(1)学习了Tensorflow框架的基本使用
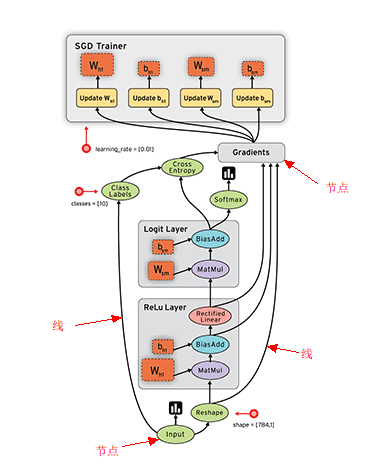
TensorFlow 被认定为 神经网络中最好用的库之一,它擅长的任务就是训练深度神经网络。我主要通过【莫烦tensorflow教程系列】进行学习,学习了tensorflow的基本使用。Tensorflow的使用比起其他的框架,它是采用数据流图(data flow graphs)来计算的,所以需要创建一个数据流图, 再将数据放在数据流图中计算(数据以张量(tensor)的形式存在),即先定义神经网络的结构, 然后再把数据放入结构当中去运算和 training,如图。
对于论文《Deep Knowledge Tracing》的Tensorflow框架的实现(链接:https://www.cnblogs.com/jiangxinyang/p/9732447.html) ,包含了一下五个文件。
1.config.py文件中主要定义了训练神经网络会用到的一些参数,如学习率、隐藏层数、批处理参数、惩罚系数等。
2.data_process.py文件是把数据从txt文件读出,通过一系列变换,转换成提供给神经网络使用的数据形式。
3.mode.py文件是搭建神经网络,定义输入层、隐藏层、LSTM层、输出层等各个层的参数,具体的计算过程Tensorflow框架已提供,只需输入参数即可。部分代码如下图。
4.train_dkt.py文件是用来训练模型
5.predict_dkt文件是用模型进行预测
(2)知识追踪论文阅读
《基于“态度”的知识追踪模型及集成技术》(2011年)
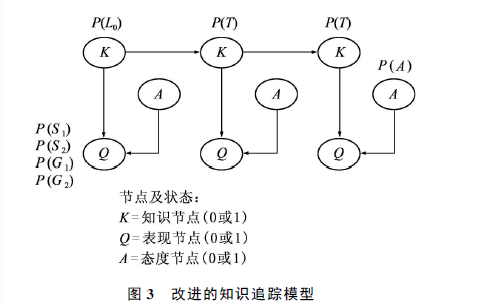
本文着重于对每一次做题时间的研究来提高准确率。通过对影响学生做题表现因素的分析,本文增加了一个态度节点来细化各种因素,改进模型,参数P(A)表示处于某种态度A的概率,当态度节点状态为1时,其概率为P(A)。
改进的模型以表现节点和态度节点作为输入,预测学生对知识的掌握情况以及未来做题的表现。由于增加了一个态度节点,P(S)和P(G)参数被细分为两个不同“态度”状态下的参数。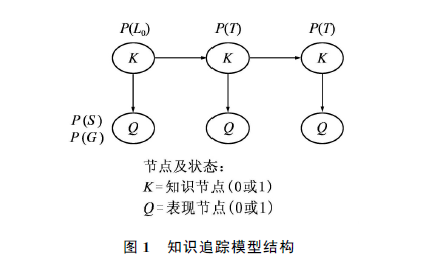
--预处理
对于态度节点赋值:态度节点的原始数据是学生做题的持续时间,不能想正确和错误一样简单地量化为1或0。
采用两种方法对其赋值:
(1)最大正确时间:将每个做题序列里做题正确的最大时间设定为阈值,高于该值得设定为0,否则为1.
