本周主要学习了self-attention的原理、精读论文《A Self-Attentive model for Knowledge Tracing》和他人复现该论文的代码。
1.self-attention介绍
2015-2017年,自从 attention 提出后,基本就成为 NLP 模型的标配。
《attention is all you need》中指出:1. 靠attention机制,不使用rnn和cnn,并行度高 2.通过attention,抓长距离依赖关系比rnn强
(1)self-attention基本结构:
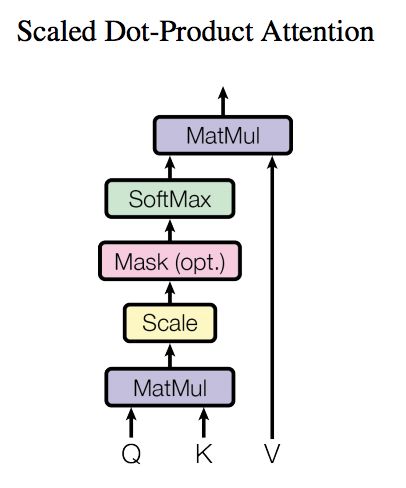
图1
Q(Query), K(Key), V(Value)三个矩阵均来自同一输入。
(2)self-attention计算
第一步:从每个编码器的输入向量(每个单词的词向量)中生成三个向量。即对于每个单词,创造一个查询向量Q、一个键向量K和一个值向量V。这三个向量都是通过词嵌入与三个权重矩阵后相乘创建的,如下图所示。
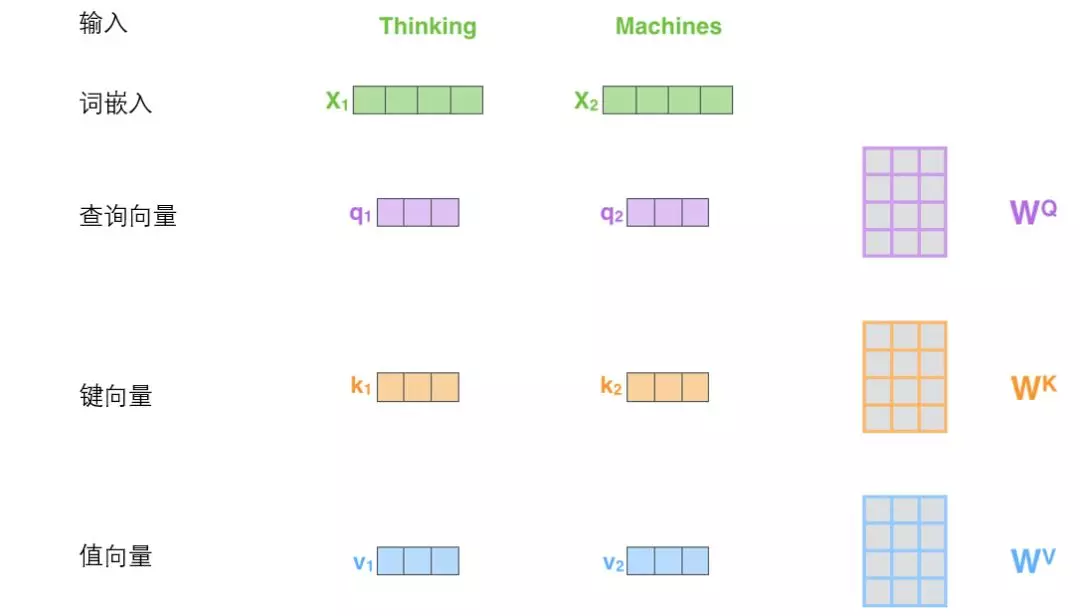

图2
X1与WQ权重矩阵相乘得到q1, 就是与这个单词相关的查询向量,同理得到键向量和值向量。WQ 、WK 、WV 都是随机初始化得到的。
第二步:计算得分,计算本例子中的第一个词“Thinking”自注意力向量,需要将输入句子中的每个单词对“Thinking”打分。即这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。这些分数是通过打分单词(所有输入句子的单词)的 键向量K 与“Thinking”的 查询向量Q 进行点积来计算的。如下图所示,Thinking单词的得分是q1*k1=112。
