前言
Redis中有一个经典的问题,在巨大的数据量的情况下,做类似于查找符合某种规则的Key的信息,这里就有两种方式,
一、 keys命令
简单粗暴,由于Redis单线程这一特性,keys命令是以阻塞的方式执行的,keys是以遍历的方式实现的复杂度是 O(n),Redis库中的key越多,查找实现代价越大,产生的阻塞时间越长。
keys * 、keys codehole* 分别是查询全部的key以及查询前缀为codehole的key。特点太暴力,性能不好,搜索的是整个redis;
缺点:
1、没有 offset、limit 参数,一次性吐出所有满足条件的 key,万一实例中有几百 w 个 key 满足条件,当你看到满屏的字符串刷的没有尽头时,你就知道难受了。
2、keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,所有读写 Redis 的其它的指令都会被延后甚至会超时报错,因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完了才可以继续。
二、 scan命令
以非阻塞的方式实现key值的查找,绝大多数情况下是可以替代keys命令的,可选性更强
scan命令的特点:
1、复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
2、提供 limit 参数,可以控制每次返回结果的最大条数,limit 只是一个 hint,返回的结果可多可少;
3、同 keys 一样,它也提供模式匹配功能;
4、服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
5、返回的结果可能会有重复,需要客户端去重复,这点非常重要;
正常情况下,使用scan没问题,如果正在rehash,则会造成重读
比如现在有四个桶,读了0,1,发生rehash时, 0会到4上,1是到5,造成重读,
redis使用高位递增遍历,如下, 当02,遍历完以后0426肯定是遍历完的
但缩容有可能发成key重复
00 0
10 2
01 1
11 3
000 0
100 4
010 2
110 6
001 1
101 7
011 3
111 8
6、遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
7、单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
三、keys、scan命令具体用法
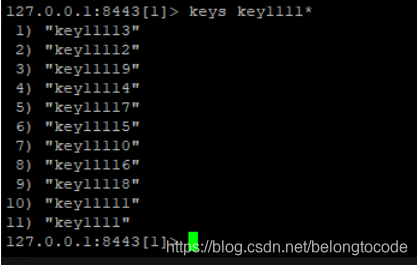
比如这里查询key111开头的key有哪些?
若使用keys命令,则执行keys key1111*,一次性全部查出来。
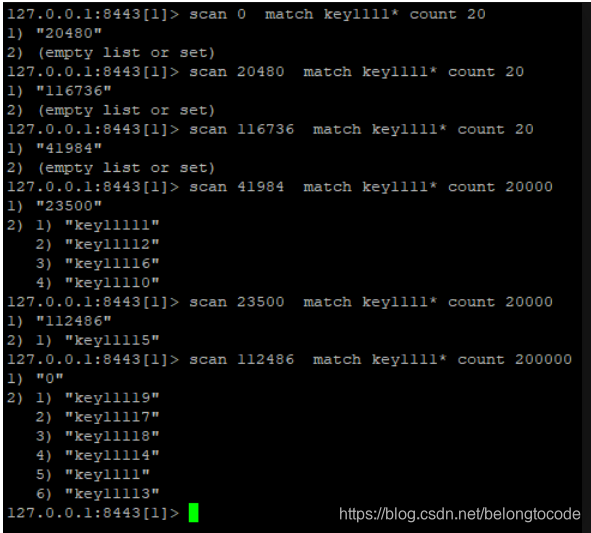
同样,如果使用scan命令,则用scan 0 match key1111* count 20
scan的语法为:SCAN cursor [MATCH pattern] [COUNT count]The default COUNT value is 10.