(2)K-means聚类算法:K-means聚类算法是把相似的对象通过分类的方法分成不同的子集,同一个子集中的对象都有相似的属性。本文将做题持续时间和做题表现作为输入矩阵,将矩阵分为两类,根据所属的聚类,将持续时间量化为0和1,赋值给态度节点。
--集成技术
集成技术主要是通过统计方法来学习不同模型的预测准确率,测算出各个模型在最终预测结果中所占比重,并综合不同模型的预测效果以达到提高预测准确率的目的。
本文采用神经网路、线性回归、随机森林3种方法对标准知识追踪模型、最大时间模型及K-means聚类之后赋值的模型进行集成,提高预测的准确率。
--实验
(1)测试平台:
1.使用Bayes net toolbox(BNT) for Matlab库进行建模
2.对时间的预处理使用数据挖掘软件WEKA和 Matlab statistics tookbox
3.集成技术分别采用 neural network toolbox 和 WEKA
(2)数据:实验数据集来自名为Bridge to Algebra在线教育系统,该数据集是2010年KDD Cup比赛数据之一。
此数据集包含1840个学生共2289726项记录.每项纪录包含学生ID、知识点所属章节、问题类型、步骤类型、开始及结束时间、回答正确或错误、请求提示次数、知识点类型、做题次数等19条信息。
该系统用于数学课堂教学,学生做的每一道题被分成了许多步骤。[ 系统记录每一个步骤的做题情况 ]。在做题过程中,学生可以请求系统中的提示,请求提示后该题无论正确与否都标记为错误。当模型计算出某学生掌握某知识点的概率达到95%时,便不会再遇到关于该知识点的题目。

(3)数据处理:由于数据集很大,本文将这个数据集按 知识点类型与学生ID 分成若干个小的集合,每个集合包含了某学生对某知识点相关题目的所有表现。本文用总均方根误差和t检验来给出预测结果。
(4)实验结果:基于“态度”的模型确实提高了预测准确率。
1.t检验结果表明,采用最大时间法虽然有了一定的提高,但是差别并不显著。
2.采用了K-means聚类算法处理做题时间后,预测结果相对于标准知识追踪模型有了显著的提高。
3.相对于标准知识追踪模型以及单纯的改进模型,3种集成技术的预测结果都有显著提高。
--结论
将本文中基于“态度”的知识追踪模型添加到 assistments在线教育系统(https://www.assistments.org/),可以充分利用原来作为多余部分的做题时间等数据,提高对学生掌握知识情况的预测的准确率.
--后续工作
对初次使用该系统的学生的预测,准确度相对欠佳;在改进模型提高预测准确度的同时,如何尽可能地获得相对较快的运算速度。
《基于贝叶斯知识跟踪模型的慕课学生评价》(2015年)
根据贝叶斯知识跟踪(BKT)的变形,提出基于知识点方面的Aspect-BKT和基于提交历史的History-BKT两套模型
主要研究如何更准确地推断学生是否正确掌握各个知识点。
--数据预处理:
智能教育系统的一个优势是,系统在设计之初,已经对知识点做了比较详细的规划。各个题目已经事先被标记为由于某一个知识点相关,需要有相关专家完成。而MOOC没有这样的专家,而且知识点详细划分是一个浩大的工程。
解决办法:直接利用MOOC本身的结构来解决该问题,MOOC课程每周都是一个时间单元,简单的做法是直接将一周的内容作为一个知识点,假设每次小测验的若干道题目都是围绕同一个知识点。
优点:不用领域的各个课程都能适用
缺点:划分力度粗、时间跨度比较短
--模型
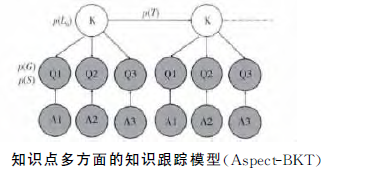
