几个时序数据库
https://www.cnblogs.com/harrychinese/p/time_series_db.html
================================
可用作时序的数据库:
================================
[时序]TimescaleDB, 基于 PostgreSQL, 支持 SQL.
[时序]KairosDB, 基于 Cassandra, 不支持 SQL.
[通用]CrateDB, 基于 Elastic Search, 但支持ANSI SQL
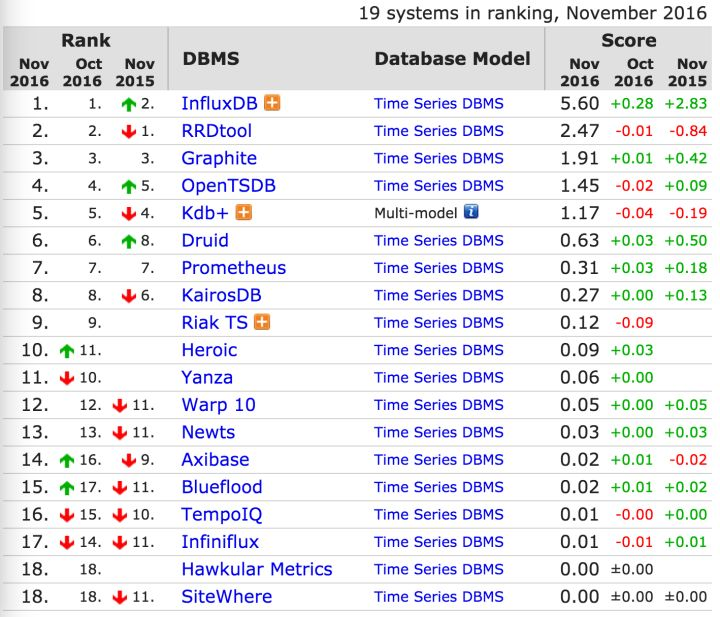
[时序]InfluxDB, 是 db-engines 上排名第一的时序数据库, 最新版中集群功能不开源了, 商业版支持, 另外并发查询性能较差.
[通用]Kudu, 列式存储(类parquet), 支持 java API 更新数据, 比较赞的是支持 upsert. 可以通过 impala 或 spark 来支持SQL 查询.
简单点评(基于底层技术做的点评, 未做个实际测试)
TimescaleDB 基于PostgreSQL, 可能适合数据量不太大的情形, 但提供丰富的SQL功能
KairosDB, 基于 Cassandra, 运维应该比较简单, 扩展性也应该不错, 写入性能估计要比 CrateDB 差一些, 另外不支持SQL.
CrateDB 基于 Elastic Search, 写入性能应该很好, 扩展性也应该不错, 估计 SQL 支持度和读取性能会差一些, 支持全文检索.
db-engines 网站的对比:
https://db-engines.com/en/system/CrateDB%3BKairosDB%3BTimescaleDB
Crate 官方的比较:
http://go.cratedb.com/rs/832-QEZ-801/images/CrateDB-Cassandra-MongoDB-Comparison.pdf
================================
支持SQL的流处理框架
================================
多数流处理方案中, 数据一般都会暂存在 kafka中, 格式推荐使用 Json/Avro, schema 推荐使用 Oracle Goldgate(OGG)数据格式.
支持SQL的流处理框架有:
1. Spark Streaming: 可以写很复杂的SQL, 比如和其他数据库DB做 join.
2. Kafka 的 KSQL: 和Kafka公用集群, 不需要额外计算集群.
3. PipelineDB : 基于 PostgreSQL 的扩展, cluster版需要付费. 流数据既可以直接写到 pipelinedb(以pipelinedb的FOREIGN TABLE形式暂存流数据), 然后通过 pipelinedb SQL来处理; 流数据也可以先打到kafka中, 然后再通过 pipelinedb extension来处理.

================================
可用作时序的数据库:
================================
[时序]TimescaleDB, 基于 PostgreSQL, 支持 SQL.
[时序]KairosDB, 基于 Cassandra, 不支持 SQL.
[通用]CrateDB, 基于 Elastic Search, 但支持ANSI SQL
[时序]InfluxDB, 是 db-engines 上排名第一的时序数据库, 最新版中集群功能不开源了, 商业版支持, 另外并发查询性能较差.
[通用]Kudu, 列式存储(类parquet), 支持 java API 更新数据, 比较赞的是支持 upsert. 可以通过 impala 或 spark 来支持SQL 查询.
简单点评(基于底层技术做的点评, 未做个实际测试)
TimescaleDB 基于PostgreSQL, 可能适合数据量不太大的情形, 但提供丰富的SQL功能
KairosDB, 基于 Cassandra, 运维应该比较简单, 扩展性也应该不错, 写入性能估计要比 CrateDB 差一些, 另外不支持SQL.
CrateDB 基于 Elastic Search, 写入性能应该很好, 扩展性也应该不错, 估计 SQL 支持度和读取性能会差一些, 支持全文检索.
db-engines 网站的对比:
https://db-engines.com/en/system/CrateDB%3BKairosDB%3BTimescaleDB
Crate 官方的比较:
http://go.cratedb.com/rs/832-QEZ-801/images/CrateDB-Cassandra-MongoDB-Comparison.pdf
================================
支持SQL的流处理框架
================================
多数流处理方案中, 数据一般都会暂存在 kafka中, 格式推荐使用 Json/Avro, schema 推荐使用 Oracle Goldgate(OGG)数据格式.
支持SQL的流处理框架有:
1. Spark Streaming: 可以写很复杂的SQL, 比如和其他数据库DB做 join.
2. Kafka 的 KSQL: 和Kafka公用集群, 不需要额外计算集群.
3. PipelineDB : 基于 PostgreSQL 的扩展, cluster版需要付费. 流数据既可以直接写到 pipelinedb(以pipelinedb的FOREIGN TABLE形式暂存流数据), 然后通过 pipelinedb SQL来处理; 流数据也可以先打到kafka中, 然后再通过 pipelinedb extension来处理.