- 一、为什么要使用索引
- 二、什么样的信息能成为索引
- 三、索引的数据结构
- 四、密集索引和稀疏索引的区别
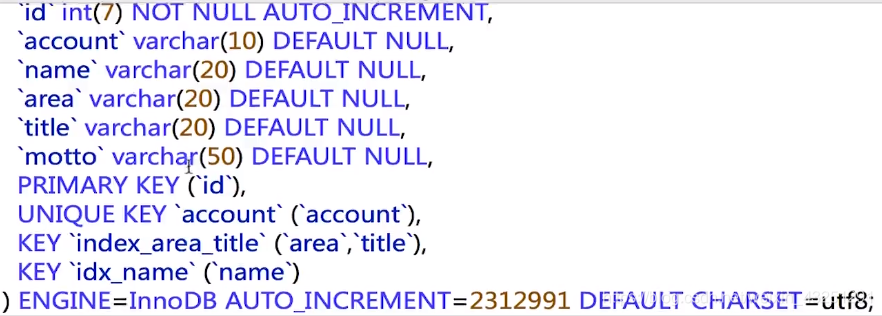
- 索引
- 锁模块常见问题
- 1.MyISAM与InNoDB关于锁方面的区别是什么
- 2.数据库事务的四大特性 ACID
- 3.事务隔离级别以及级别下的并发访问问题
- 更新丢失--mysql所有事务隔离级别在数据库层面上均可避免
- 脏读READ-UNCOMMITTED--READ-COMMITTED事务隔离级别以上可避免
- 不可重复读READ-COMMITTED -- REPEATABLE-READ事务隔离级别以上可避免
- 幻读REPEATABLE-READ -- SERIALIZABLE事务隔离级别以上可避免
- 串行化SERIALIZABLE
- 事务隔离级别性能表
- 4.InnoDB可重复读隔离级别下如何避免幻读
- 5.RC、RR级别下的InnoDB的非阻塞读如何实现
- 语法
一、为什么要使用索引
二、什么样的信息能成为索引
三、索引的数据结构
四、密集索引和稀疏索引的区别
索引
1.如何定位并优化慢查询
Ⅰ.根据慢日志定位慢查询SQL
<1> 展示慢日志设置命令
show variables like '%quer%';
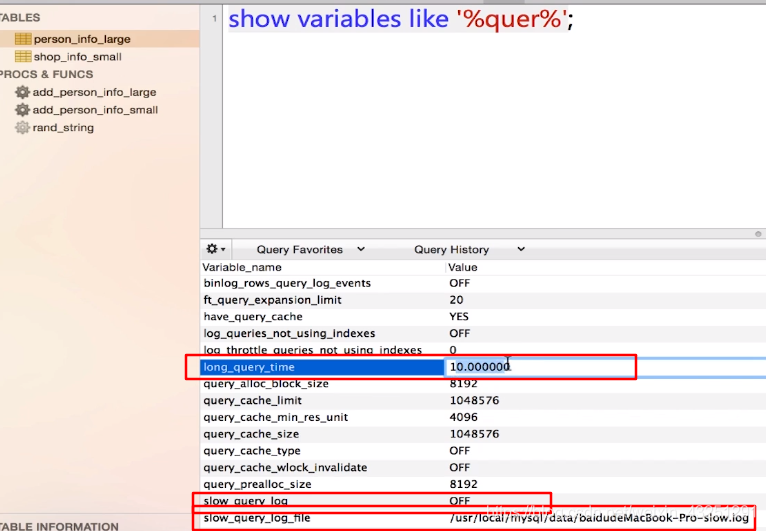
<2> slow_query_log: 慢日志, 将OFF改为ON
set global slow_query_log = on;
<3> long_query_time: 每次SQL执行10秒已经超级慢了, 改成1s, 1s即需优化
set global long_query_time = 1;
slow_query_log_file: 慢日志的全路径
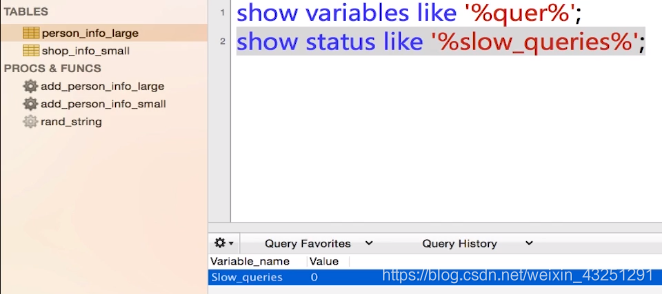
<4> 查询系统的状态
show status like '%slow_queries';
<5> 关联数据库数据
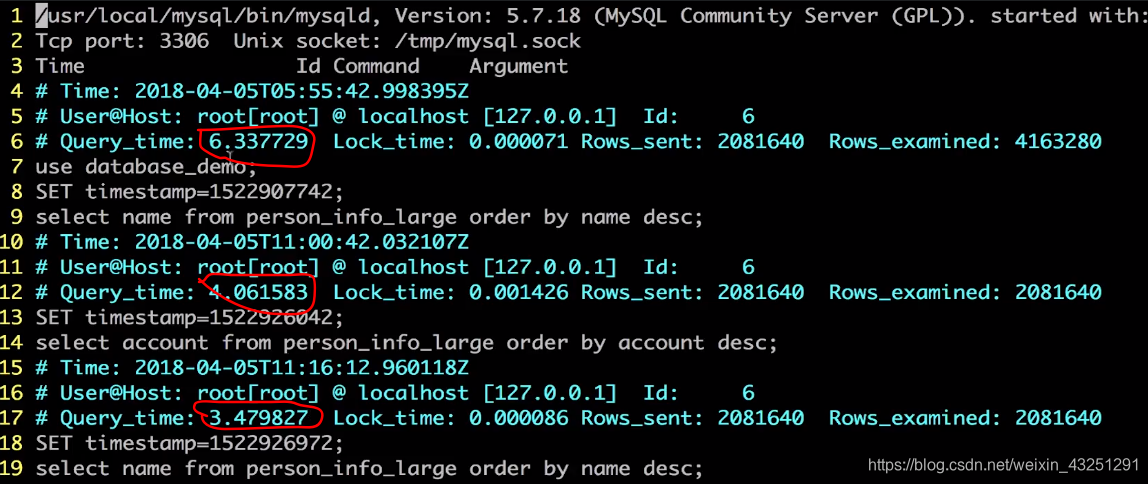
select count(id) from person_info_large;