SCAN命令是一个基于游标的迭代器。这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
这里使用scan 0 match key1111* count 20命令来完成这个查询,稍显意外的是,使用一开始都没有查询到结果,这个要从scan命令的原理来看。
scan在遍历key的时候,0就代表第一次,key1111*代表按照key1111开头的模式匹配,count 20中的20并不是代表输出符合条件的key,而是限定服务器单次遍历的字典槽位数量(约等于)。
那么,什么又叫做槽的数据?这个槽是不是Redis集群中的slot?答案是否定的。其实上图已经给出了答案了。
如果上面说的“字典槽”的数量是集群中的slot,又知道集群中的slot数量是16384,那么遍历16384个槽之后,必然能遍历出来所有的key信息,上面清楚地看到,当遍历的字典槽的数量20000的时候,游标依旧没有走完遍历结果,因此这个字典槽并不等于集群中的slot的概念。
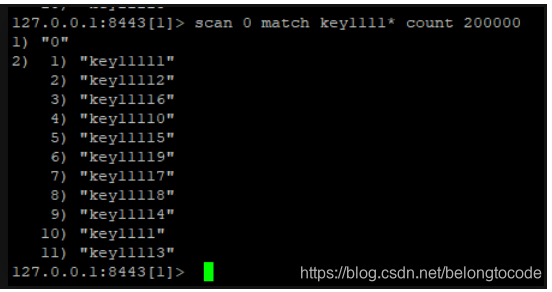
经过测试,在scan的时候,究竟遍历多大的COUNT值能完全match到符合条件的key,跟具体对象的key的个数有关,
如果以超过key个数的count来scan,必定会一次性就查找到所有符合条件的key,比如在key个数为10W个的情况下,一次遍历20w个字典槽,肯定能完全遍历出来结果。
四、探究scan底层源码
Redis的结构
Redis使用了Hash表作为底层实现,原因不外乎高效且实现简单。说到Hash表,很多Java程序员第一反应就是HashMap。没错,Redis底层key的存储结构就是类似于HashMap那样数组+链表的结构。其中第一维的数组大小为2n(n>=0)。每次扩容数组长度扩大一倍。
scan命令就是对这个一维数组进行遍历。每次返回的游标值也都是这个数组的索引。limit参数表示遍历多少个数组的元素,将这些元素下挂接的符合条件的结果都返回。因为每个元素下挂接的链表大小不同,所以每次返回的结果数量也就不同。
SCAN的遍历顺序
关于scan命令的遍历顺序,我们可以用一个小栗子来具体看一下。
127.0.0.1:6379> keys *
1) "db_number"
2) "key1"
3) "myKey"
127.0.0.1:6379> scan 0 MATCH * COUNT 1
1) "2"
2) 1) "db_number"
127.0.0.1:6379> scan 2 MATCH * COUNT 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 MATCH * COUNT 1
1) "3"
2) 1) "key1"
127.0.0.1:6379> scan 3 MATCH * COUNT 1
1) "0"
2) (empty list or set)
我们的Redis中有3个key,我们每次只遍历一个一维数组中的元素。如上所示,SCAN命令的遍历顺序是
0->2->1->3
这个顺序看起来有些奇怪。我们把它转换成二进制就好理解一些了。
00->10->01->11
我们发现每次这个序列是高位加1的。普通二进制的加法,是从右往左相加、进位。而这个序列是从左往右相加、进位的。这一点我们在redis的源码中也得到印证。
在dict.c文件的dictScan函数中对游标进行了如下处理
v = rev(v);
v++;
v = rev(v);
意思是,将游标倒置,加一后,再倒置,也就是我们所说的“高位加1”的操作。
这里大家可能会有疑问了,为什么要使用这样的顺序进行遍历,而不是用正常的0、1、2……这样的顺序呢,这是因为需要考虑遍历时发生字典扩容与缩容的情况(不得不佩服开发者考虑问题的全面性)。
我们来看一下在SCAN遍历过程中,发生扩容时,遍历会如何进行。加入我们原始的数组有4个元素,也就是索引有两位,这时需要把它扩充成3位,并进行rehash。
rehash
原来挂接在xx下的所有元素被分配到0xx和1xx下。在上图中,当我们即将遍历10时,dict进行了rehash,这时,scan命令会从010开始遍历,而000和100(原00下挂接的元素)不会再被重复遍历。
再来看看缩容的情况。假设dict从3位缩容到2位,当即将遍历110时,dict发生了缩容,这时scan会遍历10。这时010下挂接的元素会被重复遍历,但010之前的元素都不会被重复遍历了。所以,缩容时还是可能会有些重复元素出现的。
总结:scan遍历顺序采用高位进位加法来遍历,进位的方向是从高位到低位,原因是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
Redis的rehash
rehash是一个比较复杂的过程,为了不阻塞Redis的进程,它采用了一种渐进式的rehash的机制。
/* 字典 */
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
在Redis的字典结构中,有两个hash表,一个新表,一个旧表。在rehash的过程中,redis将旧表中的元素逐步迁移到新表中,接下来我们看一下dict的rehash操作的源码。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
通过注释我们就能了解到,rehash的过程是以bucket为基本单位进行迁移的。所谓的bucket其实就是我们前面所提到的一维数组的元素。每次迁移一个列表。下面来解释一下这段代码。
- 首先判断一下是否在进行rehash,如果是,则继续进行;否则直接返回。
- 接着就是分n步开始进行渐进式rehash。同时还判断是否还有剩余元素,以保证安全性。
- 在进行rehash之前,首先判断要迁移的bucket是否越界。
- 然后跳过空的bucket,这里有一个empty_visits变量,表示最大可访问的空bucket的数量,这一变量主要是为了保证不过多的阻塞Redis。
- 接下来就是元素的迁移,将当前bucket的全部元素进行rehash,并且更新两张表中元素的数量。
- 每次迁移完一个bucket,需要将旧表中的bucket指向NULL。
- 最后判断一下是否全部迁移完成,如果是,则收回空间,重置rehash索引,否则告诉调用方,仍有数据未迁移。
由于Redis使用的是渐进式rehash机制,因此,scan命令在需要同时扫描新表和旧表,将结果返回客户端。
总结:redis的扩容:旧的数据移动到新的新组下,redis采用渐进式 rehash,同时保留旧数组和新数组
参考文章:
https://www.jianshu.com/p/be15dc89a3e8
https://blog.csdn.net/zanpengfei/article/details/83691841
http://jinguoxing.github.io/redis/2018/09/04/redis-scan/
