估计每位绅士都看过妹子图,如何将里面小姐姐的图片保存下来呢?
本次博主来开车讲解如何做一个妹子图街拍美女的图片爬虫。
滴滴,各位绅士请尽快上车,本次目的地幼儿园。o(////▽////)q ,你懂得!!!
前提准备
各位绅士都上车了吧!好的,博主要将车门焊死了,不到幼儿园谁都别下车。ヾ(•ω•`)o
为了安全食用本次教程,需要准备如下:
python(版本:3.7)
requests(版本:2.21.0)
lxml(版本:4.3.3)
火狐浏览器或谷歌浏览器
win7或win10电脑一台
需求分析
爬取妹子图街拍美女模块的所有福利图,并下载保存到本地的文件夹【picture】中
妹子图街拍美女模块网址 【https://www.mzitu.com/jiepai/comment-page-1/#comments】
网页分析
首先我们打开妹子图街拍美女网址,然后右键图片点击【查看元素】查看图片链接位置
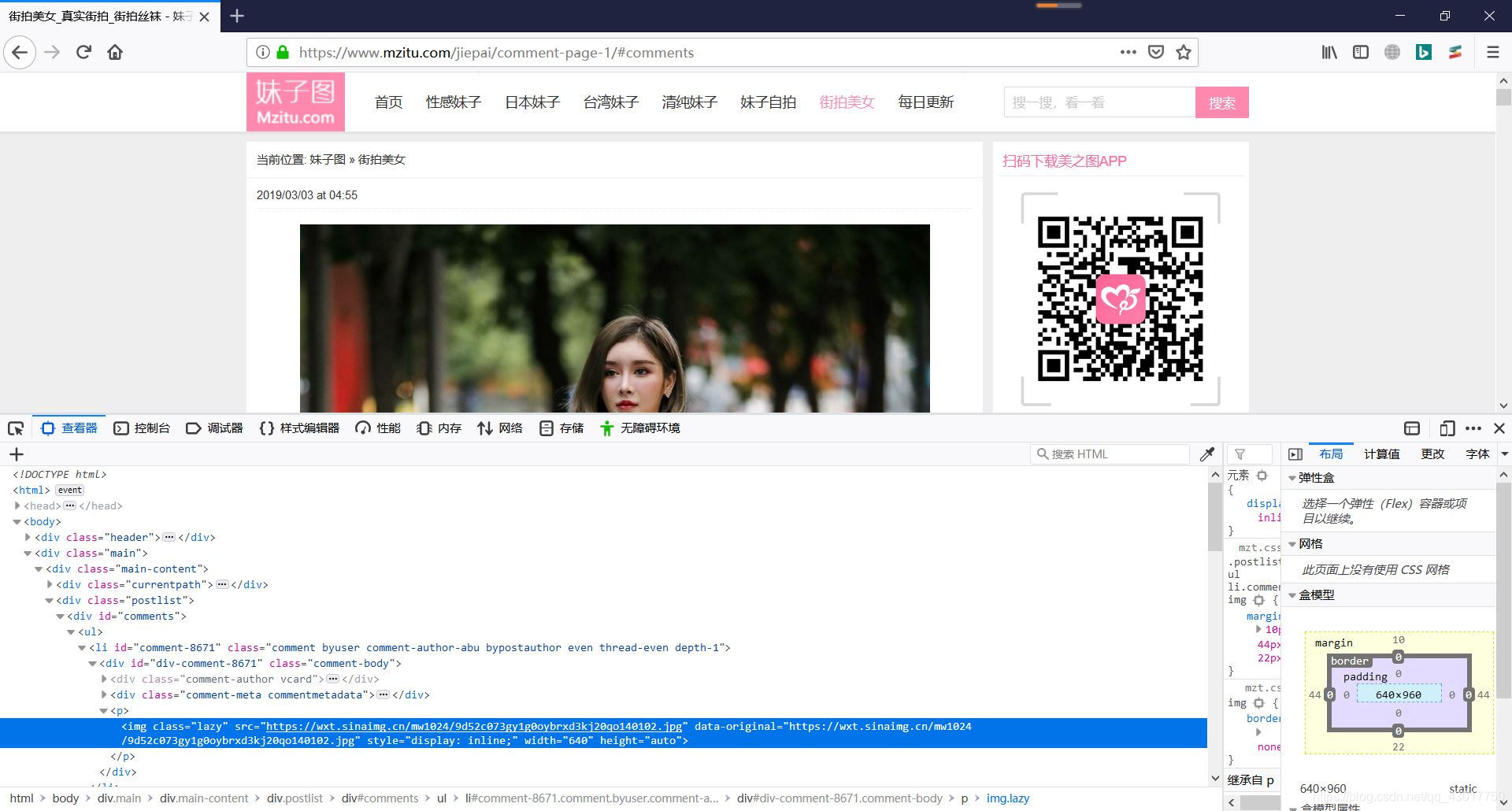 各位绅士请看网页代码,别看妹子(lll¬ω¬)!
