.hadoop.hbase.KeyValue$KVComparator`
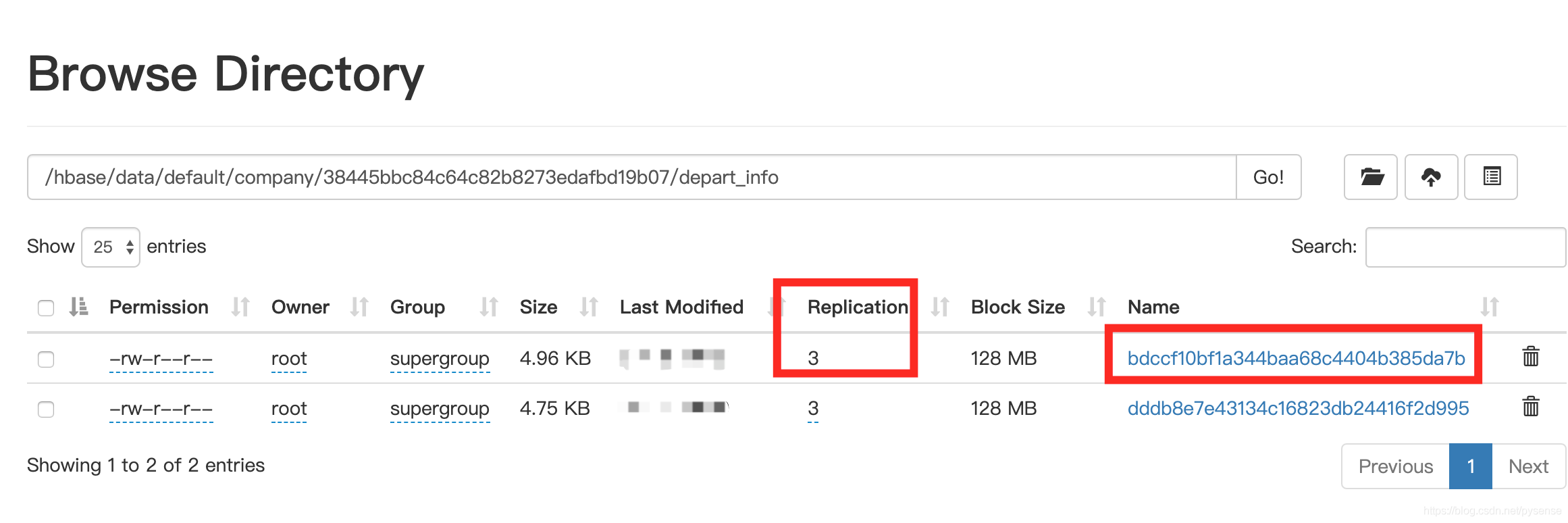
在namenode web页面:http://dn2:50070/ 可以查看HFile相关信息,如下图所示,该HFile在HDFS集群上是3份拷贝的分布式存储。
6、HBase目录结构
HMaser在hdfs文件系统上创建了HBase目录,该目录用于存放所有关于HBase文件、数据、元信息等内容。
- /hbase/.tmp: 临时目录,当对表做创建和删除操作时,会将表move到该目录下,然后进行操作。
- /hbase/WALs:在2.6章节已经提到,该目录为保存操作日志hlog,如下所示:
[root@nn ~]# hdfs dfs -ls /hbase/WALs/
Found 3 items
drwxr-xr-x * /hbase/WALs/dn1,16020,*
drwxr-xr-x * /hbase/WALs/dn2,16020,*
drwxr-xr-x * /hbase/WALs/nn,16020,*
从WALs目录下可以看到每个HRegionServer维护自己一个hlog
- /hbase/data:核心目录,存储Hbase表的数据默认情况下该目录下有两个目录
- /hbase/data/default:当在用户创建表的时候,没有指定namespace时,表就创建在此目录下
– /hbase/data/hbase:系统内部创建的表,hbase:meta,namespace - /hbase/hbase.id:存储集群唯一cluster id(UUID)
- /hbase/hbase.version:集群版本号
- /hbase/oldWALs:参考2.6章节内容——hlog过期
7、HBase的读写流程
之所以把该章节安排在文章最后,是因为基于前面讨论HBase内部结构已经有一定了解后,再分析其读写流程则显得更容易理解。
7.1 写流程
1)Client从Zookeeper中获取表region相关信息,根据要插入的rowkey,获取指定的Regionserver信息。
2)数据被写入Region的MemStore(操作也同时写入到Hlog中),若持续写入数据量超过MemStore达到预设阈值,MemStore会flush到StoreFile,当数据都同时写入到MemStore和Hlog后,那么对于client来说,本次写入即完成。
3)随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile。StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
4)单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。旧Region会下线,新Split出的2个Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
7.2 读流程
1)跟写流程一样,client先连接ZooKeeper,访问Meta Regionserver节点信息,把HBase的meta表缓存到client端。
2)根据rowkey找到Region,再去相应Regionserver 发起读请求。
3)RegionServer接收该读请求之后,既然是来询问key值是否存在,那么HBase针对检索,有自己一套方法:先查询MemStore,如果未找到,再去查询BlockCache加速读内容的缓冲区,如果还没有找到,就会到StoreFile(HFile)中查找这条数据,然后将这条数据返回给client。(注意:这里忽略了一个有关key高效检索是否存在与于HFIle的知识点:bloom-filter)
(从client在HBase读写请求过程可知,client其实无需与HMaster通信,只需要知道ZooKeeper地址即可)
小结
本文已经完成对HBase架构及其数据模型较为全面的讨论,接下来在另外一篇文章开启对Hive的部署和架构分析,Hive跟HBase、Hadoop结合使用后,形成一套可用的数据仓库。
