文章目录
- 1、Hive Requirements
- 2、Hive 环境部署
- 2.1 配置环境变量
- 2.2 配置hive-env.sh和hive-site.xml
- 2.3 配置Hive的运行日志
- 2.4 加入mysql connector
- 2.5 在mysql建表
- 2.6 初始化hive schema
- 2.7 在mysql上查看hive创建的元表
- 2.8 启动hive
- 3、hive建表测试
- 4、为何使用Hive?
- 5、Hive与HBase的关系
- 6、为HBase引入Hive组件
- 7、使用SQL开发工具连接hive进行高级SQL开发
- 7.1 配置hive-site.xml和core-site.xml
- 7.2 在nn主节点上启动hiveserver2服务
- 7.3 配置DBeaver连接hive
- 7.4 hiveserver2的webUI
- 8 使用beeline连接hiveserver2
- 8、部署高可用的Hive服务
前面的项目中,已经实现了HadoopHA、HBaseHA,本文将加入Hive数据仓库工作,并整合HBase,实现完整的大数据开发项目所具备的开发环境,为后面博客关于数据应用层开发提供支撑。
1、Hive Requirements
按官网给出的基本环境
- Java 1.7: Hive versions1.2 onward require Java 1.7 or newer. java1.7或更高版本
- Hadoop 2.x (preferred):推荐hadoop2.x版本
hive安装包可在清华镜像源拉取:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
目前stable版本为:
apache-hive-2.3.6-bin.tar.gz 2019-08-23 02:53 221M
最新版为:
apache-hive-3.1.2-bin.tar.gz 2019-08-27 04:20 266M
如何定位自身Hadoop版本与hive版本的兼容呢?
例如本blog前面部署hadoop3.1.2,可通过在hive官网查看其对应的版本
http://hive.apache.org/downloads.html,官网给出的news:
26 August 2019: release 3.1.2 available
This release works with Hadoop 3.x.y.
hive3.1.2版本支持hadoop3.x.y版本,结合本blog内容,这里使用hive3.1.2:
从hive官网给出的hadoop版本兼容可以看出hive2.x.y一般是兼容hadoop2.x.y
2、Hive 环境部署
2.1 配置环境变量
hive安装包所在路径,个人习惯将所有大数据组件放在/opt目录下,方便管理和配置
[root@nn hive-3.1.2]# pwd
/opt/hive-3.1.2
[root@nn hive-3.1.2]# vi /etc/profile
# 追加到文件后面
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
[root@nn hive-3.1.2]# source /etc/profile
# 查看hive版本
[root@nn hive-3.1.2] hive --version
Hive 3.1.2
Git git://HW13934/Users/gates/tmp/hive-branch-3.1/hive -r 8190d2be7b7165effa62bd21b7d60ef81fb0e4af
Compiled by gates on ** PDT 2019
From source with checksum 0492c08f784b188c349f6afb1d8d9847
2.2 配置hive-env.sh和hive-site.xml
[root@nn conf]# cp hive-default.xml.template hive-site.xml
[root@nn conf]# cp hive-env.sh.template hive-env.sh
[root@nn conf]# vi hive-env.sh
# 在文件最后修改
HADOOP_HOME=/opt/hadoop-3.1.2
export HIVE_CONF_DIR=/opt/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/hive-3.1.2/lib
Hive-site.xm的配置项比较多,自带模板文件内容长达6900多行,仅给出重要的设置项,其他属性的设置以及描述可参考官网
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--元数据库的mysql的配置项-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://nn:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>py_ab2018</value>
</property>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
<!--zookeeper的有关设置-->
<property>
<name>hive.zookeeper.quorum</name>
<value>nn:2181,dn1:2181,dn2:2181</value>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
<property>
<name>hive.server2.zookeeper.publish.configs</name>
<value>true</value>
</property>
<!--hiveserver2配置,可使得外部客户端使用thrift RPC协议连接远程hive-->
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>py_ab2018</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--binary对应TCP协议,也可配成http协议-->
<property>
<name>hive.server2.transport.mode</name>
<value>binary</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<!--thriftserver对外限制最大最小连接数-->
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>10</value>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>100</value>
</property>
<!--有关日志文件-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive-3.1.2/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive-3.1.2/resources</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive-3.1.2/querylog</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hive-3.1.2/operation-log</value>
<property>
</configuration>
注意因为hadoop做了HA配置,因此以上的配置需要在主nn节点和backup dn2节点配置上,在第7.1章节内容将会给出hiveserver2的相关内容。
2.3 配置Hive的运行日志
#
[root@nn hive-3.1.2]# mkdir logs
[root@nn conf]# cp hive-log4j2.properties.template hive-log4j2.properties
[root@nn conf]# vi hive-log4j2.properties
#
property.hive.log.dir = /root/hive-3.1.2/logs
2.4 加入mysql connector
hive需用通过jdbc连接mysql,该jar需自行下载,并将其拷贝至以下目录
[root@nn hive-3.1.2]# cp mysql-connector-java-5.1.32-bin.jar /opt/hive-3.1.2/lib/
2.5 在mysql建表
其实这里无需在msyql建表,因为hive-site.xml文件里面已经配置为自动创建元数据库表,hive做初始化时会自动创建。也即本节内容可以忽略。
MariaDB [(none)]> create database hive default character set utf8 collate utf8_general_ci
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| hive |
| information_schema |
| mysql |
hive> grant all on hive.* to 'hive'@'%' identified by 'py_ab2018';
# 容许本地访问,否则hive的schema初始化将无法访问msyql
grant all on *.* to 'hive'@'nn' identified by 'py_ab2018';
grant all on *.* to 'hive'@'localhost' identified by 'py_ab2018';
grant all on *.* to 'hive'@'127.0.0.1' identified by 'py_ab2018';
hive> flush privileges;
MariaDB [(none)]> select host,user,authentication_string from mysql.user; +-----------+--------+-----------------------+
| host | user | authentication_string |
+-----------+--------+-----------------------+
| localhost | root | |
| nn | root | |
| 127.0.0.1 | root | |
| ::1 | root | |
| nn | hive | |
| % | hadoop | |
| % | hive | |
| localhost | hive | |
| 127.0.0.1 | hive | |
+-----------+--------+-----------------------+
hive> exit;(quit;)
2.6 初始化hive schema
[root@nn hive-3.1.2]# schematool -initSchema -dbType mysql
Initialization script completed
schemaTool completed
[root@nn hive-3.1.2]#
2.7 在mysql上查看hive创建的元表
MariaDB [(none)]> use hive
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MariaDB [hive]> show tables;
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| CTLGS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
.....