select name from person_info_large order by name desc;(数量过大会记录到慢查询日志文件)
打开慢日志
sudo vim /usr/local/mysql/data/baidudeMacBook-Pro-slow.log
Ⅱ.使用explain等工具分析SQL
explain select name from person_info_large order by name desc;
分析显示如下

type
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>all
出现黄色标记的就需要优化,因为进行了全表扫描
extra
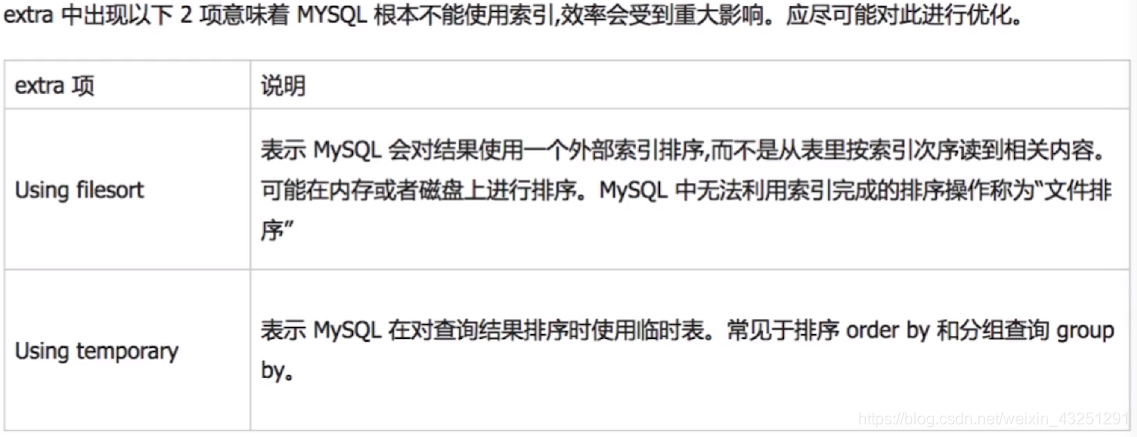
Ⅲ.修改SQL或者尽量让SQL走索引
explain select name from person_info_large order by name desc;
explain select account from person_info_large order by account desc;
如下图type extra已改善, key:account

select account from person_info_large order by account desc;
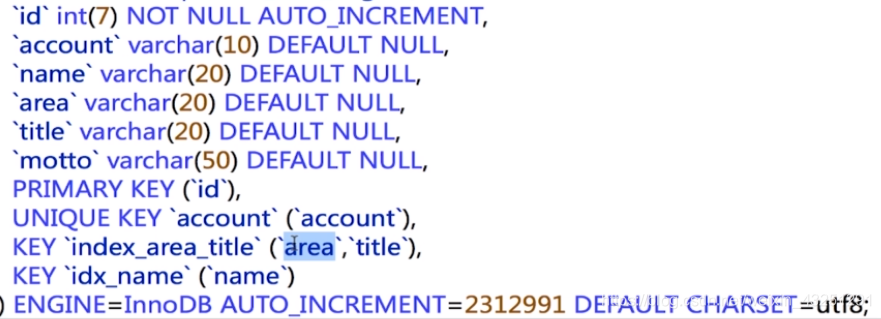
如果一定要按照名字来查询, 就在name上面加上索引, 这句是数据定义语言, 不会写入慢查询日志
alter table person_info_large add index idx_name(name);
explain select count(id) form person_info_large;
(默认唯一键, mysql尽可能使用最严格的的索引)

explain select count(id) form person_info_large force index (primary);
(强制走主键索引)

2.联合索引的最左匹配原则的成因
联合索引: 就是由多列组合的索引