各位绅士请看网页代码,别看妹子(lll¬ω¬)!
可以发现网页存在于class属性为lazy的标签中的data-original属性中,好的这样我们很容易写出匹配图片的xpath。现在页面中的所有图片可以提取出来了。由于我们是要爬取所有的网页,所有还要实现翻页的功能,分析下翻页后的网址变化。
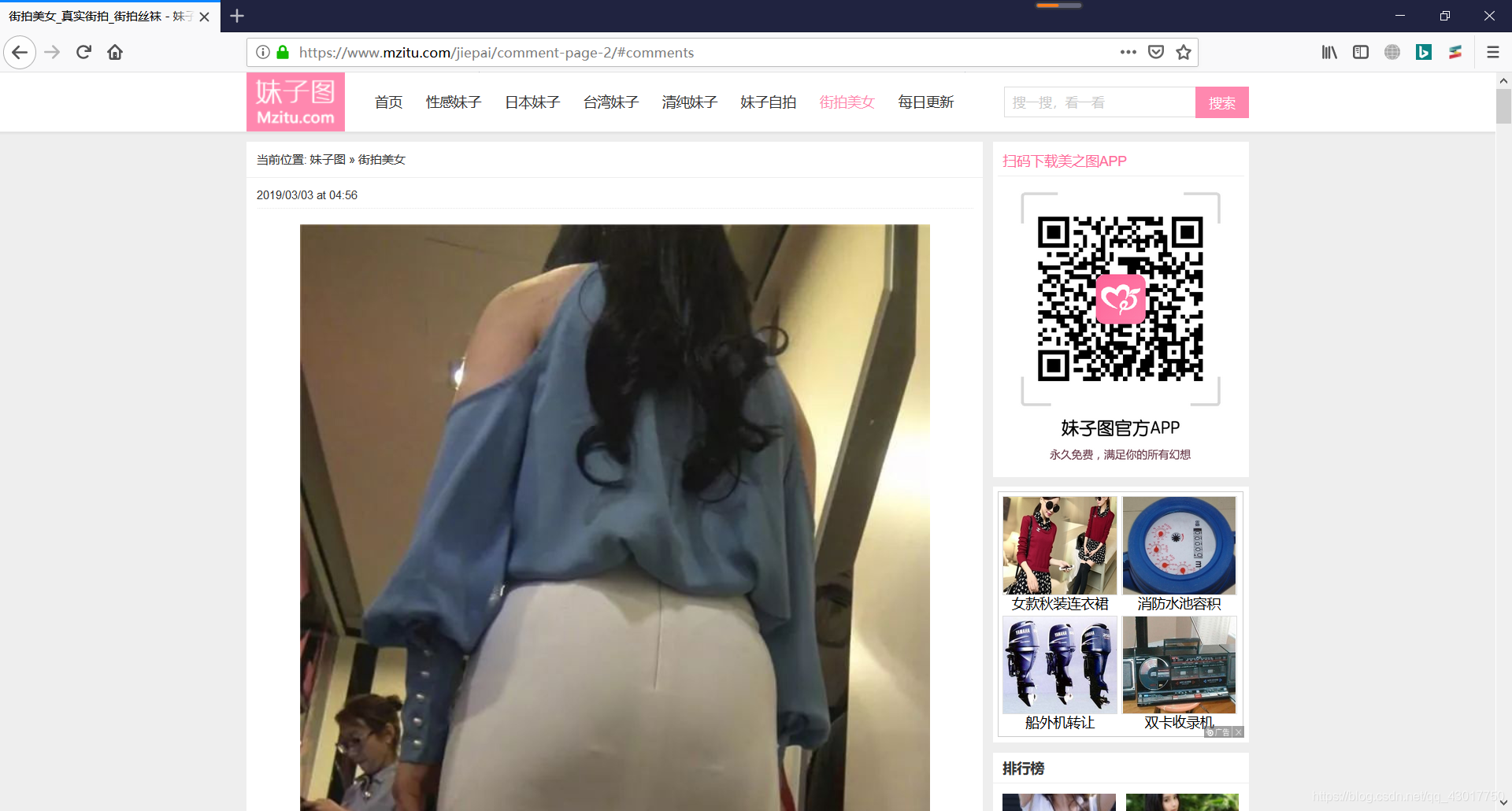 第一页的网址
第一页的网址
【https://www.mzitu.com/jiepai/comment-page-1/#comments】
第二页的网址
【https://www.mzitu.com/jiepai/comment-page-2/#comments】
可以看出翻到第N页就是将网址中page-后面的数字变成N。
实战代码
1.前提参数
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月19日
import requests
from lxml import etree
"""
设置浏览器头部,
User-Agent用于表示浏览器的参数信息
Referer用于设置使用那个网页跳转过来的
url用于设置网址模板,可以通过.format参数补充网址
"""
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Referer":"https://www.mzitu.com/jiepai/comment-page-1/",}
url = 'https://www.mzitu.com/jiepai/comment-page-{}/#comments'
name = 0
# -*- coding:utf-8 -*-的作用是设置代码使用的默认编码为utf-8
import requests导入名为requests的模块,如果可以通过pip install requests安装该模块
from lxml import etree导入lxml模块中的etree函数,用于将网页改为etree格式,进行匹配图片链接
