1.kd-tree简介
Kd-Tree(K-dimensional tree),是一种高维索引树形数据结构,经常使用于在大规模的高维数据空间进行最近邻查找,比如图像检索和识别中的高维图像特征向量的K近邻查找与匹配(查找与所给数据最接近的k个数)。
kd树结构类似于高维的二叉树,树中存储的是一些K维数据。在一个K维数据集合上构建一棵Kd-Tree代表了对该K维数据集合构成的K维空间的一个划分。
2.kd-tree的构建
2.1如何构建高维“二叉树”
那么我们如何将高维数据按照二叉树的划分方法进行划分呢?要想完成高维数据的“二叉树”的构建,我们首先需要解决两个问题:
1.每次对子空间的划分时,如何确定在哪个维度上进行划分?
为了保证划分后每部分数据更加接近,我们需要选择距离更加分散的维度进行划分,因此我们选择方差最大的维度进行划分。
2.在某个维度上进行划分时。如何确保在这一维度上的划分得到的两个子集合的数量?
我们需要找到一个划分值pivot,在某个划分维度上,大于这个值的数据划分到右子树,小与这个值的数据划分到左子树。最直接的方法就是找到这些数据在某个维度的中位数作为划分值pivot。
2.1kd-tree的构建步骤
(1)对数据在每个维度的方差进行计算,选取方差最大的维度作为划分维度kv。