2.8 启动hive
启动hive之前,务必hadoop服务已经启动,若hadoop为HA结构,必须其中一个namenode节点为active节点,例如本项目中,hadoopHA为:nn和dn2都作为namenode节点。
除此之外,还需手动在hdfs上创建hive的工作目录:这里官方的说明如下
In addition, you must use below HDFS commands to create /tmp and /user/hive/warehouse (aka hive.metastore.warehouse.dir) and set them chmod g+w before you can create a table in Hive.
以下就是对/tmp加入group写权限
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -mkdir -p /user/hive/warehouse
warehouse目录下放置的就是表对应的数据文件,在后面的章节会提供说明
启动hive,该命令是指启动hive cli,就像mysql shell
[root@nn hive-3.1.2]# hive
Hive Session ID = 627577c0-2560-4318-92af-bc2512f91d3b
hive>
以上说明hive部署成功,jps可以看到多了一个RunJar进程
[root@nn hive-3.1.2]# jps
13042 QuorumPeerMain
20163 JournalNode
19780 NameNode
20709 Jps
19499 DFSZKFailoverController
20299 RunJar
19918 DataNode
启动过程可能遇到问题:
1)启动hive会有一个多重绑定的提示
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.1.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
原因:
hadoop/common/lib有个slf4j-log4j的jar包,hive的lib下也有一个slf4j-log4j
那么在环境变量/etc/profile都配置两者的环境,hive启动后,会找到两个slf4j-log4j,因此提示多重绑定
解决办法:
保留hadoop/common/lib有个slf4j-log4j的jar包,将hive lib目录下的slf4j-log4j重命名即可。
[root@nn lib]# mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
注意:
当这个hive的日志jar包去掉后,hive日志模式将默认使用hadoop的日志配置,启动hive cli或者在hive cli上执行任何命令时都会不断打印出日志,如果需要进程在hive cli操作数据,那么建议保留hive的log4j包。如果使用外部可视化数据库管理客户端连接hive,那么可删除之。
2) hive在hdfs的/tmp/hive不具有写权限
The dir: /tmp/hive on HDFS should be writable. Current permissions are: rwxrwxr-x
将用户组以及其他用户加入可读可写可执行权限
hdfs dfs -chmod -R 777 /tmp
3、hive建表测试
HQL语句跟SQL差别不大,若对sql非常熟悉,HQL拿来即用。相关用法参考官网:DDL语句、HQL查询用法
3.1 创建一个员工表
create table if not exists emp(
id int,
name string,
age int,
sexual string,
depart_id int
)
row format delimited fields terminated by'\t'
stored as textfile;
#
hive> desc emp;
OK
id int
name string
age int
sexual string
depart_id int
Time taken: 0.263 seconds, Fetched: 5 row(s)
员工表的本地数据emp.txt
1 Aery 25 Male 1
2 Bery 23 Female 2
3 Cery 26 Female 3
4 Dery 27 Male 2
3.2 hive cli导入测试文本数据
上面创建一个emp.txt文本数据,若要使用hive将其映射为一张表,需要将数据文件上传到hdfs,hive已经提供相关命令进行此类文件数据的上传操作。
hive> load data local inpath '/opt/hive-3.1.2/test_data/emp.txt' into table emp;
Loading data to table default.emp
OK
Time taken: 1.768 seconds
hive> select * from emp;
OK
1 Aery 25 Male 1
2 Bery 23 Female 2
3 Cery 26 Femalei 3
4 Dery 27 Male 2
hive> select * from emp a where a.name='Dery';
OK
4 Dery 27 Male 2
Time taken: 0.327 seconds, Fetched: 1 row(s)
hive会把本地数据上传到hdfs文件系统上具体路径如下:
[root@nn opt]# hdfs dfs -ls /user/hive/warehouse/emp
Found 1 items
-rw-r--r-- 3 root root 73 ** /user/hive/warehouse/emp/emp.txt
从上面可知,hive建的表默认放在hdfs的warehouse目录下,而且上传的用户数据文件放在相应的表名字目录下。
3.3 加载hdfs上的数据
除了可以直接在hive cli里加载本地数据,也可先把本地数据上传到hdfs上,再通过hive加载
[root@nn test_data]# hdfs dfs -put emp.txt /tmp
[root@nn test_data]# hdfs dfs -ls /tmp
Found 3 items
-rw-r--r-- 3 root supergroup 73 ** /tmp/emp.txt
# 先清空之前的数据
hive> truncate table emp;
OK
Time taken: 0.957 seconds
# hive导入hdfs的数据
hive> load data inpath '/tmp/emp.txt' into table emp;
hive> load data inpath '/tmp/emp.txt' into table emp;
Loading data to table default.emp
OK
Time taken: 0.593 seconds
hive导入本地文件所需的实际为:1.768 s,是hdfs导入的3倍。
todo
hive 按分区上传,上传的数据会指定在相应的分区上
hive按分区删除数据:
alter table table_name drop partition (partition_name='分区名')
4、为何使用Hive?
