Spring Crest应当是个codename,代表其出品的神经网络的训练场景的加速卡。还有推理场景的加速卡,推理的设计可能会简单一点以后再看。
- 采用的是TSMC 16nm工艺,采用的是硅中介的封装。叫做CoWos的2.5D的封装,Chip on Wafer on Substrate,(Wafer是圆晶,Substrate是基底);
- 60*60=2600mm^2(相当于是BGA的面积),其中1200mm^2的CoWos封装(相当于是硅中介的面积);其中Die的大小是680mm^2。
- 含有24个TPC(Tensor Processor Clusters),支持bfloat16,也就是具有fp32的计算精度;互联也是mesh网状结构。24个TPC按照4个内存,分为4个模块。
- 芯片支持两种形态:PCIe X16 Gen4(300W TDP)和OCP的OAM(375W TDP)形态。OAM形态下ICL并不是全部引出。
整个芯片的方块图如下:
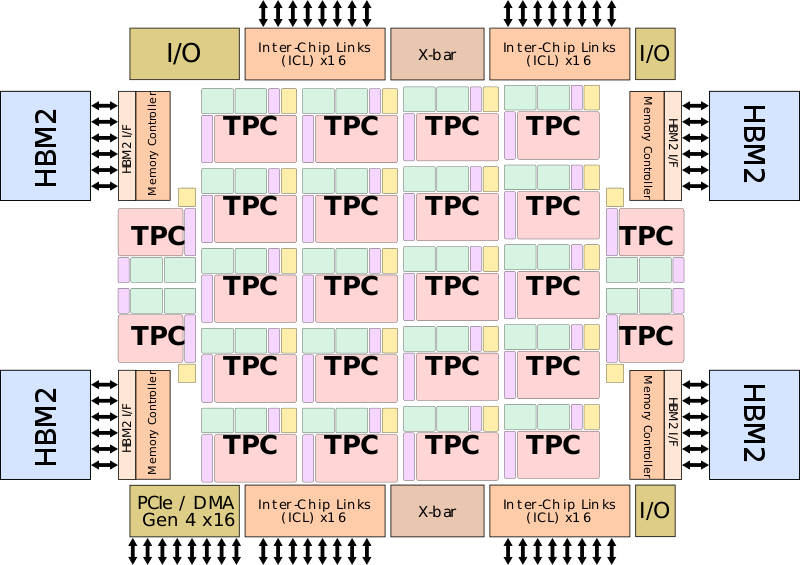
可以看出主要有下面三个方面:
- 内存方面:可以看出四边还有4个HBM2,8Hi的。每个模块四8GiB,合计是32GiB。并且工作频率是2400MHz(已经DDR倍频)。已经算是很高了。内存的带宽是:4个HBM2*1024bit*2400MHz/8/1000=1228.8GB/s=1.229TB/s
- 互联方面:互联上实现了X16*4个SerDes,工作频率是28Ghz,那么整体的带宽是:28GHz*64bit/8*2双向=448GB/s;ICL支持环状互联,全互联,立方体互联。OAM可以实现1024个互联。(PICe和ICL不是复用SerDes)
- 计算方面:参考下面对TPC的分析;一个Spring Crest有24个TPC。
TPC的方块图如下:
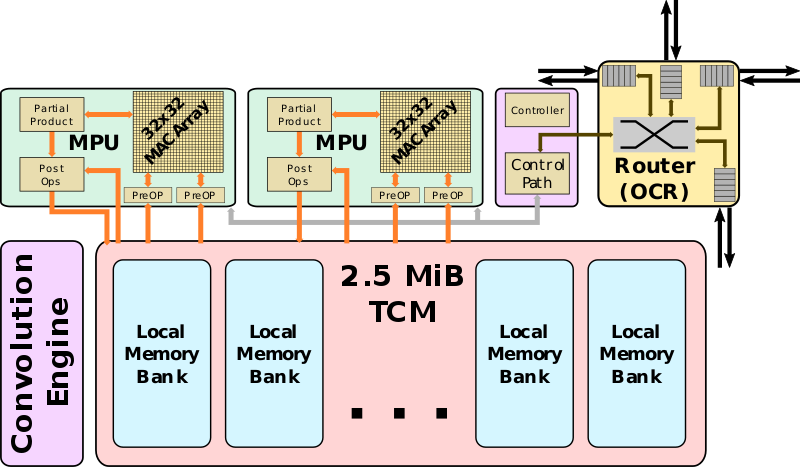
主要可以看出有四个系统:
- On Chip Router,相当于和外部联系的中转站
- The Controller,相当于控制器,主要是指令解码,调度操作,和循环指令。顺便协调TPC内部的计算单元。其中的ISA是简单的tensor指令集。
- MPU主要的运算部分,每个TPC包含2个MPU(MAC Processing Unit);每个MPU包含32*32的MAC Array,频率是1.1GHz,那么性能是:32*32*2M/A*1FLOPs/cycle*1.1Ghz=2.25TFLOPs。整个Chip的计算能力是24*2*2.25=108TFLOPs(FP32).
- 内存子系统,主要是缓存的作用,大小是2.5MiB,那么整个24个TPC可以提供的是24*2.5MiB=60MiB的缓存。并且针对并行计算有优化。这一部分的MPU和缓存的带宽是1.4Tbps,暂时不知道怎么计算的。
参考文献:
主要介绍了spring crest的参数
主要给出了MPU的工作频率,可以计算整体的理论性能
可以从下面的连接看到ICL实现的OAM的级联的方案,在上面没展开