(2)计算数据在kv维度的中位数,根据中位数将数据划分为2个子集,在kv维度上,小于等于中位数的数据放入左边子集,大于中位数的数据放入右边子集。
(3)对每个子集重复(1)(2)步骤直至子集不能再划分为止。
以二维数据为例,用(2,3)(4,7)(5,4)(7,2)(8,1)(9,6)
构建kd树。第一次构建:计算两个维度方差最大的维度(x维度),选取此维度中位(5)数进行划分。<1|5>节点表示在第一个维度上以5为划分值进行划分,小于等于5的划分到左子树,大于5的划分到右子数。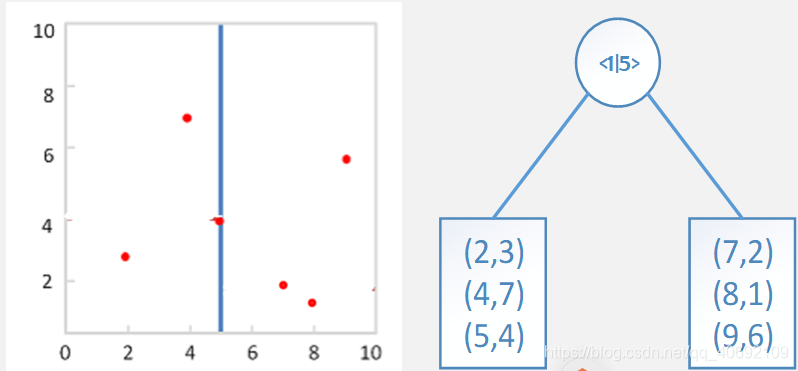
重读操作得到下面结果: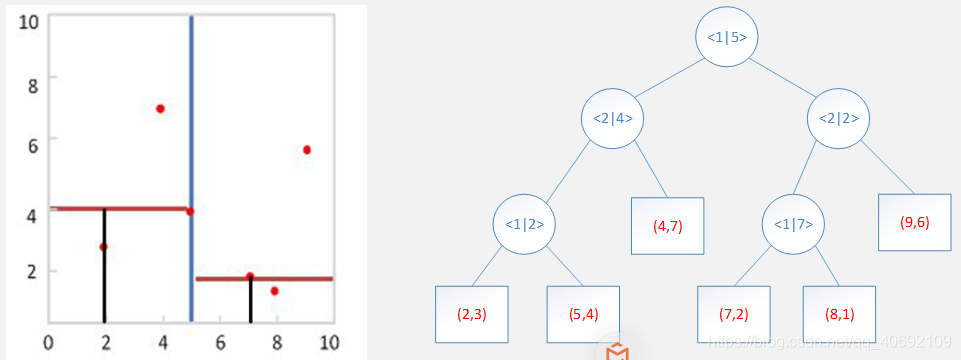
2.2kd-tree的特点
(1)数据为多维数据,不同树节点根据不同维度进行数据划分。
(2)父节点将所有数据划分至左右子树,叶子节点包含所有数据。(网上看到了不同的版本,有在父节点放入数据的,这里参考Rob Hess的sift源码里的kd-tree)
(3)在计算机视觉领域应用Kd-Tree较多的是在特征点匹配的时候,即最近邻查找而非数据查找。
(4)适用于动态程度不高的数据,插入删除不方便。
2.3中位数的计算