前面的内容为hive环境构建及其测试,那么在大数据开发项目中,为何要引入Hive组件?
4.1 无Hive组件的大数据处理
从本人博客前面几篇关于大数据组件部署和技术架构解析的blog可以了解到,若没有Hive这样的组件,
当需要从hdfs的原始数据做高级数据分析时,首先肯定需要使用java写MapReduce程序,如果再加入Spark分布式内存计算引擎,那么还需使用Scala语言写spark程序(或者使用python写pyspark)。事实上,MapReduce的程序写起来比较繁琐(注意:不是难),占据大量工作和时间。对于大部分数据开发人员(含数据分析),其实更关心的是把这些海量数据“统一处理”后,最终的呈现的数据是否有价值或者提供商业决策。若无Hive这样的组件,整个项目组将耗费大量的人力去开发更低层MapReduce程序,无论业务逻辑简单与否(虽然极其复杂的业务数据需要可能还是得写MP程序才能完成)。
4.2 Hive组件在大数据分析与处理上的优势
在大数据处理和分析中,能否有个更高层更抽象的语言层来描述算法和数据处理流程,就像传统数据库的SQL语句。Apache项目大神早已考虑到:传统数据库的数据分析与处理,每个人都在用SQL即可完成各自分析任务,这种方式在大数据hadoop生态必须给予引入。于是就有了Pig和Hive。Pig是接近脚本方式去描述MapReduce,Hive则用的是SQL,它们把脚本和SQL语言翻译成MapReduce程序,然后再丢给底层的MapReduce或者spark计算引擎去计算。也就是说,大数据开发人员只需要用更直观易懂、大家都熟悉的SQL语言去写大数据job即可完成绝大部分MapReduce任务,而且项目组的非计算机背景工作人员也可直接通过写SQL完成相应的大数据分析任务,简直不要太爽!
正因为Hive如此易用和SQL的通用性,Hive逐渐成长成了大数据仓库的核心组件,甚至很多公司的流水线作业集完全是用SQL描述,因为易写易改,一看就懂,容易维护。
4.3 Hive在hadoop项目中的作用
-
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张关系型数据库的表,并提供类似传统数据库的SQL查询功能
这里如何理解?以本文第3章节内容说明:
这里说的结构化的数据文件,例如emp.txt数据文件,里面的数据是结构化的,每行的字段值用tab键空格隔开,用换行符’\n’进行换行,该数据文件直接存在hdfs上映射为一张关系型数据库的表:因为是结构化数据,一行记录分4列,有即每行都有4个字段,当然可以把该数据文件emp.txt看成是一张数据库表。
-
Hive的查询效率取决于使用第一代的MapReduce计算框架还是内存Spark/Tez框架
这句表述如何理解?
4.2 章节提到,数据应用开发或者数据分析人员开始用Hive分析数据之后,虽然写SQL即可实现MP任务,但Hive在MapReduce处理任务的速度实在太慢,这是底层默认采用MapReduce计算架构。Spark/Tez作为新一代的内存计算框架既然比MP计算效率更高,当然可以引入到Hive里面,于是就有了Hive on Spark/Hive on Tez,到此,基本完成一个数据仓库的架构了,有了Hive on Spark/Hive on Tez,基本解决了中低速数据处理的需求,这里的中低速是指(批数据分析):例如查询某个栏目截止到昨天的访问量,时效性滞后比较长。
而高速数据处理的需求(流数据分析):例如要查询截止到1小时前,某个栏目的访问量,时效性要求高,近乎实时效果。
- Hive只适合用来做批量数据统计分析
5、Hive与HBase的关系
在前面的blog,给出了非常详细的HBase高可用的部署测试的描述,那么在本文中,HBase跟Hive是怎么样结合使用呢?或者他们之间有什么关系吗?