explain select * form person_info_large where area = 'EJZszkSK' and title = 'ABdfGF' ;
(按照左边索引area查询)

explain select * form person_info_large where area = 'EJZszkSK';
(按照左边area索引查询)

explain select * form person_info_large where title = 'ABdfGF' ;
(全表查询,没有找到左侧索引)

最左匹配原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配, 比如a = 3 and b = 4 and c > 5 and d = 6 如果建立(a, b, c, d)顺序的索引, d 是用不到索引的,如果建立(a, b, d, c)的索引则都是可以用到, a, b, d的顺序可以任意调整.
2.=和in可以乱序, 比如a = 1 and b = 2 and c = 3 建立(a, b, c)索引可以任意顺序, mysql的查询优化器会帮你优化成索引可以识别的实行
3.索引是建立的越多越好吗
数据量小的表不需要建立索引, 建立会增加额外的索引开销
数据变更需要维护索引,因此更多的索引意味着更多的维护
更多的索引意味着也需要更多的空间
锁模块常见问题
1.MyISAM与InNoDB关于锁方面的区别是什么
MyISAM默认用的是表级锁, 不支持行级锁
InnoDB默认用的是行级锁, 也支持表级锁
备注:一个tap表示一个新的session
MyISAM
session1: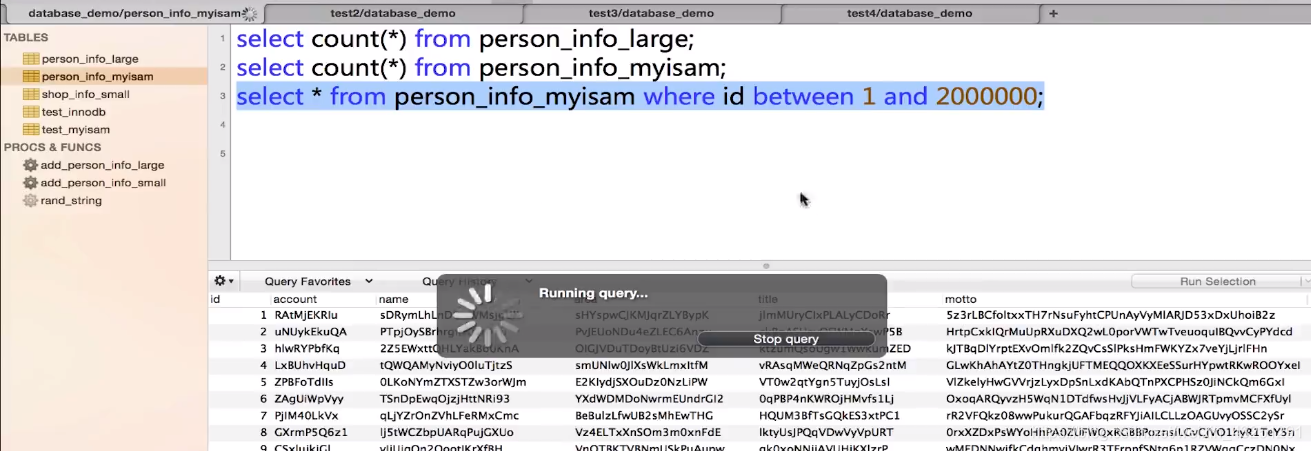
session2:

同时执行两个session, 结果session1执行之后,由于数据量大, 建立表锁, block其他的表进行更新, 执行finish才会执行session2的更新
MyISAM结论:
当数据被select的时候, 自动加上一个表级的读锁, 当对数据进行增删改的时候, 会自动加一个表级别的写锁, 当读锁未被释放的时候, 另一个session相对同一张表加一个写锁, 就会被阻塞, 直到所有的读锁被释放为止.