(1)Aspect-BKT模型
针对知识点划分不够精确,提出Aspect-BKT模型(知识点多方面的知识跟踪模型)。即使掌握了该知识点,由于知识点存在多个方面,学生还需要具有将知识点应用到小测验中各个实际问题的能力,而这主要受各个问题具体难度的影响。
各个题目的节点可以由一个Apply节点来影响,取值为0和1,反映的是不同题目之间的难度区别,p(A=1)越高,表示题目越简单。,本文采用各个题目相对于所有提交次数中做正确比例,即总体的准确率作为(p(A=1)。
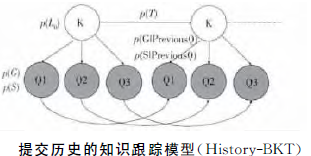
(2)History-BKT模型
针对MOOC课程的测验重复提交的特点,提出History-BKT模型。本文把每次提交作为BKT的一个时间点,各个时间点各自有一个学生掌握知识点的概率p(L)。
基本想法:题目与前一次提交的题目存在紧密的联系,前一次回答正确的题目,这一次和可能会回答正确
针对前一次答题情况 分别训练p(G)和p(S),共有第一次提交、前一次答对和前一次答错3类不同的情况,回答正确的概率分布会有所不同。
--算法过程
用EM算法训练参数,本文根据之前的训练情况,人为地参数初始化。
--实验
对于每次实验,将学生最后一次提交结果的数据作为带预测的数据,利用训练集训练参数,并用测试集的学生前几提交的结果推测最后一次提交时掌握知识点的概率p(L).
实验结果:Aspect模型比IDEM模型要差,IDEM模型和History模型没有显著区别,尤其是在数据较少时,History模型任能够保持不错的准确率。
实验分析:(1)G越大,S越小,则学生回答的准确越高。(2)原来回答错误的题目,下一次很容易回答错,但如果原来正确,下一次很难犯错。正是因为这种数据特点的有效性,才能使得History-BKT有效,而且该特点与数据量大小无关。
--结论
Aspect模过于粗糙,比不上IDEM模型,因为MOOC的数据特点,History模型取得不错的效果。
将一周时间的知识点作为一个整体知识点的当以方式过于粗糙;如何细致地模拟学生的知识状况值得思考。
--后续工作
考虑针对P(T)参数的变化,以利用丰富的学生行为数据,通过分析学生在两次小测验之间的行为,来影响相应的P(T)值。
《知识追踪模型融入遗忘和数据量因素对预测精度的影响》(2019年)
本文介绍了知识追踪及其扩展模型,作为一个案例探究,评估了知识追踪及其扩展模型预测学习者未来表现的正确率,并将模型使用所有学习者的数据与每个学习者的部分数据的预测准确性进行了比较。
--研究方法
(1)预测学习者未来表现
实验第一阶段:采用Murphy 使用Matlab 中的Bayes Net Toolbox 开发的程序来实现知识追踪模型和期望最大化(EM) 算法分析学习者特定知识掌握水平,预测学习者未来表现,并限制P ( G ) 和P ( S ) 的值,否则会出现知识追踪模型出现模型退化现象。
(2)提高学习者未来表现预测精度
实验第二阶段:使用知识追踪扩展模型,即在最初提出的知识追踪模型四个参数的基础上增加一个遗忘参数并设置不为0,在赋予学习者初始遗忘的基础上通过学习数据迭代出学习者遗忘概率值。
(3)学习者部分数据对知识追踪扩展模型未来表现预测精度影响分析
实验第三阶段:使用知识追踪扩展模型,根据采用每个学习者数据量的多少分组进行对比分析研究。 如果实验第二阶段在预测学习者未来表现时证实遗忘不可忽略,则学习者作答时间越靠前的问题,对于模型获得相对完美参数的干预就越强,因此对比分析了每个学习者学习数据的后1/3、后1/2、后2/3 量的数据与使用完整数据。