首先:Hive与HBase是没有联系的,也就是说,在大数据项目中,有Hive+Spark/MapReduce+HDFS+结构化数据,也可以独立完成大数据分析任务,同样,有HBase+HDFS+数据,也可以独立完成大数据分析任务。因为Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时高效查询的需求,尤其是Key-Value形式的查询;而Hive主要解决数据处理和计算问题,例如联合查询、统计、汇总等。这两个组件可以独立使用,也可以配合一起使用。
5.1 两者之间的区别
-
Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
-
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
-
通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
-
基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
也可参考以下两者的各自优点对比图:

5.2 两者配合使用时的大数据处理流程
在大数据架构中,Hive和HBase是协作关系,处理流程一般如下图所示:
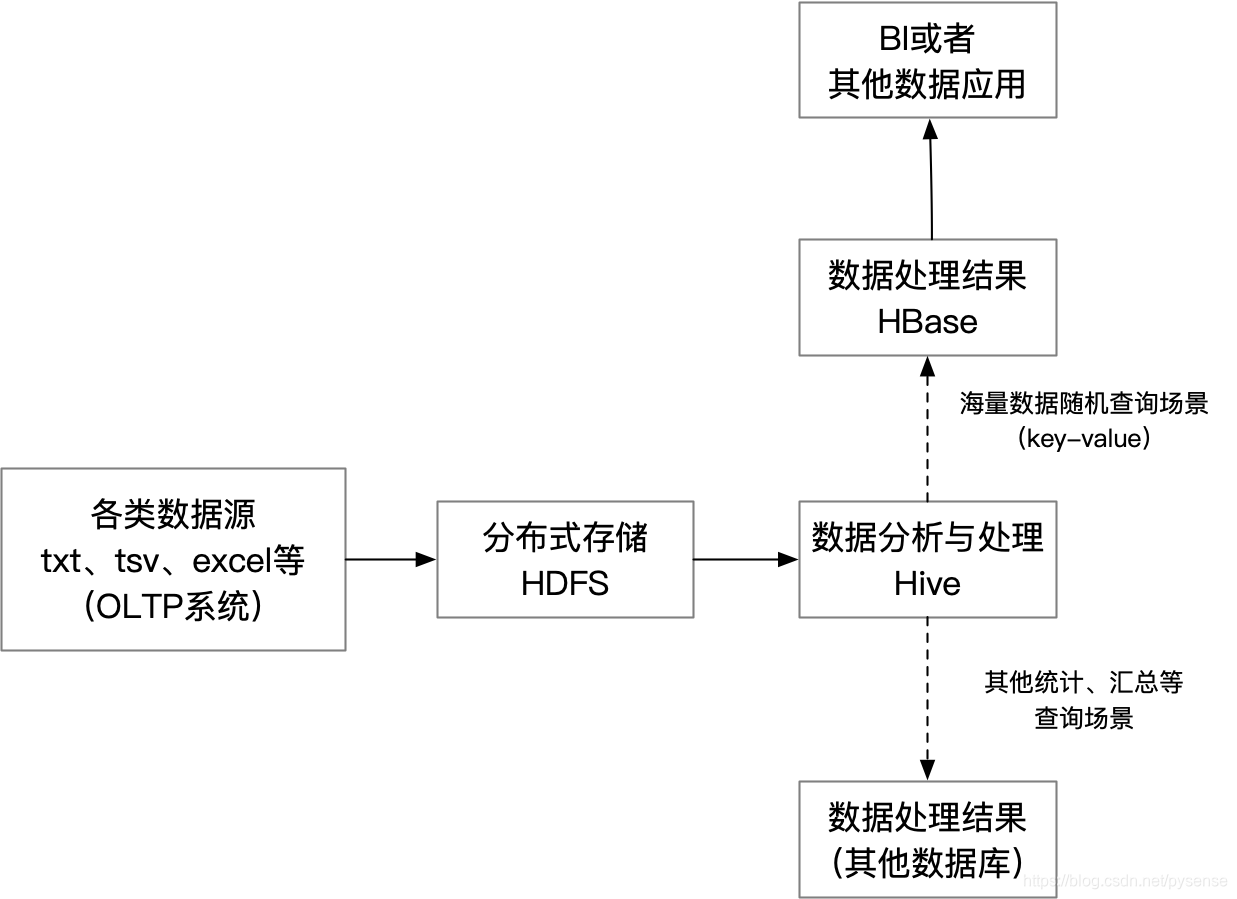
1)通过ETL工具将数据源抽取到HDFS存储,这里的数据源包括mysql等关系型数据库的数据、ftp、api接口、txt、excel、日志文件等,这里说的抽取有两种意思:一种为脚本式的自动化抽取,例如写个定时任务把ftp的数据定时导入到HDFS中,另外一种抽取则是使用Apache组件Flume,能够实时抽取日志记录到kafka消息组件中,再由消费端(例如存入hbase或者mysql等)消费kafka的日志消息,这部分内容也会在本blog给出。
2)通过Hive清洗、处理原始数据;
3)HIve清洗处理后的数据,若面向海量数据随机查询场景,例如key-value,则可存入Hbase;若其他查询场景则可导入到mysql等其他数据库
4)大数据BI分析、应用的数据接口API开发,可从HBase获得查询数据。
5.3 如果Hbase不需要Hive组件,如何实现易用的查询?