如何显示给表加上读锁呢?
lock tables person_info_MyISAM read | write;
释放读锁:
unlock tables;
读锁也叫共享锁, 写锁也叫排他锁
InnoDB
默认自动提交事务, 用的是2道锁, 加锁和解锁
下图设置仅支持当前session
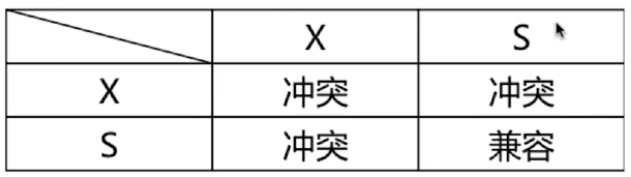
共享锁和排斥锁的兼容性
行级锁和表级锁的利弊
密度越细代价越高,表级锁直接加到表头,行级锁要扫描到具体行, InnoDB主键,查询辅助索引需要先查询主键再查到数据, MyISAM, 数据和文件分开, 索引保存的是数据文件的指针, 主键索引和辅助索引是独立的, 少量的增删改
MyISAM适合的场景
频繁执行全表count语句
对数据进行增删改的频率不高, 查询非常频繁
没有事务
InnoDB适合的场景
数据增删改查都相当频繁(增删改的时候只是某些行被锁,在大多数情况下都避免了阻塞, 避免锁住整张表)
可靠性要求比较高, 要求支持事务
数据库锁的分类
| 类型 | 分类锁 |
|---|---|
| 粒度 | 表级锁、行级锁、页级锁 |
| 锁级别 | 共享锁、排他锁 |
| 加锁方式 | 自动锁、显示锁 |
| 操作 | DML锁、DDL锁 |
| 使用方式 | 乐观锁和悲观锁 |
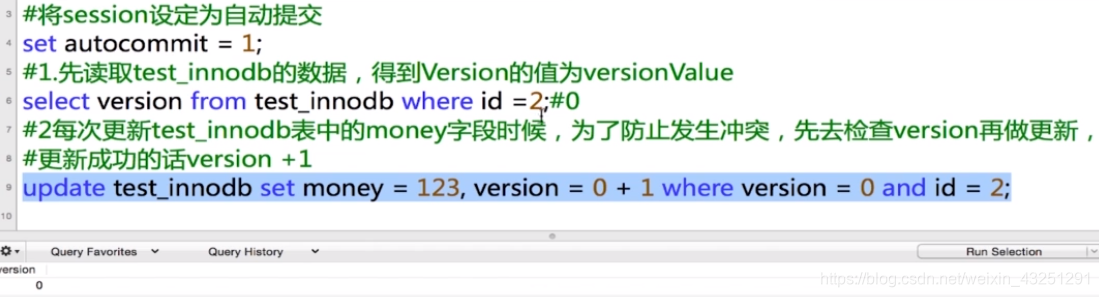
乐观锁基于数据版本version机制实现, 数据更新一次,version加一,下次修改前查看version
InnoDB
session1 提交之前检查版本, s2先执行, v=1,此时这里会查询报错
session2 这个先执行将v变成1
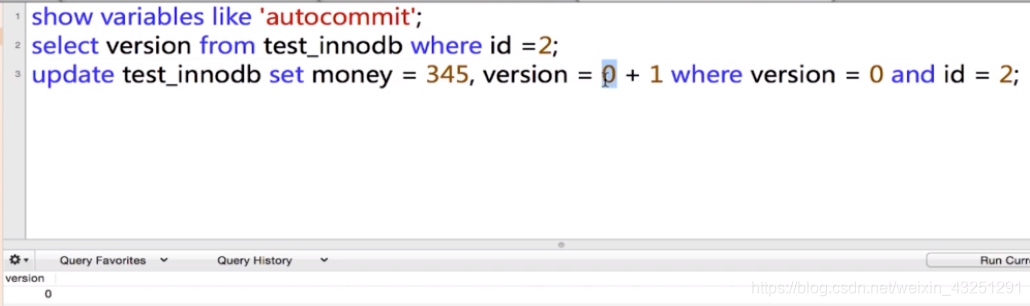
2.数据库事务的四大特性 ACID
原子性(Atomic)
要么全部执行,要么全部失败回滚
一致性(Consistency)
保持数据库从一个一致的状态转为另一个一致的状态
A:1000 B:1000 不管AB如何转账, 最后AB的总数一定是2000
隔离性(Isolation)
多个事务并发执行时, 一个事务的执行, 不应该影响其他事务的执行
持久性(Durability)
一个事务地提交应该永久的保存, 系统故障, 确保已经交的事务不能丢失和提交事物的恢复
InnoDB会将所有对页面的操作写入一个专门的文件(read do log file),并在数据库启动时,在此文件进行操作
3.事务隔离级别以及级别下的并发访问问题
事务并发访问引起的问题以及如何避免
更新丢失–mysql所有事务隔离级别在数据库层面上均可避免
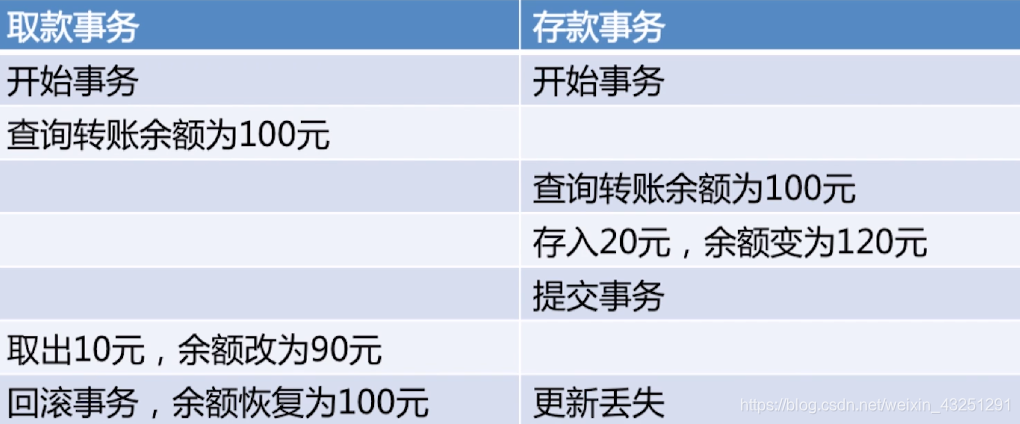
脏读READ-UNCOMMITTED–READ-COMMITTED事务隔离级别以上可避免
备注: 对一行做操作
select @@tx_isolation; # 查看事务隔离级别, 确认当前所有事务已经commit
select session transaction isolation level read uncommitted; # 设置隔离级别
start transaction; # 开启事务
step1
session1:
update account_innodb set balance = balance - 100 where id = 1;
select * form account_innodb where id = 1;
value: balance = balance(1000) - 100= 900 没有提交 未执行commit
session2:
select * form account_innodb where id = 1;
balance= 900 读到了session1未commit的数据
step2