--实验
(1)数据集
本研究从KDD Cup 2010数据集中选择了数据集的一个子集,即学习者在概率单元第四小部分的学习过程样本,此样本包括200 个学习者,每个学习者包括30 个维度问题答案,共6,000 个样本数据点作为知识追踪模型的训练和测试数据集。
(2)实验过程:实验分为三个阶段,如图所示。

(3)实验结果:1.遗忘参数对于提高知识追踪模型对学习这未来表现存在积极影响;2.知识追踪扩展模型使用学习者后10个、后20 个数据与完整数据具有可比的预测表现,
扩展模型使用每个学习者后15 个数据有比使用完整数据更好的预测表现。
--结论
知识追踪扩展模型(遗忘不为0) 可以更准确地预测学习者未来表现;因为遗忘因素的存在学习者越靠前作答的问题对于模型获得更加完美参数的干预就越强,因此选择合适的每个学习者的后数据量更有可能产生更能代表学习者知识水平的模型参数值,不仅可以提高预测精度,还可以节省模型训练时间。
不足之处:1.知识追踪模型给予所有学习者同一参数值(初始概率、学习率、猜测和失误率等),在学习者真实学习过程中应该是不同的。 2.知识追踪模型没有考虑学习者答题时的态度、参与度以及不同情绪 对模型预测学习者未来表现精度的影响。
--后续工作
(1)探究模型运行的数据集是采用离散(0, 1) 还是连续(0-1 之间任意值) 的数据形式更有利于预测学习者真实知识状态。
(2)探究[个性化学习者初始概率]实现知识追踪的个性化建模,以验证个性化参数的知识追踪模型是否对学习者未来表现预测精度更好,并探究融入更多的学习者其他特性对于改善知识追踪模型预测性能的价值。
(3)探究不同知识追踪模型对于实验数据的偏好及为模型测得的学习者学习收益与对应的学习者学习操作行为建立相关匹配模式。
《Structured Konwledge Tracing Models for Student Assessment on Coursera》
这边篇文章与《基于贝叶斯知识跟踪模型的慕课学生评价》是同一个作者,《基于贝叶斯知识跟踪模型的慕课学生评价》提出了Aspect-Bkt和History-Bkt模型,本文提出了Multi-Gained-Bkt和Historical模型,创新主要在于Multi-Gained-Bkt模型。这里主要介绍Multi-Gained-Bkt模型。
利用MOOC知识组织的特点,每章内容通常有多个授课是视频组成,每个视频往往在几分钟内聚焦于一个具体而完整的主题,因此,可以将每个视频所涵盖的内容为一个KC。
Multi-Gained-Bkt模型中,将整个章节视为整体的粗粒度KC,而每个视频所涵盖的内容则是细粒度KC之一,模型如下图所示。At 表示在t时刻细粒度KC的知识状态,P(Mk)表示在总体KC以掌握的情况下,掌握细粒度KC的概率。
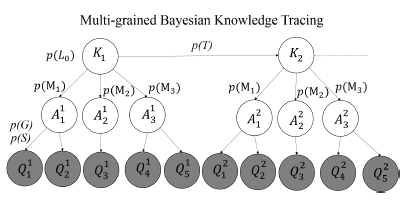
Multi-Gained-Bkt模型中,每个粗粒度KC有多个问题,多了一个细粒度层。当学生掌握了一个粗粒度KC时,有可能是掌握了一个其所包含的细粒度KC,否则,不可能掌握任何一个细粒度KC。P(A)和P(M)计算如下。第一个公式表示,在t时刻下,细粒度k未掌握的概率=当前知识状态P(Lt) * 未掌握细粒度K的概率p(Mk)+未掌握知识点的概率(1-(Lt))
![]()
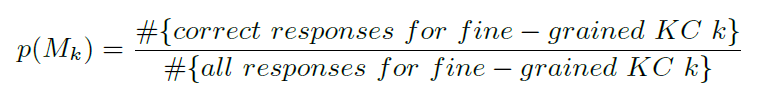
本模型将模型复杂度控制在4个自由参数,并用EM算来估计参数和预测提交结果。