在kd-tree构建步骤中的第2步,我们需要计算处方差最大维度的中位数。计算中位数传统的方法就是将数据进行排序后取中间数:比如冒泡排序、快速排序。但是在我所参考的源码中,作者使用的是一种rank-select(快速选择算法)。不同的算法对kd-tree的构建时间的影响各不相同。
rank-select
快速排序
3.kd-tree的查找
对数据Q的一次查询是从根节点开始,对各个节点进行访问,直至访问至叶子结点,计算与叶子节点内数据的距离。访问过程:在节点的维度与节点的划分大小进行比较。
因为每次访问时只在一个维度比较大小,所以此时得到的最近点并不一定为最小距离的点,未被访问的分支内话可能存在距离更小的点。还需要对未被访问的分支进行回溯。
数据点集合:(2,3), (4,7), (5,4), (9,6), (8,1), (7,2) ,需要访问的点为(8,3)。
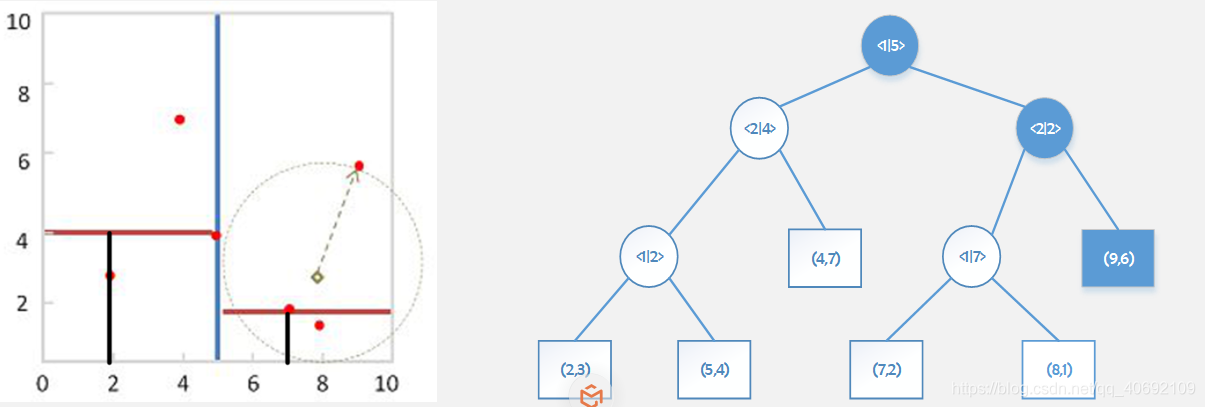
在构造树的过程中,记录下每一个子树所在的切割维度k和切割值m,(k, m)。Q与子树的距离则为|Q(k) - m|。当访问的最小距离大于Q与子树距离时,则重新访问子树未被访问的一个分支,如果最后得到的子节点更小,则更新最小距离Dcur。
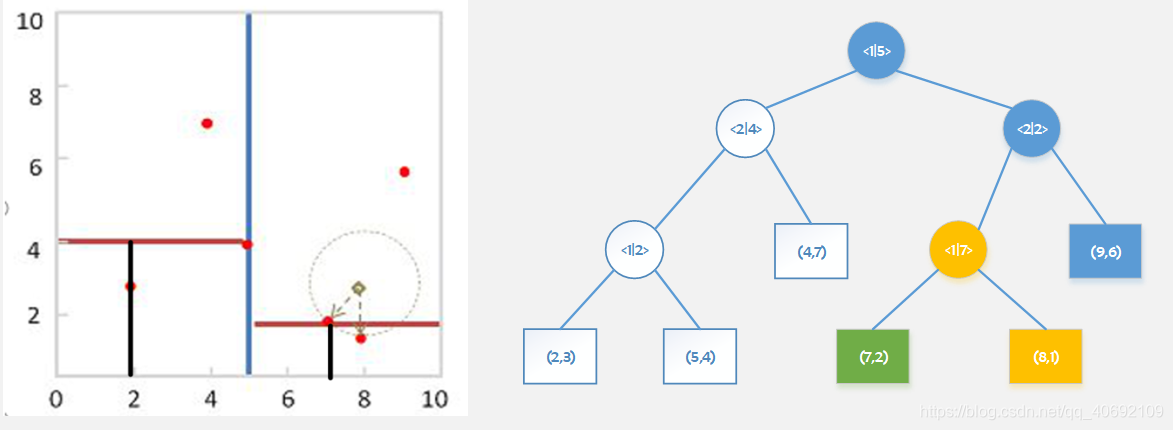
基于BBF的回溯