session1:
rollback; # 由于某种原因回滚, 结果值返回 1000
session2:
update account_innodb set balance = balance +200 where id = 1;
balance = 900 +200 -->1100 实际是应该是回滚的数据 1000 + 200 = 1200
脏读, 本事务读到其他事务未提交的数据
避免脏读:
select session transaction isolation level read committed; # 设置隔离级别
不可重复读READ-COMMITTED – REPEATABLE-READ事务隔离级别以上可避免
备注: 对一行做操作
select @@tx_isolation; # 查看事务隔离级别, 确认当前所有事务已经commit
select session transaction isolation level read committed; # 设置隔离级别
start transaction; # 开启事务
step1
session1:读
select * from account_innodb where id = 1; # value=1300
session2:
update account_innodb set balance = balance + 300;
select * from account_innodb where id = 1;
commit;
step2
session1:
select * from account_innodb where id = 1; # value=1600
注意: session1事务开启未提交, 同一id的值没做任何更新操作,两次读取的结果不一样. 如果以第一次查询结果作增删变更, 会造成数据紊乱
避免不可重复读:
select session transaction isolation level repeatable read; # 设置隔离级别
变更到此事务级别, 可以避免session1未提交的第二次读取, 读取不到其他事务update的数据,但是自己update commit是根据其他事务update commit之后的数据来更新的
幻读REPEATABLE-READ – SERIALIZABLE事务隔离级别以上可避免
备注: 对数据库所有记录(整表)作操作
select @@tx_isolation; # 查看事务隔离级别, 确认当前所有事务已经commit
select session transaction isolation level repeatable read; # 设置隔离级别
start transaction; # 开启事务
step1
session1:
select * from account_innodb where id = 1; # value = 1600
update account_innodb set balance = 1000;
session2:
select * from account_innodb where id = 1; # value = 1600
update account_innodb set balance = balance + 400;
select * from account_innodb where id = 1; # 未提交查询value = 2000
step2
session1:
select * from account_innodb where id = 1;
value = 1600(不管step1 session2 commit与否, value都是1600)
可重复读,本次事务内,未提交,读的值都是一样的