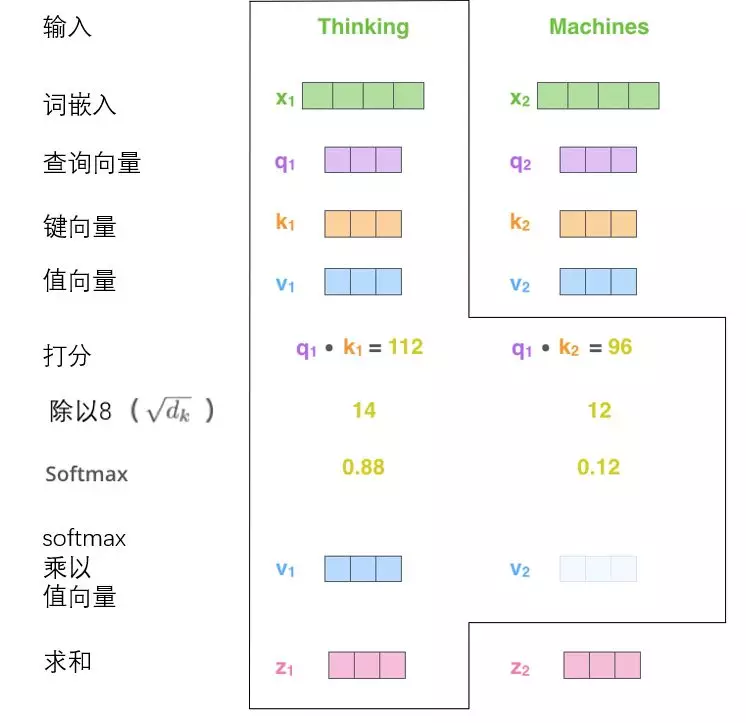
图3
第三步:第三步是将分数除以8,8是键向量K的维数dk =64的平方根,如图3所示。
第四步:通过softmax使所有单词的分数归一化,得到的分数都是正值,且和为1,如图3所示。这个softmax分数决定了每个单词对当前编码位置(“Thinking”)的贡献。
第五步:将每个值向量V乘以softmax分数。这里是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。如图3所示。
第六步:对加权值向量求和等到z,然后即得到自注意力层在该位置的输出(在图3例子中是对于第一个单词)。
(3)通过矩阵运算实现self-attention
第一步:计算查询矩阵、键矩阵和值矩阵。将输入句子的词嵌入装进矩阵X中(X中的每一行代表输入句子的一个单词所对应的词向量),再乘以训练的权重矩阵(WQ 、WK 、WV )。
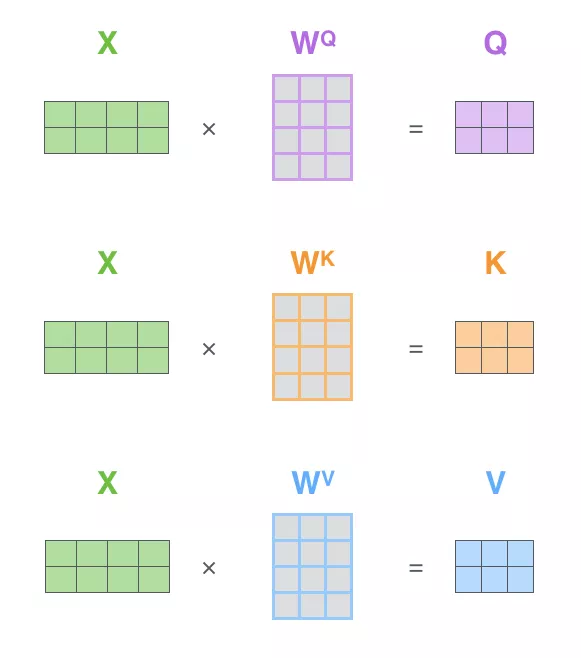
图4
第二步:根据公式1,计算self-attention的输出。
公式1: 
seff-attention的矩阵运算形式:
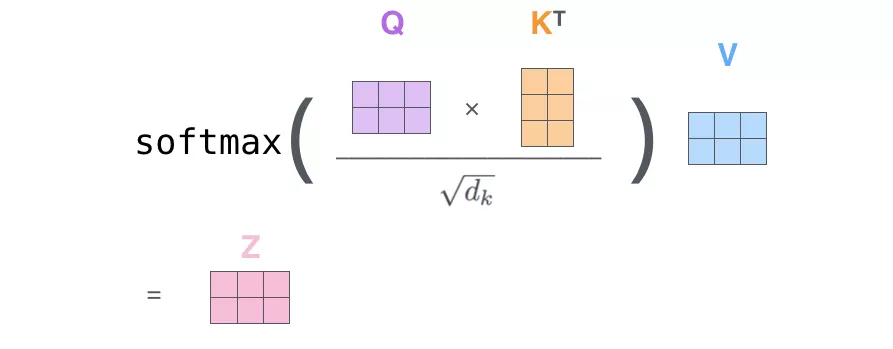
图5
(4)举例
“I arrived at the bank after crossing the river” ,句子中的bank指的是银行还是河岸呢,这就需要联系上下文,当看到river,就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。
Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。
(5)Multi-head Attention
Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,即侧重点可能略有不同,这样给了模型更大的容量。
在这里我们以 举例说明。Multi-Head Attention的输出分成3步:
1.将数据 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵
。
2.将8个 按列拼成一个大的特征矩阵;
3.特征矩阵经过一层全连接后得到输出 。

图6 Muti-head attention 计算过程
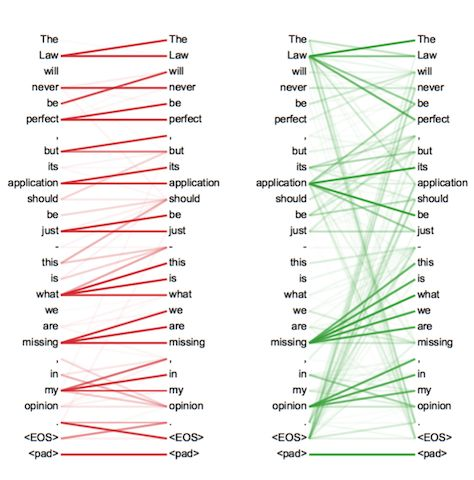
图7 两个head学习到的Attention侧重点略有不同
2.Transformer模型
上面介绍的self-attention只是Ttransformer模型中的一层神经网络。Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
《Attention is all you need》论文中,采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
1.时间片 的计算依赖
时刻的计算结果,这样限制了模型的并行能力;
2.顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
(1)Encoder&Decoder
Transformer的本质上是一个Encoder-Decoder的结构。
 =
= 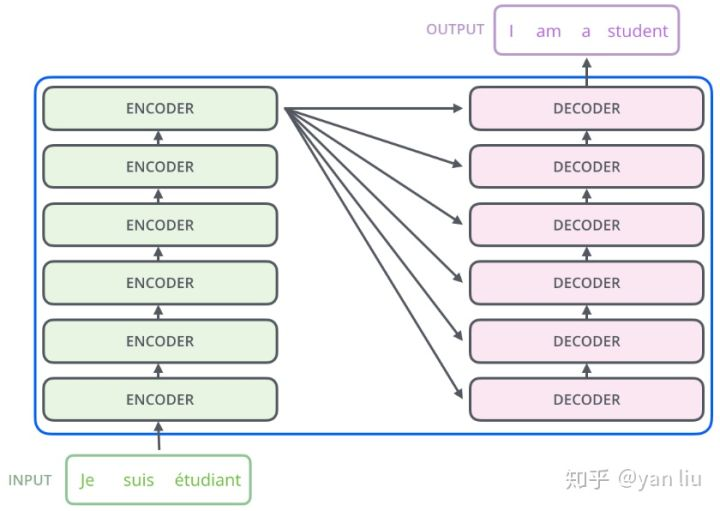
图8 图9
1.Encoder:
(1)数据经过Self-attention模块得到一个加权之后的特征向量 Z,公式如下图所示。
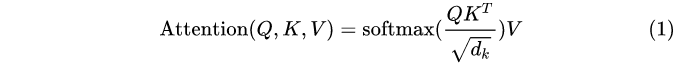