header 用于保存headers参数,用于模拟浏览器
url 用于保存网址模板,方便后期生成网页网址
name用于保存当前是第几张图片
2.下载网页
def get_html(url):
"""获取网页代码并以返回值的形式弹出"""
html = requests.get(url,headers=header).text
return html
定义一个函数get_html用于下载网页代码,调用时需要传递一个网址作为参数
使用requests模块的get函数,将网址作为传递进去,并将header作为浏览器头部传入关键字形参headers,将内容以text文本的形式保存到变量html中,并使用return将网页内容弹出。
3.下载图片
def get_img(url):
"""下载图片并保存到指定文件夹下"""
global name
name +=1
img_name = 'picture\\{}.jpg'.format(name)
img = requests.get(url,headers=header).content
with open (img_name,'wb') as save_img:
save_img.write(img)
定义一个函数get_img用于下载图片,调用时需要传递一个网址作为参数
global name ,用于该函数修改全局变量name 的值
name += 1 设置当前name的值为原先name的值加一,等价于 name += 1
设置一个变量img_name用于设置图片名称。使用requests模块的get函数,将网址作为传递进去,并将header作为浏览器头部传入关键字形参headers,将内容以content二进制数据的形式保存到变量img中,并且保存到picture文件夹中。现在也能获取网页代码,也能下载图片,我们还需要获取所有图片的网址
4.获取图片链接
def get_url(html):
"""获取图片链接并以返回值的形式弹出"""