在文章基于HadoopHA服务部署HBaseHA分布式服务(详细版)的第10章节内容,提到操作HBase 表的示例,例如要查询company表的R2行记录,首先启动hbase shell,使用以下命令
hbase(main):> get 'company','R1','staff_info:age'
COLUMN CELL
staff_info:age timestamp=**, value=23
可以看到,这种查询方式适合开发人员或者hbase管理员,而对于已经非常熟悉SQL查询的分析人员来说,无疑非常不友好。Hive正好能提供一种叫“外部表”的机制实现以SQL的形式对HBase的数据进行查询操作,内容在以下章节给出。
6、为HBase引入Hive组件
前面提到,引入Hive就是为了能够使用SQL语句轻松完成对于HBase上的数据进行查询任务。
Hive连接HBase的原理:
让hive加载到连接hbase的jar包,通过hbase提供的java api即可实现Hive对Hbase的操作,此时可以吧Hive看成是HBase的客户端,类似navicat客户至于mysql,只不过navicat提供UI操作界面,hive是通过cli shell操作,当然我们也可以使用Hive的UI操作工具来实现UI操作(后面会给出基于DBeaver来实现)
6.1 hive-env.sh
[root@nn conf]# vi hive-env.sh
# 文件最后添加
export HBASE_HOME=/opt/hbase-2.1.7
6.2 在hive-site.xml添加zookeeper集群
<!--zookeeper的有关设置-->
<property>
<name>hive.zookeeper.quorum</name>
<value>nn:2181,dn1:2181,dn2:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.server2.zookeeper.publish.configs</name>
<value>true</value>
</property>
以上两个配置实现了Hive连接至Hbase
6.3 测试hive操作hbase
首先hbase有测试数据,之前创建的company table,里面有两个列簇,这里不再赘述。
在hive创建外部表,用于映射Hbase的列簇,这里以staff_info列簇作为测试
hive> CREATE EXTERNAL TABLE staff_info(
rowkey string,
name string,
age int,
sexual string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES
("hbase.columns.mapping"=":key,staff_info:name,staff_info:age,staff_info:sex")
TBLPROPERTIES("hbase.table.name" = "company");
外部表创建语法解释:
创建一个外部表,表名为staff_info,字段有4个,(rowkey,name,age,sexual),其中rowkey为对于hbase上的rowkey,该字段不是数据字段,name、age、sexual为数据字段。处理类org.apache.hadoop.hive.hbase.HBaseStorageHandler,hbase到hive的映射关系::key,列簇:列名1,列簇:列名2…
指定映射HBase的table name
执行结果
