前言:介绍dom4j解析xml和xpath解析xml。
--------解析方式---------
1.sax:特点:逐行解析,只能查询.
2.dom:特点:一次性将文档加载到内容中,形成一个dom树.可以对dom树curd操作
-------解析技术---------
JAXP:sun公司提供支持DOM和SAX开发包
JDom:dom4j兄弟
jsoup:一种处理HTML特定解析开发包
★dom4j:比较常用的解析开发包,hibernate底层采用。
-----dom4j解析xml-------
使用步骤:1.导入jar包
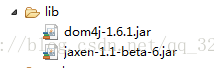
2.创建一个核心对象 SAXReader,new SAXReader();
3.将xml文档加载到内存中形成一棵树,Document doc=reader.read(文件)
4.获取根节点,Element root=doc.getRootElement();
5.通过根节点就可以获取其他节点(文本节点,属性节点,元素节点)
获取所有的子元素:List<Element> list=root.elements()
获取元素的指定属性内容:String value=root.attributeValue("属性名");
获取子标签标签体:遍历list 获取到每一个子元素,String text=ele.elementText("子标签名称")
6.代码实现:
需要解析的内容如图:
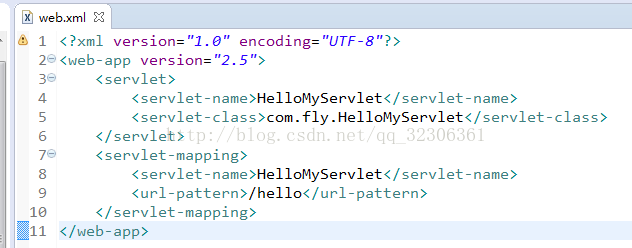
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jDemo {
public static void main(String[] args) throws Exception {
//创建核心对象
SAXReader reader = new SAXReader();
//获取dom树
Document doc = reader.read("D:\\fly\\javaee\\Day0801\\xml\\web.xml");
//获取根节点
Element root = doc.getRootElement();
//获取其他节点
List<Element> list = root.elements();
//遍历集合
for (Element ele : list) {
//获取servlet-name的标签体
String text = ele.elementText("servlet-name");
// System.out.println(text);
String text2 = ele.elementText("url-pattern");
// System.out.println(text2);
}
//获取root的version属性值
String value = root.attributeValue("version");
System.out.println(value);
}
}1、依赖于dom4j
2、使用步骤:
1)导入jar包(dom4j和jaxen-1.1-beta-6.jar)
2)加载xml文件到内存中
3)使用api:selectNode("表达式"),selectSingleNode("表达式");
3、表达式的写法:
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
例如一个标签下有一个id属性且有值 id=2;
//元素名[@属性名='属性值']
//元素名[@id='2']
4、代码:
import java.util.List;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class XpathDemo {
public static void main(String[] args) throws Exception {
Document doc = new SAXReader().read("D:\\fly\\javaee\\Day0801\\xml\\web.xml");
Element ele = (Element) doc.selectSingleNode("//servlet/servlet-name");
System.out.println(ele.getText());
}
}