etree_html = etree.HTML(html)
img_url = etree_html.xpath('//img[@class="lazy"]/@data-original')
return img_url
使用etree.HTML方法将网页代码转换为etree格式的数据
使用xpath匹配处所有的图片链接,便以reture的方式弹出
5.主函数
def main():
'''使用for循环爬取所有网页'''
for n in range(1,24):
print ("正在爬取第{}页".format(n))
html = get_html(url.format(n))
img_list = get_url(html)
for img in img_list:
get_url(img)
main()
使用for循环设置变量n的值,从数字1开始增长,结束值为24,默认步长为正一。
使用print ("正在爬取第{}页".format(n)) 打印当前爬取的是第几页。
然后将n的值传递进变量url中补齐网址,并将该网址传递进get_html函数,将下载到的网址保存到变量html中。
将变量html中保存的网页代码传递进get_url函数,用于提取处网页中的所有福利图链接。
使用使用for循环提取每张图片的具体链接传递进get_img函数用于下载图片
最后使用main()调用主函数
验证效果
现在我们执行这些代码,看看回发生什么
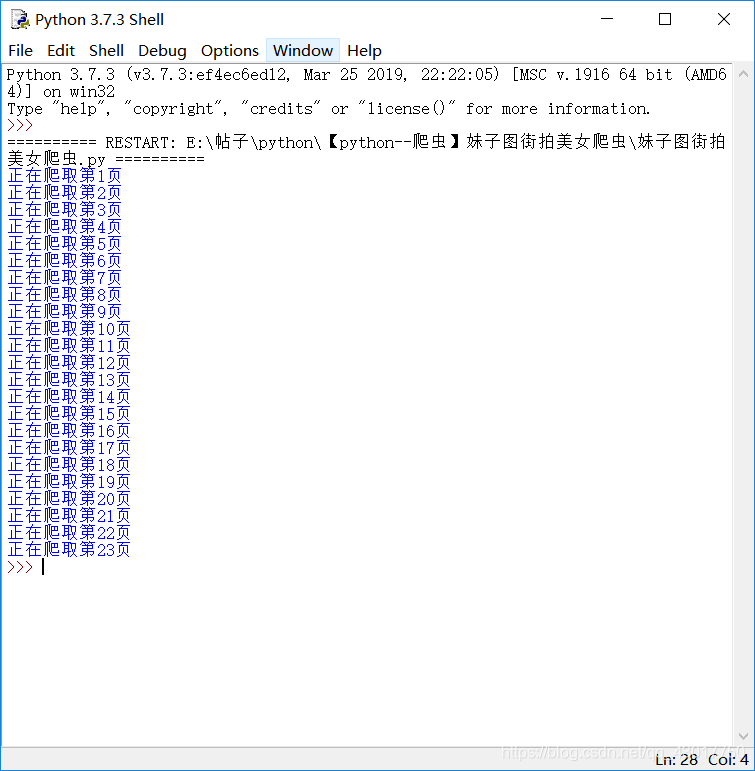
显示爬取了1到23页,在来看看爬取的图片,各位绅士请把持住o(////▽////)q
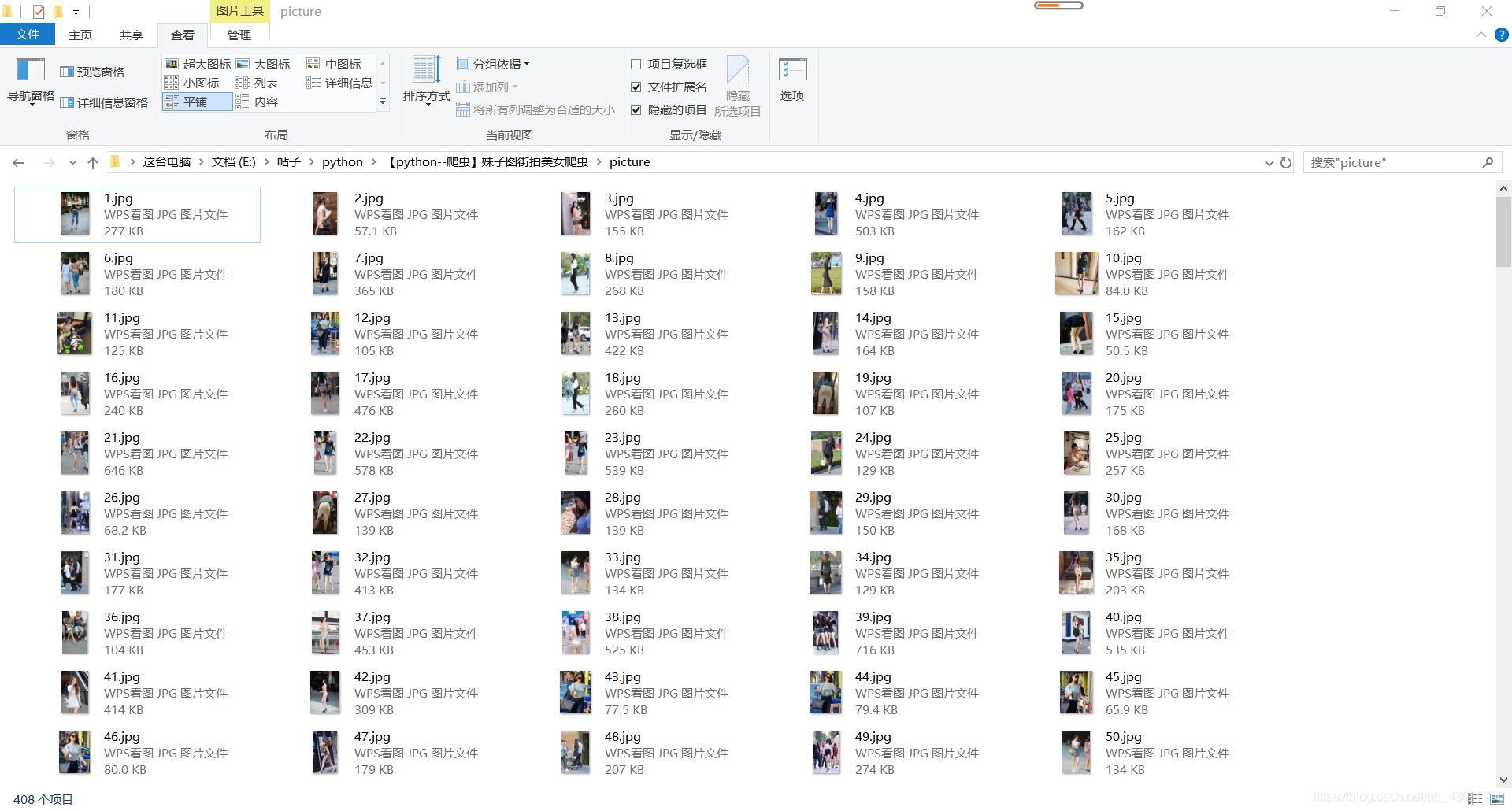
完整代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月19日
import requests
from lxml import etree
"""
设置浏览器头部,
User-Agent用于表示浏览器的参数信息
Referer用于设置使用那个网页跳转过来的
url用于设置网址模板,可以通过.format参数补充网址
"""
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Referer":"https://www.mzitu.com/jiepai/comment-page-1/",}
url = 'https://www.mzitu.com/jiepai/comment-page-{}/#comments'
name = 0
def get_html(url):
"""获取网页代码并以返回值的形式弹出"""
html = requests.get(url,headers=header).text
return html
def get_img(url):
"""下载图片并保存到指定文件夹下"""
global name
name +=1
img_name = 'picture\\{}.jpg'.format(name)
img = requests.get(url,headers=header).content
with open (img_name,'wb') as save_img:
save_img.write(img)
def get_url(html):
"""获取图片链接并以返回值的形式弹出"""
etree_html = etree.HTML(html)
img_url = etree_html.xpath('//img[@class="lazy"]/@data-original')
return img_url
def main():
'''使用for循环爬取所有网页'''
for n in range(1,24):
print ("正在爬取第{}页".format(n))
html = get_html(url.format(n))
img_list = get_url(html)
for img in img_list:
get_img(img)
main()