** INFO [16e10346-1e6d-4bb5-b89b-bd12f3614ec7 main] zookeeper.RecoverableZooKeeper: Process identifier=hconnection-0x448892f1 connecting to ZooKeeper ensemble=nn:2181,dn1:2181,dn2:2181
OK
Time taken: 1.151 seconds
在hive查询相关hbase的staff_info数据
hive> select * from staff_info;
OK
R1 Bery 23 Female
R2 Dery 27 Male
Time taken: 3.562 seconds, Fetched: 2 row(s)
hive> select * from staff_info a where a.name='Bery';
OK
R1 Bery 23 Female
Time taken: 1.376 seconds, Fetched: 1 row(s)
以上完成Hive和HBase的开发环境整合配置。
7、使用SQL开发工具连接hive进行高级SQL开发
在前面章节内容可以看到,hive的操作直接基于hive服务器上的hive cli上进行,使用hive交互命令式写sql效率会很低,调试也不方便,因此需要外部SQL IDE工具提高开发效率。本文采用DBeaver,也是本人长期使用的数据库管理客户端工具,重点它是开源的,在Mac上用起来流畅、UI有一定设计感!)。
关于DBeaver的介绍(官网下载):
DBeaver 是一个开源、跨平台、基于java语言编写的的通用数据库管理工具和 SQL 客户端,支持 MySQL, PostgreSQL, Oracle, Hive、Spark、elasticsearch等以及其他兼容 JDBC 的数据库(DBeaver可以支持的数据库太多了)
DBeaver 提供一个图形界面用来查看数据库结构、执行SQL查询和脚本,浏览和导出数据,处理BLOB/CLOB 数据,修改数据库结构等。
可以看到,DBeaver支持各自类型数据库以及hadoop相关的组件,之后会有专门文章用DBeaver开发spark数据分析项目。
DBeaver连接hive需要做以下几个配置,否则无法成功连接
7.1 配置hive-site.xml和core-site.xml
hive服务端启用相应的thrift TCP端口,暴露给客户端连接使用。
在2.2章节内容,hive-site.xml已经配置了hive server2服务,端口号按默认的10000,监听host为全网地址0.0.0.0,nn和dn2都需要配置hive server2。此外,还需要hadoop的配置文件core-site.xml放通拥有hdfs文件系统的用户,在本blog里,hadoop的用户为root上,需加入以下property
core-site.xml配置如下
<!--放通客户端以root用户访问hdfs-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
如果hadoop文件使用者不是’root‘用户,例如‘foo-bar’用户那么对应的name值为
<name>hadoop.proxyuser.foo-bar.groups</name>,
以上配置需要在nn和dn2同时配置,因为这两个节点做了hadoop HA。
若不配置“放通客户端以root用户访问hdfs”,使用DBeaver或者jdbc api连接hive server2会提示以下出错信息:
连接错误提示