update account_innodb set balance = balance - 100 where id = 1; # value = 1900
update的值会读取step1 session2 update commit 后的值进行增删
step
session1: # 当前读获取整张表的数据, 当前读是读取的当前事务提交的最新数据
select * from account_innodb lock in share mode; (加一个共享锁, 显示三条数据)
update account_innodb set balance = 1000;
注意:当session2insert一条数据后,执行此操作, 会显示更新4条数据的结果,实际只有三条, 不加共享锁, 会更新成4条
session2:
insert into account_innodb values(4,"Newman",500);
InnoDB默认行锁,但是会等待session1执行操作完成才会执行session2
串行化SERIALIZABLE
备注: 对一行做操作
select @@tx_isolation; # 查看事务隔离级别, 确认当前所有事务已经commit
select session transaction isolation level serializable; # 设置隔离级别
start transaction; # 开启事务
step
session1:
select * from account_innodb;
此事务级别所有的操作都会加上锁,即使不标注lock也会自动上锁
update account_innodb set balance = 1000;
commit;
session2:
insert into account_innodb values(5,"Oldman",600);
语句被block,需要等待session1commit或者rollback才能执行, 避免幻读的发生,此时session1表内数据均已上锁
commit;
事务隔离级别性能表
| 事务隔离级别 | 更新丢失 | 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|---|---|
| READ-UNCOMMITTED | 读未提交 | v | v | v | |
| READ-COMMITTED | 读提交 | v | v | ||
| REPEATABLE-READ | 重复读 | v | |||
| SERIALIZABLE | 串行化 |
Oracle默认: READ-COMMITTED
MySQL默认: REPEATABLE-READ
不可重复读和幻读看起来非常类似, 不可重复读侧重于对同一数据的修改,幻读侧重于新增或者删除
4.InnoDB可重复读隔离级别下如何避免幻读
表象: 快照读(非阻塞) --伪MVCC
内在: next-key锁(行锁+gap锁)
当前读和快照读
当前读: select…lock inshare mode, select…for update
当前读: update、delete、insert(不管是共享锁还是排他锁,都是当前读,因为读取的都是最新版本,并且保证其他并发事务不能修改当前记录,对读取的记录加锁)
5.RC、RR级别下的InnoDB的非阻塞读如何实现
数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
undo日志
read view
语法
关键语法
GROUP BY
满足"SELECT子句中的列名必须为分组列或列函数"
列函数对于group by子句定义的每组各返回一个结果


HAVING
通常与GROUP BY子句一起使用
WHERE过滤行, HAVING过滤组
出现在同一sql的顺序: WHERE>GROUP BY>HAVING


COUNT, SUM, MAX, MIN, AVG