当树中元素维度过高时,回溯次数会变得很大,查找效率会随着维度的添加而迅速下降。我们常用BBF(best bin first)算法来改进kd-tree该算法可以实现近似K近邻的高速搜索。在保证一定查找精度的前提下使得查找速度较快。
特点:
(1)人为规定了最大回溯次数。
(2)按照查找数据与树分支的距离创建优先级队列,离所查找数据越近的树分支优先回溯。其中优先级队列按数据与树分支的距离由小到大顺序排列,存放着距离和对应的树节点未被查找的一个分支的位置。
查询点Q: (5.5, 5)
第一遍查询:(9,6)
距离d=13.25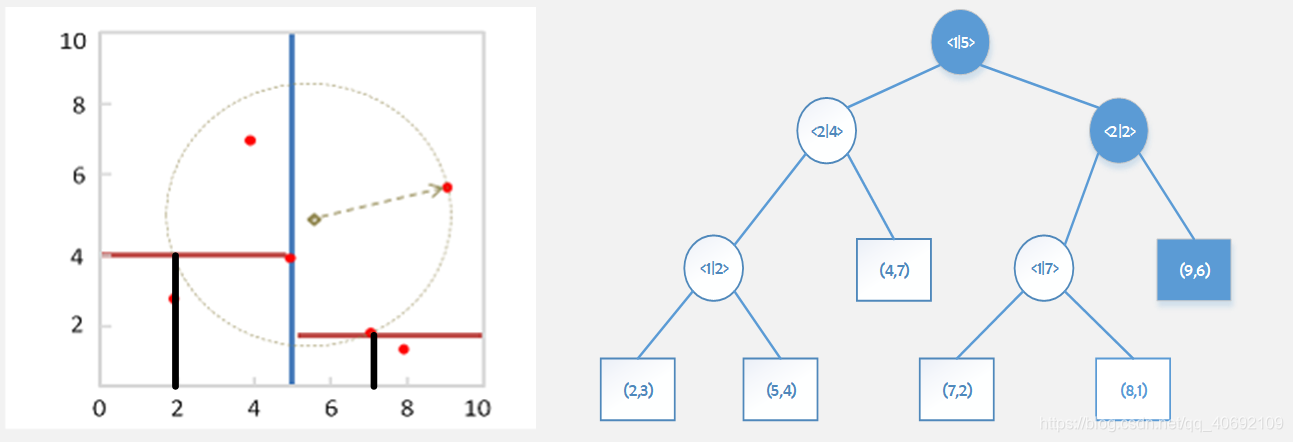
查询同时计算点与节点距离,按距离放入优先级队列。
与<1|5>距离为0.5,与<2|2>距离为3。
此时优先级队列:<1|5> <2|2>
查询点Q: (5.5, 5)
选择距离Q最近的未被选择树分支进行回溯。
第二遍查询:(4,7)
距离d=6.25
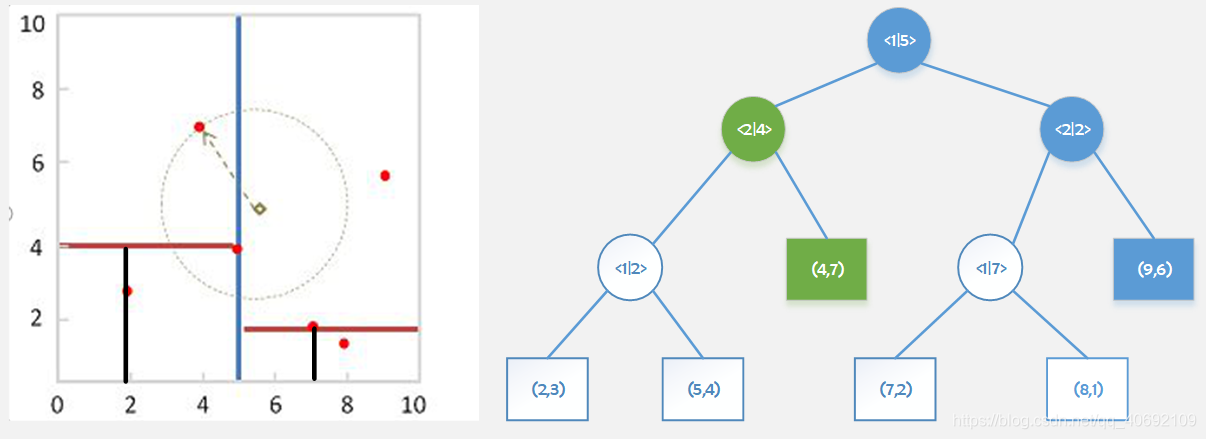
原优先级队列:<1|5> <2|2>
第二遍取出<1|5>第二次查询时更新队列。
更新后优先级队列<2|4> <2|2>
查询点Q: (5.5, 5)
继续从优先级队列里选择距离Q近期的未被选择树分支回溯。
第三遍查询:(5,4)