Required field ‘serverProtocolVersion’ is unset! Struct:TOpenSessionResp(status:TStatus(statusCode:ERROR_STATUS, infoMessages:[*org.apache.hive.service.cli.HiveSQLException:Failed to open new session: java.lang.RuntimeException: ==org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root:14:13 ==
7.2 在nn主节点上启动hiveserver2服务
# 以前台进程方式打开
[root@nn conf]# hiveserver2
Hive Session ID = 1c92d507-7725-4e57-a7fe-03a9ae0cdf13
使用jps -ml查看所有大数据组件服务的情况,RunJar表示hiveserver2服务
[root@nn ~]# jps -ml
16340 org.apache.hadoop.util.RunJar /opt/hive-3.1.2/lib/hive-service-3.1.2.jar org.apache.hive.service.server.HiveServer2 --hiveconf hive.aux.jars ****
14085 org.apache.hadoop.yarn.server.nodemanager.NodeManager
14710 org.apache.hadoop.hbase.master.HMaster start
5815 org.apache.hadoop.hdfs.tools.DFSZKFailoverController
13273 org.apache.hadoop.hdfs.server.datanode.DataNode
16666 sun.tools.jps.Jps -ml
5451 org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
13547 org.apache.hadoop.hdfs.qjournal.server.JournalNode
14876 org.apache.hadoop.hbase.regionserver.HRegionServer start
13135 org.apache.hadoop.hdfs.server.namenode.NameNode
13951 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
也可查看是否有10000端口
[root@nn ~]# ss -nltp|grep 10000
LISTEN 0 50 :::10000 :::*
users:(("java",pid=16340,fd=506))
至此,hiveserver2已经可以对外提供hive的连接服务。
7.3 配置DBeaver连接hive
创建新的hive连接
 在
在编辑驱动设置里面,选择下载驱动,这里DBeaver会自动去拉取相应的jar驱动包
 驱动为:
驱动为:hive-jdbc-uber-2.6.5.0-292.jar (Uber开发的驱动?)
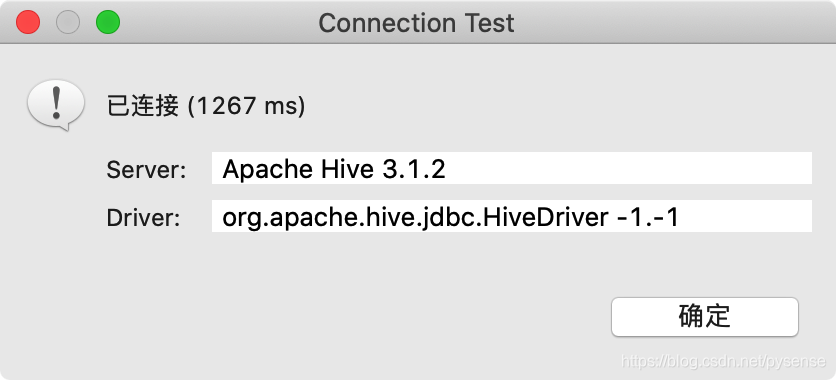
测试是否可连,以下提示远程hive服务器的版本为hive3.1.2
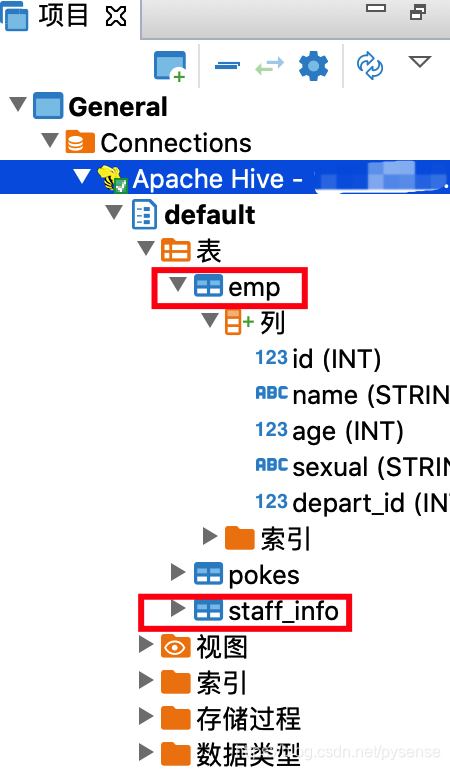
 下图可以看到DBeaver已经可以查看hive之前创建的emp表,以及hive的外部表——hbase的staff_info表
下图可以看到DBeaver已经可以查看hive之前创建的emp表,以及hive的外部表——hbase的staff_info表