(2)将Z输入到Feed Forward Neural Network,这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,公式如下图所示。
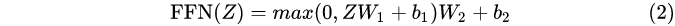

图11 Encoder结构
2.Decoder:
与Encoder相比,Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
1.Self-Attention:当前翻译和已经翻译的前文之间的关系;
2.Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
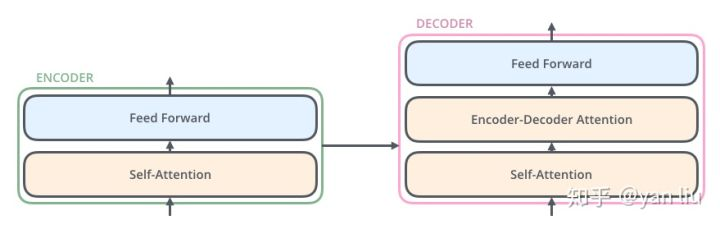
图12 Decoder结构
(2)位置编码
论文中在编码词向量时引入了位置编码(Position Embedding)的特征,即位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。通常位置编码是一个长度为 的特征向量,这样便于和词向量进行单位加的操作。
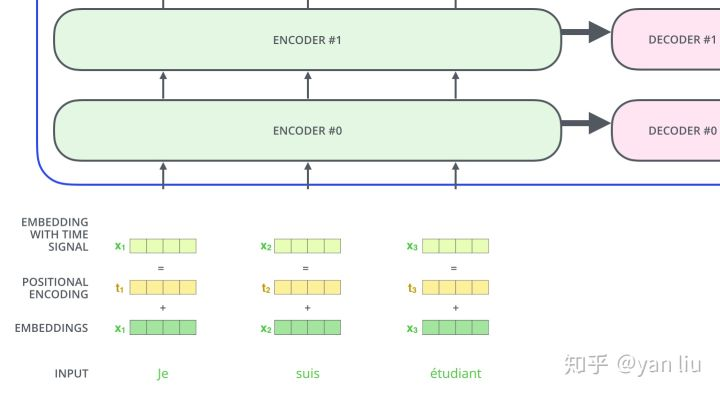
图13
(3)Transformer 还用了残差网络(Residual Connection)、归一化(Normalization)来处理数据。
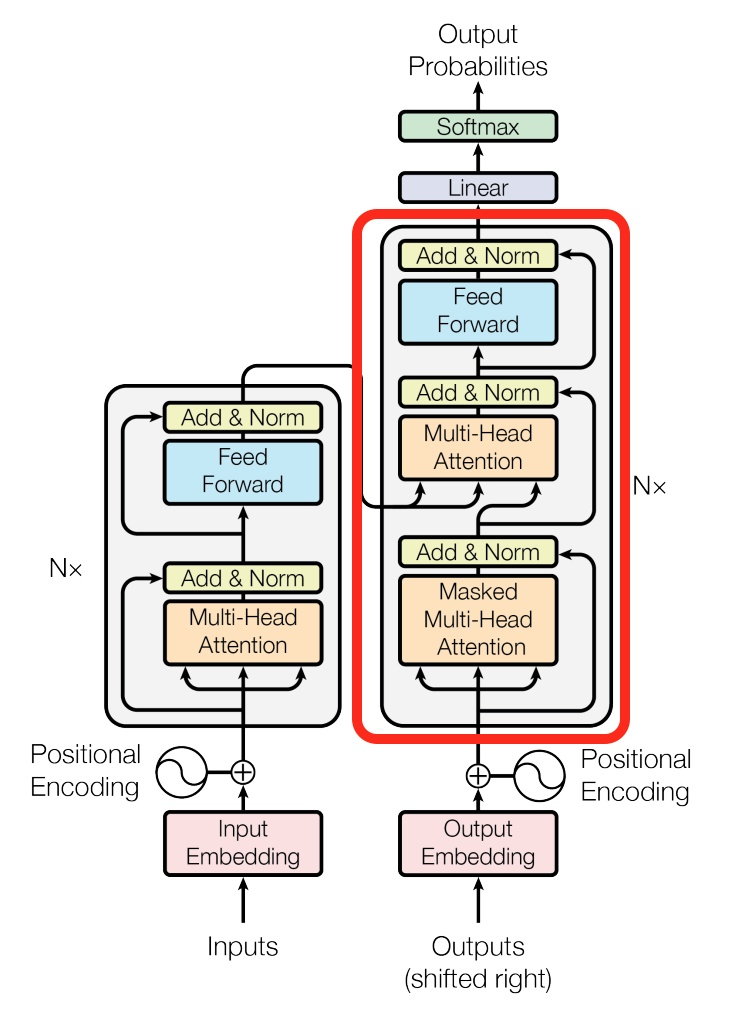
图14 Transformer 模型
3.论文《A Self-Attentive model for Knowledge Tracing》
本论文将标准的Transformer模型应用到Konwledge Tracing中,主要的区别在于数据的输入。
数据处理:
(1)键向量k和值向量来自于学生先前的问题回答交互序列xi=(ei , ri), ei 指的是问题的序号,ri 指的是当前问题 ei 是否回答正确,正确用1表示,错误用0表示。
(2)查询向量q的输入来自于学生的即将回答问题序列 ei+1 。
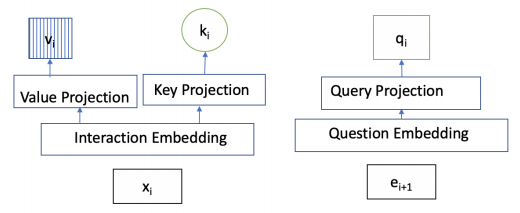
图15 查询向量、键向量、值向量的输入
(3)Embedding layer: yt = et + rt * E(y在0~2E之间),E指的是问题序列的总数量。将yt 转换 Interaction embedding matrix M(维度为2E*d),类似词向量矩阵,即将问题转换为向量表示。
(4)Positon Encoding : 在问题向量中加入问题的位置信息。
本文模型还使用了Self-attention layer、Mutiple heads、Feed Forward layer、Residual Connections、Layer normalization、Prediction layer,与前面介绍的使用相同,即代入相应大的公式计算。
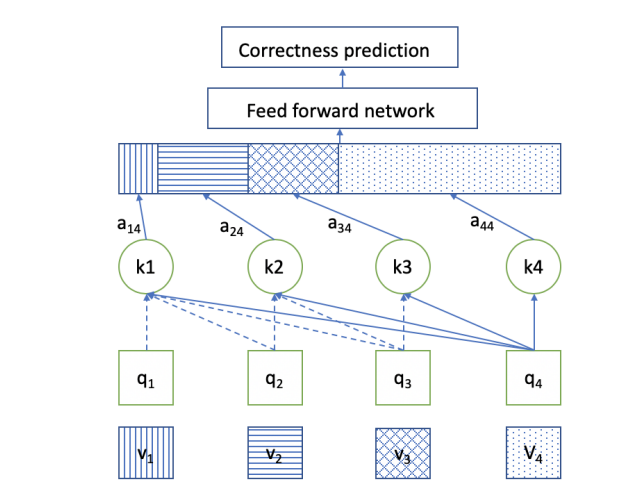
图16 论文模型框架
4.下周计划
思考像Transformer的升级版Transformer-XL模型、XLnet模型能否应用到Konwledge Tracing中。
参考:1.《BERT大火却不懂Transformer?读这一篇就够了》https://mp.weixin.qq.com/s/WDq8tUpfiKHNC6y_8pgHoA
2.《详解Transformer》 https://zhuanlan.zhihu.com/p/48508221
3.《Attention机制详解》 https://zhuanlan.zhihu.com/p/47282410