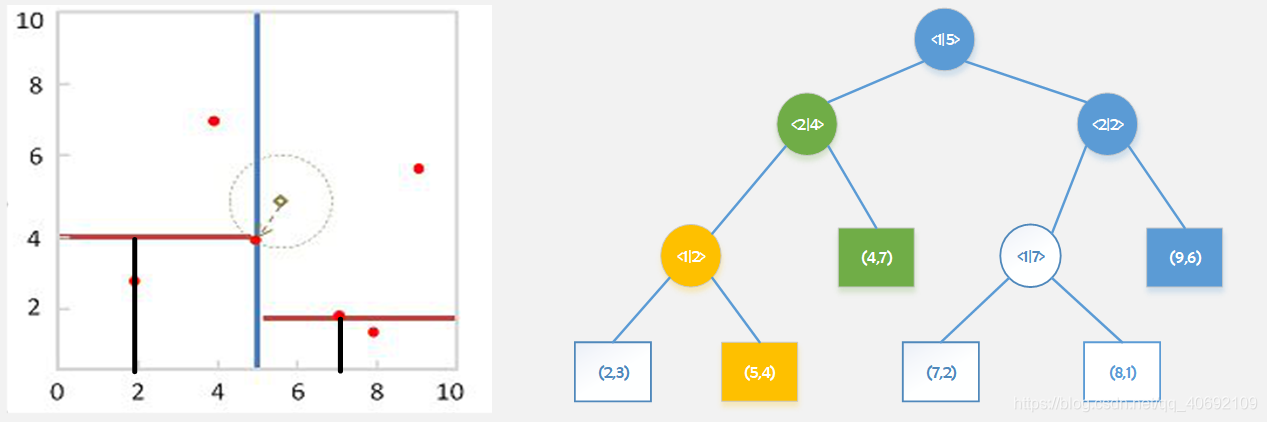
原优先级队列:<2|4> <2|2>
第三遍取出<2|4>第三次查询时更新队列。
更新后优先级队列 <2|2> <1|2>
优先级队列的创建
优先级队列的创建用了堆的思想。
通俗来讲堆其实就是利用完全二叉树的结构来维护的一维数组。
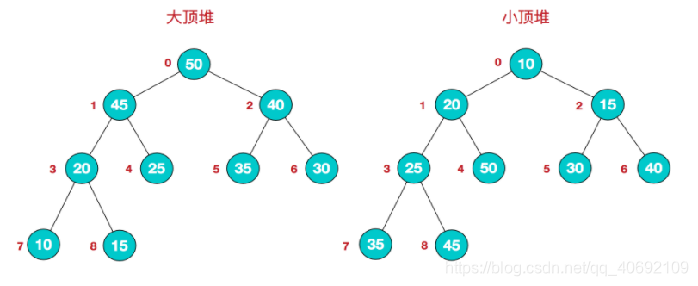
大顶堆:每个结点的值都大于或等于其左右孩子结点的值(arr[i]>=arr[2i+1]&&arr[i]>=arr[2i+2])
小顶堆:每个结点的值都小于或等于其左右孩子结点的值(arr[i]<=arr[2i+1]&&arr[i]<=arr[2i+2])
向堆里插入数据(以小顶堆为例):
将数据放入数组最后,依次和其所对应父节点(n/2-1)比较,如果小与父节点则与父节点交换位置。
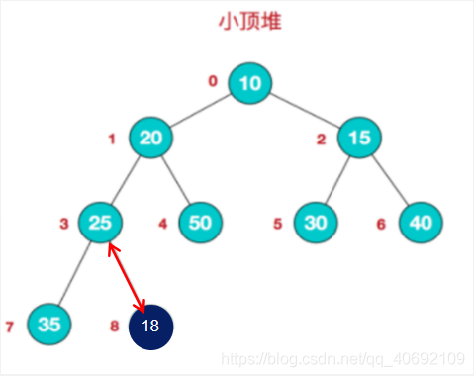
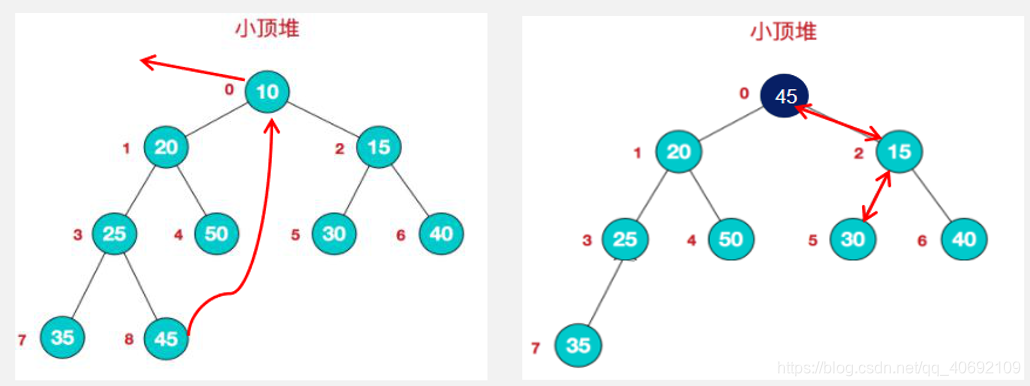
从堆里提取最小值:
直接将数组里第一个数取出,然后将最后一个数据放入第一个位置,然后将此父节点数据与两个子节点比较,最小的数放入父节点,递归此步骤直到完成排序。
参考:
Kd-Tree算法原理和开源实现代码
Rob Hess sift源码