 在DBeaver编辑器上对hive上的emp表进行简单的查询:
在DBeaver编辑器上对hive上的emp表进行简单的查询:
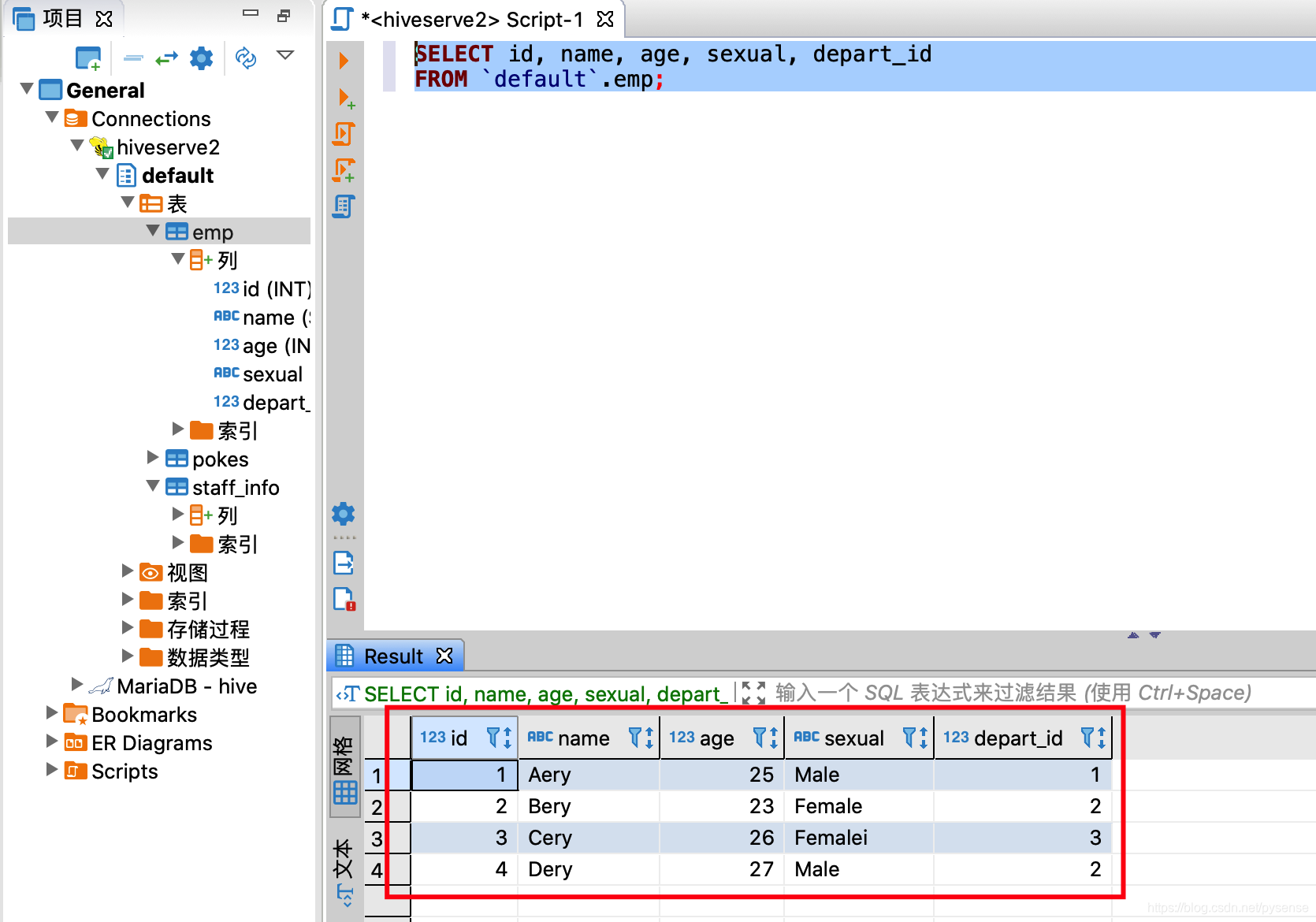 至此,hive的SQL可视化开发环境已经部署完成,配合DBeaver出色的Tab自动补全,写HQL效率有效提升。
至此,hive的SQL可视化开发环境已经部署完成,配合DBeaver出色的Tab自动补全,写HQL效率有效提升。
7.4 hiveserver2的webUI
在上一节内容,通过命令hiveserver2可启动远程连接服务,其实该命令还启动另外一个进程:hiveserver2自己的webUI服务进程,该web页面可看到每个客户端在hive服务器上执行过的查询语句、会话,包括IP、用户名、当前执行的操作(查询)数量、链接总时长、空闲时长等指标,是管理客户端连接和查询的后台页面。
在hiveserver2服务器上也即nn节点上查看10002端号:
[root@nn ~]# ss -nltp|grep 10002
LISTEN 0 50 :::10002 :::* users:(("java",pid=16340,fd=511))
web 页面入口:http://nn:10002/
当前连接的客户端会话
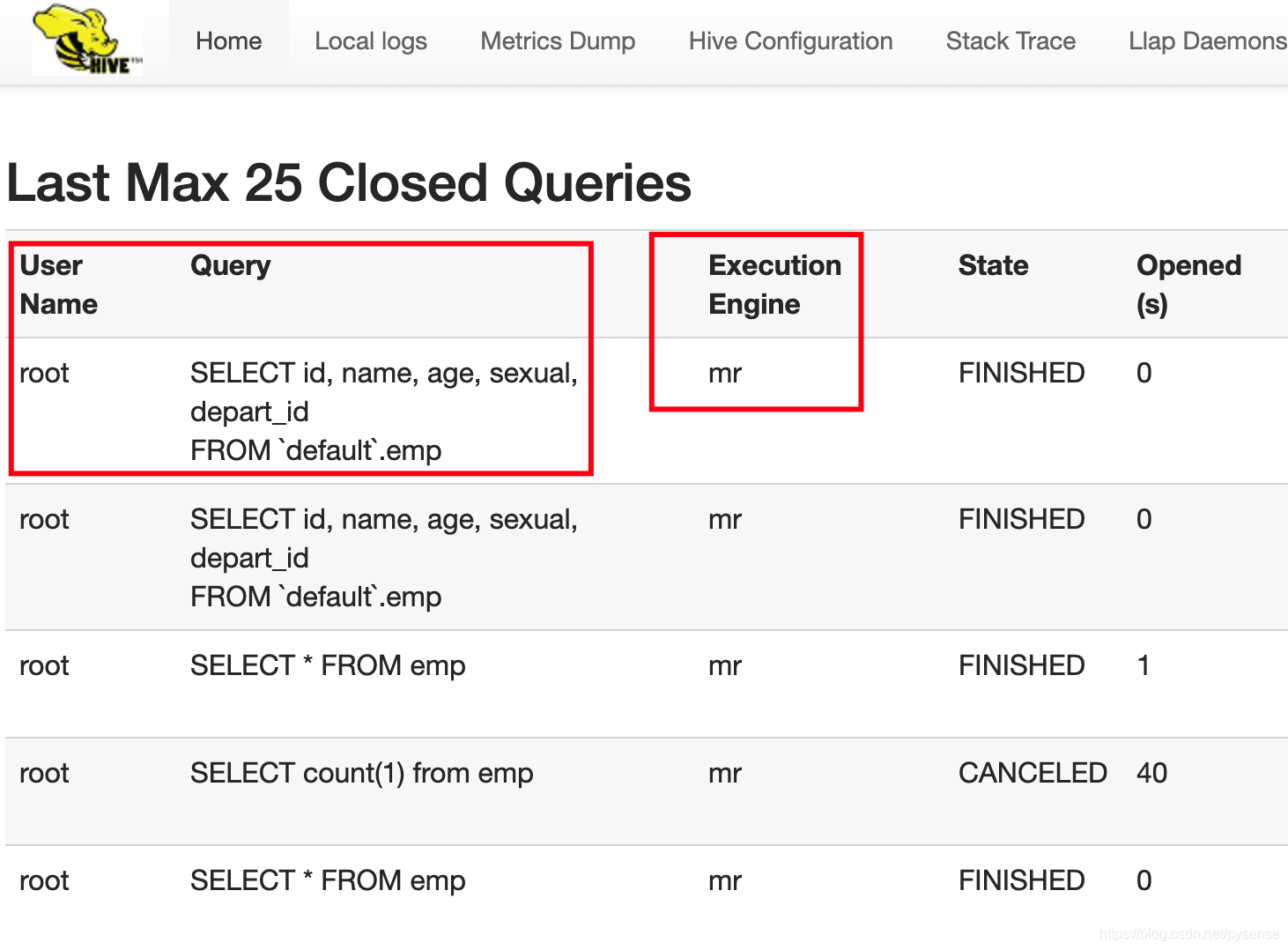
 已经完成的查询语句,这里可以看到HQL使用底层计算框架为MapReduce
已经完成的查询语句,这里可以看到HQL使用底层计算框架为MapReduce
 至此,已经完成使用外部SQL客户端工具DBeaver连接hive的任务,那么接下来:在Hbase导入大数据文件,部署高可用hiveserver2服务。
至此,已经完成使用外部SQL客户端工具DBeaver连接hive的任务,那么接下来:在Hbase导入大数据文件,部署高可用hiveserver2服务。
8 使用beeline连接hiveserver2
在以上章节都提到两种方式连接到hiveserver2,此外,还有hive自带的一个客户端工具beeline,也可以连接到hive,按hive的官方规划,beeline将取代之前版本的hive cli。具体为何取代hive cli,参考官网说明:
HiveServer2 (introduced in Hive 0.11) has its own CLI called Beeline.
HiveCLI is now deprecated in favor of Beeline, as it lacks the
multi-user, security, and other capabilities of HiveServer2. To run
HiveServer2 and Beeline from shell:
连接用法hiveserver2的用法:
beeline -u jdbc:hive2:nn:10000 -n root -p ****
可以看出因为beeline在使用jdbc接口连接时要求带入hive-site.xml配置账户和密码,因此官网说提供了 security功能。
具体使用方式这里不再
8、部署高可用的Hive服务
以上仅在hdfs、hbase的主节点nn配置hive单集服务,hive可以看做是hdfs对外提供的SQL客户端服务,若nn节点不可用,将导致nn节点hive服务也无法使用,因此实际生产环境,需要将hive部署为HA模式,与hdfs和hbaseHA模式一起构成完整的高可用离线分析大数据开发环境。这部分的内容在下一篇文章给出:构建高可用Hive HA和整合HBase开发环境(二)
